Static Program Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Static Analysis the Workhorse of a End-To-End Securitye Testing Strategy
Static Analysis The Workhorse of a End-to-End Securitye Testing Strategy Achim D. Brucker [email protected] http://www.brucker.uk/ Department of Computer Science, The University of Sheffield, Sheffield, UK Winter School SECENTIS 2016 Security and Trust of Next Generation Enterprise Information Systems February 8–12, 2016, Trento, Italy Static Analysis: The Workhorse of a End-to-End Securitye Testing Strategy Abstract Security testing is an important part of any security development lifecycle (SDL) and, thus, should be a part of any software (development) lifecycle. Still, security testing is often understood as an activity done by security testers in the time between “end of development” and “offering the product to customers.” Learning from traditional testing that the fixing of bugs is the more costly the later it is done in development, security testing should be integrated, as early as possible, into the daily development activities. The fact that static analysis can be deployed as soon as the first line of code is written, makes static analysis the right workhorse to start security testing activities. In this lecture, I will present a risk-based security testing strategy that is used at a large European software vendor. While this security testing strategy combines static and dynamic security testing techniques, I will focus on static analysis. This lecture provides a introduction to the foundations of static analysis as well as insights into the challenges and solutions of rolling out static analysis to more than 20000 developers, distributed across the whole world. A.D. Brucker The University of Sheffield Static Analysis February 8–12., 2016 2 Today: Background and how it works ideally Tomorrow: (Ugly) real world problems and challenges (or why static analysis is “undecideable” in practice) Our Plan A.D. -

List of Requirements for Code Reviews
WP2 DIGIT B1 - EP Pilot Project 645 Deliverable 9: List of Requirements for Code Reviews Specific contract n°226 under Framework Contract n° DI/07172 – ABCIII April 2016 DIGIT Fossa WP2 – Governance and Quality of Software Code – Auditing of Free and Open Source Software. Deliverable 9: List of requirements for code reviews Author: Disclaimer The information and views set out in this publication are those of the author(s) and do not necessarily reflect the official opinion of the Commission. The content, conclusions and recommendations set out in this publication are elaborated in the specific context of the EU – FOSSA project. The Commission does not guarantee the accuracy of the data included in this study. All representations, warranties, undertakings and guarantees relating to the report are excluded, particularly concerning – but not limited to – the qualities of the assessed projects and products. Neither the Commission nor any person acting on the Commission’s behalf may be held responsible for the use that may be made of the information contained herein. © European Union, 2016. Reuse is authorised, without prejudice to the rights of the Commission and of the author(s), provided that the source of the publication is acknowledged. The reuse policy of the European Commission is implemented by a Decision of 12 December 2011. Document elaborated in the specific context of the EU – FOSSA project. Reuse or reproduction authorised without prejudice to the Commission’s or the authors’ rights. Page 2 of 51 DIGIT Fossa WP2 – Governance and Quality of Software Code – Auditing of Free and Open Source Software. Deliverable 9: List of requirements for code reviews Contents CONTENTS............................................................................................................................................ -

Precise and Scalable Static Program Analysis of NASA Flight Software
Precise and Scalable Static Program Analysis of NASA Flight Software G. Brat and A. Venet Kestrel Technology NASA Ames Research Center, MS 26912 Moffett Field, CA 94035-1000 650-604-1 105 650-604-0775 brat @email.arc.nasa.gov [email protected] Abstract-Recent NASA mission failures (e.g., Mars Polar Unfortunately, traditional verification methods (such as Lander and Mars Orbiter) illustrate the importance of having testing) cannot guarantee the absence of errors in software an efficient verification and validation process for such systems. Therefore, it is important to build verification tools systems. One software error, as simple as it may be, can that exhaustively check for as many classes of errors as cause the loss of an expensive mission, or lead to budget possible. Static program analysis is a verification technique overruns and crunched schedules. Unfortunately, traditional that identifies faults, or certifies the absence of faults, in verification methods cannot guarantee the absence of errors software without having to execute the program. Using the in software systems. Therefore, we have developed the CGS formal semantic of the programming language (C in our static program analysis tool, which can exhaustively analyze case), this technique analyses the source code of a program large C programs. CGS analyzes the source code and looking for faults of a certain type. We have developed a identifies statements in which arrays are accessed out Of static program analysis tool, called C Global Surveyor bounds, or, pointers are used outside the memory region (CGS), which can analyze large C programs for embedded they should address. -
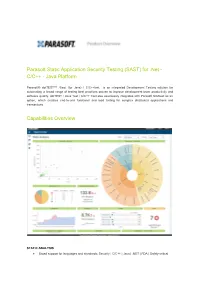
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

