Proposal to Encode Some Additional Symbols Used in Church Slavonic Text (Revision 2)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

Above the Grave of John Odenswurge
J. DUNBAR HYLTON, M. D. ABOVE THE GRATE OF John OoENS^TUiiaE, A COSMOPOLITE. BY J. DUNBAR HYLTON, M. D., AUTHOR OF "THE BRIDE OF GETTYSBURG," "ARTELOISE," "BETRAYED," "THE PR.^SIDICIDE," "THE HEIR OF LYOLYNN," ETC., ETC. NEW YORK: HOWARD CHALLEN, 744 Broadway. 1884. AND THE AUTHOR, PALMYRA, N. J. MAIS LIB. (X ho CONTENTS. Page The Lay of Mt. Vesuvius 5 Lay of the River Euphrates . - _ _ - 9 The Battle of the Dogs and Cats - - - - 23 My Jersey Girl --------37 She Waits for Me 41 To Jack 42 I Saw Her 43 - My Yankee Maid. ( The, original version) - - 45 Lost ------ 50 The Eagle 51 A Drunkard's Vision .-.-..-. 54 She 66 He 67 Leap Year ---------69 Again -----70 Song of the Sea --------72 Homer -75 Blind Old Ossian .____-- 76 510 — ; Above the Grave. THE LAY OF MT. VESUVIUS. From awful caves where discord raves With never-ending ire, From the roaring womb where thunders boom, While flames with flames aspire. From hills and glens and crypts and dens Of never-ending fire Deep in the earth, I draw my birth, And all my tumult dire. While lasts the flame in earth's vast frame I'll ne'er from her retire. With awful glow my lights I throw O'er ocean's sounding waves To ocean's flow and realms below My burning lava raves And roars, while cast in billows vast Adown my reeking sides It clears its path and fears no wrath From ought that there abides. It covers o'er forever more glen The forest, hill and ; The landscape green no more is seen, Nor homes of mortal men. -

®Lje Lournal
AA/\ Brsscuinnts for Frank bought Abe. Ilar- MARRIED. rZf\ ' I*T7. Tons of certificates of character A. A. t)v/' /' M Kvcryliody is ge.iliig THE SUN. THE ' JoUENAL . property, Millheira. I'll 11 It's VM ICItK'AN AiONTUI.Y,.! ihli- f OHlieS can Louisiana Return tsihi in ult., by Hpv. F. Iv i:lust rate I, ably Faml.y Aluga/ltie give the ? \u25a0 ' On the 28h 1877 not - \u2666 \u2666 \u2666 1377. NEW YORK. Ditley. of at omjr i vc.tr. Specimens ftct*. tint.AT ®lje Hoard even respectability, Aurand, Mr. Jnmeft 11. 'l. IIS fct. common Applet on A Muslin, nly9sct*. TRitMH TO JOHN I'OrftlUiU, during lournal P<rter twp? Clinton Co., mil* Miss I'ubv, I'm adehihiu The different editors of Tl SUN when it is known that its several Aaronsbury. (lie next year wl l !*? tliesauie as during the % Rover's in V *S NW\V\V\V\VK yard, at VV, I>er Leah iVulisa of Millnull, sain** Co. venr thai has lust passed. Tito dallyedlMon are steeper in crime : -\u2666? \u2666 psjrcs. niembeiß W. | will on week uavs be a sheet of four neighbor 1). Zerby pur- On tlioSrtl lilt.,by Itev. M. K8 T AHLIHIIED 1809. and on Sundays a sheet of eieht luges, or n6 & Madison Wells shot and mur- Our L. weekly . Proprietors. J. latum*. Mr. >Nniu't columns v while Hie edition falter Dcmicr. ; V 4 Nlnuder. & broad dp deivd a Spaniard in Rapides parMi chased Sam'l M. Swariz's property, MIKI Miss Kmtna Strohecker, all of P. -

