Voice and Audio Compression for Wireless Communications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Packetcable™ 2.0 Codec and Media Specification PKT-SP-CODEC
PacketCable™ 2.0 Codec and Media Specification PKT-SP-CODEC-MEDIA-I10-120412 ISSUED Notice This PacketCable specification is the result of a cooperative effort undertaken at the direction of Cable Television Laboratories, Inc. for the benefit of the cable industry and its customers. This document may contain references to other documents not owned or controlled by CableLabs. Use and understanding of this document may require access to such other documents. Designing, manufacturing, distributing, using, selling, or servicing products, or providing services, based on this document may require intellectual property licenses from third parties for technology referenced in this document. Neither CableLabs nor any member company is responsible to any party for any liability of any nature whatsoever resulting from or arising out of use or reliance upon this document, or any document referenced herein. This document is furnished on an "AS IS" basis and neither CableLabs nor its members provides any representation or warranty, express or implied, regarding the accuracy, completeness, noninfringement, or fitness for a particular purpose of this document, or any document referenced herein. 2006-2012 Cable Television Laboratories, Inc. All rights reserved. PKT-SP-CODEC-MEDIA-I10-120412 PacketCable™ 2.0 Document Status Sheet Document Control Number: PKT-SP-CODEC-MEDIA-I10-120412 Document Title: Codec and Media Specification Revision History: I01 - Released 04/05/06 I02 - Released 10/13/06 I03 - Released 09/25/07 I04 - Released 04/25/08 I05 - Released 07/10/08 I06 - Released 05/28/09 I07 - Released 07/02/09 I08 - Released 01/20/10 I09 - Released 05/27/10 I10 – Released 04/12/12 Date: April 12, 2012 Status: Work in Draft Issued Closed Progress Distribution Restrictions: Authors CL/Member CL/ Member/ Public Only Vendor Key to Document Status Codes: Work in Progress An incomplete document, designed to guide discussion and generate feedback, that may include several alternative requirements for consideration. -

TR-135 Data Model for a TR-069 Enabled STB
TECHNICAL REPORT TR-135 Data Model for a TR-069 Enabled STB Version: Issue 1 Version Date: December 2007 © The Broadband Forum. All rights reserved. Data Model for a TR-069 Enabled STB TR-135 Notice The Broadband Forum is a non-profit corporation organized to create guidelines for broadband network system development and deployment. This Technical Report has been approved by members of the Forum. This document is not binding on the Broadband Forum, any of its members, or any developer or service provider. This document is subject to change, but only with approval of members of the Forum. This document is provided "as is," with all faults. Any person holding a copyright in this document, or any portion thereof, disclaims to the fullest extent permitted by law any representation or warranty, express or implied, including, but not limited to, (a) any warranty of merchantability, fitness for a particular purpose, non-infringement, or title; (b) any warranty that the contents of the document are suitable for any purpose, even if that purpose is known to the copyright holder; (c) any warranty that the implementation of the contents of the documentation will not infringe any third party patents, copyrights, trademarks or other rights. This publication may incorporate intellectual property. The Broadband Forum encourages but does not require declaration of such intellectual property. For a list of declarations made by Broadband Forum member companies, please see www.broadband-forum.org. December 2007 © The Broadband Forum. All rights reserved. -