Email: [email protected] Website
Email: [email protected] Website: http://chrismatech.com Experienced software and systems engineer who has successfully deployed custom & industry-standard embedded, desktop and networked systems for commercial and DoD customers. Delivered systems operate on airborne, terrestrial, maritime, and space based vehicles and platforms. Expert in performing all phases of the software and system development life-cycle including: Creating requirements and design specifications. Model-driven software development, code implementation, and unit test. System integration. Requirements-based system verification with structural coverage at the system and module levels. Formal qualification/certification test. Final product packaging, delivery, and site installation. Post-delivery maintenance and customer support. Requirements management and end-to-end traceability. Configuration management. Review & control of change requests and defect reports. Quality assurance. Peer reviews/Fagan inspections, TIMs, PDRs and CDRs. Management and project planning proficiencies include: Supervising, coordinating, and mentoring engineering staff members. Creating project Software Development Plans (SDPs). Establishing system architectures, baseline designs, and technical direction. Creating & tracking project task and resource scheduling, costs, resource utilization, and metrics (e.g., Earned Value Analysis). Preparing proposals in response to RFPs and SOWs. Project Management • Microsoft Project, Excel, Word, PowerPoint, Visio & Documentation: • Adobe Acrobat Professional -

Static Program Analysis Via 3-Valued Logic
Static Program Analysis via 3-Valued Logic ¡ ¢ £ Thomas Reps , Mooly Sagiv , and Reinhard Wilhelm ¤ Comp. Sci. Dept., University of Wisconsin; [email protected] ¥ School of Comp. Sci., Tel Aviv University; [email protected] ¦ Informatik, Univ. des Saarlandes;[email protected] Abstract. This paper reviews the principles behind the paradigm of “abstract interpretation via § -valued logic,” discusses recent work to extend the approach, and summarizes on- going research aimed at overcoming remaining limitations on the ability to create program- analysis algorithms fully automatically. 1 Introduction Static analysis concerns techniques for obtaining information about the possible states that a program passes through during execution, without actually running the program on specific inputs. Instead, static-analysis techniques explore a program’s behavior for all possible inputs and all possible states that the program can reach. To make this feasible, the program is “run in the aggregate”—i.e., on abstract descriptors that repre- sent collections of many states. In the last few years, researchers have made important advances in applying static analysis in new kinds of program-analysis tools for identi- fying bugs and security vulnerabilities [1–7]. In these tools, static analysis provides a way in which properties of a program’s behavior can be verified (or, alternatively, ways in which bugs and security vulnerabilities can be detected). Static analysis is used to provide a safe answer to the question “Can the program reach a bad state?” Despite these successes, substantial challenges still remain. In particular, pointers and dynamically-allocated storage are features of all modern imperative programming languages, but their use is error-prone: ¨ Dereferencing NULL-valued pointers and accessing previously deallocated stor- age are two common programming mistakes. -

