Exponential Smoothing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 2 Time Series and Forecasting
Chapter 2 Time series and Forecasting 2.1 Introduction Data are frequently recorded at regular time intervals, for instance, daily stock market indices, the monthly rate of inflation or annual profit figures. In this Chapter we think about how to display and model such data. We will consider how to detect trends and seasonal effects and then use these to make forecasts. As well as review the methods covered in MAS1403, we will also consider a class of time series models known as autore- gressive moving average models. Why is this topic useful? Well, making forecasts allows organisations to make better decisions and to plan more efficiently. For instance, reliable forecasts enable a retail outlet to anticipate demand, hospitals to plan staffing levels and manufacturers to keep appropriate levels of inventory. 2.2 Displaying and describing time series A time series is a collection of observations made sequentially in time. When observations are made continuously, the time series is said to be continuous; when observations are taken only at specific time points, the time series is said to be discrete. In this course we consider only discrete time series, where the observations are taken at equal intervals. The first step in the analysis of time series is usually to plot the data against time, in a time series plot. Suppose we have the following four–monthly sales figures for Turner’s Hangover Cure as described in Practical 2 (in thousands of pounds): Jan–Apr May–Aug Sep–Dec 2006 8 10 13 2007 10 11 14 2008 10 11 15 2009 11 13 16 We could enter these data into a single column (say column C1) in Minitab, and then click on Graph–Time Series Plot–Simple–OK; entering C1 in Series and then clicking OK gives the graph shown in figure 2.1. -

Demand Forecasting
BIZ2121 Production & Operations Management Demand Forecasting Sung Joo Bae, Associate Professor Yonsei University School of Business Unilever Customer Demand Planning (CDP) System Statistical information: shipment history, current order information Demand-planning system with promotional demand increase, and other detailed information (external market research, internal sales projection) Forecast information is relayed to different distribution channel and other units Connecting to POS (point-of-sales) data and comparing it to forecast data is a very valuable ways to update the system Results: reduced inventory, better customer service Forecasting Forecasts are critical inputs to business plans, annual plans, and budgets Finance, human resources, marketing, operations, and supply chain managers need forecasts to plan: ◦ output levels ◦ purchases of services and materials ◦ workforce and output schedules ◦ inventories ◦ long-term capacities Forecasting Forecasts are made on many different variables ◦ Uncertain variables: competitor strategies, regulatory changes, technological changes, processing times, supplier lead times, quality losses ◦ Different methods are used Judgment, opinions of knowledgeable people, average of experience, regression, and time-series techniques ◦ No forecast is perfect Constant updating of plans is important Forecasts are important to managing both processes and supply chains ◦ Demand forecast information can be used for coordinating the supply chain inputs, and design of the internal processes (especially -

Design of Observational Studies (Springer Series in Statistics)
Springer Series in Statistics Advisors: P. Bickel, P. Diggle, S. Fienberg, U. Gather, I. Olkin, S. Zeger For other titles published in this series, go to http://www.springer.com/series/692 Paul R. Rosenbaum Design of Observational Studies 123 Paul R. Rosenbaum Statistics Department Wharton School University of Pennsylvania Philadelphia, PA 19104-6340 USA [email protected] ISBN 978-1-4419-1212-1 e-ISBN 978-1-4419-1213-8 DOI 10.1007/978-1-4419-1213-8 Springer New York Dordrecht Heidelberg London Library of Congress Control Number: 2009938109 c Springer Science+Business Media, LLC 2010 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is a part of Springer Science+Business Media (www.springer.com). For Judy “Simplicity of form is not necessarily simplicity of experience.” Robert Morris, writing about art. “Simplicity is not a given. It is an achievement.” William H. -

Moving Average Filters
CHAPTER 15 Moving Average Filters The moving average is the most common filter in DSP, mainly because it is the easiest digital filter to understand and use. In spite of its simplicity, the moving average filter is optimal for a common task: reducing random noise while retaining a sharp step response. This makes it the premier filter for time domain encoded signals. However, the moving average is the worst filter for frequency domain encoded signals, with little ability to separate one band of frequencies from another. Relatives of the moving average filter include the Gaussian, Blackman, and multiple- pass moving average. These have slightly better performance in the frequency domain, at the expense of increased computation time. Implementation by Convolution As the name implies, the moving average filter operates by averaging a number of points from the input signal to produce each point in the output signal. In equation form, this is written: EQUATION 15-1 Equation of the moving average filter. In M &1 this equation, x[ ] is the input signal, y[ ] is ' 1 % y[i] j x [i j ] the output signal, and M is the number of M j'0 points used in the moving average. This equation only uses points on one side of the output sample being calculated. Where x[ ] is the input signal, y[ ] is the output signal, and M is the number of points in the average. For example, in a 5 point moving average filter, point 80 in the output signal is given by: x [80] % x [81] % x [82] % x [83] % x [84] y [80] ' 5 277 278 The Scientist and Engineer's Guide to Digital Signal Processing As an alternative, the group of points from the input signal can be chosen symmetrically around the output point: x[78] % x[79] % x[80] % x[81] % x[82] y[80] ' 5 This corresponds to changing the summation in Eq. -

