Executing SAS® Code in Python Scripts with Saspy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mastering Machine Learning with Scikit-Learn
www.it-ebooks.info Mastering Machine Learning with scikit-learn Apply effective learning algorithms to real-world problems using scikit-learn Gavin Hackeling BIRMINGHAM - MUMBAI www.it-ebooks.info Mastering Machine Learning with scikit-learn Copyright © 2014 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: October 2014 Production reference: 1221014 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-836-5 www.packtpub.com Cover image by Amy-Lee Winfield [email protected]( ) www.it-ebooks.info Credits Author Project Coordinator Gavin Hackeling Danuta Jones Reviewers Proofreaders Fahad Arshad Simran Bhogal Sarah -

Installing Python Ø Basics of Programming • Data Types • Functions • List Ø Numpy Library Ø Pandas Library What Is Python?
Python in Data Science Programming Ha Khanh Nguyen Agenda Ø What is Python? Ø The Python Ecosystem • Installing Python Ø Basics of Programming • Data Types • Functions • List Ø NumPy Library Ø Pandas Library What is Python? • “Python is an interpreted high-level general-purpose programming language.” – Wikipedia • It supports multiple programming paradigms, including: • Structured/procedural • Object-oriented • Functional The Python Ecosystem Source: Fabien Maussion’s “Getting started with Python” Workshop Installing Python • Install Python through Anaconda/Miniconda. • This allows you to create and work in Python environments. • You can create multiple environments as needed. • Highly recommended: install Python through Miniconda. • Are we ready to “play” with Python yet? • Almost! • Most data scientists use Python through Jupyter Notebook, a web application that allows you to create a virtual notebook containing both text and code! • Python Installation tutorial: [Mac OS X] [Windows] For today’s seminar • Due to the time limitation, we will be using Google Colab instead. • Google Colab is a free Jupyter notebook environment that runs entirely in the cloud, so you can run Python code, write report in Jupyter Notebook even without installing the Python ecosystem. • It is NOT a complete alternative to installing Python on your local computer. • But it is a quick and easy way to get started/try out Python. • You will need to log in using your university account (possible for some schools) or your personal Google account. Basics of Programming Indentations – Not Braces • Other languages (R, C++, Java, etc.) use braces to structure code. # R code (not Python) a = 10 if (a < 5) { result = TRUE b = 0 } else { result = FALSE b = 100 } a = 10 if (a < 5) { result = TRUE; b = 0} else {result = FALSE; b = 100} Basics of Programming Indentations – Not Braces • Python uses whitespaces (tabs or spaces) to structure code instead. -

Documentation for Confluence 5.3 Confluence 5.3 Documentation 2
Documentation for Confluence 5.3 Confluence 5.3 Documentation 2 Contents Confluence User's Guide . 7 Getting Started with Confluence . 8 About Confluence . 9 Dashboard . 9 Page in View Mode . 11 Confluence Glossary . 13 Keyboard Shortcuts . 17 Creating Content . 21 Using the Editor . 23 Quick Reference Guide for the Confluence Editor . 27 Working with Text Effects . 38 Working with Links . 40 Working with Anchors . 45 Displaying Images . 48 Deleting an Image . 51 Working with Tables . 52 Using Symbols, Emoticons and Special Characters . 54 Using Autocomplete . 55 Working with Page Layouts and Columns and Sections . 60 Working with Macros . 63 Activity Stream Macro . 68 Anchor Macro . 68 Attachments Macro . 68 Blog Posts Macro . 68 Change-History Macro . 72 Chart Macro . 73 Cheese Macro . 84 Children Display Macro . 84 Code Block Macro . 87 Column Macro . 90 Content by Label Macro . 90 Content by User Macro . 94 Content Report Table Macro . 95 Contributors Macro . 97 Contributors Summary Macro . 100 Create from Template Macro . 105 Create Space Button Macro . 107 Excerpt Include Macro . 108 Excerpt Macro . 109 Expand Macro . 110 Favourite Pages Macro . 111 Gadget Macro . 112 Gallery Macro . 114 Global Reports Macro . 117 HTML Include Macro . 118 HTML Macro . 119 IM Presence Macro . 119 Include Page Macro . 120 Info Macro . 122 JIRA Issues Macro . 122 JUnit Report Macro . 128 Labels List Macro . 129 Livesearch Macro . 130 Loremipsum Macro . 131 Multimedia Macro . 131 Navigation Map Macro . 132 Created in 2013 by Atlassian. Licensed under a Creative Commons Attribution 2.5 Australia License. Confluence 5.3 Documentation 3 Network Macro . 133 Noformat Macro . 134 Note Macro . -

