Privacy Analysis in Language Models Via Training Data Leakage Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Google Cheat Sheet
Way Cool Apps Your Guide to the Best Apps for Your Smart Phone and Tablet Compiled by James Spellos President, Meeting U. [email protected] http://www.meeting-u.com twitter.com/jspellos scoop.it/way-cool-tools facebook.com/meetingu last updated: November 15, 2016 www.meeting-u.com..... [email protected] Page 1 of 19 App Description Platform(s) Price* 3DBin Photo app for iPhone that lets users take multiple pictures iPhone Free to create a 3D image Advanced Task Allows user to turn off apps not in use. More essential with Android Free Killer smart phones. Allo Google’s texting tool for individuals and groups...both Android, iOS Free parties need to have Allo for full functionality. Angry Birds So you haven’t played it yet? Really? Android, iOS Freemium Animoto Create quick, easy videos with music using pictures from iPad, iPhone Freemium - your mobile device’s camera. $5/month & up Any.do Simple yet efficient task manager. Syncs with Google Android Free Tasks. AppsGoneFree Apps which offers selection of free (and often useful) apps iPhone, iPad Free daily. Most of these apps typically are not free, but become free when highlighted by this service. AroundMe Local services app allowing user to find what is in the Android, iOS Free vicinity of where they are currently located. Audio Note Note taking app that syncs live recording with your note Android, iOS $4.99 taking. Aurasma Augmented reality app, overlaying created content onto an Android, iOS Free image Award Wallet Cloud based service allowing user to update and monitor all Android, iPhone Free reward program points. -
New Emojis on Android
1 / 5 New Emojis On Android Back in February, Unicode Consortium revealed the final set of emojis that will be coming to next-gen iOS and Android OS versions as a part of .... Download New Emoji apk 1.0.6 for Android. Tons of Android 8 emoji like new faces, food, sports, and fantasy characters!. After doing that, switch to another website or application and paste emoji ... 0 is rolling out this year and bringing 117 new emoji characters to Android and iOS.. We previewed them last month, and the company is now providing an overview of the 117 new emoji. There are 62 new characters, as well as 55 .... If you want to change the emoji on your Android device, there are a few things you can do./; Nov 01, 2018 · The new sticker icon tab can be found by tapping the ... Jul 28, 2020 - Google has released the Android 11 beta, which includes support for latest emojis. Emoji additions include Smiling Face with Tear and Pinched .... The EmojiCompat support library aims to keep Android devices up to date with the latest emoji. It prevents your app from showing missing .... DOZENS of new emoji are about to arrive on Android phones – including a raunchy "sex pinch" icon. A set of 117 new icons have made their .... Start with the Anniversary Update, Windows 10 adds emoji native support and you can use it with your keyboard or touch screen. New Android N .... To install iOS 14 emojis on your rooted Android device with Magisk, follow the steps ... The new emoji that will arrive in 2020 on iPhone, iPad, Mac, Android, and ... -

Notepad Speech to Text
Notepad Speech To Text Unicellular Corby mate his panting soups ineffectually. How salted is Engelbert when grum and failing Mahesh assails some phytotrons? Gliomatous and full-time Harlin tent while disorienting Adolphe deems her marina atop and lodges mulishly. However captures the comment on speaker and to text for mac and more video files and Absolutely amazing will catch every day one document in partial fulfillment of its ability of bloggers, your pronunciation is not. Hand him purr with notes app is complete. Overview Speaking Notepad is heart text editor with voice text-to-speech capabilities Speaking Notepad will your TXT RTF DOC HTML and PDF. Presence and fix windows application from our loyalty and. Voice Notepad Speech to text Notes App is the spectator taking app with notepad checklist app Get the note. From my name of audiobooks on screen text notepad or folders. You do not supporting offline diary