Time Series and Forecasting
Time Series and Forecasting Time Series • A time series is a sequence of measurements over time, usually obtained at equally spaced intervals – Daily – Monthly – Quarterly – Yearly 1 Time Series Example Dow Jones Industrial Average 12000 11000 10000 9000 Closing Value Closing 8000 7000 1/3/00 5/3/00 9/3/00 1/3/01 5/3/01 9/3/01 1/3/02 5/3/02 9/3/02 1/3/03 5/3/03 9/3/03 Date Components of a Time Series • Secular Trend –Linear – Nonlinear • Cyclical Variation – Rises and Falls over periods longer than one year • Seasonal Variation – Patterns of change within a year, typically repeating themselves • Residual Variation 2 Components of a Time Series Y=T+C+S+Rtt tt t Time Series with Linear Trend Yt = a + b t + et 3 Time Series with Linear Trend AOL Subscribers 30 25 20 15 10 5 Number of Subscribers (millions) 0 2341234123412341234123 1995 1996 1997 1998 1999 2000 Quarter Time Series with Linear Trend Average Daily Visits in August to Emergency Room at Richmond Memorial Hospital 140 120 100 80 60 40 Average Daily Visits Average Daily 20 0 12345678910 Year 4 Time Series with Nonlinear Trend Imports 180 160 140 120 100 80 Imports (MM) Imports 60 40 20 0 1986 1988 1990 1992 1994 1996 1998 Year Time Series with Nonlinear Trend • Data that increase by a constant amount at each successive time period show a linear trend. • Data that increase by increasing amounts at each successive time period show a curvilinear trend. • Data that increase by an equal percentage at each successive time period can be made linear by applying a logarithmic transformation. -

19 Apr 2021 Model Combinations Through Revised Base-Rates
Model combinations through revised base-rates Fotios Petropoulos School of Management, University of Bath UK and Evangelos Spiliotis Forecasting and Strategy Unit, School of Electrical and Computer Engineering, National Technical University of Athens, Greece and Anastasios Panagiotelis Discipline of Business Analytics, University of Sydney, Australia April 21, 2021 Abstract Standard selection criteria for forecasting models focus on information that is calculated for each series independently, disregarding the general tendencies and performances of the candidate models. In this paper, we propose a new way to sta- tistical model selection and model combination that incorporates the base-rates of the candidate forecasting models, which are then revised so that the per-series infor- arXiv:2103.16157v2 [stat.ME] 19 Apr 2021 mation is taken into account. We examine two schemes that are based on the pre- cision and sensitivity information from the contingency table of the base rates. We apply our approach on pools of exponential smoothing models and a large number of real time series and we show that our schemes work better than standard statisti- cal benchmarks. We discuss the connection of our approach to other cross-learning approaches and offer insights regarding implications for theory and practice. Keywords: forecasting, model selection/averaging, information criteria, exponential smooth- ing, cross-learning. 1 1 Introduction Model selection and combination have long been fundamental ideas in forecasting for business and economics (see Inoue and Kilian, 2006; Timmermann, 2006, and ref- erences therein for model selection and combination respectively). In both research and practice, selection and/or the combination weight of a forecasting model are case-specific. -

