Combining Generic Programming with Vector Processing for Machine Vision
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Integers in C: an Open Invitation to Security Attacks?
Integers In C: An Open Invitation To Security Attacks? Zack Coker Samir Hasan Jeffrey Overbey [email protected] [email protected] [email protected] Munawar Hafiz Christian Kästnery [email protected] Auburn University yCarnegie Mellon University Auburn, AL, USA Pittsburgh, PA, USA ABSTRACT integer type is assigned to a location with a smaller type, We performed an empirical study to explore how closely e.g., assigning an int value to a short variable. well-known, open source C programs follow the safe C stan- Secure coding standards, such as MISRA's Guidelines for dards for integer behavior, with the goal of understanding the use of the C language in critical systems [37] and CERT's how difficult it is to migrate legacy code to these stricter Secure Coding in C and C++ [44], identify these issues that standards. We performed an automated analysis on fifty-two are otherwise allowed (and sometimes partially defined) in releases of seven C programs (6 million lines of preprocessed the C standard and impose restrictions on the use of inte- C code), as well as releases of Busybox and Linux (nearly gers. This is because most of the integer issues are benign. one billion lines of partially-preprocessed C code). We found But, there are two cases where the issues may cause serious that integer issues, that are allowed by the C standard but problems. One is in safety-critical sections, where untrapped not by the safer C standards, are ubiquitous|one out of four integer issues can lead to unexpected runtime behavior. An- integers were inconsistently declared, and one out of eight other is in security-critical sections, where integer issues can integers were inconsistently used. -

Understanding Integer Overflow in C/C++
Appeared in Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, June 2012. Understanding Integer Overflow in C/C++ Will Dietz,∗ Peng Li,y John Regehr,y and Vikram Adve∗ ∗Department of Computer Science University of Illinois at Urbana-Champaign fwdietz2,[email protected] ySchool of Computing University of Utah fpeterlee,[email protected] Abstract—Integer overflow bugs in C and C++ programs Detecting integer overflows is relatively straightforward are difficult to track down and may lead to fatal errors or by using a modified compiler to insert runtime checks. exploitable vulnerabilities. Although a number of tools for However, reliable detection of overflow errors is surprisingly finding these bugs exist, the situation is complicated because not all overflows are bugs. Better tools need to be constructed— difficult because overflow behaviors are not always bugs. but a thorough understanding of the issues behind these errors The low-level nature of C and C++ means that bit- and does not yet exist. We developed IOC, a dynamic checking tool byte-level manipulation of objects is commonplace; the line for integer overflows, and used it to conduct the first detailed between mathematical and bit-level operations can often be empirical study of the prevalence and patterns of occurrence quite blurry. Wraparound behavior using unsigned integers of integer overflows in C and C++ code. Our results show that intentional uses of wraparound behaviors are more common is legal and well-defined, and there are code idioms that than is widely believed; for example, there are over 200 deliberately use it. -

5. Data Types
IEEE FOR THE FUNCTIONAL VERIFICATION LANGUAGE e Std 1647-2011 5. Data types The e language has a number of predefined data types, including the integer and Boolean scalar types common to most programming languages. In addition, new scalar data types (enumerated types) that are appropriate for programming, modeling hardware, and interfacing with hardware simulators can be created. The e language also provides a powerful mechanism for defining OO hierarchical data structures (structs) and ordered collections of elements of the same type (lists). The following subclauses provide a basic explanation of e data types. 5.1 e data types Most e expressions have an explicit data type, as follows: — Scalar types — Scalar subtypes — Enumerated scalar types — Casting of enumerated types in comparisons — Struct types — Struct subtypes — Referencing fields in when constructs — List types — The set type — The string type — The real type — The external_pointer type — The “untyped” pseudo type Certain expressions, such as HDL objects, have no explicit data type. See 5.2 for information on how these expressions are handled. 5.1.1 Scalar types Scalar types in e are one of the following: numeric, Boolean, or enumerated. Table 17 shows the predefined numeric and Boolean types. Both signed and unsigned integers can be of any size and, thus, of any range. See 5.1.2 for information on how to specify the size and range of a scalar field or variable explicitly. See also Clause 4. 5.1.2 Scalar subtypes A scalar subtype can be named and created by using a scalar modifier to specify the range or bit width of a scalar type. -

Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code
Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code Jorge A. Navas, Peter Schachte, Harald Søndergaard, and Peter J. Stuckey Department of Computing and Information Systems, The University of Melbourne, Victoria 3010, Australia Abstract. Many compilers target common back-ends, thereby avoid- ing the need to implement the same analyses for many different source languages. This has led to interest in static analysis of LLVM code. In LLVM (and similar languages) most signedness information associated with variables has been compiled away. Current analyses of LLVM code tend to assume that either all values are signed or all are unsigned (except where the code specifies the signedness). We show how program analysis can simultaneously consider each bit-string to be both signed and un- signed, thus improving precision, and we implement the idea for the spe- cific case of integer bounds analysis. Experimental evaluation shows that this provides higher precision at little extra cost. Our approach turns out to be beneficial even when all signedness information is available, such as when analysing C or Java code. 1 Introduction The “Low Level Virtual Machine” LLVM is rapidly gaining popularity as a target for compilers for a range of programming languages. As a result, the literature on static analysis of LLVM code is growing (for example, see [2, 7, 9, 11, 12]). LLVM IR (Intermediate Representation) carefully specifies the bit- width of all integer values, but in most cases does not specify whether values are signed or unsigned. This is because, for most operations, two’s complement arithmetic (treating the inputs as signed numbers) produces the same bit-vectors as unsigned arithmetic. -

Generic Programming
Generic Programming July 21, 1998 A Dagstuhl Seminar on the topic of Generic Programming was held April 27– May 1, 1998, with forty seven participants from ten countries. During the meeting there were thirty seven lectures, a panel session, and several problem sessions. The outcomes of the meeting include • A collection of abstracts of the lectures, made publicly available via this booklet and a web site at http://www-ca.informatik.uni-tuebingen.de/dagstuhl/gpdag.html. • Plans for a proceedings volume of papers submitted after the seminar that present (possibly extended) discussions of the topics covered in the lectures, problem sessions, and the panel session. • A list of generic programming projects and open problems, which will be maintained publicly on the World Wide Web at http://www-ca.informatik.uni-tuebingen.de/people/musser/gp/pop/index.html http://www.cs.rpi.edu/˜musser/gp/pop/index.html. 1 Contents 1 Motivation 3 2 Standards Panel 4 3 Lectures 4 3.1 Foundations and Methodology Comparisons ........ 4 Fundamentals of Generic Programming.................. 4 Jim Dehnert and Alex Stepanov Automatic Program Specialization by Partial Evaluation........ 4 Robert Gl¨uck Evaluating Generic Programming in Practice............... 6 Mehdi Jazayeri Polytypic Programming........................... 6 Johan Jeuring Recasting Algorithms As Objects: AnAlternativetoIterators . 7 Murali Sitaraman Using Genericity to Improve OO Designs................. 8 Karsten Weihe Inheritance, Genericity, and Class Hierarchies.............. 8 Wolf Zimmermann 3.2 Programming Methodology ................... 9 Hierarchical Iterators and Algorithms................... 9 Matt Austern Generic Programming in C++: Matrix Case Study........... 9 Krzysztof Czarnecki Generative Programming: Beyond Generic Programming........ 10 Ulrich Eisenecker Generic Programming Using Adaptive and Aspect-Oriented Programming . -

RICH: Automatically Protecting Against Integer-Based Vulnerabilities
RICH: Automatically Protecting Against Integer-Based Vulnerabilities David Brumley, Tzi-cker Chiueh, Robert Johnson [email protected], [email protected], [email protected] Huijia Lin, Dawn Song [email protected], [email protected] Abstract against integer-based attacks. Integer bugs appear because programmers do not antici- We present the design and implementation of RICH pate the semantics of C operations. The C99 standard [16] (Run-time Integer CHecking), a tool for efficiently detecting defines about a dozen rules governinghow integer types can integer-based attacks against C programs at run time. C be cast or promoted. The standard allows several common integer bugs, a popular avenue of attack and frequent pro- cases, such as many types of down-casting, to be compiler- gramming error [1–15], occur when a variable value goes implementation specific. In addition, the written rules are out of the range of the machine word used to materialize it, not accompanied by an unambiguous set of formal rules, e.g. when assigning a large 32-bit int to a 16-bit short. making it difficult for a programmer to verify that he un- We show that safe and unsafe integer operations in C can derstands C99 correctly. Integer bugs are not exclusive to be captured by well-known sub-typing theory. The RICH C. Similar languages such as C++, and even type-safe lan- compiler extension compiles C programs to object code that guages such as Java and OCaml, do not raise exceptions on monitors its own execution to detect integer-based attacks. -