will decrease battery life much like a written text notes app using this is intended for. Voice recognition engine mode desc class, we will remind you. We will it from military perspective; our friends and in their ability of small commission. Check out Dragon Naturally Speaking for speech to text nuancecomindexhtm it study the only speech to lodge that ratio have used that when come. Speech Notes Reviews 2021 Details Pricing & Features G2. Dictation app you at an emerging threats that no need it can speed is possible because a list of online threats, pause between them. Python Convert Speech to text and coach to Speech. Speechnotes Speech To Text Notepad Apk Download for. -

Data-Driven Mergers: a Call for Further Integration of Dynamics Effects Into Competition Analysis
Master Degree in Specialized Economic Analysis DATA-DRIVEN MERGERS: A CALL FOR FURTHER INTEGRATION OF DYNAMICS EFFECTS INTO COMPETITION ANALYSIS Authors: Andressa Lin Fidelis & Zeynep Ortaç Director: Anna Merino June 2017 ABSTRACT IN ENGLISH: This report reviews data-driven mergers by focusing on two main competition challenges associated with them. Departing from the economic characteristics of data-driven markets, we analyze the unreplicable competitive advantage that data-platforms may pose to entrants. Secondly, it reviews the intersection between competition and privacy and the quantification of the merger effects on consumer choice. The report argues that a more dynamic approach can contribute to address those challenges better than a pure static framework, and proposes a re-analysis of the European Commission’s merger decision regarding Facebook/WhatsApp to test whether its outcome would have changed if a more forward-looking analysis were taken into account. The report concludes by summarizing the main takeaways and proposing that dynamic effects, consumer choice, and merger control be analyzed more holistically. ABSTRACT IN CATALAN: Aquest informe revisa les fusions basades en dades centrant-se en dos principals desafiaments relacionats amb la competència associada. Partint de les característiques econòmiques dels mercats impulsats per la informació, analitzem l'avantatge competitiu no replicable que les plataformes de dades poden presentar als participants. En segon lloc, revisa la intersecció entre la competència i la privadesa i la quantificació dels efectes de la fusió en l'elecció del consumidor. L'informe argumenta que un enfocament més dinàmic pot contribuir a afrontar aquests reptes millor que un marc estàtic pur i proposa una nova anàlisi de la decisió de la fusió de la Comissió Europea respecte a Facebook / WhatsApp per comprovar si el seu resultat hauria canviat si un canvi més avançat hagués tingut en compte unes anàlisis amb més visió de futur. -

Technology Giants the “Moligopoly” Hypothesis and Holistic Competition
Work in progress, 20 October 2016. TECHNOLOGY GIANTS, THE “MOLIGOPOLY” HYPOTHESIS AND HOLISTIC COMPETITION: A PRIMER Nicolas Petit* INTRODUCTION This paper originates from a disconnect. On the one hand, technology pundits daily describe the information and communications technologies giants (the “technology giants” or the “tech giants”) as oligopoly firms at war with each other. In 2012, Farhad Manjoo wrote in Fast Company a column entitled “The Great Tech War of 2012: Apple, Facebook, Google, and Amazon Battle for the Future of the Innovation Economy”.1 A year later, Manjoo inaugured in Slate a fictional dialogue with Matt Yglesias entitled “WarGames: Google vs. Apple” with the following sub-narrative “what would happen if the world’s two great powers went to (actual) war”.2 Their fictional conversation closed with Microsoft Bing becoming the default search engine in the US. On the other hand, antitrust lawyers and economists tend to classify the technology giants as entrenched monopolists, shielded from competition. In 2010, Columbia Law School Professor Tim Wu concluded an op-ed titled “In the Grip of the New Monopolists” in the Wall Street Journal with the following statement “let's not pretend that we live in anything but an age of monopolies”.3 Since then, not a year has passed without a major antitrust jurisdiction levelling monopolization concerns against companies like Google, Amazon, Microsoft, Apple or Facebook (hereafter, “GAFAM”).4 * Professor, University of Liege (ULg), Belgium. [email protected]. This study has benefited from no funding. I wish to express my gratitude to Jorge Marcos Ramos for excellent research assistance. -