MPEG2+4 SDI Codec Manual-V6.Pdf
QVidium™ TECHNOLOGIES, INC. MPEG2+4 SDI IP Codec Model #QVSDI-11-IP User’s Manual v.6 March 24, 2008 Application Firmware Version 21 © 2007-2008 QVidium™ Technologies, Inc. 12989 Chaparral Ridge Road, San Diego, CA 92130 Phone 858.792.6407 • Fax 858.792.9131 User’s Manual v.6 QVidium™ MPEG2+4 SDI IP Codec Table of Contents 1 Introduction.............................................................................................................3 1.1 Overview...........................................................................................................3 1.2 Network Setup .................................................................................................3 1.3 Ping....................................................................................................................5 1.4 Passwords and Security.................................................................................6 1.5 Resetting to Default Settings .........................................................................6 1.6 Upgrading .........................................................................................................6 1.7 System View.....................................................................................................7 2 Encoder Configuration and Operation.............................................................9 2.1 Configuring the Encoder.................................................................................9 2.2 Starting the Encoder .......................................................................................9 -
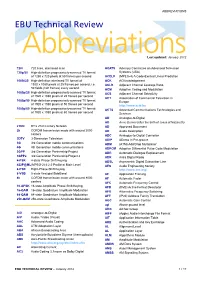
ABBREVIATIONS EBU Technical Review
ABBREVIATIONS EBU Technical Review AbbreviationsLast updated: January 2012 720i 720 lines, interlaced scan ACATS Advisory Committee on Advanced Television 720p/50 High-definition progressively-scanned TV format Systems (USA) of 1280 x 720 pixels at 50 frames per second ACELP (MPEG-4) A Code-Excited Linear Prediction 1080i/25 High-definition interlaced TV format of ACK ACKnowledgement 1920 x 1080 pixels at 25 frames per second, i.e. ACLR Adjacent Channel Leakage Ratio 50 fields (half frames) every second ACM Adaptive Coding and Modulation 1080p/25 High-definition progressively-scanned TV format ACS Adjacent Channel Selectivity of 1920 x 1080 pixels at 25 frames per second ACT Association of Commercial Television in 1080p/50 High-definition progressively-scanned TV format Europe of 1920 x 1080 pixels at 50 frames per second http://www.acte.be 1080p/60 High-definition progressively-scanned TV format ACTS Advanced Communications Technologies and of 1920 x 1080 pixels at 60 frames per second Services AD Analogue-to-Digital AD Anno Domini (after the birth of Jesus of Nazareth) 21CN BT’s 21st Century Network AD Approved Document 2k COFDM transmission mode with around 2000 AD Audio Description carriers ADC Analogue-to-Digital Converter 3DTV 3-Dimension Television ADIP ADress In Pre-groove 3G 3rd Generation mobile communications ADM (ATM) Add/Drop Multiplexer 4G 4th Generation mobile communications ADPCM Adaptive Differential Pulse Code Modulation 3GPP 3rd Generation Partnership Project ADR Automatic Dialogue Replacement 3GPP2 3rd Generation Partnership -

2250 G. Fernando Obsoletes: 2038 Sun Microsystems, Inc
Network Working Group D. Hoffman Request for Comments: 2250 G. Fernando Obsoletes: 2038 Sun Microsystems, Inc. Category: Standards Track V. Goyal Precept Software, Inc. M. Civanlar AT&T Labs - Research January 1998 RTP Payload Format for MPEG1/MPEG2 Video Status of this Memo This document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions for improvements. Please refer to the current edition of the "Internet Official Protocol Standards" (STD 1) for the standardization state and status of this protocol. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (1998). All Rights Reserved. Abstract This memo describes a packetization scheme for MPEG video and audio streams. The scheme proposed can be used to transport such a video or audio flow over the transport protocols supported by RTP. Two approaches are described. The first is designed to support maximum interoperability with MPEG System environments. The second is designed to provide maximum compatibility with other RTP-encapsulated media streams and future conference control work of the IETF. This memo is a revision of RFC 2038, an Internet standards track protocol. In this revision, the packet loss resilience mechanisms in Section 3.4 were extended to include additional picture header information required for MPEG2. A new section on security considerations for this payload type is added. Hoffman, et. al. Standards Track [Page 1] RFC 2250 RTP Format for MPEG1/MPEG2 Video January 1998 1. Introduction ISO/IEC JTC1/SC29 WG11 (also referred to as the MPEG committee) has defined the MPEG1 standard (ISO/IEC 11172)[1] and the MPEG2 standard (ISO/IEC 13818)[2]. -

Dialogic® Bordernet™ Virtualized Session Border Controller (SBC) Product Description Document
Dialogic® BorderNet™ Virtualized Session Border Controller (SBC) Product Description Document July 2013 www.dialogic.com Copyright and Legal Notice Copyright © 2011-2013 Dialogic Inc. All Rights Reserved. You may not reproduce this document in whole or in part without permission in writing from Dialogic Inc. at the address provided below. All contents of this document are furnished for informational use only and are subject to change without notice and do not represent a commitment on the part of Dialogic Inc. and its affiliates or subsidiaries (“Dialogic”). Reasonable effort is made to ensure the accuracy of the information contained in the document. However, Dialogic does not warrant the accuracy of this information and cannot accept responsibility for errors, inaccuracies or omissions that may be contained in this document. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH DIALOGIC® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN A SIGNED AGREEMENT BETWEEN YOU AND DIALOGIC, DIALOGIC ASSUMES NO LIABILITY WHATSOEVER, AND DIALOGIC DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF DIALOGIC PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY INTELLECTUAL PROPERTY RIGHT OF A THIRD PARTY. Dialogic products are not intended for use in certain safety-affecting situations. Please see http://www.dialogic.com/company/terms-of-use.aspx for more details. Due to differing national regulations and approval requirements, certain Dialogic products may be suitable for use only in specific countries, and thus may not function properly in other countries. -

User's Manual
USER’S MANUAL Information in this document is subject to change without notice. No part of this document may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, for any purpose, for any reason, without express written permission of HEURIS. The software described in this document is furnished under a license agreement. The software may be used or copied only in accordance with the terms and conditions of the agreements. It is against the law to copy the software on any medium except as specifically allowed in the license agreement. MPEG Power Professional™ User Manual Version 2.0 ©1999. HEURIS. All rights reserved. HEURIS PO Box 56914 St. Louis, MO 63156 MPEG Power Professional is a registered trademark of HEURIS. Avid Media Composer and OMF are registered trademarks of Avid Technology, Inc. QuickTime is a registered trademark of Apple, Inc. Media100 is a registered trademark of Data Translation. Windows 95/98, Windows NT, and Windows are trademarks of Microsoft Corporation. Adobe After Effects is a registered trademark of Adobe Systems. All other trademarks contained herein are the property of their respective owners. 2 INTRODUCTION 7 CHAPTER 1 Ð GETTING STARTED: ENCODING YOUR FIRST PROJECT 17 Chapter Overview 18 1.1 Exporting Your Media 18 1.2 Opening a New Project 18 1.3 Inserting a Task and Choosing Encoding Task 19 1.4 Choosing Encode Settings 20 1.5 Editing Encode Settings 20 1.6 Naming Your Destination File 20 1.7 Start Your Encode 21 1.8 Monitoring an Encoding -

QVAVC-HD Codec Manual-V23.Pdf
QVidium® TECHNOLOGIES, INC. H.264 HD Super-Codec™ Models: #QVAVC-HD, #QVAVC-HD-LITE, and #QVAVC-ANALOG User’s Manual v.23 January 25, 2011 Application Firmware Version 116 © 2009-2011 QVidium® Technologies, Inc. 12989 Chaparral Ridge Road, San Diego, CA 92130 Phone 858.792.6407 • Fax 858.792.9131 User’s Manual v.23 QVidium® H.264 HD Super-Codec™ Table of Contents 1 Introduction.............................................................................................................4 1.1 Overview...........................................................................................................4 1.2 Network Setup .................................................................................................4 1.3 Ping....................................................................................................................6 1.4 Passwords and Security.................................................................................7 1.5 Updating............................................................................................................7 1.6 System View.....................................................................................................8 2 Encoder Configuration.......................................................................................10 2.1 Configuring the Encoder - Overview...........................................................10 2.2 Basic Encoding Configuration......................................................................10 2.3 Configuring Packet Transport & Error -

MPEG-2 Video Transcoding
MPEG-2 Video Transcoding by Delbert Dueck Final report submitted in partial satisfaction of the requirements for the degree of Bachelor of Science in Computer Engineering in the Faculty of Engineering of the University of Manitoba Faculty and Industry Supervisors: Dr. Ken Ferens, Assistant Professor Fern Berard, Norsat International Inc. Spring 2001 © Copyright by Delbert Dueck, 2001. ABSTRACT Common sense dictates that as Internet connection speeds increase, so too does the bandwidth of commonly transmitted data. Presumably, this means that today’s Internet of text and images will evolve into an Internet with high-quality video conforming to the MPEG standard. This report begins by introducing MPEG, the MPEG-2 standard, and providing a description of the structure of an MPEG-2 video elementary stream. This is followed by a detailed examination of the MPEG-2 picture encoding process. The fourth chapter extends the encoding procedure by devel- oping and implementing an algorithm for transcoding pictures and video streams. Finally, pic- tures from transcoded video are evaluated and it is demonstrated that they retain much of the picture quality of the original high-bandwidth video encoding. ii ACKNOWLEDGEMENTS I would like to thank Dr. Ken Ferens for the assistance and guidance he gave over the course of this project. I would also like to acknowledge the contributions of Norsat International Inc., who provided me with the MPEG-2 standards documents on which this thesis is based. I also had the privilege of using their MPEG-2 video encoding hardware and software to produce the test bit streams used in this report. -

Episode Podcast 5.1.2 Administrator’S Guide
Note on License The accompanying Software is licensed and may not be distributed without writ- ten permission. Disclaimer The contents of this document are subject to revision without notice due to contin- ued progress in methodology, design, and manufacturing. Telestream shall have no liability for any error or damages of any kind resulting from the use of this document and/or software. The Software may contain errors and is not designed or intended for use in on-line facilities, aircraft navigation or communications systems, air traffic control, direct life support machines, or weapons systems (“High Risk Activities”) in which the failure of the Software would lead directly to death, personal injury or severe physical or environmental damage. You represent and warrant to Telestream that you will not use, distribute, or license the Software for High Risk Activities. Export Regulations. Software, including technical data, is subject to Swedish export control laws, and its associated regulations, and may be subject to export or import regulations in other countries. You agree to comply strictly with all such regulations and acknowledge that you have the responsibility to obtain licenses to export, re-export, or import Software. Copyright Statement ©Telestream, Inc, 2009 All rights reserved. No part of this document may be copied or distributed. This document is part of the software product and, as such, is part of the license agreement governing the software. So are any other parts of the software product, such as packaging and distribution media. The information in this document may be changed without prior notice and does not represent a commitment on the part of Telestream. -

Cinegy Convert 12 System Recommendations
Cinegy Convert 12 System Recommendations © Cinegy GmbH Document version: 6ae6f26 Table of Contents 1. General Recommendations . 1 1.1. Operating Systems Support. 1 1.2. NVidia Accelerated Encoding. 1 1.3. Hardware Recommendations. 2 2. Supported Codecs and File Formats . 3 2.1. Supported TV Formats. 3 2.2. Supported Media File Formats. 3 2.3. Supported Video Codecs . 4 2.4. Supported Audio Codecs . 4 2.5. File Formats Support . 4 2.6. Audio Formats Support . 5 Chapter 1. General Recommendations Chapter 1. General Recommendations 1.1. Operating Systems Support Cinegy Convert software is certified to run on the 64-bit editions of the following operating systems: • Windows Server 2016 • Windows Server 2019 • Windows 10 Enterprise • Windows 10 Pro Operating system recommendation: Windows Server 2019 is recommended for servers, Windows 10 Pro is recommended for workstations and desktop PCs. We recommend updating Windows OS to include the latest Microsoft updates and hotfixes. 1.2. NVidia Accelerated Encoding Cinegy Convert supports the hardware accelerated encoding for H.264 4:2:0, Cinegy Daniel2 and HEVC NVidia GPU video codecs. The codecs are highly recommended to use it for high-density output formats like HD/UHD. In order to be able to use the encoding hardware acceleration you will need to install the NVidia graphics board (based on Maxwell generation GPU) into the Convert server: • NVidia GeForce Series (started from GeForce 600) • NVidia Quadro Series Please note that the GeForce and lower Quadro Series (Quadro 600) has a limitation -

Recommendation Itu-R Br.1575
Rec. ITU-R BR.1575 1 RECOMMENDATION ITU-R BR.1575 Guide to the selection of digital video tape recording formats for studio production in the standard definition television (SDTV) environment based on production requirements (Question ITU-R 239/11) (2002) The ITU Radiocommunication Assembly, considering a) that digital video tape recording (VTR) formats for programme production are selected based on user requirements such as performance and operational requirements; b) that Recommendation ITU-R BR.657 – Digital television tape recording, standards for the international exchange of television programmes on magnetic tape, describes user requirements for digital television tape recorders, and is the basis for the standardization of D-1 format; c) that Recommendation ITU-R BR.1292 – Engineering guidelines for video recording in SDTV production and post-production chains, recommends engineering guidelines for television post-production; d) that Recommendation ITU-R BR.1356 – User requirements for application of compression in television production, lists user requirements for application of compression in television production, for bit rates up to 50 Mbit/s in particular; e) that Recommendation ITU-R BR.1376 – Compression families for use in recording and networked SDTV production, recommends compression based on intra-frame coding at a data rate close to 50 Mbit/s for mainstream applications which require high margin of quality overhead for post-production; f) that Recommendation ITU-R BR.1376 specifies the two compression families which meet the requirements in considering e) above: – DV-based 50 Mbit/s 4:2:2 intra-frame; – MPEG-2 4:2:2P@ML 50 Mbit/s intra-frame; g) that the two categories of programme production in standard definition television (SDTV) environment, the “high-end” and the “mainstream”, are identified based on the user’s requirements in Appendix 3 of Recommendation ITU-R BR.1376, 2 Rec.