New Perspectives About the Tor Ecosystem: Integrating Structure with Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Adobe Application Manager Enterprise Edition Deployment Guide
ADOBE® APPLICATION MANAGER ENTERPRISE EDITION GUIDE DE DEPLOIEMENT EN ENTREPRISE Adobe® Application Manager Enterprise Edition version 3.1 Version de document 3.1 Date du document : Septembre 2012 © 2012 Adobe Systems Incorporated and its licensors. All rights reserved. Adobe® Application Manager Enterprise Edition Guide de déploiement en entreprise This guide is licensed for use under the terms of the Creative Commons Attribution Non-Commercial 3.0 License. This License allows users to copy, distribute, and transmit the guide for noncommercial purposes only so long as (1) proper attribution to Adobe is given as the owner of the guide; and (2) any reuse or distribution of the guide contains a notice that use of the guide is governed by these terms. The best way to provide notice is to include the following link. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/3.0/ Adobe, the Adobe logo, Acrobat, Adobe Audition, Adobe Bridge, Adobe Device Central, Adobe OnLocation, Adobe Premiere, Adobe Premiere Pro, Adobe Technical Communication Suite, After Effects, Contribute, Captivate, Creative Suite, CS Live, Dreamweaver, Encore, Fireworks, Flash, Flash Builder, Flash Catalyst, FrameMaker, Illustrator, InDesign, Photoshop, RoboHelp, SiteCatalyst, and Soundbooth are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Apple, Mac, and Mac OS are trademarks of Apple Inc., registered in the United States and other countries. Microsoft, Windows, and Windows Vista are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. UNIX is a registered trademark of The Open Group in the US and other countries. -
Maximum Internet Security: a Hackers Guide - Networking - Intrusion Detection
- Maximum Internet Security: A Hackers Guide - Networking - Intrusion Detection Exact Phrase All Words Search Tips Maximum Internet Security: A Hackers Guide Author: Publishing Sams Web Price: $49.99 US Publisher: Sams Featured Author ISBN: 1575212684 Benoît Marchal Publication Date: 6/25/97 Pages: 928 Benoît Marchal Table of Contents runs Pineapplesoft, a Save to MyInformIT consulting company that specializes in Internet applications — Now more than ever, it is imperative that users be able to protect their system particularly e-commerce, from hackers trashing their Web sites or stealing information. Written by a XML, and Java. In 1997, reformed hacker, this comprehensive resource identifies security holes in Ben co-founded the common computer and network systems, allowing system administrators to XML/EDI Group, a think discover faults inherent within their network- and work toward a solution to tank that promotes the use those problems. of XML in e-commerce applications. Table of Contents I Setting the Stage 1 -Why Did I Write This Book? 2 -How This Book Will Help You Featured Book 3 -Hackers and Crackers Sams Teach 4 -Just Who Can Be Hacked, Anyway? Yourself Shell II Understanding the Terrain Programming in 5 -Is Security a Futile Endeavor? 24 Hours 6 -A Brief Primer on TCP/IP 7 -Birth of a Network: The Internet Take control of your 8 -Internet Warfare systems by harnessing the power of the shell. III Tools 9 -Scanners 10 -Password Crackers 11 -Trojans 12 -Sniffers 13 -Techniques to Hide One's Identity 14 -Destructive Devices IV Platforms -

The Current Economics of Cyber Attacks
The Current Economics of Cyber Attacks Ron Winward Security Evangelist October 17, 2016 What Are We Talking About Historical Context Does Hacking Pay? Cyber Aack Marketplace Economics of Defenses: Reality Check 2 Once Upon a Time… 3 Story of the Automobile Ideal economic condions help fuel and grow this industry Be&er Roads Assembly Line Ideal Economic Condi9ons Growth 4 Cyber Attacks Reaching a Tipping Point More Resources More Targets More Mature Availability of low More high value, A level of maturity cost resources increasingly vulnerable that drives efficiency targets leads to more and ensures valuable informaon anonymity The economics of hacking have turned a corner! 5 Modern Economics of Cyber Attacks and Hacking 6 Do You Romanticize Hackers? 7 Reality of Today’s Hackers May look more like this . than like this 8 Today’s Adversary: Not always the Lone Wolf Structured organizaon with roles, focus Premeditated plan for targe9ng, exfiltraon, mone9zaon of data/assets Mul9-layered trading networks for distribu9on, Source: HPE: the business of hacking obfuscaon Why? Because increasingly, CRIME PAYS! 9 Or Does It? The average aacker earns approximately ¼ of the salary of an average IT employee The cost and 9me to plan aacks has decreased Be&er access to be&er tools makes aacks easier Remember: Nobody is trying to be “average” 10 Sophisticated Understanding of Value Mone9zable criminal enterprise Credit Cards Medical Records Intellectual Property Creden9als Vulnerabili9es Exploits 11 The Economics of Web Attacks Hacker steals US healthcare -

