An Eagle's Eye View Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 . Call to Order New Mexico Commission for the Blind State Rehabilitation Council FINAL MINUTES Regular Meeting October 22
New Mexico Commission for the Blind State Rehabilitation Council FINAL MINUTES Regular Meeting October 22, 2018, 9:00 AM Commission for the Blind 2200 Yale Blvd SE Albuquerque, NM 87106 1 . Call to Order Chairman O'Brien called the meeting to order at 9:05 AM. 2. Roll Call and Introduction of New Members Roll was taken, and present were Bernadine Chavez, Kaity Ellis, (by phone), Urja Lansing, Coby Livingstone, Lila Martinez, Tom O'Brien, and Greg Trapp. Paula Seanez joined the meeting later. Not present were Lucy Birbiglia, Christine Hall, and Yolanda Montoya-Cordova. Mr. Trapp said that Paul Luttrell's appointment had expired, but that he was expecting him to be reappointed. 3. Introduction of Guests and Staff Staff present included Jim Salas, Deputy Director; Kelly Burma, Skills Center Coordinator; and Trish Adams, Executive Secretary. 4. Approval of Agenda Ms. Livingstone moved to approve the agenda, and Ms. Lansing seconded the motion. Mr. Trapp asked that the dormitory schedule item be moved up on the agenda to accommodate Ms. Mallahan's schedule. A vote was taken and the agenda approved unanimously. 5. Approval of Minutes of Meeting of September 18, 2018 Ms. Lansing moved to approve the minutes, and Ms. Ellis seconded the motion. A vote was taken and the agenda approved. Ms. Chavez abstained. 6. Chair Report, Tom O'Brien Mr. O'Brien said he appreciated the members making the effort to attend meetings, but that he would still like to have better participation. He said that he understood that work schedules can interfere with attendance. 7. -

Tid Bits Outreach Services Tid Bits September 1, 2006
Editor: Sherri D. Lyle, COMS/TVI/EDL NMSBVI, Department of Tid Bits Outreach Services Tid Bits September 1, 2006 The Changing Face of NMSBVI Outreach Programs Children who are blind or visually impaired Beginning in July 2006, NMSBVI has made the have so many, many needs as they progress next change in the process of serving students from infancy to adulthood. Never has it been who do not wish to attend the residential clearer to those in the field that it does, indeed, campus. The Outreach Program for school- ‘take a village’ to raise a child with blindness. In aged students has moved to Albuquerque and our efforts to meet the ever increasing societal joined with the Early Childhood Program to demands to educate children with their peers; create a solid, birth through twenty-one to, through our educational process, provide program, statewide, that serves our children. solid, competent members of the adult work The program is made up of the birth-to-three force; to ensure that all children have equal program, a preschool in Albuquerque that has opportunities to discover themselves and their operated since 1974 and the school-aged world, NMSBVI continues to look at the way we program. serve students in New Mexico. Outreach Services to Students in History Public Schools For the past several years NMSBVI, has Students who are blind/visually impaired and partnered with a variety of early intervention who attend public school, belong to that school organizations, educational institutions, families district. School districts are intensely committed and other stakeholders to develop programs to providing services that help their students that are far-reaching throughout the state and develop needed skills and competencies for that address the fluctuating needs of students graduation. -
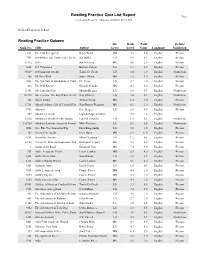
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Thursday, 05/20/10, 09:41 AM
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Thursday, 05/20/10, 09:41 AM Holden Elementary School Reading Practice Quizzes Int. Book Point Fiction/ Quiz No. Title Author Level Level Value Language Nonfiction 661 The 18th Emergency Betsy Byars MG 4.1 3.0 English Fiction 7351 20,000 Baseball Cards Under the Sea Jon Buller LG 2.6 0.5 English Fiction 11592 2095 Jon Scieszka MG 4.8 2.0 English Fiction 6201 213 Valentines Barbara Cohen LG 3.1 2.0 English Fiction 30629 26 Fairmount Avenue Tomie De Paola LG 4.4 1.0 English Nonfiction 166 4B Goes Wild Jamie Gilson MG 5.2 5.0 English Fiction 9001 The 500 Hats of Bartholomew CubbinsDr. Seuss LG 3.9 1.0 English Fiction 413 The 89th Kitten Eleanor Nilsson MG 4.3 2.0 English Fiction 11151 Abe Lincoln's Hat Martha Brenner LG 2.6 0.5 English Nonfiction 61248 Abe Lincoln: The Boy Who Loved BooksKay Winters LG 3.6 0.5 English Nonfiction 101 Abel's Island William Steig MG 6.2 3.0 English Fiction 13701 Abigail Adams: Girl of Colonial Days Jean Brown Wagoner MG 4.2 3.0 English Nonfiction 9751 Abiyoyo Pete Seeger LG 2.8 0.5 English Fiction 907 Abraham Lincoln Ingri & Edgar d'Aulaire 4.0 1.0 English 31812 Abraham Lincoln (Pebble Books) Lola M. Schaefer LG 1.5 0.5 English Nonfiction 102785 Abraham Lincoln: Sixteenth President Mike Venezia LG 5.9 0.5 English Nonfiction 6001 Ace: The Very Important Pig Dick King-Smith LG 5.0 3.0 English Fiction 102 Across Five Aprils Irene Hunt MG 8.9 11.0 English Fiction 7201 Across the Stream Mirra Ginsburg LG 1.2 0.5 English Fiction 17602 Across the Wide and Lonesome Prairie:Kristiana The Oregon Gregory Trail Diary.. -

