Multimedia Stream Adaptation Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Packetcable™ 2.0 Codec and Media Specification PKT-SP-CODEC
PacketCable™ 2.0 Codec and Media Specification PKT-SP-CODEC-MEDIA-I10-120412 ISSUED Notice This PacketCable specification is the result of a cooperative effort undertaken at the direction of Cable Television Laboratories, Inc. for the benefit of the cable industry and its customers. This document may contain references to other documents not owned or controlled by CableLabs. Use and understanding of this document may require access to such other documents. Designing, manufacturing, distributing, using, selling, or servicing products, or providing services, based on this document may require intellectual property licenses from third parties for technology referenced in this document. Neither CableLabs nor any member company is responsible to any party for any liability of any nature whatsoever resulting from or arising out of use or reliance upon this document, or any document referenced herein. This document is furnished on an "AS IS" basis and neither CableLabs nor its members provides any representation or warranty, express or implied, regarding the accuracy, completeness, noninfringement, or fitness for a particular purpose of this document, or any document referenced herein. 2006-2012 Cable Television Laboratories, Inc. All rights reserved. PKT-SP-CODEC-MEDIA-I10-120412 PacketCable™ 2.0 Document Status Sheet Document Control Number: PKT-SP-CODEC-MEDIA-I10-120412 Document Title: Codec and Media Specification Revision History: I01 - Released 04/05/06 I02 - Released 10/13/06 I03 - Released 09/25/07 I04 - Released 04/25/08 I05 - Released 07/10/08 I06 - Released 05/28/09 I07 - Released 07/02/09 I08 - Released 01/20/10 I09 - Released 05/27/10 I10 – Released 04/12/12 Date: April 12, 2012 Status: Work in Draft Issued Closed Progress Distribution Restrictions: Authors CL/Member CL/ Member/ Public Only Vendor Key to Document Status Codes: Work in Progress An incomplete document, designed to guide discussion and generate feedback, that may include several alternative requirements for consideration. -

Audio/Video Transport Working Group
Audio/Video Transport Working Group 60th IETF – San Diego 1 - 6 August 2004 Colin Perkins <[email protected]> Magnus Westerlund <[email protected]> Mailing list: <[email protected]> Agenda - Tuesday Introduction and Status Update 15 RTCP XR MIB 15 RTP Payload/Generic FEC-Encoded Time-Sensitive Media 15 RTP Payload Formats for H.261 and H.263 15 RTP Payload Format for JPEG 2000 15 RTP Payload Format for VMR-WB 15 RTP Payload Format for AMR-WB+ 15 RTP Payload Format for 3GPP Timed Text 15 RTP Payload Format for Text Conversation 5 RTP and MIME types 25 Agenda - Wednesday Introduction 5 Framing RTP on Connection-Oriented Transport 10 RTCP Extensions for SSM 15 RTP Profile for RTCP-based Feedback 15 RTP Profile for TFRC 15 Req. for Transport of Video Control Commands 15 Header Compression over MPLS 15 A Multiplexing Mechanism for RTP 15 MRTP: Multi-Flow Real-time Transport Protocol 15 Intellectual Property When starting a presentation you MUST say if: • There is IPR associated with your draft • The restrictions listed in section 5 of RFC 3667 apply to your draft When asking questions or commenting on a draft: • You MUST disclose any IPR you know of relating to the technology under discussion Reference: RFC 3667/3668 and the “Note Well” text Document Status Standards Published: • STD 64: RTP: A Transport Protocol for Real-Time Application, RFC 3550 • STD 65: RTP Profile for Audio and Video Conferences with Minimal Control, RFC 3551 References MUST include STD number, example: H. Schulzrinne, et. al., "RTP: A Transport Protocol for Real-Time Applications", STD 64, RFC 3550, Internet Engineering Task Force, July 2003. -