Quick Install for AWS EMR
Quick Install for AWS EMR Version: 6.8 Doc Build Date: 01/21/2020 Copyright © Trifacta Inc. 2020 - All Rights Reserved. CONFIDENTIAL These materials (the “Documentation”) are the confidential and proprietary information of Trifacta Inc. and may not be reproduced, modified, or distributed without the prior written permission of Trifacta Inc. EXCEPT AS OTHERWISE PROVIDED IN AN EXPRESS WRITTEN AGREEMENT, TRIFACTA INC. PROVIDES THIS DOCUMENTATION AS-IS AND WITHOUT WARRANTY AND TRIFACTA INC. DISCLAIMS ALL EXPRESS AND IMPLIED WARRANTIES TO THE EXTENT PERMITTED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE AND UNDER NO CIRCUMSTANCES WILL TRIFACTA INC. BE LIABLE FOR ANY AMOUNT GREATER THAN ONE HUNDRED DOLLARS ($100) BASED ON ANY USE OF THE DOCUMENTATION. For third-party license information, please select About Trifacta from the Help menu. 1. Release Notes . 4 1.1 Changes to System Behavior . 4 1.1.1 Changes to the Language . 4 1.1.2 Changes to the APIs . 18 1.1.3 Changes to Configuration 23 1.1.4 Changes to the Object Model . 26 1.2 Release Notes 6.8 . 30 1.3 Release Notes 6.4 . 36 1.4 Release Notes 6.0 . 42 1.5 Release Notes 5.1 . 49 2. Quick Start 55 2.1 Install from AWS Marketplace with EMR . 55 2.2 Upgrade for AWS Marketplace with EMR . 62 3. Configure 62 3.1 Configure for AWS . 62 3.1.1 Configure for EC2 Role-Based Authentication . 68 3.1.2 Enable S3 Access . 70 3.1.2.1 Create Redshift Connections 81 3.1.3 Configure for EMR . -

Delft University of Technology Arrowsam In-Memory Genomics
Delft University of Technology ArrowSAM In-Memory Genomics Data Processing Using Apache Arrow Ahmad, Tanveer; Ahmed, Nauman; Peltenburg, Johan; Al-Ars, Zaid DOI 10.1109/ICCAIS48893.2020.9096725 Publication date 2020 Document Version Accepted author manuscript Published in 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS) Citation (APA) Ahmad, T., Ahmed, N., Peltenburg, J., & Al-Ars, Z. (2020). ArrowSAM: In-Memory Genomics Data Processing Using Apache Arrow. In 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS): Proceedings (pp. 1-6). [9096725] IEEE . https://doi.org/10.1109/ICCAIS48893.2020.9096725 Important note To cite this publication, please use the final published version (if applicable). Please check the document version above. Copyright Other than for strictly personal use, it is not permitted to download, forward or distribute the text or part of it, without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license such as Creative Commons. Takedown policy Please contact us and provide details if you believe this document breaches copyrights. We will remove access to the work immediately and investigate your claim. This work is downloaded from Delft University of Technology. For technical reasons the number of authors shown on this cover page is limited to a maximum of 10. © 2020 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. -

The Platform Inside and out Release 0.8
The Platform Inside and Out Release 0.8 Joshua Patterson – GM, Data Science RAPIDS End-to-End Accelerated GPU Data Science Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 2 Data Processing Evolution Faster data access, less data movement Hadoop Processing, Reading from disk HDFS HDFS HDFS HDFS HDFS Read Query Write Read ETL Write Read ML Train Spark In-Memory Processing 25-100x Improvement Less code HDFS Language flexible Read Query ETL ML Train Primarily In-Memory Traditional GPU Processing 5-10x Improvement More code HDFS GPU CPU GPU CPU GPU ML Language rigid Query ETL Read Read Write Read Write Read Train Substantially on GPU 3 Data Movement and Transformation The bane of productivity and performance APP B Read Data APP B GPU APP B Copy & Convert Data CPU GPU Copy & Convert Copy & Convert APP A GPU Data APP A Load Data APP A 4 Data Movement and Transformation What if we could keep data on the GPU? APP B Read Data APP B GPU APP B Copy & Convert Data CPU GPU Copy & Convert Copy & Convert APP A GPU Data APP A Load Data APP A 5 Learning from Apache Arrow ● Each system has its own internal memory format ● All systems utilize the same memory format ● 70-80% computation wasted on serialization and deserialization ● No overhead for cross-system communication ● Similar functionality implemented in multiple projects ● Projects can share functionality (eg, Parquet-to-Arrow reader) From Apache Arrow -