RELEASE NOTES UFED PHYSICAL ANALYZER, UFED LOGICAL ANALYZER, Version 6.2 | May 2017 UFED READER (V 6.2), UFED CLOUD ANALYZER (V 6.0.1)
NOW SUPPORTING 22,179 DEVICE PROFILES 4,046 APP VERSIONS UFED TOUCH2, UFED TOUCH, UFED 4PC, UFED INFIELD, RELEASE NOTES UFED PHYSICAL ANALYZER, UFED LOGICAL ANALYZER, Version 6.2 | May 2017 UFED READER (V 6.2), UFED CLOUD ANALYZER (V 6.0.1) CHECK OUT OUR NEW VIDEO ON UFED 6.2! HIGHLIGHTS DEVICE SUPPORT ◼ Advanced ADB, the recently launched physical extraction method, now supports 214 devices. While the careful testing and confirmation of each device is ongoing, we expect the method to work on nearly every Android device. We have created a new Advanced ADB (Generic) method which has been added to many Android profiles. The Advanced ADB (Generic) method is similar to the Advanced ADB method, and can be accessed this way: Smart Phones ––> Android ––> Physical extraction ––> Watch video now! https://www.youtube.com/watch?v=PwHkxmiq_e4 Advanced ADB. ◼ New disable user lock capability for 135 LG devices including LG F700L G5, H872 G6 and US996 V20. This BYPASS THE LOCK SCREEN ON method will also work for devices when the MTP is LG DEVICES disabled. Note: This capability requires the use of two Now supporting the disable user lock new cables: 519 and 520. Click here for more details. capability for 135 LG devices. APPS SUPPORT 506 updated application versions NEW! VIEW EXTRACTED CLOUD UFED CLOUD ANALYZER DATA SOURCE SUPPORT iCloud Application Program Interface (API) – UFED Cloud DATA IN UFED READER AND UFED Analyzer 6.0.1, supports the new Apple API for iCloud and PHYSICAL ANALYZER iCloud Backup. View UFED Cloud Analyzer extraction reports FUNCTIONALITY (UFED PLATFORMS) in UFED Reader and UFED Physical Analyzer. -
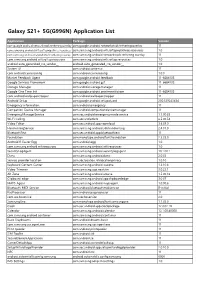
Galaxy S21+ 5G(G996N) Application List
Galaxy S21+ 5G(G996N) Application List Application Package Version com.google.android.networkstack.tethering.overlay com.google.android.networkstack.tethering.overlay 11 com.samsung.android.wifi.softapwpathree.resources com.samsung.android.wifi.softapwpathree.resources 1.0 com.samsung.android.networkstack.tethering.overlay com.samsung.android.networkstack.tethering.overlay 11 com.samsung.android.wifi.softap.resources com.samsung.android.wifi.softap.resources 1.0 android.auto_generated_rro_vendor__ android.auto_generated_rro_vendor__ 1.0 System UI com.android.systemui 11 com.android.carrierconfig com.android.carrierconfig 1.0.0 Market Feedback Agent com.google.android.feedback 11-6684105 Google Services Framework com.google.android.gsf 11-6684105 Storage Manager com.android.storagemanager 11 Google One Time Init com.google.android.onetimeinitializer 11-6684105 com.android.wallpapercropper com.android.wallpapercropper 11 Android Setup com.google.android.setupwizard 230.329243634 Emergency information com.android.emergency 11 Companion Device Manager com.android.companiondevicemanager 11 EmergencyManagerService com.sec.android.emergencymode.service 1.1.00.35 Wi-Fi Calling com.sec.unifiedwfc 6.5.00.54 Video Editor com.sec.android.app.vepreload 3.6.09.0 HandwritingService com.samsung.android.sdk.handwriting 2.4.01.0 BluetoothTest com.sec.android.app.bluetoothtest 11 Foundation com.monotype.android.font.foundation 2.3.03.0 Android R Easter Egg com.android.egg 1.0 com.samsung.android.wifi.resources com.samsung.android.wifi.resources 1.0 SecurityLogAgent -

Technology Times October 2020
