Chapter 7 Process Architecture and Control
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comprehensive Review for Central Processing Unit Scheduling Algorithm
IJCSI International Journal of Computer Science Issues, Vol. 10, Issue 1, No 2, January 2013 ISSN (Print): 1694-0784 | ISSN (Online): 1694-0814 www.IJCSI.org 353 A Comprehensive Review for Central Processing Unit Scheduling Algorithm Ryan Richard Guadaña1, Maria Rona Perez2 and Larry Rutaquio Jr.3 1 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines 2 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines 3 Computer Studies and System Department, University of the East Caloocan City, 1400, Philippines Abstract when an attempt is made to execute a program, its This paper describe how does CPU facilitates tasks given by a admission to the set of currently executing processes is user through a Scheduling Algorithm. CPU carries out each either authorized or delayed by the long-term scheduler. instruction of the program in sequence then performs the basic Second is the Mid-term Scheduler that temporarily arithmetical, logical, and input/output operations of the system removes processes from main memory and places them on while a scheduling algorithm is used by the CPU to handle every process. The authors also tackled different scheduling disciplines secondary memory (such as a disk drive) or vice versa. and examples were provided in each algorithm in order to know Last is the Short Term Scheduler that decides which of the which algorithm is appropriate for various CPU goals. ready, in-memory processes are to be executed. Keywords: Kernel, Process State, Schedulers, Scheduling Algorithm, Utilization. 2. CPU Utilization 1. Introduction In order for a computer to be able to handle multiple applications simultaneously there must be an effective way The central processing unit (CPU) is a component of a of using the CPU. -
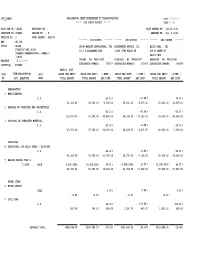
Bid Check Report * * * Time: 14:04
DOT_RGGB01 WASHINGTON STATE DEPARTMENT OF TRANSPORTATION DATE: 05/28/2013 * * * BID CHECK REPORT * * * TIME: 14:04 PS &E JOB NO : 11W101 REVISION NO : BIDS OPENED ON : Jun 26 2013 CONTRACT NO : 008498 REGION NO : 9 AWARDED ON : Jul 1 2013 VERSION NO : 2 WORK ORDER# : XL4078 ------- LOW BIDDER ------- ------- 2ND BIDDER ------- ------- 3RD BIDDER ------- HWY : SR 104 TITLE : SR104 ORION MARINE CONTRACTORS, INC. BLACKWATER MARINE, LLC QUIGG BROS., INC. KINGSTON TML SLIPS 1112 E ALEXANDER AVE 12019 76TH PLACE NE 819 W STATE ST DOLPHIN PRESERVATION - PHASE 4 98520-5934 11W101 PROJECT : NH-2013(079) TACOMA WA 984214102 KIRKLAND WA 980342437 ABERDEEN WA 985200281 COUNTY(S) : KITSAP CONTRACTOR NUMBER : 100767 CONTRACTOR NUMBER : 100874 CONTRACTOR NUMBER : 680000 ENGR'S. EST. ITEM ITEM DESCRIPTION UNIT PRICE PER UNIT/ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ PRICE PER UNIT/ % DIFF./ NO. EST. QUANTITY MEAS TOTAL AMOUNT TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. TOTAL AMOUNT AMT.DIFF. PREPARATION 1 MOBILIZATION L.S. -25.20 % -25.48 % 40.00 % 25,000.00 18,700.00 -6,300.00 18,630.00 -6,370.00 35,000.00 10,000.00 2 REMOVAL OF STRUCTURE AND OBSTRUCTION L.S. -56.10 % -65.08 % -56.71 % 115,500.00 50,700.00 -64,800.00 40,338.00 -75,162.00 50,000.00 -65,500.00 3 DISPOSAL OF CREOSOTED MATERIAL L.S. -21.05 % -8.99 % -15.79 % 47,500.00 37,500.00 -10,000.00 43,228.35 -4,271.65 40,000.00 -7,500.00 STRUCTURE 4 STRUCTURAL LOW ALLOY STEEL - DOLPHINS L.S. -