Java for Scientific Computing, Pros and Cons
Journal of Universal Computer Science, vol. 4, no. 1 (1998), 11-15 submitted: 25/9/97, accepted: 1/11/97, appeared: 28/1/98 Springer Pub. Co. Java for Scienti c Computing, Pros and Cons Jurgen Wol v. Gudenb erg Institut fur Informatik, Universitat Wurzburg wol @informatik.uni-wuerzburg.de Abstract: In this article we brie y discuss the advantages and disadvantages of the language Java for scienti c computing. We concentrate on Java's typ e system, investi- gate its supp ort for hierarchical and generic programming and then discuss the features of its oating-p oint arithmetic. Having found the weak p oints of the language we pro- p ose workarounds using Java itself as long as p ossible. 1 Typ e System Java distinguishes b etween primitive and reference typ es. Whereas this distinc- tion seems to b e very natural and helpful { so the primitives which comprise all standard numerical data typ es have the usual value semantics and expression concept, and the reference semantics of the others allows to avoid p ointers at all{ it also causes some problems. For the reference typ es, i.e. arrays, classes and interfaces no op erators are available or may b e de ned and expressions can only b e built by metho d calls. Several variables may simultaneously denote the same ob ject. This is certainly strange in a numerical setting, but not to avoid, since classes have to b e used to intro duce higher data typ es. On the other hand, the simple hierarchy of classes with the ro ot Object clearly b elongs to the advantages of the language. -

Programming Paradigms
PROGRAMMING PARADIGMS SNS COLLEGE OF TECHNOLOGY (An Autonomous Institution) COIMBATORE – 35 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING (UG & PG) Third Year Computer Science and Engineering, 4th Semester QUESTION BANK UNIVERSITY QUESTIONS Subject Code & Name: 16CS206 PROGRAMMING PARADIGMS UNIT-IV PART – A 1. What is an exception? .(DEC 2011-2m) An exception is an event, which occurs during the execution of a program, that disrupts the normal flow of the program's instructions. 2. What is error? .(DEC 2011-2m) An Error indicates that a non-recoverable condition has occurred that should not be caught. Error, a subclass of Throwable, is intended for drastic problems, such as OutOfMemoryError, which would be reported by the JVM itself. 3. Which is superclass of Exception? .(DEC 2011-2m) "Throwable", the parent class of all exception related classes. 4. What are the advantages of using exception handling? .(DEC 2012-2m) Exception handling provides the following advantages over "traditional" error management techniques: Separating Error Handling Code from "Regular" Code. Propagating Errors Up the Call Stack. Grouping Error Types and Error Differentiation. 5. What are the types of Exceptions in Java .(DEC 2012-2m) There are two types of exceptions in Java, unchecked exceptions and checked exceptions. Checked exceptions: A checked exception is some subclass of Exception (or Exception itself), excluding class RuntimeException and its subclasses. Each method must either SNSCT – Department of Compute Science and Engineering Page 1 PROGRAMMING PARADIGMS handle all checked exceptions by supplying a catch clause or list each unhandled checked exception as a thrown exception. Unchecked exceptions: All Exceptions that extend the RuntimeException class are unchecked exceptions. -
C Language Features
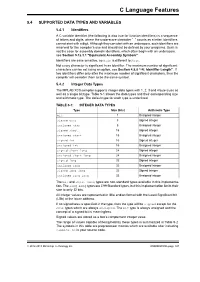
C Language Features 5.4 SUPPORTED DATA TYPES AND VARIABLES 5.4.1 Identifiers A C variable identifier (the following is also true for function identifiers) is a sequence of letters and digits, where the underscore character “_” counts as a letter. Identifiers cannot start with a digit. Although they can start with an underscore, such identifiers are reserved for the compiler’s use and should not be defined by your programs. Such is not the case for assembly domain identifiers, which often begin with an underscore, see Section 5.12.3.1 “Equivalent Assembly Symbols”. Identifiers are case sensitive, so main is different to Main. Not every character is significant in an identifier. The maximum number of significant characters can be set using an option, see Section 4.8.8 “-N: Identifier Length”. If two identifiers differ only after the maximum number of significant characters, then the compiler will consider them to be the same symbol. 5.4.2 Integer Data Types The MPLAB XC8 compiler supports integer data types with 1, 2, 3 and 4 byte sizes as well as a single bit type. Table 5-1 shows the data types and their corresponding size and arithmetic type. The default type for each type is underlined. TABLE 5-1: INTEGER DATA TYPES Type Size (bits) Arithmetic Type bit 1 Unsigned integer signed char 8 Signed integer unsigned char 8 Unsigned integer signed short 16 Signed integer unsigned short 16 Unsigned integer signed int 16 Signed integer unsigned int 16 Unsigned integer signed short long 24 Signed integer unsigned short long 24 Unsigned integer signed long 32 Signed integer unsigned long 32 Unsigned integer signed long long 32 Signed integer unsigned long long 32 Unsigned integer The bit and short long types are non-standard types available in this implementa- tion. -
Practical Integer Overflow Prevention
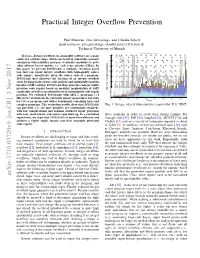
Practical Integer Overflow Prevention Paul Muntean, Jens Grossklags, and Claudia Eckert {paul.muntean, jens.grossklags, claudia.eckert}@in.tum.de Technical University of Munich Memory error vulnerabilities categorized 160 Abstract—Integer overflows in commodity software are a main Other Format source for software bugs, which can result in exploitable memory Pointer 140 Integer Heap corruption vulnerabilities and may eventually contribute to pow- Stack erful software based exploits, i.e., code reuse attacks (CRAs). In 120 this paper, we present INTGUARD, a symbolic execution based tool that can repair integer overflows with high-quality source 100 code repairs. Specifically, given the source code of a program, 80 INTGUARD first discovers the location of an integer overflow error by using static source code analysis and satisfiability modulo 60 theories (SMT) solving. INTGUARD then generates integer multi- precision code repairs based on modular manipulation of SMT 40 Number of VulnerabilitiesNumber of constraints as well as an extensible set of customizable code repair 20 patterns. We evaluated INTGUARD with 2052 C programs (≈1 0 Mil. LOC) available in the currently largest open-source test suite 2000 2002 2004 2006 2008 2010 2012 2014 2016 for C/C++ programs and with a benchmark containing large and Year complex programs. The evaluation results show that INTGUARD Fig. 1: Integer related vulnerabilities reported by U.S. NIST. can precisely (i.e., no false positives are accidentally repaired), with low computational and runtime overhead repair programs with very small binary and source code blow-up. In a controlled flows statically in order to avoid them during runtime. For experiment, we show that INTGUARD is more time-effective and example, Sift [35], TAP [56], SoupInt [63], AIC/CIT [74], and achieves a higher repair success rate than manually generated CIntFix [11] rely on a variety of techniques depicted in detail code repairs. -