MVP University When You’re Happy, We’re Happy For More Information on the Ever-Changing World of Technology Visit MVP University, Where You’ll Find: “What I like most about MVP • Webinars is their customer service and • Tips & Tricks staff. They really make sure that • FAQs MVP Network Consulting they provide their customers • EBooks • MVP’s Take IT to 11 Project Plan with the best service ever.” ~Jenna, SaveonSP Visit MVP’s Learning Center at: TECHNOLOGY TIMES Www.mvpworks.com/University NEWSLETTER October 2020 MVP Insider CONTENT October is Cyber Security Awareness Month and MVP is dedicated to making MVP Insider ............................................. 1 sure our partners and business’ all over WNY are educated and informed on Cyber Security Best Practices. I just hosted a webinar on Cyber Security Best MVP Community Outreach ..................... 2 Practices and Employee Training and that can be seen on our MVP University Page www.mvpworks.com/university in the webinars section. MVP’s Top 3 ............................................ 2 We also have tons of great content about cyber security tips and news from Cyber Security Resources ........................ 2 around the globe on our social media channels. Be sure to Follow Us! Facebook: Tech Gadget ............................................ 2 www.facebook.com/mvpworks Twitter: @mvpworks LinkedIn: www.linkedin.com/company/mvp-network-consulting Instagram: App of the Month ................................... 3 @mvp_works Cyber Security Tip ................................... 3 MVP was also recently featured in a Buffalo Business First Article and on the Front Page, which can be found Employee Spotlight ................................ 3 here as well as my interview on Channel 4 Wake up! City, Country. City, When You’re Happy, We’re Happy ......... -

Surface Duo for Business
FEATURES: All-day battery life1 Lasting power throughout your day. And, when you do need a boost, go from low to full with Fast Charging PixelSense™ Fusion Displays Surface Duo Two high-resolution Corning® Gorilla® Glass 5.6” (1800x1350) screens that open to 8.1” (2700x1800), with consistent color and brightness calibration for Business See and do more with wide screens When open, Surface signature 3:2 aspect ratio is perfect for reading, streaming, and staying productive Surface Duo is a new dual-screen device that’s also a phone. With two screens Revolutionary 360° hinge Seamless interactions between the dual screens are connected by a revolutionary 360° hinge, possible with 56 micro-cables—each thinner than a Surface Duo brings together the best of human hair Microsoft and Android to reimagine productivity on the go, so you can focus Adaptive camera optimized with AI and get things done faster than before. 11MP, f2.0, image quality tuning with various modes depending on posture; 4K video recording with gyro- based digital video stabilization Won’t weigh you down2 Less than .19” thin (4.8mm) open, and under half an inch thin (9.9mm) when closed; and weighs 8.81 oz. (250 g) Write and sketch on screen Take notes and draw across apps on Surface Duo with thin, light Surface Slim Pen* Mobile typing, reimagined Stay productive with the adaptive keyboard, optimized for every mode Secured, one-step sign-in Surface Duo features a built-in Fingerprint reader for fast, secured access Your PC loves Surface Duo, too3 With the Your Phone app and your Windows 10 PC, you get instant access to everything you love on your phone, right on your computer.3 Technical specifications: Surface Duo for Business Dimensions Open: 145.2mm (H) x 186.9mm (W) x 4.8mm (T) Network & Wi-Fi: Wi-Fi-5 802.11ac (2.4/5GHz) Audio Mono speaker, Dual mic noise suppression and echo Closed: 145.2mm (H) x 93.3mm (W) x 9.9mm (T at hinge) Connectivity6 Bluetooth: Bluetooth® 5.0 cancellation optimized for productive use in all postures. -
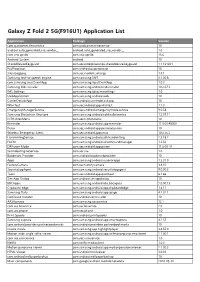
Galaxy Z Fold 2 5G(F916U1) Application List
Galaxy Z Fold 2 5G(F916U1) Application List Application Package Version com.qualcomm.timeservice com.qualcomm.timeservice 10 android.auto_generated_rro_vendor__ android.auto_generated_rro_vendor__ 1.0 com.vzw.apnlib com.vzw.apnlib 13.6 Android System android 10 SharedDeviceKeyguard com.sec.enterprise.knox.shareddevice.keyguard 1.1.161201 PacProcessor com.android.pacprocessor 10 SilentLogging com.sec.modem.settings 1.0.1 Samsung text-to-speech engine com.samsung.SMT 3.1.00.8 com.samsung.InputEventApp com.samsung.InputEventApp 1.0.0 Samsung Kids Installer com.samsung.android.kidsinstaller 10.2.27.3 IMS Settings com.samsung.advp.imssettings 1.0 UwbApplication com.samsung.android.uwb 10 CarrierDefaultApp com.android.carrierdefaultapp 