The Internet and Drug Markets
INSIGHTS EN ISSN THE INTERNET AND DRUG MARKETS 2314-9264 The internet and drug markets 21 The internet and drug markets EMCDDA project group Jane Mounteney, Alessandra Bo and Alberto Oteo 21 Legal notice This publication of the European Monitoring Centre for Drugs and Drug Addiction (EMCDDA) is protected by copyright. The EMCDDA accepts no responsibility or liability for any consequences arising from the use of the data contained in this document. The contents of this publication do not necessarily reflect the official opinions of the EMCDDA’s partners, any EU Member State or any agency or institution of the European Union. Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) The information given is free, as are most calls (though some operators, phone boxes or hotels may charge you). More information on the European Union is available on the internet (http://europa.eu). Luxembourg: Publications Office of the European Union, 2016 ISBN: 978-92-9168-841-8 doi:10.2810/324608 © European Monitoring Centre for Drugs and Drug Addiction, 2016 Reproduction is authorised provided the source is acknowledged. This publication should be referenced as: European Monitoring Centre for Drugs and Drug Addiction (2016), The internet and drug markets, EMCDDA Insights 21, Publications Office of the European Union, Luxembourg. References to chapters in this publication should include, where relevant, references to the authors of each chapter, together with a reference to the wider publication. For example: Mounteney, J., Oteo, A. and Griffiths, P. -

Fraud and the Darknets
OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud And The Darknets Thomas Harper Assistant Special Agent in Charge Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division What is an OIG? • Established by Congress • Independent agency that reports to Congress • Agency head appointed by the President and confirmed by Congress • Mission: protect the taxpayer’s interests by ensuring the integrity and efficiency of the associated agency OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Technology Crimes Division • Investigate criminal cyber threats against the Department’s IT infrastructure, or • Criminal activity in cyber space that threatens the Department’s administration of Federal education assistance funds • Investigative jurisdiction encompasses any IT system used in the administration of Federal money originating from the Department of Education. OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Work Examples • Grade hacking • Computer Intrusions • Criminal Forums online selling malware • ID/Credential theft to hijack Student Aid applications • Misuse of Department systems to obtain personal information • Falsifying student aid applications by U.S. government employees • Child Exploitation material trafficking OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud and the Darknets Special Thanks to Financial Crimes Enforcement Network (FINCEN) OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division Fraud and the Darknets OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. Department of Education Technology Crimes Division OFFICE OF THE INSPECTOR GENERAL U.S. -

Into the Reverie: Exploration of the Dream Market
Into the Reverie: Exploration of the Dream Market Theo Carr1, Jun Zhuang2, Dwight Sablan3, Emma LaRue4, Yubao Wu5, Mohammad Al Hasan2, and George Mohler2 1Department of Mathematics, Northeastern University, Boston, MA 2Department of Computer & Information Science, Indiana University - Purdue University, Indianapolis, IN 3Department of Mathematics and Computer Science, University of Guam, Guam 4Department of Mathematics and Statistics, University of Arkansas at Little Rock, AK 5Department of Computer Science, Georgia State University, Atlanta, GA [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract—Since the emergence of the Silk Road market in Onymous" in 2014, a worldwide action taken by law enforce- the early 2010s, dark web ‘cryptomarkets’ have proliferated and ment and judicial agencies aimed to put a kibosh on these offered people an online platform to buy and sell illicit drugs, illicit behaviors [5]. Law enforcement interventions such as relying on cryptocurrencies such as Bitcoin for anonymous trans- actions. However, recent studies have highlighted the potential for Onymous, along with exit scams and hacks, have successfully de-anonymization of bitcoin transactions, bringing into question shut down numerous cryptomarkets, including AlphaBay, Silk the level of anonymity afforded by cryptomarkets. We examine a Road, Dream, and more recently, Wall Street [6]. Despite these set of over 100,000 product reviews from several cryptomarkets interruptions, new markets have continued to proliferate. The collected in 2018 and 2019 and conduct a comprehensive analysis authors of [7] note that there appears to be a consistent daily of the markets, including an examination of the distribution of drug sales and revenue among vendors, and a comparison demand of about $500,000 for illicit products on the dark web, of incidences of opioid sales to overdose deaths in a US city. -

