PHP and Unicode
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

QCMUQ@QALB-2015 Shared Task: Combining Character Level MT and Error-Tolerant Finite-State Recognition for Arabic Spelling Correction
QCMUQ@QALB-2015 Shared Task: Combining Character level MT and Error-tolerant Finite-State Recognition for Arabic Spelling Correction Houda Bouamor1, Hassan Sajjad2, Nadir Durrani2 and Kemal Oflazer1 1Carnegie Mellon University in Qatar [email protected], [email protected] 2Qatar Computing Research Institute fhsajjad,[email protected] Abstract sion, in this task participants are asked to imple- We describe the CMU-Q and QCRI’s joint ment a system that takes as input MSA (Modern efforts in building a spelling correction Standard Arabic) text with various spelling errors system for Arabic in the QALB 2015 and automatically correct it. In this year’s edition, Shared Task. Our system is based on a participants are asked to test their systems on two hybrid pipeline that combines rule-based text genres: (i) news corpus (mainly newswire ex- linguistic techniques with statistical meth- tracted from Aljazeera); (ii) a corpus of sentences ods using language modeling and machine written by learners of Arabic as a Second Lan- translation, as well as an error-tolerant guage (ASL). Texts produced by learners of ASL finite-state automata method. Our sys- generally contain a number of spelling errors. The tem outperforms the baseline system and main problem faced by them is using Arabic with achieves better correction quality with an vocabulary and grammar rules that are different F1-measure of 68.42% on the 2014 testset from their native language. and 44.02 % on the L2 Dev. In this paper, we describe our Arabic spelling correction system. Our system is based on a 1 Introduction hybrid pipeline which combines rule-based tech- With the increased usage of computers in the pro- niques with statistical methods using language cessing of various languages comes the need for modeling and machine translation, as well as an correcting errors introduced at different stages. -

Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention
Combining Character and Word Information in Neural Machine Translation Using a Multi-Level Attention † † ‡ † † Huadong Chen , Shujian Huang ,∗ David Chiang , Xinyu Dai , Jiajun Chen †State Key Laboratory for Novel Software Technology, Nanjing University chenhd,huangsj,daixinyu,chenjj @nlp.nju.edu.cn { } ‡Department of Computer Science and Engineering, University of Notre Dame [email protected] Abstract of (sub)words are based purely on their contexts, but the potentially rich information inside the unit Natural language sentences, being hierarchi- itself is seldom explored. Taking the Chinese word cal, can be represented at different levels of 被打伤 (bei-da-shang) as an example, the three granularity, like words, subwords, or charac- ters. But most neural machine translation sys- characters in this word are a passive voice marker, tems require the sentence to be represented as “hit” and “wound”, respectively. The meaning of a sequence at a single level of granularity. It the whole word, “to be wounded”, is fairly com- can be difficult to determine which granularity positional. But this compositionality is ignored if is better for a particular translation task. In this the whole word is treated as a single unit. paper, we improve the model by incorporating Secondly, obtaining the word or sub-word multiple levels of granularity. Specifically, we boundaries can be non-trivial. For languages like propose (1) an encoder with character atten- tion which augments the (sub)word-level rep- Chinese and Japanese, a word segmentation step resentation with character-level information; is needed, which must usually be trained on la- (2) a decoder with multiple attentions that en- beled data. -

Combining Character and Conversational Types in Strategic Choice
Different Games in Dialogue: Combining character and conversational types in strategic choice Alafate Abulmiti Universite´ de Paris, CNRS Laboratoire de Linguistique Formelle [email protected] Abstract We seek to develop an approach to strategic choice applicable to the general case of dialogical In this paper, we show that investigating the in- interaction, where termination is an important con- teraction of conversational type (often known sideration and where assessment is internal to the as language game or speech genre) with the character types of the interlocutors is worth- participants. Strategic choice is modelled by com- while. We present a method of calculating the bining structure from conversational types with psy- decision making process for selecting dialogue chological and cognitive notions associated with moves that combines character type and con- the players. versational type. We also present a mathemat- Character type as a relatively independent factor ical model that illustrate these factors’ interac- abstracted out of the conversational type is impor- tions in a quantitative way. tant for dialogue. Although there is some analy- 1 Introduction sis concerning both character effects and conversa- tional types in the dialogue, combining them and Wittgenstein(1953); Bakhtin(2010) introduced analyzing their interactions in a quantitative way language games/speech genres as notions tying di- has not, to our knowledge, been carried out before. versity of linguistic behaviors to activity. Build- The purposes of this paper is, hence, to combine ing on this, and insights of pragmaticists such as character type effect and conversational type anal- Hymes(1974); Allwood(2000), and earlier work ysis to yield a method that could help to analyse in AI by (Allen and Perrault, 1980; Cohen and strategic choice in dialogue. -