Survey of Verification and Validation Techniques for Small Satellite Software Development
Survey of Verification and Validation Techniques for Small Satellite Software Development Stephen A. Jacklin NASA Ames Research Center Presented at the 2015 Space Tech Expo Conference May 19-21, Long Beach, CA Summary The purpose of this paper is to provide an overview of the current trends and practices in small-satellite software verification and validation. This document is not intended to promote a specific software assurance method. Rather, it seeks to present an unbiased survey of software assurance methods used to verify and validate small satellite software and to make mention of the benefits and value of each approach. These methods include simulation and testing, verification and validation with model-based design, formal methods, and fault-tolerant software design with run-time monitoring. Although the literature reveals that simulation and testing has by far the longest legacy, model-based design methods are proving to be useful for software verification and validation. Some work in formal methods, though not widely used for any satellites, may offer new ways to improve small satellite software verification and validation. These methods need to be further advanced to deal with the state explosion problem and to make them more usable by small-satellite software engineers to be regularly applied to software verification. Last, it is explained how run-time monitoring, combined with fault-tolerant software design methods, provides an important means to detect and correct software errors that escape the verification process or those errors that are produced after launch through the effects of ionizing radiation. Introduction While the space industry has developed very good methods for verifying and validating software for large communication satellites over the last 50 years, such methods are also very expensive and require large development budgets. -

An Eclipse Plug-In for Testing and Debugging
GZoltar: An Eclipse Plug-In for Testing and Debugging José Campos André Riboira Alexandre Perez Rui Abreu Department of Informatics Engineering Faculty of Engineering, University of Porto Portugal {jose.carlos.campos, andre.riboira, alexandre.perez}@fe.up.pt; [email protected] ABSTRACT coverage). Several debugging tools exist which are based on Testing and debugging is the most expensive, error-prone stepping through the execution of the program (e.g., GDB phase in the software development life cycle. Automated and DDD). These traditional, manual fault localization ap- testing and diagnosis of software faults can drastically proaches have a number of important limitations. The place- improve the efficiency of this phase, this way improving ment of print statements as well as the inspection of their the overall quality of the software. In this paper we output are unstructured and ad-hoc, and are typically based present a toolset for automatic testing and fault localiza- on the developer's intuition. In addition, developers tend to use only test cases that reveal the failure, and therefore do tion, dubbed GZoltar, which hosts techniques for (regres- sion) test suite minimization and automatic fault diagno- not use valuable information from (the typically available) sis (namely, spectrum-based fault localization). The toolset passing test cases. provides the infrastructure to automatically instrument the Aimed at drastic cost reduction, much research has been source code of software programs to produce runtime data. performed in developing automatic testing and fault local- Subsequently the data was analyzed to both minimize the ization techniques and tools. As far as testing is concerned, test suite and return a ranked list of diagnosis candidates. -

Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK
1 From Start-ups to Scale-ups: Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK Abstract—This paper1 describes some of the challenges and research questions that target the most productive intersection opportunities when deploying static and dynamic analysis at we have yet witnessed: that between exciting, intellectually scale, drawing on the authors’ experience with the Infer and challenging science, and real-world deployment impact. Sapienz Technologies at Facebook, each of which started life as a research-led start-up that was subsequently deployed at scale, Many industrialists have perhaps tended to regard it unlikely impacting billions of people worldwide. that much academic work will prove relevant to their most The paper identifies open problems that have yet to receive pressing industrial concerns. On the other hand, it is not significant attention from the scientific community, yet which uncommon for academic and scientific researchers to believe have potential for profound real world impact, formulating these that most of the problems faced by industrialists are either as research questions that, we believe, are ripe for exploration and that would make excellent topics for research projects. boring, tedious or scientifically uninteresting. This sociological phenomenon has led to a great deal of miscommunication between the academic and industrial sectors. I. INTRODUCTION We hope that we can make a small contribution by focusing on the intersection of challenging and interesting scientific How do we transition research on static and dynamic problems with pressing industrial deployment needs. Our aim analysis techniques from the testing and verification research is to move the debate beyond relatively unhelpful observations communities to industrial practice? Many have asked this we have typically encountered in, for example, conference question, and others related to it. -