Atlassian Is Primed to Widen Its Appeal Beyond IT
Seth Agulnick, [email protected] REPORT Atlassian Is Primed to Widen Its Appeal Beyond IT Companies: CA, CRM, GOOG/GOOGL, HPE, IBM, JIVE, MSFT, NOW, ORCL, TEAM, ZEN February 11, 2016 Report Type: Initial Coverage ☐ Previously Covered Full Report ☐ Update Report Research Question: Will Atlassian’s workflow tools continue to grow quickly with software development teams while also expanding into new use cases? Summary of Findings Silo Summaries . Atlassian Corp. Plc’s (TEAM) tracking and collaboration tools, widely 1) Atlassian Software Users considered the best-in-class for software development, are gaining JIRA and Confluence are both effective tools for team traction among nontechnical teams. collaboration. JIRA can be customized to suit nearly any team’s development process, though setup is . The company’s two flagship products, JIRA and Confluence, are complicated. Confluence is much easier to use and slowly being rolled out in departments like human resources, sales, tends to be deployed more widely. Atlassian’s biggest customer support and product management. These represent a advantage is the way all of its software pieces work together. Atlassian products—which already are being much larger market than Atlassian’s traditional core in IT. branched out beyond software development—can grow . JIRA was praised for its flexibility and advanced customization even further with business teams. options, though the latter trait makes setup and maintenance a challenge. It has great potential for sales growth with any business 2) Users of Competing Software Three of these five sources said Atlassian’s JIRA is not team that needs to track numerous tasks through a multistage the right fit for every company. -
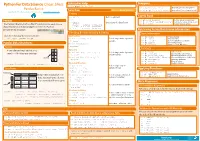
Cheat Sheet Pandas Python.Indd
Python For Data Science Cheat Sheet Asking For Help Dropping >>> help(pd.Series.loc) Pandas Basics >>> s.drop(['a', 'c']) Drop values from rows (axis=0) Selection Also see NumPy Arrays >>> df.drop('Country', axis=1) Drop values from columns(axis=1) Learn Python for Data Science Interactively at www.DataCamp.com Getting Sort & Rank >>> s['b'] Get one element -5 Pandas >>> df.sort_index() Sort by labels along an axis Get subset of a DataFrame >>> df.sort_values(by='Country') Sort by the values along an axis The Pandas library is built on NumPy and provides easy-to-use >>> df[1:] Assign ranks to entries Country Capital Population >>> df.rank() data structures and data analysis tools for the Python 1 India New Delhi 1303171035 programming language. 2 Brazil Brasília 207847528 Retrieving Series/DataFrame Information Selecting, Boolean Indexing & Setting Basic Information Use the following import convention: By Position (rows,columns) Select single value by row & >>> df.shape >>> import pandas as pd >>> df.iloc[[0],[0]] >>> df.index Describe index Describe DataFrame columns 'Belgium' column >>> df.columns Pandas Data Structures >>> df.info() Info on DataFrame >>> df.iat([0],[0]) Number of non-NA values >>> df.count() Series 'Belgium' Summary A one-dimensional labeled array a 3 By Label Select single value by row & >>> df.sum() Sum of values capable of holding any data type b -5 >>> df.loc[[0], ['Country']] Cummulative sum of values 'Belgium' column labels >>> df.cumsum() >>> df.min()/df.max() Minimum/maximum values c 7 Minimum/Maximum index -

FALL 2020 Knowledge Management Category
FALL 2020 Customer Success Report Knowledge Management Category Knowledge Management Category Big data is ubiquitous in today’s digital age. Cloud usage has made unlimited data storage possible and affordable. Numerous business platforms allow enterprises to acquire this data – from internal business files and industry knowledge to customer information. However, this mass of data and knowledge needs to be organized so that users can easily search and find the information they need. This can be done with the help of knowledge management (KM) software. The solution allows you to identify, create, distribute and organize your firm’s knowledge repository. It gives your organization a unified, single information pool that can be easily accessed, discovered and updated. In this way, the product helps to make enterprises leaner and more efficient and profitable. FALL 2020 CUSTOMER SUCCESS REPORT Knowledge Management Category 2 Award Levels Customer Success Report Ranking Methodology The FeaturedCustomers Customer Success ranking is based on data from our customer reference platform, market presence, MARKET LEADER web presence, & social presence as well as additional data Vendor on FeaturedCustomers.com with aggregated from online sources and media properties. Our substantial customer base & market ranking engine applies an algorithm to all data collected to share. Leaders have the highest ratio of calculate the final Customer Success Report rankings. customer success content, content quality score, and social media presence The overall Customer -