Chapter 5. Characters: Typology and Page Encoding 1
Chapter 5. Characters: typology and page encoding 1 Chapter 5. Characters: typology and encoding Version 2.0 (16 May 2008) 5.1 Introduction PDF of chapter 5. The basic characters a-z / A-Z in the Latin alphabet can be encoded in virtually any electronic system and transferred from one system to another without loss of information. Any other characters may cause problems, even well established ones such as Modern Scandinavian ‘æ’, ‘ø’ and ‘å’. In v. 1 of The Menota handbook we therefore recommended that all characters outside a-z / A-Z should be encoded as entities, i.e. given an appropriate description and placed between the delimiters ‘&’ and ‘;’. In the last years, however, all major operating systems have implemented full Unicode support and a growing number of applications, including most web browsers, also support Unicode. We therefore believe that encoders should take full advantage of the Unicode Standard, as recommended in ch. 2.2.2 above. As of version 2.0, the character encoding recommended in The Menota handbook has been synchronised with the recommendations by the Medieval Unicode Font Initiative . The character recommendations by MUFI contain more than 1,300 characters in the Latin alphabet of potential use for the encoding of Medieval Nordic texts. As a consequence of the synchronisation, the list of entities which is part of the Menota scheme is identical to the one by MUFI. In other words, if a character is encoded with a code point or an entity in the MUFI character recommendation, it will be a valid character encoding also in a Menota text. -
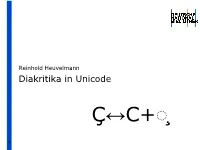
Diakritika in Unicode
Reinhold Heuvelmann Diakritika in Unicode Ç↔C+◌̧ 1 Code Charts http://www.unicode.org/charts/ , Stichwort "combining" – http://www.unicode.org/charts/PDF/U0300.pdf – http://www.unicode.org/charts/PDF/U1AB0.pdf – http://www.unicode.org/charts/PDF/U1DC0.pdf – http://www.unicode.org/charts/PDF/U20D0.pdf – http://www.unicode.org/charts/PDF/UFE20.pdf 2 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 3 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Stacking Sequences, Beispiel 1 http://www.unicode.org/versions/Unicode9.0.0/ch02.pdf 4 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Stacking Sequences, Beispiel 2 5 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Aus den FAQ zu Characters and Combining Marks Q: Why are new combinations of Latin letters with diacritical marks not suitable for addition to Unicode? A: There are several reasons. First, Unicode encodes many diacritical marks, and the combinations can already be produced, as noted in the answers to some questions above. If precomposed equivalents were added, the number of multiple spellings would be increased, and decompositions would need to be defined and maintained for them, adding to the complexity of existing decomposition tables in implementations. ... 6 | 10 | Diakritika in Unicode | Datenbezieher-Workshop 30. Mai 2017 Aus den FAQ zu Characters and Combining Marks ... Finally, normalization form NFC (the composed form favored for use on the Web) is frozen—no new letter combinations can be added to it. Therefore, the normalized NFC representation of any new precomposed letters would still use decomposed sequences, which can already be expressed by combining character sequences in Unicode. -