QCMUQ@QALB-2015 Shared Task: Combining Character Level MT and Error-Tolerant Finite-State Recognition for Arabic Spelling Correction
QCMUQ@QALB-2015 Shared Task: Combining Character level MT and Error-tolerant Finite-State Recognition for Arabic Spelling Correction Houda Bouamor1, Hassan Sajjad2, Nadir Durrani2 and Kemal Oflazer1 1Carnegie Mellon University in Qatar [email protected], [email protected] 2Qatar Computing Research Institute fhsajjad,[email protected] Abstract sion, in this task participants are asked to imple- We describe the CMU-Q and QCRI’s joint ment a system that takes as input MSA (Modern efforts in building a spelling correction Standard Arabic) text with various spelling errors system for Arabic in the QALB 2015 and automatically correct it. In this year’s edition, Shared Task. Our system is based on a participants are asked to test their systems on two hybrid pipeline that combines rule-based text genres: (i) news corpus (mainly newswire ex- linguistic techniques with statistical meth- tracted from Aljazeera); (ii) a corpus of sentences ods using language modeling and machine written by learners of Arabic as a Second Lan- translation, as well as an error-tolerant guage (ASL). Texts produced by learners of ASL finite-state automata method. Our sys- generally contain a number of spelling errors. The tem outperforms the baseline system and main problem faced by them is using Arabic with achieves better correction quality with an vocabulary and grammar rules that are different F1-measure of 68.42% on the 2014 testset from their native language. and 44.02 % on the L2 Dev. In this paper, we describe our Arabic spelling correction system. Our system is based on a 1 Introduction hybrid pipeline which combines rule-based tech- With the increased usage of computers in the pro- niques with statistical methods using language cessing of various languages comes the need for modeling and machine translation, as well as an correcting errors introduced at different stages. -

Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention
Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention † † ‡ † † Huadong Chen , Shujian Huang ,∗ David Chiang , Xinyu Dai , Jiajun Chen †State Key Laboratory for Novel Software Technology, Nanjing University chenhd,huangsj,daixinyu,chenjj @nlp.nju.edu.cn { } ‡Department of Computer Science and Engineering, University of Notre Dame [email protected] Abstract of (sub)words are based purely on their contexts, but the potentially rich information inside the unit Natural language sentences, being hierarchi- itself is seldom explored. Taking the Chinese word cal, can be represented at different levels of 被打伤 (bei-da-shang) as an example, the three granularity, like words, subwords, or charac- ters. But most neural machine translation sys- characters in this word are a passive voice marker, tems require the sentence to be represented as “hit” and “wound”, respectively. The meaning of a sequence at a single level of granularity. It the whole word, “to be wounded”, is fairly com- can be difficult to determine which granularity positional. But this compositionality is ignored if is better for a particular translation task. In this the whole word is treated as a single unit. paper, we improve the model by incorporating Secondly, obtaining the word or sub-word multiple levels of granularity. Specifically, we boundaries can be non-trivial. For languages like propose (1) an encoder with character atten- tion which augments the (sub)word-level rep- Chinese and Japanese, a word segmentation step resentation with character-level information; is needed, which must usually be trained on la- (2) a decoder with multiple attentions that en- beled data. -

PC19 Inf. 12 (In English and French / En Inglés Y Francés / En Anglais Et Français)
PC19 Inf. 12 (In English and French / en inglés y francés / en anglais et français) CONVENTION ON INTERNATIONAL TRADE IN ENDANGERED SPECIES OF WILD FAUNA AND FLORA CONVENCIÓN SOBRE EL COMERCIO INTERNACIONAL DE ESPECIES AMENAZADAS DE FAUNA Y FLORA SILVESTRES CONVENTION SUR LE COMMERCE INTERNATIONAL DES ESPECES DE FAUNE ET DE FLORE SAUVAGES MENACEES D'EXTINCTION ____________ Nineteenth meeting of the Plants Committee – Geneva (Switzerland), 18-21 April 2011 Decimonovena reunión del Comité de Flora – Ginebra (Suiza), 18-21 de abril de 2011 Dix-neuvième session du Comité pour les plantes – Genève (Suisse), 18 – 21 avril 2011 PRELIMINARY REPORT ON SUSTAINABLE HARVESTING OF PRUNUS AFRICANA (ROSACEAE) IN THE NORTH WEST REGION OF CAMEROON The attached information document has been submitted by the CITES Secretariat1. El documento informativo adjunto ha sido presentado por la Secretaría CITES2. Le document d'information joint est soumis par le Secrétariat CITES3. 1 The geographical designations employed in this document do not imply the expression of any opinion whatsoever on the part of the CITES Secretariat or the United Nations Environment Programme concerning the legal status of any country, territory, or area, or concerning the delimitation of its frontiers or boundaries. The responsibility for the contents of the document rests exclusively with its author. 2 Las denominaciones geográficas empleadas en este documento no implican juicio alguno por parte de la Secretaría CITES o del Programa de las Naciones Unidas para el Medio Ambiente sobre la condición jurídica de ninguno de los países, zonas o territorios citados, ni respecto de la delimitación de sus fronteras o límites. -