IEEE Std 1003.1-2008
This preview is downloaded from www.sis.se. Buy the entire standard via https://www.sis.se/std-911530 INTERNATIONAL ISO/IEC/ STANDARD IEEE 9945 First edition 2009-09-15 Information technology — Portable Operating System Interface (POSIX®) Base Specifications, Issue 7 Technologies de l'information — Spécifications de base de l'interface pour la portabilité des systèmes (POSIX ®), Issue 7 Reference number ISO/IEC/IEEE 9945:2009(E) Copyright © 2001-2008, IEEE and The Open Group. All rights reserved This preview is downloaded from www.sis.se. Buy the entire standard via https://www.sis.se/std-911530 ISO/IEC/IEEE 9945:2009(E) PDF disclaimer This PDF file may contain embedded typefaces. In accordance with Adobe's licensing policy, this file may be printed or viewed but shall not be edited unless the typefaces which are embedded are licensed to and installed on the computer performing the editing. In downloading this file, parties accept therein the responsibility of not infringing Adobe's licensing policy. Neither the ISO Central Secretariat nor IEEE accepts any liability in this area. Adobe is a trademark of Adobe Systems Incorporated. Details of the software products used to create this PDF file can be found in the General Info relative to the file; the PDF-creation parameters were optimized for printing. Every care has been taken to ensure that the file is suitable for use by ISO member bodies and IEEE members. In the unlikely event that a problem relating to it is found, please inform the ISO Central Secretariat or IEEE at the address given below. -

The Different Unix Contexts
The different Unix contexts • User-level • Kernel “top half” - System call, page fault handler, kernel-only process, etc. • Software interrupt • Device interrupt • Timer interrupt (hardclock) • Context switch code Transitions between contexts • User ! top half: syscall, page fault • User/top half ! device/timer interrupt: hardware • Top half ! user/context switch: return • Top half ! context switch: sleep • Context switch ! user/top half Top/bottom half synchronization • Top half kernel procedures can mask interrupts int x = splhigh (); /* ... */ splx (x); • splhigh disables all interrupts, but also splnet, splbio, splsoftnet, . • Masking interrupts in hardware can be expensive - Optimistic implementation – set mask flag on splhigh, check interrupted flag on splx Kernel Synchronization • Need to relinquish CPU when waiting for events - Disk read, network packet arrival, pipe write, signal, etc. • int tsleep(void *ident, int priority, ...); - Switches to another process - ident is arbitrary pointer—e.g., buffer address - priority is priority at which to run when woken up - PCATCH, if ORed into priority, means wake up on signal - Returns 0 if awakened, or ERESTART/EINTR on signal • int wakeup(void *ident); - Awakens all processes sleeping on ident - Restores SPL a time they went to sleep (so fine to sleep at splhigh) Process scheduling • Goal: High throughput - Minimize context switches to avoid wasting CPU, TLB misses, cache misses, even page faults. • Goal: Low latency - People typing at editors want fast response - Network services can be latency-bound, not CPU-bound • BSD time quantum: 1=10 sec (since ∼1980) - Empirically longest tolerable latency - Computers now faster, but job queues also shorter Scheduling algorithms • Round-robin • Priority scheduling • Shortest process next (if you can estimate it) • Fair-Share Schedule (try to be fair at level of users, not processes) Multilevel feeedback queues (BSD) • Every runnable proc. -

Windows Command Prompt Cheatsheet
Windows Command Prompt Cheatsheet - Command line interface (as opposed to a GUI - graphical user interface) - Used to execute programs - Commands are small programs that do something useful - There are many commands already included with Windows, but we will use a few. - A filepath is where you are in the filesystem • C: is the C drive • C:\user\Documents is the Documents folder • C:\user\Documents\hello.c is a file in the Documents folder Command What it Does Usage dir Displays a list of a folder’s files dir (shows current folder) and subfolders dir myfolder cd Displays the name of the current cd filepath chdir directory or changes the current chdir filepath folder. cd .. (goes one directory up) md Creates a folder (directory) md folder-name mkdir mkdir folder-name rm Deletes a folder (directory) rm folder-name rmdir rmdir folder-name rm /s folder-name rmdir /s folder-name Note: if the folder isn’t empty, you must add the /s. copy Copies a file from one location to copy filepath-from filepath-to another move Moves file from one folder to move folder1\file.txt folder2\ another ren Changes the name of a file ren file1 file2 rename del Deletes one or more files del filename exit Exits batch script or current exit command control echo Used to display a message or to echo message turn off/on messages in batch scripts type Displays contents of a text file type myfile.txt fc Compares two files and displays fc file1 file2 the difference between them cls Clears the screen cls help Provides more details about help (lists all commands) DOS/Command Prompt help command commands Source: https://technet.microsoft.com/en-us/library/cc754340.aspx. -