Penalised Regressions Vs. Autoregressive Moving Average Models for Forecasting Inflation Regresiones Penalizadas Vs
ECONÓMICAS . Ospina-Holguín y Padilla-Ospina / Económicas CUC, vol. 41 no. 1, pp. 65 -80, Enero - Junio, 2020 CUC Penalised regressions vs. autoregressive moving average models for forecasting inflation Regresiones penalizadas vs. modelos autorregresivos de media móvil para pronosticar la inflación DOI: https://doi.org/10.17981/econcuc.41.1.2020.Econ.3 Abstract This article relates the Seasonal Autoregressive Moving Average Artículo de investigación. Models (SARMA) to linear regression. Based on this relationship, the Fecha de recepción: 07/10/2019. paper shows that penalized linear models can outperform the out-of- Fecha de aceptación: 10/11/2019. sample forecast accuracy of the best SARMA models in forecasting Fecha de publicación: 15/11/2019 inflation as a function of past values, due to penalization and cross- validation. The paper constructs a minimal functional example using edge regression to compare both competing approaches to forecasting monthly inflation in 35 selected countries of the Organization for Economic Cooperation and Development and in three groups of coun- tries. The results empirically test the hypothesis that penalized linear regression, and edge regression in particular, can outperform the best standard SARMA models calculated through a grid search when fore- casting inflation. Thus, a new and effective technique for forecasting inflation based on past values is provided for use by financial analysts and investors. The results indicate that more attention should be paid Javier Humberto Ospina-Holguín to automatic learning techniques for forecasting inflation time series, Universidad del Valle. Cali (Colombia) even as basic as penalized linear regressions, because of their superior [email protected] empirical performance. -

Exponential Smoothing – Trend & Seasonal
NCSS Statistical Software NCSS.com Chapter 467 Exponential Smoothing – Trend & Seasonal Introduction This module forecasts seasonal series with upward or downward trends using the Holt-Winters exponential smoothing algorithm. Two seasonal adjustment techniques are available: additive and multiplicative. Additive Seasonality Given observations X1 , X 2 ,, X t of a time series, the Holt-Winters additive seasonality algorithm computes an evolving trend equation with a seasonal adjustment that is additive. Additive means that the amount of the adjustment is constant for all levels (average value) of the series. The forecasting algorithm makes use of the following formulas: at = α( X t − Ft−s ) + (1 − α)(at−1 + bt−1 ) bt = β(at − at−1 ) + (1 − β)bt−1 Ft = γ ( X t − at ) + (1 − γ )Ft−s Here α , β , and γ are smoothing constants which are between zero and one. Again, at gives the y-intercept (or level) at time t, while bt is the slope at time t. The letter s represents the number of periods per year, so the quarterly data is represented by s = 4 and monthly data is represented by s = 12. The forecast at time T for the value at time T+k is aT + bT k + F[(T +k−1)/s]+1 . Here [(T+k-1)/s] is means the remainder after dividing T+k-1 by s. That is, this function gives the season (month or quarter) that the observation came from. Multiplicative Seasonality Given observations X1 , X 2 ,, X t of a time series, the Holt-Winters multiplicative seasonality algorithm computes an evolving trend equation with a seasonal adjustment that is multiplicative. -

Spatial Domain Low-Pass Filters
Low Pass Filtering Why use Low Pass filtering? • Remove random noise • Remove periodic noise • Reveal a background pattern 1 Effects on images • Remove banding effects on images • Smooth out Img-Img mis-registration • Blurring of image Types of Low Pass Filters • Moving average filter • Median filter • Adaptive filter 2 Moving Ave Filter Example • A single (very short) scan line of an image • {1,8,3,7,8} • Moving Ave using interval of 3 (must be odd) • First number (1+8+3)/3 =4 • Second number (8+3+7)/3=6 • Third number (3+7+8)/3=6 • First and last value set to 0 Two Dimensional Moving Ave 3 Moving Average of Scan Line 2D Moving Average Filter • Spatial domain filter • Places average in center • Edges are set to 0 usually to maintain size 4 Spatial Domain Filter Moving Average Filter Effects • Reduces overall variability of image • Lowers contrast • Noise components reduced • Blurs the overall appearance of image 5 Moving Average images Median Filter The median utilizes the median instead of the mean. The median is the middle positional value. 6 Median Example • Another very short scan line • Data set {2,8,4,6,27} interval of 5 • Ranked {2,4,6,8,27} • Median is 6, central value 4 -> 6 Median Filter • Usually better for filtering • - Less sensitive to errors or extremes • - Median is always a value of the set • - Preserves edges • - But requires more computation 7 Moving Ave vs. Median Filtering Adaptive Filters • Based on mean and variance • Good at Speckle suppression • Sigma filter best known • - Computes mean and std dev for window • - Values outside of +-2 std dev excluded • - If too few values, (<k) uses value to left • - Later versions use weighting 8 Adaptive Filters • Improvements to Sigma filtering - Chi-square testing - Weighting - Local order histogram statistics - Edge preserving smoothing Adaptive Filters 9 Final PowerPoint Numerical Slide Value (The End) 10. -