DEVELOPING SECURE SOFTWARE T in an AGILE PROCESS Dejan
Software - in an - in Software Developing Secure aBSTRACT Background: Software developers are facing in- a real industry setting. As secondary methods for creased pressure to lower development time, re- data collection a variety of approaches have been Developing Secure Software lease new software versions more frequent to used, such as semi-structured interviews, work- customers and to adapt to a faster market. This shops, study of literature, and use of historical data - in an agile proceSS new environment forces developers and companies from the industry. to move from a plan based waterfall development process to a flexible agile process. By minimizing Results: The security engineering best practices the pre development planning and instead increa- were investigated though a series of case studies. a sing the communication between customers and The base agile and security engineering compati- gile developers, the agile process tries to create a new, bility was assessed in literature, by developers and more flexible way of working. This new way of in practical studies. The security engineering best working allows developers to focus their efforts on practices were group based on their purpose and p the features that customers want. With increased their compatibility with the agile process. One well roce connectability and the faster feature release, the known and popular best practice, automated static Dejan Baca security of the software product is stressed. To de- code analysis, was toughly investigated for its use- velop secure software, many companies use secu- fulness, deployment and risks of using as part of SS rity engineering processes that are plan heavy and the process. -

Using Static Program Analysis to Aid Intrusion Detection
Using Static Program Analysis to Aid Intrusion Detection Manuel Egele, Martin Szydlowski, Engin Kirda, and Christopher Kruegel Secure Systems Lab Technical University Vienna fpizzaman,msz,ek,[email protected] Abstract. The Internet, and in particular the world-wide web, have be- come part of the everyday life of millions of people. With the growth of the web, the demand for on-line services rapidly increased. Today, whole industry branches rely on the Internet to do business. Unfortunately, the success of the web has recently been overshadowed by frequent reports of security breaches. Attackers have discovered that poorly written web applications are the Achilles heel of many organizations. The reason is that these applications are directly available through firewalls and are of- ten developed by programmers who focus on features and tight schedules instead of security. In previous work, we developed an anomaly-based intrusion detection system that uses learning techniques to identify attacks against web- based applications. That system focuses on the analysis of the request parameters in client queries, but does not take into account any infor- mation about the protected web applications themselves. The result are imprecise models that lead to more false positives and false negatives than necessary. In this paper, we describe a novel static source code analysis approach for PHP that allows us to incorporate information about a web application into the intrusion detection models. The goal is to obtain a more precise characterization of web request parameters by analyzing their usage by the program. This allows us to generate more precise intrusion detection models. -

Engineering of Reliable and Secure Software Via Customizable Integrated Compilation Systems
Engineering of Reliable and Secure Software via Customizable Integrated Compilation Systems Zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften von der KIT-Fakultät für Informatik des Karlsruher Institut für Technologie (KIT) genehmigte Dissertation von Dipl.-Inf. Oliver Scherer Tag der mündlichen Prüfung: 06.05.2021 1. Referent: Prof. Dr. Veit Hagenmeyer 2. Referent: Prof. Dr. Ralf Reussner This document is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0): https://creativecommons.org/licenses/by-sa/4.0/deed.en Abstract Lack of software quality can cause enormous unpredictable costs. Many strategies exist to prevent or detect defects as early in the development process as possible and can generally be separated into proactive and reactive measures. Proactive measures in this context are schemes where defects are avoided by planning a project in a way that reduces the probability of mistakes. They are expensive upfront without providing a directly visible benefit, have low acceptance by developers or don’t scale with the project. On the other hand, purely reactive measures only fix bugs as they are found and thus do not yield any guarantees about the correctness of the project. In this thesis, a new method is introduced, which allows focusing on the project specific issues and decreases the discrepancies between the abstract system model and the final software product. The first component of this method isa system that allows any developer in a project to implement new static analyses and integrate them into the project. The integration is done in a manner that automatically prevents any other project developer from accidentally violating the rule that the new static analysis checks.