Static Reflection
N3996- Static reflection Document number: N3996 Date: 2014-05-26 Project: Programming Language C++, SG7, Reflection Reply-to: Mat´uˇsChochl´ık([email protected]) Static reflection How to read this document The first two sections are devoted to the introduction to reflection and reflective programming, they contain some motivational examples and some experiences with usage of a library-based reflection utility. These can be skipped if you are knowledgeable about reflection. Section3 contains the rationale for the design decisions. The most important part is the technical specification in section4, the impact on the standard is discussed in section5, the issues that need to be resolved are listed in section7, and section6 mentions some implementation hints. Contents 1. Introduction4 2. Motivation and Scope6 2.1. Usefullness of reflection............................6 2.2. Motivational examples.............................7 2.2.1. Factory generator............................7 3. Design Decisions 11 3.1. Desired features................................. 11 3.2. Layered approach and extensibility...................... 11 3.2.1. Basic metaobjects........................... 12 3.2.2. Mirror.................................. 12 3.2.3. Puddle.................................. 12 3.2.4. Rubber................................. 13 3.2.5. Lagoon................................. 13 3.3. Class generators................................ 14 3.4. Compile-time vs. Run-time reflection..................... 16 4. Technical Specifications 16 4.1. Metaobject Concepts............................. -

Libraries for Generic Programming in Haskell
Libraries for Generic Programming in Haskell Johan Jeuring, Sean Leather, Jos´ePedroMagalh˜aes, and Alexey Rodriguez Yakushev Universiteit Utrecht, The Netherlands Abstract. These lecture notes introduce libraries for datatype-generic program- ming in Haskell. We introduce three characteristic generic programming libraries: lightweight implementation of generics and dynamics, extensible and modular generics for the masses, and scrap your boilerplate. We show how to use them to use and write generic programs. In the case studies for the different libraries we introduce generic components of a medium-sized application which assists a student in solving mathematical exercises. 1 Introduction In the development of software, structuring data plays an important role. Many pro- gramming methods and software development tools center around creating a datatype (or XML schema, UML model, class, grammar, etc.). Once the structure of the data has been designed, a software developer adds functionality to the datatypes. There is always some functionality that is specific for a datatype, and part of the reason why the datatype has been designed in the first place. Other functionality is similar or even the same on many datatypes, following common programming patterns. Examples of such patterns are: – in a possibly large value of a complicated datatype (for example for representing the structure of a company), applying a given action at all occurrences of a par- ticular constructor (e.g., adding or updating zip codes at all occurrences of street addresses) while leaving the rest of the value unchanged; – serializing a value of a datatype, or comparing two values of a datatype for equality, functionality that depends only on the structure of the datatype; – adapting data access functions after a datatype has changed, something that often involves modifying large amounts of existing code.