Humidity Definitions
ROTRONIC TECHNICAL NOTE Humidity Definitions 1 Relative humidity Table of Contents Relative humidity is the ratio of two pressures: %RH = 100 x p/ps where p is 1 Relative humidity the actual partial pressure of the water vapor present in the ambient and ps 2 Dew point / Frost the saturation pressure of water at the temperature of the ambient. point temperature Relative humidity sensors are usually calibrated at normal room temper - 3 Wet bulb ature (above freezing). Consequently, it generally accepted that this type of sensor indicates relative humidity with respect to water at all temperatures temperature (including below freezing). 4 Vapor concentration Ice produces a lower vapor pressure than liquid water. Therefore, when 5 Specific humidity ice is present, saturation occurs at a relative humidity of less than 100 %. 6 Enthalpy For instance, a humidity reading of 75 %RH at a temperature of -30°C corre - 7 Mixing ratio sponds to saturation above ice. by weight 2 Dew point / Frost point temperature The dew point temperature of moist air at the temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to water (liquid). The frost point temperature of moist air at temperature T, pressure P b and mixing ratio r is the temperature to which air must be cooled in order to be saturated with respect to ice. Magnus Formula for dew point (over water): Td = (243.12 x ln (pw/611.2)) / (17.62 - ln (pw/611.2)) Frost point (over ice): Tf = (272.62 x ln (pi/611.2)) / (22.46 - -

Chapter 3: Processes
Chapter 3: Processes Operating System Concepts – 9th Edition Silberschatz, Galvin and Gagne ©2013 Chapter 3: Processes Process Concept Process Scheduling Operations on Processes Interprocess Communication Examples of IPC Systems Communication in Client-Server Systems Operating System Concepts – 9th Edition 3.2 Silberschatz, Galvin and Gagne ©2013 Objectives To introduce the notion of a process -- a program in execution, which forms the basis of all computation To describe the various features of processes, including scheduling, creation and termination, and communication To explore interprocess communication using shared memory and message passing To describe communication in client-server systems Operating System Concepts – 9th Edition 3.3 Silberschatz, Galvin and Gagne ©2013 Process Concept An operating system executes a variety of programs: Batch system – jobs Time-shared systems – user programs or tasks Textbook uses the terms job and process almost interchangeably Process – a program in execution; process execution must progress in sequential fashion Multiple parts The program code, also called text section Current activity including program counter, processor registers Stack containing temporary data Function parameters, return addresses, local variables Data section containing global variables Heap containing memory dynamically allocated during run time Operating System Concepts – 9th Edition 3.4 Silberschatz, Galvin and Gagne ©2013 Process Concept (Cont.) Program is passive entity stored on disk (executable -

Your Performance Task Summary Explanation
Lab Report: 11.2.5 Manage Files Your Performance Your Score: 0 of 3 (0%) Pass Status: Not Passed Elapsed Time: 6 seconds Required Score: 100% Task Summary Actions you were required to perform: In Compress the D:\Graphics folderHide Details Set the Compressed attribute Apply the changes to all folders and files In Hide the D:\Finances folder In Set Read-only on filesHide Details Set read-only on 2017report.xlsx Set read-only on 2018report.xlsx Do not set read-only for the 2019report.xlsx file Explanation In this lab, your task is to complete the following: Compress the D:\Graphics folder and all of its contents. Hide the D:\Finances folder. Make the following files Read-only: D:\Finances\2017report.xlsx D:\Finances\2018report.xlsx Complete this lab as follows: 1. Compress a folder as follows: a. From the taskbar, open File Explorer. b. Maximize the window for easier viewing. c. In the left pane, expand This PC. d. Select Data (D:). e. Right-click Graphics and select Properties. f. On the General tab, select Advanced. g. Select Compress contents to save disk space. h. Click OK. i. Click OK. j. Make sure Apply changes to this folder, subfolders and files is selected. k. Click OK. 2. Hide a folder as follows: a. Right-click Finances and select Properties. b. Select Hidden. c. Click OK. 3. Set files to Read-only as follows: a. Double-click Finances to view its contents. b. Right-click 2017report.xlsx and select Properties. c. Select Read-only. d. Click OK. e. -

Operating Systems Processes
Operating Systems Processes Eno Thereska [email protected] http://www.imperial.ac.uk/computing/current-students/courses/211/ Partly based on slides from Julie McCann and Cristian Cadar Administrativia • Lecturer: Dr Eno Thereska § Email: [email protected] § Office: Huxley 450 • Class website http://www.imperial.ac.uk/computing/current- students/courses/211/ 2 Tutorials • No separate tutorial slots § Tutorials embedded in lectures • Tutorial exercises, with solutions, distributed on the course website § You are responsible for studying on your own the ones that we don’t cover during the lectures § Let me know if you have any questions or would like to discuss any others in class 3 Tutorial question & warmup • List the most important resources that must be managed by an operating system in the following settings: § Supercomputer § Smartphone § ”Her” A lonely writer develops an unlikely relationship with an operating system designed to meet his every need. Copyright IMDB.com 4 Introduction to Processes •One of the oldest abstractions in computing § An instance of a program being executed, a running program •Allows a single processor to run multiple programs “simultaneously” § Processes turn a single CPU into multiple virtual CPUs § Each process runs on a virtual CPU 5 Why Have Processes? •Provide (the illusion of) concurrency § Real vs. apparent concurrency •Provide isolation § Each process has its own address space •Simplicity of programming § Firefox doesn’t need to worry about gcc •Allow better utilisation of machine resources § Different processes require different resources at a certain time 6 Concurrency Apparent Concurrency (pseudo-concurrency): A single hardware processor which is switched between processes by interleaving. -