Citrix Gateway Service
Citrix Gateway Service Citrix Product Documentation | docs.citrix.com September 28, 2021 Citrix Gateway Service Contents Release Notes 3 Get started with Citrix Gateway service 14 Technical Security Overview 15 Migrate Citrix Gateway to Citrix Gateway service for HDX Proxy 18 HDX Adaptive transport with EDT support for Citrix Gateway service 24 Support for Citrix Virtual Apps and Desktops 27 Route tables to resolve conflicts if the related domains in both SaaS and web apps are the same ‑ Tech Preview 29 Contextual access to Enterprise Web and SaaS applications – Tech Preview 33 Read‑only access for admins to SaaS and Web apps 37 Support for Software as a Service apps 41 Apps configuration using a template 52 SaaS app server specific configuration 59 Citrix Gateway Connector 73 Citrix Gateway Connector dashboard 96 Support for Enterprise web apps 97 Support for Citrix Endpoint Management 109 Citrix Cloud Gateway Connector availability in Azure Marketplace 113 Citrix Cloud Gateway Connector availability in Azure 118 Deploy a Citrix Gateway Connector instance on AWS ‑ Tech Preview 125 ADFS integration with Secure Workspace Access 131 FAQ 140 © 1999–2021 Citrix Systems, Inc. All rights reserved. 2 Citrix Gateway Service Release Notes August 24, 2021 The Citrix Gateway service release to cloud release notes describe the new features, enhancements to existing features, fixed issues, and known issues available in a service release. The release notes include one or more of the following sections: What’s new: The new features and enhancements available in the current release. Fixed issues: The issues that are fixed in the current release. -

WHY USE a WIKI? an Introduction to the Latest Online Publishing Format
WHY USE A WIKI? An Introduction to the Latest Online Publishing Format A WebWorks.com White Paper Author: Alan J. Porter VP-Operations WebWorks.com a brand of Quadralay Corporation [email protected] WW_WP0309_WIKIpub © 2009 – Quadralay Corporation. All rights reserved. NOTE: Please feel free to redistribute this white paper to anyone you feel may benefit. If you would like an electronic copy for distribution, just send an e-mail to [email protected] CONTENTS Overview................................................................................................................................ 2 What is a Wiki? ...................................................................................................................... 2 Open Editing = Collaborative Authoring .................................................................................. 3 Wikis in More Detail................................................................................................................ 3 Wikis Are Everywhere ............................................................................................................ 4 Why Use a Wiki...................................................................................................................... 5 Getting People to Use Wikis ................................................................................................... 8 Populating the Wiki................................................................................................................. 9 WebWorks ePublisher and Wikis -

Pandas: Powerful Python Data Analysis Toolkit Release 0.25.3
pandas: powerful Python data analysis toolkit Release 0.25.3 Wes McKinney& PyData Development Team Nov 02, 2019 CONTENTS i ii pandas: powerful Python data analysis toolkit, Release 0.25.3 Date: Nov 02, 2019 Version: 0.25.3 Download documentation: PDF Version | Zipped HTML Useful links: Binary Installers | Source Repository | Issues & Ideas | Q&A Support | Mailing List pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. See the overview for more detail about whats in the library. CONTENTS 1 pandas: powerful Python data analysis toolkit, Release 0.25.3 2 CONTENTS CHAPTER ONE WHATS NEW IN 0.25.2 (OCTOBER 15, 2019) These are the changes in pandas 0.25.2. See release for a full changelog including other versions of pandas. Note: Pandas 0.25.2 adds compatibility for Python 3.8 (GH28147). 1.1 Bug fixes 1.1.1 Indexing • Fix regression in DataFrame.reindex() not following the limit argument (GH28631). • Fix regression in RangeIndex.get_indexer() for decreasing RangeIndex where target values may be improperly identified as missing/present (GH28678) 1.1.2 I/O • Fix regression in notebook display where <th> tags were missing for DataFrame.index values (GH28204). • Regression in to_csv() where writing a Series or DataFrame indexed by an IntervalIndex would incorrectly raise a TypeError (GH28210) • Fix to_csv() with ExtensionArray with list-like values (GH28840). 1.1.3 Groupby/resample/rolling • Bug incorrectly raising an IndexError when passing a list of quantiles to pandas.core.groupby. DataFrameGroupBy.quantile() (GH28113).