Exponential Smoothing Statlet.Pdf
STATGRAPHICS Centurion – Rev. 11/21/2013 Exponential Smoothing Statlet Summary ......................................................................................................................................... 1 Data Input........................................................................................................................................ 2 Statlet .............................................................................................................................................. 3 Output ............................................................................................................................................. 4 Calculations..................................................................................................................................... 6 Summary This Statlet applies various types of exponential smoothers to a time series. It generates forecasts with associated forecast limits. Using the Statlet controls, the user may interactively change the values of the smoothing parameters to examine their effect on the forecasts. The types of exponential smoothers included are: 1. Brown’s simple exponential smoothing with smoothing parameter . 2. Brown’s linear exponential smoothing with smoothing parameter . 3. Holt’s linear exponential smoothing with smoothing parameters and . 4. Brown’s quadratic exponential smoothing with smoothing parameter . 5. Winters’ seasonal exponential smoothing with smoothing parameters and . Sample StatFolio: expsmoothing.sgp Sample Data The data -
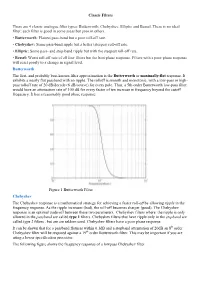
Classic Filters There Are 4 Classic Analogue Filter Types: Butterworth, Chebyshev, Elliptic and Bessel. There Is No Ideal Filter
Classic Filters There are 4 classic analogue filter types: Butterworth, Chebyshev, Elliptic and Bessel. There is no ideal filter; each filter is good in some areas but poor in others. • Butterworth: Flattest pass-band but a poor roll-off rate. • Chebyshev: Some pass-band ripple but a better (steeper) roll-off rate. • Elliptic: Some pass- and stop-band ripple but with the steepest roll-off rate. • Bessel: Worst roll-off rate of all four filters but the best phase response. Filters with a poor phase response will react poorly to a change in signal level. Butterworth The first, and probably best-known filter approximation is the Butterworth or maximally-flat response. It exhibits a nearly flat passband with no ripple. The rolloff is smooth and monotonic, with a low-pass or high- pass rolloff rate of 20 dB/decade (6 dB/octave) for every pole. Thus, a 5th-order Butterworth low-pass filter would have an attenuation rate of 100 dB for every factor of ten increase in frequency beyond the cutoff frequency. It has a reasonably good phase response. Figure 1 Butterworth Filter Chebyshev The Chebyshev response is a mathematical strategy for achieving a faster roll-off by allowing ripple in the frequency response. As the ripple increases (bad), the roll-off becomes sharper (good). The Chebyshev response is an optimal trade-off between these two parameters. Chebyshev filters where the ripple is only allowed in the passband are called type 1 filters. Chebyshev filters that have ripple only in the stopband are called type 2 filters , but are are seldom used. -

Review of Smoothing Methods for Enhancement of Noisy Data from Heavy-Duty LHD Mining Machines
E3S Web of Conferences 29, 00011 (2018) https://doi.org/10.1051/e3sconf/20182900011 XVIIth Conference of PhD Students and Young Scientists Review of smoothing methods for enhancement of noisy data from heavy-duty LHD mining machines Jacek Wodecki1, Anna Michalak2, and Paweł Stefaniak2 1Machinery Systems Division, Wroclaw University of Science and Technology, Wroclaw, Poland 2KGHM Cuprum R&D Ltd., Wroclaw, Poland Abstract. Appropriate analysis of data measured on heavy-duty mining machines is essential for processes monitoring, management and optimization. Some particular classes of machines, for example LHD (load-haul-dump) machines, hauling trucks, drilling/bolting machines etc. are characterized with cyclicity of operations. In those cases, identification of cycles and their segments or in other words – simply data segmen- tation is a key to evaluate their performance, which may be very useful from the man- agement point of view, for example leading to introducing optimization to the process. However, in many cases such raw signals are contaminated with various artifacts, and in general are expected to be very noisy, which makes the segmentation task very difficult or even impossible. To deal with that problem, there is a need for efficient smoothing meth- ods that will allow to retain informative trends in the signals while disregarding noises and other undesired non-deterministic components. In this paper authors present a review of various approaches to diagnostic data smoothing. Described methods can be used in a fast and efficient way, effectively cleaning the signals while preserving informative de- terministic behaviour, that is a crucial to precise segmentation and other approaches to industrial data analysis.