TR-135 Data Model for a TR-069 Enabled STB
TECHNICAL REPORT TR-135 Data Model for a TR-069 Enabled STB Version: Issue 1 Version Date: December 2007 © The Broadband Forum. All rights reserved. Data Model for a TR-069 Enabled STB TR-135 Notice The Broadband Forum is a non-profit corporation organized to create guidelines for broadband network system development and deployment. This Technical Report has been approved by members of the Forum. This document is not binding on the Broadband Forum, any of its members, or any developer or service provider. This document is subject to change, but only with approval of members of the Forum. This document is provided "as is," with all faults. Any person holding a copyright in this document, or any portion thereof, disclaims to the fullest extent permitted by law any representation or warranty, express or implied, including, but not limited to, (a) any warranty of merchantability, fitness for a particular purpose, non-infringement, or title; (b) any warranty that the contents of the document are suitable for any purpose, even if that purpose is known to the copyright holder; (c) any warranty that the implementation of the contents of the documentation will not infringe any third party patents, copyrights, trademarks or other rights. This publication may incorporate intellectual property. The Broadband Forum encourages but does not require declaration of such intellectual property. For a list of declarations made by Broadband Forum member companies, please see www.broadband-forum.org. December 2007 © The Broadband Forum. All rights reserved. -

MPEG2+4 SDI Codec Manual-V6.Pdf
QVidium™ TECHNOLOGIES, INC. MPEG2+4 SDI IP Codec Model #QVSDI-11-IP User’s Manual v.6 March 24, 2008 Application Firmware Version 21 © 2007-2008 QVidium™ Technologies, Inc. 12989 Chaparral Ridge Road, San Diego, CA 92130 Phone 858.792.6407 • Fax 858.792.9131 User’s Manual v.6 QVidium™ MPEG2+4 SDI IP Codec Table of Contents 1 Introduction.............................................................................................................3 1.1 Overview...........................................................................................................3 1.2 Network Setup .................................................................................................3 1.3 Ping....................................................................................................................5 1.4 Passwords and Security.................................................................................6 1.5 Resetting to Default Settings .........................................................................6 1.6 Upgrading .........................................................................................................6 1.7 System View.....................................................................................................7 2 Encoder Configuration and Operation.............................................................9 2.1 Configuring the Encoder.................................................................................9 2.2 Starting the Encoder .......................................................................................9 -

RFC 8872: Guidelines for Using the Multiplexing Features of RTP To
Stream: Internet Engineering Task Force (IETF) RFC: 8872 Category: Informational Published: January 2021 ISSN: 2070-1721 Authors: M. Westerlund B. Burman C. Perkins H. Alvestrand R. Even Ericsson Ericsson University of Glasgow Google RFC 8872 Guidelines for Using the Multiplexing Features of RTP to Support Multiple Media Streams Abstract The Real-time Transport Protocol (RTP) is a flexible protocol that can be used in a wide range of applications, networks, and system topologies. That flexibility makes for wide applicability but can complicate the application design process. One particular design question that has received much attention is how to support multiple media streams in RTP. This memo discusses the available options and design trade-offs, and provides guidelines on how to use the multiplexing features of RTP to support multiple media streams. Status of This Memo This document is not an Internet Standards Track specification; it is published for informational purposes. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Not all documents approved by the IESG are candidates for any level of Internet Standard; see Section 2 of RFC 7841. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at https://www.rfc-editor.org/info/rfc8872. Copyright Notice Copyright (c) 2021 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. -

RFC 3016 RTP Payload Format for MPEG-4 Audio/Visual November 2000
Network Working Group Y. Kikuchi Request for Comments: 3016 Toshiba Category: Standards Track T. Nomura NEC S. Fukunaga Oki Y. Matsui Matsushita H. Kimata NTT November 2000 RTP Payload Format for MPEG-4 Audio/Visual Streams Status of this Memo This document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions for improvements. Please refer to the current edition of the "Internet Official Protocol Standards" (STD 1) for the standardization state and status of this protocol. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (2000). All Rights Reserved. Abstract This document describes Real-Time Transport Protocol (RTP) payload formats for carrying each of MPEG-4 Audio and MPEG-4 Visual bitstreams without using MPEG-4 Systems. For the purpose of directly mapping MPEG-4 Audio/Visual bitstreams onto RTP packets, it provides specifications for the use of RTP header fields and also specifies fragmentation rules. It also provides specifications for Multipurpose Internet Mail Extensions (MIME) type registrations and the use of Session Description Protocol (SDP). 1. Introduction The RTP payload formats described in this document specify how MPEG-4 Audio [3][5] and MPEG-4 Visual streams [2][4] are to be fragmented and mapped directly onto RTP packets. These RTP payload formats enable transport of MPEG-4 Audio/Visual streams without using the synchronization and stream management functionality of MPEG-4 Systems [6]. Such RTP payload formats will be used in systems that have intrinsic stream management Kikuchi, et al. Standards Track [Page 1] RFC 3016 RTP Payload Format for MPEG-4 Audio/Visual November 2000 functionality and thus require no such functionality from MPEG-4 Systems. -