Special Characters in Aletheia
Special Characters in Aletheia Last Change: 28 May 2014 The following table comprises all special characters which are currently available through the virtual keyboard integrated in Aletheia. The virtual keyboard aids re-keying of historical documents containing characters that are mostly unsupported in other text editing tools (see Figure 1). Figure 1: Text input dialogue with virtual keyboard in Aletheia 1.2 Due to technical reasons, like font definition, Aletheia uses only precomposed characters. If required for other applications the mapping between a precomposed character and the corresponding decomposed character sequence is given in the table as well. When writing to files Aletheia encodes all characters in UTF-8 (variable-length multi-byte representation). Key: Glyph – the icon displayed in the virtual keyboard. Unicode – the actual Unicode character; can be copied and pasted into other applications. Please note that special characters might not be displayed properly if there is no corresponding font installed for the target application. Hex – the hexadecimal code point for the Unicode character Decimal – the decimal code point for the Unicode character Description – a short description of the special character Origin – where this character has been defined Base – the base character of the special character (if applicable), used for sorting Combining Character – combining character(s) to modify the base character (if applicable) Pre-composed Character Decomposed Character (used in Aletheia) (only for reference) Combining Glyph -

Character Properties 4
The Unicode® Standard Version 14.0 – Core Specification To learn about the latest version of the Unicode Standard, see https://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2021 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at https://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see https://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 14.0. Includes index. ISBN 978-1-936213-29-0 (https://www.unicode.org/versions/Unicode14.0.0/) 1. -

Name Description
Perl version 5.10.0 documentation - perluniintro NAME perluniintro - Perl Unicode introduction DESCRIPTION This document gives a general idea of Unicode and how to use Unicodein Perl. Unicode Unicode is a character set standard which plans to codify all of thewriting systems of the world, plus many other symbols. Unicode and ISO/IEC 10646 are coordinated standards that provide codepoints for characters in almost all modern character set standards,covering more than 30 writing systems and hundreds of languages,including all commercially-important modern languages. All charactersin the largest Chinese, Japanese, and Korean dictionaries are alsoencoded. The standards will eventually cover almost all characters inmore than 250 writing systems and thousands of languages.Unicode 1.0 was released in October 1991, and 4.0 in April 2003. A Unicode character is an abstract entity. It is not bound to anyparticular integer width, especially not to the C language char.Unicode is language-neutral and display-neutral: it does not encode the language of the text and it does not define fonts or other graphicallayout details. Unicode operates on characters and on text built fromthose characters. Unicode defines characters like LATIN CAPITAL LETTER A or GREEKSMALL LETTER ALPHA and unique numbers for the characters, in thiscase 0x0041 and 0x03B1, respectively. These unique numbers are called code points. The Unicode standard prefers using hexadecimal notation for the codepoints. If numbers like 0x0041 are unfamiliar to you, take a peekat a later section, Hexadecimal Notation. The Unicode standard uses the notation U+0041 LATIN CAPITAL LETTER A, to give thehexadecimal code point and the normative name of the character. -

The Brill Typeface User Guide & Complete List of Characters
The Brill Typeface User Guide & Complete List of Characters Version 2.06, October 31, 2014 Pim Rietbroek Preamble Few typefaces – if any – allow the user to access every Latin character, every IPA character, every diacritic, and to have these combine in a typographically satisfactory manner, in a range of styles (roman, italic, and more); even fewer add full support for Greek, both modern and ancient, with specialised characters that papyrologists and epigraphers need; not to mention coverage of the Slavic languages in the Cyrillic range. The Brill typeface aims to do just that, and to be a tool for all scholars in the humanities; for Brill’s authors and editors; for Brill’s staff and service providers; and finally, for anyone in need of this tool, as long as it is not used for any commercial gain.* There are several fonts in different styles, each of which has the same set of characters as all the others. The Unicode Standard is rigorously adhered to: there is no dependence on the Private Use Area (PUA), as it happens frequently in other fonts with regard to characters carrying rare diacritics or combinations of diacritics. Instead, all alphabetic characters can carry any diacritic or combination of diacritics, even stacked, with automatic correct positioning. This is made possible by the inclusion of all of Unicode’s combining characters and by the application of extensive OpenType Glyph Positioning programming. Credits The Brill fonts are an original design by John Hudson of Tiro Typeworks. Alice Savoie contributed to Brill bold and bold italic. The black-letter (‘Fraktur’) range of characters was made by Karsten Lücke. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc.