On the Impact and Applicability of Network Edge Computing to Reduce Network Latencies of Worldwide Client Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Global Glitch: Swaths of Internet Go Down After Cloud Outage 8 June 2021, by Kelvin Chan
Global glitch: Swaths of internet go down after cloud outage 8 June 2021, by Kelvin Chan The company said in an emailed statement that it was a "technical issue" and "not related to a cyber attack." Still, major futures markets in the U.S. dipped sharply minutes after the outage, which came a month after hackers forced the shutdown of the biggest fuel pipeline in the U.S. Fastly is a content-delivery network, or CDN. It provides vital but behind-the-scenes cloud computing "edge servers" to many of the web's popular sites. These servers store, or "cache," content such as images and video in places around the world so that it is closer to users, allowing them to fetch it more quickly and smoothly. This Jan. 17, 2001 file photo shows people entering CNN Center, the headquarters for CNN, in downtown Atlanta. Numerous websites were unavailable on Fastly says its services mean that a European user Tuesday June 8, 2021, after an apparent widespread going to an American website can get the content outage at cloud service company Fastly. Dozens of high- 200 to 500 milliseconds faster. traffic websites including the New York Times, CNN, Twitch and the U.K. government's home page, could not be reached. Credit: AP Photo/Ric Feld, File Dozens of websites went down briefly around the globe Tuesday, including CNN, The New York Times and Britain's government home page, after an outage at the cloud computing service Fastly, illustrating how vital a small number of behind-the- scenes companies have become to running the internet. -

Public Company Analysis 6
MOBILE SMART FUNDAMENTALS MMA MEMBERS EDITION NOVEMBER 2014 messaging . advertising . apps . mcommerce www.mmaglobal.com NEW YORK • LONDON • SINGAPORE • SÃO PAULO MOBILE MARKETING ASSOCIATION NOVEMBER 2014 REPORT Measurement & Creativity Thoughts for 2015 Very simply, mobile marketing will continue to present the highest growth opportunities for marketers faced with increasing profitability as well as reaching and engaging customers around the world. Widely acknowledged to be the channel that gets you the closest to your consumers, those marketers that leverage this uniqueness of mobile will gain competitive footholds in their vertical markets, as well as use mobile to transform their marketing and their business. The MMA will be focused on two cores issues which we believe will present the biggest opportunities and challenges for marketers and the mobile industry in 2015: Measurement and Creativity. On the measurement side, understanding the effectiveness of mobile: the ROI of a dollar spent and the optimized level for mobile in the marketing mix will become more and more critical as increased budgets are being allocated towards mobile. MMA’s SMoX (cross media optimization research) will provide the first-ever look into this. Additionally, attribution and understanding which mobile execution (apps, video, messaging, location etc…) is working for which mobile objective will be critical as marketers expand their mobile strategies. On the Creative side, gaining a deeper understanding of creative effectiveness cross-screen and having access to case studies from marketers that are executing some beautiful campaigns will help inspire innovation and further concentration on creating an enhanced consumer experience specific to screen size. We hope you’ve had a successful 2014 and we look forward to being a valuable resource to you again in 2015. -

A View from the Edge: a Stub-AS Perspective of Traffic Localization
A View From the Edge: A Stub-AS Perspective of Traffic Localization and its Implications Bahador Yeganeh Reza Rejaie Walter Willinger University of Oregon University of Oregon NIKSUN, Inc. [email protected] [email protected] [email protected] Abstract—Serving user requests from near-by caches or servers to implement their business model for getting content closer has been a powerful technique for localizing Internet traffic with to the end users. For example, while Akamai [1] operates and the intent of providing lower delay and higher throughput to maintains a global infrastructure consisting of more then 200K end users while also lowering the cost for network operators. This basic concept has led to the deployment of different types of servers located in more than 1.5K different ASes to bring the infrastructures of varying degrees of complexity that large CDNs, requested content by its customers closer to the edge of the ISPs, and content providers operate to localize their user traffic. network where this content is consumed, other CDNs such Prior measurement studies in this area have focused mainly on as Limelight or EdgeCast rely on existing infrastructure in revealing these deployed infrastructures, reverse-engineering the the form of large IXPs to achieve this task [2]. Similar to techniques used by these companies to map end users to close- by caches or servers, or evaluating the performance benefits that Akamai but smaller in scale, major CPs such as Google and “typical” end users experience from well-localized traffic. Netflix negotiate with third-party networks to deploy their own To our knowledge, there has been no empirical study that caches or servers that are then used to serve exclusively the assesses the nature and implications of traffic localization as CP’s own content. -