Dialogic® Bordernet™ Product Description
Dialogic® BorderNet™ Virtualized Session Border Controller Product Description Release 3.3.1 Dialogic® BorderNet™ Virtualized Session Border Controller Product Description Copyright and Legal Notice Copyright © 2013-2016 Dialogic Corporation. All Rights Reserved. You may not reproduce this document in whole or in part without permission in writing from Dialogic Corporation at the address provided below. All contents of this document are furnished for informational use only and are subject to change without notice and do not represent a commitment on the part of Dialogic Corporation and its affiliates or subsidiaries (“Dialogic”). Reasonable effort is made to ensure the accuracy of the information contained in the document. However, Dialogic does not warrant the accuracy of this information and cannot accept responsibility for errors, inaccuracies or omissions that may be contained in this document. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH DIALOGIC® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN A SIGNED AGREEMENT BETWEEN YOU AND DIALOGIC, DIALOGIC ASSUMES NO LIABILITY WHATSOEVER, AND DIALOGIC DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF DIALOGIC PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY INTELLECTUAL PROPERTY RIGHT OF A THIRD PARTY. Dialogic products are not intended for use in certain safety-affecting situations. Please see http://www.dialogic.com/company/terms-of- use.aspx for more details. Due to differing national regulations and approval requirements, certain Dialogic products may be suitable for use only in specific countries, and thus may not function properly in other countries. -
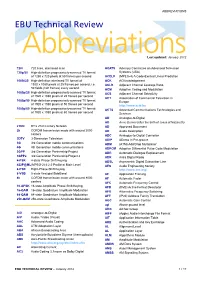
ABBREVIATIONS EBU Technical Review
ABBREVIATIONS EBU Technical Review AbbreviationsLast updated: January 2012 720i 720 lines, interlaced scan ACATS Advisory Committee on Advanced Television 720p/50 High-definition progressively-scanned TV format Systems (USA) of 1280 x 720 pixels at 50 frames per second ACELP (MPEG-4) A Code-Excited Linear Prediction 1080i/25 High-definition interlaced TV format of ACK ACKnowledgement 1920 x 1080 pixels at 25 frames per second, i.e. ACLR Adjacent Channel Leakage Ratio 50 fields (half frames) every second ACM Adaptive Coding and Modulation 1080p/25 High-definition progressively-scanned TV format ACS Adjacent Channel Selectivity of 1920 x 1080 pixels at 25 frames per second ACT Association of Commercial Television in 1080p/50 High-definition progressively-scanned TV format Europe of 1920 x 1080 pixels at 50 frames per second http://www.acte.be 1080p/60 High-definition progressively-scanned TV format ACTS Advanced Communications Technologies and of 1920 x 1080 pixels at 60 frames per second Services AD Analogue-to-Digital AD Anno Domini (after the birth of Jesus of Nazareth) 21CN BT’s 21st Century Network AD Approved Document 2k COFDM transmission mode with around 2000 AD Audio Description carriers ADC Analogue-to-Digital Converter 3DTV 3-Dimension Television ADIP ADress In Pre-groove 3G 3rd Generation mobile communications ADM (ATM) Add/Drop Multiplexer 4G 4th Generation mobile communications ADPCM Adaptive Differential Pulse Code Modulation 3GPP 3rd Generation Partnership Project ADR Automatic Dialogue Replacement 3GPP2 3rd Generation Partnership -