Abstract Introduction Methodology
Kajetan Hinner (2000): Statistics of major IRC networks: methods and summary of user count. M/C: A Journal of Media and Culture 3(4). <originally: http://www.api-network.com/mc/0008/count.html> now: http://www.media-culture.org.au/0008/count.html - Actual figures and updates: www.hinner.com/ircstat/ Abstract The article explains a successful approach to monitor the major worldwide Internet Relay Chat (IRC) networks. It introduces a new research tool capable of producing detailed and accurate statistics of IRC network’s user count. Several obsolete methods are discussed before the still ongoing Socip.perl program is explained. Finally some IRC statistics are described, like development of user figures, their maximum count, IRC channel figures, etc. Introduction Internet Relay Chat (IRC) is a text-based service, where people can meet online and chat. All chat is organized in channels which a specific topic, like #usa or #linux. A user can be taking part in several channels when connected to an IRC network. For a long time the only IRC network has been EFnet (Eris-Free Network, named after its server eris.berkeley.edu), founded in 1990. The other three major IRC networks are Undernet (1993), DALnet (1994) and IRCnet, which split off EFnet in June 1996. All persons connecting to an IRC network at one time create that IRC network’s user space. People are constantly signing on and off, the total number of users ever been to a specific IRC network could be called social space of that IRC network. It is obvious, that the IRC network’s social space by far outnumbers its user space. -

Users As Co-Designers of Software-Based Media: the Co-Construction of Internet Relay Chat
Users as Co-Designers of Software-Based Media: The Co-Construction of Internet Relay Chat Guillaume Latzko-Toth Université Laval AbsTrAcT While it has become commonplace to present users as co-creators or “produsers” of digital media, their participation is generally considered in terms of content production. The case of Internet Relay Chat (IRC) shows that users can be fully involved in the design process, a co-construction in the sense of Science and Technology Studies (STS): a collective, simultaneous, and mutual construction of actors and artifacts. A case study of the early de - velopment of two IRC networks sheds light on that process and shows that “ordinary users” managed to invite themselves as co-designers of the socio-technical device. The article con - cludes by suggesting that IRC openness to user agency is not an intrinsic property of software- based media and has more to do with its architecture and governance structure. Keywords Digital media; Communication technology; Co-construction; Design process; Ordinary user résumé Il est devenu banal de présenter l’usager comme cocréateur ou « produtilisateur » des médias numériques, mais sa participation est généralement envisagée comme une production de contenus. Le cas d’IRC (Internet Relay Chat) montre que les usagers des médias à support logiciel peuvent s’engager pleinement dans le processus de conception, une co-construction au sens des Science and Technology Studies : une construction collective, simultanée et mutuelle des acteurs et des artefacts. Une étude de cas portant sur le développement de deux réseaux IRC éclaire ce processus et montre que les « usagers ordinaires » sont parvenus à s’inviter comme co-concepteurs du dispositif. -

Myagora Parent Update for January 4, 2018
myAgora Parent Update for January 4, 2018 Subscribe Past Issues Translate RSS View this email in your browser Welcome Back! One Last Final Reminder: Deadline to Submit Fall ISP Rebate is January 5! Friday, January 5 is the deadline to submit your internet bill for the Fall ISP Rebate! Parents/legal guardians can log in to the Sapphire Community Web Portal to submit for the Fall Rebate period which covers September through December and is due by January 5, 2018. Fall rebate checks will be mailed January 31, 2018. Watch this video for step-by-step instructions on how to submit your ISP rebate. Additional information can be found on our website at https://agora.org/pupil-parent- services/isp-rebate-program/ https://us13.campaign-archive.com/?u=2a591de2a33ed5c751ca978a2&id=205e786611[1/23/2018 3:10:45 PM] myAgora Parent Update for January 4, 2018 PLEASE NOTE: We cannot accept Internet bills submitted by email, fax, mail or Agora Staff on behalf of families. If you need help setting up your Sapphire account, visit our Resources & Guides page on the Agora.org website https://agora.org/resources-and- guides/ Time to RSVP For National School Choice Events! Parents at Agora know that school choice is one of the most important decisions you'll make for your child so we are joining with schools all across this country to celebrate! During the last week in January and into early February, Agora will be part of these special events to raise public awareness of the different K-12 education options available to children and families, while spotlighting the benefits of school choice. -