Domain Shadowing: Leveraging Content Delivery Networks for Robust Blocking-Resistant Communications
Domain Shadowing: Leveraging Content Delivery Networks for Robust Blocking-Resistant Communications Mingkui Wei Cybersecurity Engineering George Mason University, Fairfax, VA, 22030 Abstract according to the Host header but have the TLS connection still appear to belong to the allowed domain. The blocking- We debut domain shadowing, a novel censorship evasion resistance of domain fronting derives from the significant technique leveraging content delivery networks (CDNs). Do- “collateral damage”, i.e., to disable domain fronting, the censor main shadowing exploits the fact that CDNs allow their cus- needs to block users from accessing the entire CDN, resulting tomers to claim arbitrary domains as the back-end. By set- in all domains on the CDN inaccessible. Because today’s ting the front-end of a CDN service as an allowed domain Internet relies heavily on web caches and many high-profile and the back-end a blocked one, a censored user can access websites also use CDNs to distribute their content, completely resources of the blocked domain with all “indicators”, includ- blocking access to a particular CDN may not be a feasible ing the connecting URL, the SNI of the TLS connection, and option for the censor. Because of its strong blocking-resistant the Host header of the HTTP(S) request, appear to belong power, domain fronting has been adopted by many censorship to the allowed domain. Furthermore, we demonstrate that evasion systems since it has been proposed [24, 28, 34, 36]. domain shadowing can be proliferated by domain fronting, In the last two years, however, many CDNs began to disable a censorship evasion technique popularly used a few years domain fronting by enforcing the match between the SNI and ago, making it even more difficult to block. -

Exploring the Interplay Between CDN Caching and Video Streaming Performance
Exploring the interplay between CDN caching and video streaming performance Ehab Ghabashneh and Sanjay Rao Purdue University Abstract—Content Delivery Networks (CDNs) are critical for our goal of understanding performance implications for such optimizing Internet video delivery. In this paper, we characterize videos. For each chunk in a video session, our measurements how CDNs serve video content, and the implications for video characterize where in the CDN hierarchy (or origin) the chunk performance, especially emerging 4K video streaming. Our work is based on measurements of multiple well known video pub- is served from, the application-perceived throughput, the chunk lishers served by top CDNs. Our results show that (i) video size, and the latency incurred before each chunk is received. chunks in a session often see heterogeneous behavior in terms of Our results show that it is common for chunks in a video whether they hit in the CDN, and which layer they are served session to be served from different layers in the CDN hierarchy from; and (ii) application throughput can vary significantly even or the origin. Further, while there is a higher tendency for across chunks in a session based on where they are served from. The differences while sensitive to client location and CDN can chunks at the start of a session to be served from edge locations, sometimes be significant enough to impact the viability of 4K even chunks later in the session may be served from multiple streaming. We consider the implications for Adaptive bit rate locations. Interestingly, some sessions may exhibit significant (ABR) algorithms given they rely on throughput prediction, and switching in terms of the location from which consecutive are agnostic to whether objects hit in the CDN and where. -
3000 Applications
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -
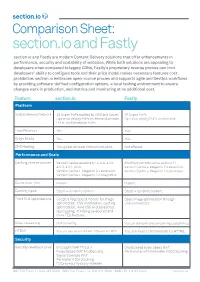
Section.Io and Fastly
Comparison Sheet: section.io and Fastly section.io and Fastly are modern Content Delivery solutions that offer enhancements in performance, security and scalability of websites. While both solutions are appealing to developers when compared to legacy CDNs, Fastly’s proprietary reverse proxies can limit developers’ ability to configure tools and their price model makes necessary features cost prohibitive. section.io embraces open-source proxies and supports agile and DevOps workflows by providing software-defined configuration options, a local testing environment to ensure changes work in production, and metrics and monitoring at no additional cost. Feature section.io Fastly Platform Global Delivery Network 29 Super PoPs backed by AWS and Azure. 35 Super PoPs. Option to deploy PoPs on demand, private Option to deploy PoPs on demand. PoPs, and Developer PoPs. Load Balancer Yes. Yes. Origin Shield Yes. Yes. DNS Hosting Yes, global Anycast network included. Not offered. PerformancePerformance + Scale and Scale Caching reverse proxies Varnish Cache versions 5.1.2, 5.0, 4.1.5, Modified Varnish Cache version 2.1 4.0.3, 4.0.1, 3.0.5 .Varnish Cache + Magento 2.x extension Varnish Cache + Magento 2.x extension Varnish Cache + Magento 1.x extension Varnish Cache + Magento 1.x integration Cache clear time Instant. Instant. Caching types Static + dynamic content. Static + dynamic content. Front End Optimizations Google’s PageSpeed module for image Basic image optimization through optimization, CSS minification, caching undisclosed tool. optimization, Inine CSS and JavaScript, lazy loading, minifying JavaScript and more FEO features. Video streaming Not currently. Yes, on demand and streaming capabilities. HTTP/2 Yes, no extra cost for HTTPS and HTTP/2. -