Preview - Click Here to Buy the Full Publication
This is a preview - click here to buy the full publication IEC 62481-2 ® Edition 2.0 2013-09 INTERNATIONAL STANDARD colour inside Digital living network alliance (DLNA) home networked device interoperability guidelines – Part 2: DLNA media formats INTERNATIONAL ELECTROTECHNICAL COMMISSION PRICE CODE XH ICS 35.100.05; 35.110; 33.160 ISBN 978-2-8322-0937-0 Warning! Make sure that you obtained this publication from an authorized distributor. ® Registered trademark of the International Electrotechnical Commission This is a preview - click here to buy the full publication – 2 – 62481-2 © IEC:2013(E) CONTENTS FOREWORD ......................................................................................................................... 20 INTRODUCTION ................................................................................................................... 22 1 Scope ............................................................................................................................. 23 2 Normative references ..................................................................................................... 23 3 Terms, definitions and abbreviated terms ....................................................................... 30 3.1 Terms and definitions ............................................................................................ 30 3.2 Abbreviated terms ................................................................................................. 34 3.4 Conventions ......................................................................................................... -

TANDBERG and H.323
SIP D50444 revision 1.1 May 2008 TANDBERG and SIP TABLE OF CONTENTS INTRODUCTION ........................................................................................................................................5 WHAT IS SIP?............................................................................................................................................6 Components ...............................................................................................................................................6 User Agent........................................................................................................................................6 Proxy Server.....................................................................................................................................6 Registrar...........................................................................................................................................7 Redirect Server ................................................................................................................................7 Requests for Comments.............................................................................................................................7 SIP Messages.............................................................................................................................................9 SIP Requests ...................................................................................................................................9 -

2250 G. Fernando Obsoletes: 2038 Sun Microsystems, Inc
Network Working Group D. Hoffman Request for Comments: 2250 G. Fernando Obsoletes: 2038 Sun Microsystems, Inc. Category: Standards Track V. Goyal Precept Software, Inc. M. Civanlar AT&T Labs - Research January 1998 RTP Payload Format for MPEG1/MPEG2 Video Status of this Memo This document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions for improvements. Please refer to the current edition of the "Internet Official Protocol Standards" (STD 1) for the standardization state and status of this protocol. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (1998). All Rights Reserved. Abstract This memo describes a packetization scheme for MPEG video and audio streams. The scheme proposed can be used to transport such a video or audio flow over the transport protocols supported by RTP. Two approaches are described. The first is designed to support maximum interoperability with MPEG System environments. The second is designed to provide maximum compatibility with other RTP-encapsulated media streams and future conference control work of the IETF. This memo is a revision of RFC 2038, an Internet standards track protocol. In this revision, the packet loss resilience mechanisms in Section 3.4 were extended to include additional picture header information required for MPEG2. A new section on security considerations for this payload type is added. Hoffman, et. al. Standards Track [Page 1] RFC 2250 RTP Format for MPEG1/MPEG2 Video January 1998 1. Introduction ISO/IEC JTC1/SC29 WG11 (also referred to as the MPEG committee) has defined the MPEG1 standard (ISO/IEC 11172)[1] and the MPEG2 standard (ISO/IEC 13818)[2]. -

Dialogic® Bordernet™ Virtualized Session Border Controller (SBC) Product Description Document
Dialogic® BorderNet™ Virtualized Session Border Controller (SBC) Product Description Document July 2013 www.dialogic.com Copyright and Legal Notice Copyright © 2011-2013 Dialogic Inc. All Rights Reserved. You may not reproduce this document in whole or in part without permission in writing from Dialogic Inc. at the address provided below. All contents of this document are furnished for informational use only and are subject to change without notice and do not represent a commitment on the part of Dialogic Inc. and its affiliates or subsidiaries (“Dialogic”). Reasonable effort is made to ensure the accuracy of the information contained in the document. However, Dialogic does not warrant the accuracy of this information and cannot accept responsibility for errors, inaccuracies or omissions that may be contained in this document. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH DIALOGIC® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN A SIGNED AGREEMENT BETWEEN YOU AND DIALOGIC, DIALOGIC ASSUMES NO LIABILITY WHATSOEVER, AND DIALOGIC DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF DIALOGIC PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY INTELLECTUAL PROPERTY RIGHT OF A THIRD PARTY. Dialogic products are not intended for use in certain safety-affecting situations. Please see http://www.dialogic.com/company/terms-of-use.aspx for more details. Due to differing national regulations and approval requirements, certain Dialogic products may be suitable for use only in specific countries, and thus may not function properly in other countries.