Guia Rápido Firefox, Pegue O Seu Aqui: Personalizar
ARQUIVO HISTÓRICO no topo da página. Você pode desbloqueá-lo ou não, clicando Nova Janela Ctrl N Voltar Alt ¬ no botão Opções da barra. Para liberar todos os Popup, Nova Aba Ctrl T Avançar Alt ® escolha em Preferências/Opções, Conteúdo e ligue ou Abrir endereço... Ctrl L Página Inicial Alt Home desligue a opção Bloquear Janelas Popup. Curso a Distância e Grátis – você pode fazer o curso Abrir Arquivo... Ctrl O Exibir todo o histórico Ctrl Shift H do Firefox a distância e de graça no site www.cdtc.org.br (p/ Fechar Janela Alt F4 ou Ctrl Shift W Reabrir Aba todos) e em http://cursos.cdtc.org.br (p/ funcionário público). Fechar Aba Ctrl F4 ou Ctrl W FAVORITOS Download do Firefox: Para fazer o download do Salvar Como... Ctrl S Adicionar página... Ctrl D programa Mozilla Firefox, acesse: www.mozilla.com/en- Enviar Endereço Inscrever RSS... US/firefox/all.html Configurar Página... Adicionar todas as abas... Ctrl Shift D Extensões: São programas adicionados ao Firefox para Visualizar Impressão Organizar Favoritos ... torná-lo mais poderoso. Você pode adicionar novos recursos e adaptar o seu Firefox ao seu estilo de navegar. A instalação Imprimir... Ctrl P Barra dos Favoritos pode ser feita a partir da opção Complementos em Importar... Favoritos recentes Ferramentas. Exemplos: Sage (leitor de RSS), Forecastfox Modo Offline Marcadores recentes (previsão do tempo), Tab Mix Plus, etc. Sair Get Bookmarks Add-ons Favorito Dinâmico – RSS: O conteúdo do favorito Mozilla Firefox dinâmico é atualizado periodicamente, não necessita visitar o EDITAR FERRAMENTAS site constantemente pra saber das novidades. -
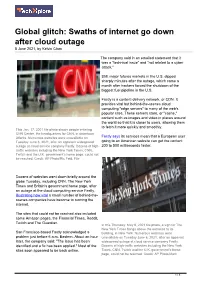
Global Glitch: Swaths of Internet Go Down After Cloud Outage 8 June 2021, by Kelvin Chan
Global glitch: Swaths of internet go down after cloud outage 8 June 2021, by Kelvin Chan The company said in an emailed statement that it was a "technical issue" and "not related to a cyber attack." Still, major futures markets in the U.S. dipped sharply minutes after the outage, which came a month after hackers forced the shutdown of the biggest fuel pipeline in the U.S. Fastly is a content-delivery network, or CDN. It provides vital but behind-the-scenes cloud computing "edge servers" to many of the web's popular sites. These servers store, or "cache," content such as images and video in places around the world so that it is closer to users, allowing them to fetch it more quickly and smoothly. This Jan. 17, 2001 file photo shows people entering CNN Center, the headquarters for CNN, in downtown Atlanta. Numerous websites were unavailable on Fastly says its services mean that a European user Tuesday June 8, 2021, after an apparent widespread going to an American website can get the content outage at cloud service company Fastly. Dozens of high- 200 to 500 milliseconds faster. traffic websites including the New York Times, CNN, Twitch and the U.K. government's home page, could not be reached. Credit: AP Photo/Ric Feld, File Dozens of websites went down briefly around the globe Tuesday, including CNN, The New York Times and Britain's government home page, after an outage at the cloud computing service Fastly, illustrating how vital a small number of behind-the- scenes companies have become to running the internet. -

Exploratory Programming for the Arts and Humanities
Exploratory Programming for the Arts and Humanities Exploratory Programming for the Arts and Humanities Second Edition Nick Montfort The MIT Press Cambridge, Massachusetts London, England © 2021 Nick Montfort The open access edition of this work was made possible by generous funding from the MIT Libraries. This work is subject to a Creative Commons CC-BY-NC-SA license. Subject to such license, all rights are reserved. This book was set in ITC Stone Serif Std and ITC Stone Sans Std by New Best-set Typesetters Ltd. Library of Congress Cataloging-in-Publication Data Names: Montfort, Nick, author. Title: Exploratory programming for the arts and humanities / Nick Montfort. Description: Second edition. | Cambridge, Massachusetts : The MIT Press, [2021] | Includes bibliographical references and index. | Summary: "Exploratory Programming for the Arts and Humanities offers a course on programming without prerequisites. It covers both the essentials of computing and the main areas in which computing applies to the arts and humanities"—Provided by publisher. Identifiers: LCCN 2019059151 | ISBN 9780262044608 (hardcover) Subjects: LCSH: Computer programming. | Digital humanities. Classification: LCC QA76.6 .M664 2021 | DDC 005.1—dc23 LC record available at https://lccn.loc.gov/2019059151 10 9 8 7 6 5 4 3 2 1 [Contents] [List of Figures] xv [Acknowledgments] xvii [1] Introduction 1 [1.1] 1 [1.2] Exploration versus Exploitation 4 [1.3] A Justification for Learning to Program? 6 [1.4] Creative Computing and Programming as Inquiry 7 [1.5] Programming Breakthroughs