Fastly Blames Global Internet Outage on Software Bug 9 June 2021
Fastly blames global internet outage on software bug 9 June 2021 He said the outage was "broad and severe" but the company quickly identified, isolated and disabled the problem and after 49 minutes, most of its network was up and running again. The bug had been included in a software update that was rolled out in May and Rockwell said the company is trying to figure out why it wasn't detected during testing. "Even though there were specific conditions that triggered this outage, we should have anticipated it," Rockwell said. San Francisco-based Fastly provides what's called a content delivery network—an arrangement that allows customer websites to store data such as The Fastly home page is seen on Tuesday, June 8, images and videos on various mirror servers across 2021, in Los Angeles. Dozens of websites briefly went 26 countries. Keeping the data closer to users offline around the globe Tuesday, including CNN, The means it shows up faster. New York Times and Britain's government home page, after an outage at the cloud service Fastly. The incident But the incident highlighted how the much of the illustrates how vital a small number of behind-the-scenes global internet is dependent on a handful of behind companies have become to running the internet. Credit: the scenes companies like Fastly that provide vital AP Photo/Marcio Jose Sanchez infrastructure, and it amplified concerns about how vulnerable they are to more serious disruption. Fastly, the company hit by a major outage that © 2021 The Associated Press. All rights reserved. -