Combining Character and Conversational Types in Strategic Choice
Different Games in Dialogue: Combining character and conversational types in strategic choice Alafate Abulmiti Universite´ de Paris, CNRS Laboratoire de Linguistique Formelle [email protected] Abstract We seek to develop an approach to strategic choice applicable to the general case of dialogical In this paper, we show that investigating the in- interaction, where termination is an important con- teraction of conversational type (often known sideration and where assessment is internal to the as language game or speech genre) with the character types of the interlocutors is worth- participants. Strategic choice is modelled by com- while. We present a method of calculating the bining structure from conversational types with psy- decision making process for selecting dialogue chological and cognitive notions associated with moves that combines character type and con- the players. versational type. We also present a mathemat- Character type as a relatively independent factor ical model that illustrate these factors’ interac- abstracted out of the conversational type is impor- tions in a quantitative way. tant for dialogue. Although there is some analy- 1 Introduction sis concerning both character effects and conversa- tional types in the dialogue, combining them and Wittgenstein(1953); Bakhtin(2010) introduced analyzing their interactions in a quantitative way language games/speech genres as notions tying di- has not, to our knowledge, been carried out before. versity of linguistic behaviors to activity. Build- The purposes of this paper is, hence, to combine ing on this, and insights of pragmaticists such as character type effect and conversational type anal- Hymes(1974); Allwood(2000), and earlier work ysis to yield a method that could help to analyse in AI by (Allen and Perrault, 1980; Cohen and strategic choice in dialogue. -

PHP and Unicode
PHP and Unicode Andrei Zmievski Yahoo! Inc ApacheCon US 2005 Andrei Zmievski © 2005 Agenda ✓ Multi-i18n-what? ✓ Can’t PHP do it now? ✓ Unicode ✓ How do we get it into PHP? ✓ When can I get my hands on it? PHP and Unicode Andrei Zmievski © 2005 Multi-i18n-what? ✓ There is more than one country in the world ✓ They don't all speak English! ✓ Some of them even speak French PHP and Unicode Andrei Zmievski © 2005 Definitions Character Set A collection of abstract characters or graphemes used in a certain domain ...А Б В Г Д Е Ё Ж З И... PHP and Unicode Andrei Zmievski © 2005 Definitions Character Encoding Form Representation of a character set using a number of integer codes (code values) KOI8-R: А = 225, И= 234 CP-1252: А = 192, И = 201 Unicode: А = 410, И = 418 PHP and Unicode Andrei Zmievski © 2005 Multi-i18n-what? ✓ Dealing with multiple encodings is a pain ✓ Different algorithms, conversion, detection, validation, processing... understanding ✓ Dealing with multiple languages is a pain too ✓ But cannot be avoided in this day and age PHP and Unicode Andrei Zmievski © 2005 Challenges ✓ Need to implement applications for multiple languages and cultures ✓ Perform language and encoding appropriate searching, sorting, word breaking, etc. ✓ Support date, time, number, currency, and more esoteric formatting in the specific locale ✓ And much more PHP and Unicode Andrei Zmievski © 2005 Agenda ✓ Multi-i18n-what? ✓ Can’t PHP do it now? ✓ Unicode ✓ How do we get it into PHP? ✓ When can I get my hands on it? PHP and Unicode Andrei Zmievski © 2005 Agenda -