HP Decset for Openvms Guide to the Module Management System
HP DECset for OpenVMS Guide to the Module Management System Order Number: AA–P119J–TE July 2005 This guide describes the Module Management System (MMS) and explains how to get started using its basic features. Revision/Update Information: This is a revised manual. Operating System Version: OpenVMS I64 Version 8.2 OpenVMS Alpha Version 7.3–2 or 8.2 OpenVMS VAX Version 7.3 Windowing System Version: DECwindows Motif for OpenVMS I64 Version 1.5 DECwindows Motif for OpenVMS Alpha Version 1.3–1 or 1.5 DECwindows Motif for OpenVMS VAX Version 1.2–6 Software Version: HP DECset Version 12.7 for OpenVMS Hewlett-Packard Company Palo Alto, California © Copyright 2005 Hewlett-Packard Development Company, L.P. Confidential computer software. Valid license from HP required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor’s standard commercial license. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Intel and Itanium are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Java is a US trademark of Sun Microsystems, Inc. Microsoft, Windows, and Windows NT are U.S. registered trademarks of Microsoft Corporation. -

Linux Hardening Techniques Vasudev Baldwa Ubnetdef, Spring 2021 Agenda
Linux Hardening Techniques Vasudev Baldwa UBNetDef, Spring 2021 Agenda 1. What is Systems Hardening? 2. Basic Principles 3. Updates & Encryption 4. Monitoring 5. Services 6. Firewalls 7. Logging What is System Hardening? ⬡ A collection of tools, techniques, and best practices to reduce vulnerability in technology applications, systems, infrastructure, firmware, and other areas ⬡ 3 major areas: OS vs Software vs Network ⬠ When have we done hardening in this class before? ⬠ This lecture is focusing mostly on OS and software level Why Harden? ⬡ Firewalls can only get us so far, what happens when at attack is inside the network? ⬠ If you have nothing protecting your systems you are in trouble ⬡ We want some kind of secondary protection A Few Cybersecurity Principles ⬡ Zero Trust Security ⬠ Instead of assuming everything behind the firewall is safe, Zero Trust verifies each request as though it originates from an unsecure network ⬡ Principle of Least Privilege ⬠ Only privileges needed to complete a task should be allowed ⬠ Users should not have domain administrator/root privileges ⬡ Principle of Least Common Mechanism ⬠ Mechanisms used to access resources should not be shared in order to avoid the transmission of data. ⬠ Shared resources should not be used to access resources The Threat Model ⬡ A process by which potential threats can be identified and prioritized. ⬠ If you have a web server that feeds input to a mysql database, then protecting against mysql injections would be prioritized in your model. 2 considerations ⬡ *nix like is a very -

Unix / Linux Processes Management
UUNNIIXX // LLIINNUUXX -- PPRROOCCEESSSSEESS MMAANNAAGGEEMMEENNTT http://www.tutorialspoint.com/unix/unix-processes.htm Copyright © tutorialspoint.com Advertisements In this chapter, we will discuss in detail about process management in Unix. When you execute a program on your Unix system, the system creates a special environment for that program. This environment contains everything needed for the system to run the program as if no other program were running on the system. Whenever you issue a command in Unix, it creates, or starts, a new process. When you tried out the ls command to list the directory contents, you started a process. A process, in simple terms, is an instance of a running program. The operating system tracks processes through a five-digit ID number known as the pid or the process ID. Each process in the system has a unique pid. Pids eventually repeat because all the possible numbers are used up and the next pid rolls or starts over. At any point of time, no two processes with the same pid exist in the system because it is the pid that Unix uses to track each process. Starting a Process When you start a process (run a command), there are two ways you can run it − Foreground Processes Background Processes Foreground Processes By default, every process that you start runs in the foreground. It gets its input from the keyboard and sends its output to the screen. You can see this happen with the ls command. If you wish to list all the files in your current directory, you can use the following command − $ls ch*.doc This would display all the files, the names of which start with ch and end with .doc − ch01-1.doc ch010.doc ch02.doc ch03-2.doc ch04-1.doc ch040.doc ch05.doc ch06-2.doc ch01-2.doc ch02-1.doc The process runs in the foreground, the output is directed to my screen, and if the ls command wants any input (which it does not), it waits for it from the keyboard.