FASTLY, INC. (Exact Name of Registrant As Specified in Its Charter) ______
UNITED STATES SECURITIES AND EXCHANGE COMMISSION WASHINGTON, D.C. 20549 ____________________________ FORM 10-K ____________________________ ☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2020 or ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 Commission File Number: 001-38897 ____________________________ FASTLY, INC. (Exact name of registrant as specified in its charter) ____________________________ Delaware 27-5411834 (State or other jurisdiction of (I.R.S. Employer incorporation or organization) Identification Number) 475 Brannan Street, Suite 300 San Francisco, CA 94107 (Address of principal executive offices) (Zip code) (844) 432-7859 (Registrant's telephone number, including area code) Not Applicable (Former name, former address, or former fiscal year, if changed since last report) ____________________________ Securities registered pursuant to Section 12(b) of the Act: Title of each class Trading Symbol(s) Name of each exchange on which registered Class A Common Stock, $0.00002 par value FSLY The New York Stock Exchange Securities registered pursuant to Section 12(g) of the Act: None Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes ☒ No ☐ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or 15(d) of the Act. Yes ☐ No ☒ Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -
Annual Report John Hancock Multifactor Etfs ETF
Annual report John Hancock Multifactor ETFs ETF April 30, 2021 A message to shareholders Dear shareholder, The global equity markets were propelled to strong gains for the 12 months ended April 30, 2021. The U.S. Federal Reserve and other world central banks maintained their policies of ultra-low short-term interest rates. With little in the way of yield available on safer assets, investors gravitated toward equities in search of more attractive total returns. The approval and subsequent rollout of multiple COVID-19 vaccines also boosted investor sentiment by providing a clearer path for economic conditions to return to normal in 2021. The passing of fiscal stimulus packages in the United States was an additional source of support for the markets. In combination, these developments helped the major stock indexes gradually recapture, and ultimately exceed, the levels at which they stood prior to the global outbreak of the coronavirus in early 2020. Despite the overall good news, there are still obstacles. Some economies may have reopened too early, the pace of vaccinations varies widely from country to country, and many industries will take time to recover from the losses suffered. In these uncertain times, your financial professional can assist with positioning your portfolio so that it’s sufficiently diversified to help meet your long-term objectives and to withstand the inevitable bouts of market volatility along the way. On behalf of everyone at John Hancock Investment Management, I’d like to take this opportunity to welcome new shareholders and thank existing shareholders for the continued trust you’ve placed in us. -
![Test Plan Has Been Prepared Using the AMTSO Test Plan Template and Usage Directions, Version [2.4]](https://docslib.b-cdn.net/cover/5369/test-plan-has-been-prepared-using-the-amtso-test-plan-template-and-usage-directions-version-2-4-6065369.webp)
Test Plan Has Been Prepared Using the AMTSO Test Plan Template and Usage Directions, Version [2.4]
Cloud Web Application Firewall (WAF) CyberRisk Validation Methodology Methodology Version: Draft V1.0 Last Revision: June 02, 2021 Language: English www.secureiqlab.com Q2 2021 AMTSO Standard Compliance Statement This Test has been designed to comply with the Anti-Malware Testing Standards Organization, Inc. (“AMTSO”) Testing Protocol Standard for the Testing of Anti-Malware Solutions, Version [1.3] (the “Standard”). This Test Plan has been prepared using the AMTSO Test Plan Template and Usage Directions, Version [2.4]. SecureIQLab is solely responsible for the content of this Test Plan. TABLE OF CONTENTS 1. INTRODUCTION 2 1.1 THE NEED FOR WEB APPLICATION FIREWALL (WAF) 2 1.2 CLOUD WAF BENEFITS: 2 1.3 PROPOSED CLOUD WAF DEPLOYMENT MODELS: 2 1.4 STATEMENT OF INTENT: 3 1.5 TESTING GOALS INCLUDE: 3 1.6 CLOUD WAF FEATURES TO BE EVALUATED 3 Performance, Availability and Reliability: 3 Security Features 3 1.7 CLOUD WAF VENDOR PARTICIPATION SELECTION CRITERIA 4 1.8 SCOPE: 4 1.9 FUNDING AGREEMENT: 5 1.10 OPT-OUT POLICY 5 2. GENERAL EVALUATION APPROACH 5 2.1 CLOUD WAF SECURITY EFFECTIVENESS VALIDATION 5 Information Gathering and PUT Reconnaissance 5 Exploitation 5 Post Exploitation 6 Defense Evasion Testing 6 2.2 CLOUD WAF TEST LIFE CYCLE 6 2.3 RISK AND RISK MANAGEMENT: 7 2.4 PROPOSED ATTACK TYPES 7 2.5 ATTACK RELEVANCE: 8 2.6 GEOLIMITATIONS: 8 2.7 DISTRIBUTION OF TEST DATA: 8 3. CONTROL PROCEDURES 8 4. DEPENDENCIES 8 5. SCORE, DISPUTE PROCESS, AND EVIDENCE SETTING PROCESS 9 6. ATTESTATIONS 9 7. APPENDIX: 10 8. -

Release Notes
1 Juniper Networks Deep Packet Inspection-Decoder (Application Signature) Release Notes August 04, 2020 Contents Recent Release History | 2 Overview | 2 New Features and Enhancements | 3 New Software Features and Enhancements Introduced in JDPI-Decoder Release 3313 | 3 New Applications | 3 Updated Applications | 30 Custom Applications | 38 New or Modified Application Groups | 38 Obsolete Applications | 40 Resolved Issues | 46 Requesting Technical Support | 47 Self-Help Online Tools and Resources | 47 Creating a Service Request with JTAC | 48 Revision History | 49 2 Recent Release History Table 1 on page 2 summarizes the features and resolved issues in recent releases. You can use this table to help you decide to update the JDPI-Decoder version in your deployment. Table 1: JDPI-Decoder Features and Resolved Issues by Release Release Signature JDPI Decoder Engine Engine Date Pack Version Version Version 4 Version 5 Features and Resolved Issues Aughst The relevant 1.460.2-43 4.20.0-111 5.3.0-61 This JDPI-Decoder version is 04, 2020 signature supported only on the Junos OS package 12.3X48-D80 and later releases, version is 3313. 15.1X49-D140 and later releases, and Junos OS 17.4R1 and later releases on all supported SRX Series platforms. Starting in Junos OS release 20.1R1, enhancements to custom applications are included in the JDPI-Decoder release. Overview The JDPI-Decoder is a dynamically loadable module that mainly provides application classification functionality and associated protocol attributes. It is hosted on an external server and can be downloaded as a package and installed on the device. The package also includes XML files that contain additional details of the list of applications and groups.