Chapter 5. Characters: Typology and Page Encoding 1
Chapter 5. Characters: typology and page encoding 1 Chapter 5. Characters: typology and encoding Version 2.0 (16 May 2008) 5.1 Introduction PDF of chapter 5. The basic characters a-z / A-Z in the Latin alphabet can be encoded in virtually any electronic system and transferred from one system to another without loss of information. Any other characters may cause problems, even well established ones such as Modern Scandinavian ‘æ’, ‘ø’ and ‘å’. In v. 1 of The Menota handbook we therefore recommended that all characters outside a-z / A-Z should be encoded as entities, i.e. given an appropriate description and placed between the delimiters ‘&’ and ‘;’. In the last years, however, all major operating systems have implemented full Unicode support and a growing number of applications, including most web browsers, also support Unicode. We therefore believe that encoders should take full advantage of the Unicode Standard, as recommended in ch. 2.2.2 above. As of version 2.0, the character encoding recommended in The Menota handbook has been synchronised with the recommendations by the Medieval Unicode Font Initiative . The character recommendations by MUFI contain more than 1,300 characters in the Latin alphabet of potential use for the encoding of Medieval Nordic texts. As a consequence of the synchronisation, the list of entities which is part of the Menota scheme is identical to the one by MUFI. In other words, if a character is encoded with a code point or an entity in the MUFI character recommendation, it will be a valid character encoding also in a Menota text. -
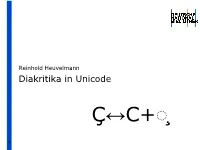
Diakritika in Unicode
Reinhold Heuvelmann Diakritika in Unicode Ç↔C+◌̧ 1 Code Charts http://www.unicode.org/charts/ , Stichwort "combining" – http://www.unicode.org/charts/PDF/U0300.pdf – http://www.unicode.org/charts/PDF/U1AB0.pdf – http://www.unicode.org/charts/PDF/U1DC0.pdf – http://www.unicode.org/charts/PDF/U20D0.pdf – http://www.unicode.org/charts/PDF/UFE20.pdf 2 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 3 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Stacking Sequences, Beispiel 1 http://www.unicode.org/versions/Unicode9.0.0/ch02.pdf 4 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Stacking Sequences, Beispiel 2 5 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Aus den FAQ zu Characters and Combining Marks Q: Why are new combinations of Latin letters with diacritical marks not suitable for addition to Unicode? A: There are several reasons. First, Unicode encodes many diacritical marks, and the combinations can already be produced, as noted in the answers to some questions above. If precomposed equivalents were added, the number of multiple spellings would be increased, and decompositions would need to be defined and maintained for them, adding to the complexity of existing decomposition tables in implementations. ... 6 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Aus den FAQ zu Characters and Combining Marks ... Finally, normalization form NFC (the composed form favored for use on the Web) is frozen—no new letter combinations can be added to it. Therefore, the normalized NFC representation of any new precomposed letters would still use decomposed sequences, which can already be expressed by combining character sequences in Unicode. -

Special Characters in Aletheia
Special Characters in Aletheia Last Change: 28 May 2014 The following table comprises all special characters which are currently available through the virtual keyboard integrated in Aletheia. The virtual keyboard aids re-keying of historical documents containing characters that are mostly unsupported in other text editing tools (see Figure 1). Figure 1: Text input dialogue with virtual keyboard in Aletheia 1.2 Due to technical reasons, like font definition, Aletheia uses only precomposed characters. If required for other applications the mapping between a precomposed character and the corresponding decomposed character sequence is given in the table as well. When writing to files Aletheia encodes all characters in UTF-8 (variable-length multi-byte representation). Key: Glyph – the icon displayed in the virtual keyboard. Unicode – the actual Unicode character; can be copied and pasted into other applications. Please note that special characters might not be displayed properly if there is no corresponding font installed for the target application. Hex – the hexadecimal code point for the Unicode character Decimal – the decimal code point for the Unicode character Description – a short description of the special character Origin – where this character has been defined Base – the base character of the special character (if applicable), used for sorting Combining Character – combining character(s) to modify the base character (if applicable) Pre-composed Character Decomposed Character (used in Aletheia) (only for reference) Combining Glyph