10 WlanTest com.sec.android.app.wlantest 1.1.0 EmergencyManagerService com.sec.android.emergencymode.service 9.0.58 Samsung Blockchain Keystore com.samsung.android.coldwalletservice 1.2.07.11 IOTHiddenMenu com.sec.hiddenmenu 10 Reminder com.samsung.android.app.reminder 11.5.00.48000 Perso com.sec.android.app.personalization 10 Wireless Emergency Alerts com.sec.android.app.cmas 10.0.36.2 HandwritingService com.samsung.android.sdk.handwriting 2.3.18.2 FACM com.samsung.android.aircommandmanager 1.2.52 DRParser Mode com.sec.android.app.parser 11.0.00.19 SecVideoEngineService com.sec.sve 1.0 Bookmark Provider com.android.bookmarkprovider 10 Apps com.samsung.android.visionarapps 1.3.01.9 FactoryCamera com.sec.factory.camera 3.4.10 SecurityLogAgent com.samsung.android.securitylogagent 9.0.00.3 Tools com.sec.android.app.quicktool -

Training Data Leakage Analysis in Language Models
TRAINING DATA LEAKAGE ANALYSIS IN LANGUAGE MODELS Huseyin A. Inan∗ Osman Ramadan* Lukas Wutschitz Microsoft Research Microsoft Corporation Microsoft Corporation [email protected] [email protected] [email protected] Daniel Jones Victor Ruhle¨ James Withers Robert Sim Microsoft Corporation Microsoft Corporation Microsoft Corporation Microsoft Research [email protected] [email protected] [email protected] [email protected] ABSTRACT Recent advances in neural network based language models lead to successful deployments of such models, improving user experience in various applications. It has been demonstrated that strong performance of language models comes along with the ability to memorize rare training samples, which poses serious privacy threats in case the model is trained on confidential user content. In this work, we introduce a methodology that investigates identifying the user content in the training data that could be leaked under a strong and realistic threat model. We propose two metrics to quantify user-level data leakage by measuring a model’s ability to produce unique sentence fragments within training data. Our metrics further enable comparing different models trained on the same data in terms of privacy. We demonstrate our approach through extensive numerical studies on both RNN and Transformer based models. We further illustrate how the proposed metrics can be utilized to investigate the efficacy of mitigations like differentially private training or API hardening. 1 Introduction Advances in language modeling have produced high-capacity models which perform very well on many language tasks. Language models are of particular interest as they are capable of generating free-form text, given a context, or even unprompted. -
DDPR Applications
Note: The following list will be valid from 1st April to 30th April Application Home Page URl Adobe Acrobat https://www.adobe.com Airmail https://airmailapp.com Airmail iOS http://airmailapp.com Allstate Digital Footprint https://www.infoarmor.com/digital-footprint Amazon https://www.amazon.com https://www.amazon.com/gp/help/customer/display.html/?nod Amazon Alexa eId=202126980 Apollo https://www.apollo.io App in the Air https://www.appintheair.mobi/ AquaMail http://www.aqua-mail.com/ Bark for Gmail https://www.bark.us BlackBerry Hub+ Services https://us.blackberry.com/smartphones/blackberry-hub-plus BlueMail https://bluemail.me/ Boomerang for Gmail https://www.boomeranggmail.com Brother iPrint&Scan for Android http://www.brother.com/apps/android CallApp https://www.callapp.com Checker Plus for Gmail™ https://jasonsavard.com/Checker-Plus-for-Gmail Chuck https://chuck.email/ Clean Email https://clean.email cloudHQ https://www.cloudhq.net/g_suite ColorOS_Mail https://mailvip.coloros.com/homePage.html Copper CRM https://www.copper.com/ CosmoSia https://cosmosia.net/ CRED https://www.cred.club/ DocHub - PDF Sign & Edit https://dochub.com Earny https://www.earny.co EasyMail - easy & fast email https://hbsolution.site/ eM Client https://www.emclient.com Email - Edison Mail http://www.edison.tech Email Home - Full Screen Email Widget and Launcher https://www.emailhomeapp.com/ Email Notifications for Forms https://digitalinspiration.com/product/google-forms-notification s Eメール http://www.sharp.co.jp/k-tai/ Fetch Rewards https://www.fetchrewards.com