Medicare and Medicaid Programs
Federal Register / Vol. 78, No. 131 / Tuesday, July 9, 2013 / Proposed Rules 41013 and its effects on visibility in Class I and in Page, Phoenix, and Tucson, DEPARTMENT OF HEALTH AND areas. Arizona. HUMAN SERVICES On February 5, 2013, EPA proposed a On June 20, 2013, SRP submitted a BART determination to require NGS to Centers for Medicare & Medicaid letter, on behalf of six stakeholders, achieve a nearly 80 percent reduction of Services requesting another extension of the its current overall NOX emission rate. 1 EPA also proposed an alternative to comment period for NGS. SRP 42 CFR Parts 431 describes working over the past several BART that would provide flexibility to [CMS–1450–CN] NGS in the schedule for the installation months with representatives from the of new post-combustion control Central Arizona Water Conservation RIN 0938–AR52 equipment. EPA’s proposed alternative District, the Environmental Defense to BART credits NGS for its early and Fund, the Gila River Indian Community, Medicare and Medicaid Programs; voluntary installation of new the Navajo Nation Environmental Home Health Prospective Payment System Rate Update for CY 2014, combustion controls to reduce NOX Protection Agency, and the U.S. emissions beginning in 2009. EPA, Department of the Interior to develop a Home Health Quality Reporting therefore, proposed to find that this BART alternative. SRP states that Requirements, and Cost Allocation of alternative achieves greater reasonable although significant progress has been Home Health Survey Expenses Correction progress than BART. made on the development of an In recognition that there may be other alternative, additional time is needed to AGENCY: Centers for Medicare & approaches that could result in finalize their alternative and submit it to Medicaid Services (CMS), HHS. -

PARCC Accessibility Features and Accomodations Manual
PARCC ACCESSIBILITY FEATURES AND ACCOMMODATIONS MANUAL Guidance for Districts and Decision-Making Teams to Ensure that PARCC Summative Assessments Produce Valid Results for All Students FOURTH EDITION Produced by: Partnership for Assessment of Readiness for College and Careers (PARCC) PARTNERSHIP FOR ASSESSMENT OF READINESS FOR COLLEGE AND CAREERS (PARCC) The Partnership for Assessment of Readiness for College and Careers (PARCC) is a group of states working together to develop a set of assessments that measure whether students are on track to be successful in college and their careers. These high-quality, computer-based K-12 assessments in mathematics and English language arts (ELA)/literacy give schools, teachers, students, and parents better information on whether students are on track in their learning and for success after high school, and tools to help teachers customize learning to meet student needs. The first full administration of the PARCC assessments occurred during the 2014-2015 school year. PARCC Accessibility Features and Accommodations Manual: Guidance for Districts and Decision-Making Teams to Ensure that PARCC Summative Assessments Produce Valid Results for All Students Fourth Edition (September 19, 2015) PARTNERSHIP FOR ASSESSMENT OF READINESS FOR COLLEGE AND CAREERS (PARCC) Available online at: http://avocet.pearson.com/PARCC/Home The contents of the PARCC Accessibility Features and Accommodations Manual (First Edition) were developed under a grant from the U.S. Department of Education. However, these contents do not necessarily represent the policy of the U.S. Department of Education and you should not assume endorsement by the Federal government. PARCC ACCESSIBILITY FEATURES AND ACCOMMODATIONS MANUAL – FOURTH EDITION 1 Acknowledgments This manual is the result of four years of work among states, Parcc Inc. -

PUBLIC NOTICE Federal Communications Commission Th News Media Information 202 / 418-0500 445 12 St., S.W
PUBLIC NOTICE Federal Communications Commission th News Media Information 202 / 418-0500 445 12 St., S.W. Internet: http://www.fcc.gov Washington, D.C. 20554 TTY: 1-888-835-5322 DA 15-103 Released: January 23, 2015 FCC SEEKS PUBLIC COMMENT ON SIXTH ANNUAL REPORT TO CONGRESS ON STATE COLLECTION AND DISTRIBUTION OF 911 AND ENHANCED 911 FEES AND CHARGES PS Docket No. 09-14 Comments Due: February 23, 2015 Reply Comments Due: March 24, 2015 The Federal Communications Commission (Commission) today releases to the public its Sixth Annual Report to Congress on State Collection and Distribution of 911 and Enhanced 911 Fees and Charges (Report). The Commission submits the Report to Congress annually pursuant to the New and Emerging Technologies 911 Improvement Act of 2008 (NET 911 Act), which requires that the Commission report whether 911 fees and charges collected by the states, the District of Columbia, U.S. territories, and Indian territories (states and other reporting entities) are being used for any purpose other than to support 911 and Enhanced 911 (E911) services. By this public notice, the Commission formally solicits public comment on the Report, the information provided to the Commission by states and other reporting entities, and the reported expenditure of funds for Next Generation 911 (NG911) services. The Report covers the collection and distribution of 911 and Enhanced 911 fees and charges for the calendar year ending December 31, 2013, and was submitted to Congress on December 31, 2014. A copy of the Report can be found on the Commission’s website at https://www.fcc.gov/encyclopedia/9-1- 1-and-e9-1-1-services. -

Watchtower Publications List
WATCHTOWER PUBLICATIONS LIST January 2011 This booklet contains a list of items currently available in the United States. © 2011 WATCH TOWER BIBLE AND TRACT SOCIETY OF PENNSYLVANIA All Rights Reserved Watchtower Publications List English (S-15-E Us) Made in the United States INTRODUCTION This Watchtower Publications List (S-15) is a listing of publications and languages available to con- gregations in your branch territory. After each monthly announcement to all congregations of new publi- cations available is received, please feel free to add the new publications to your list. This will help you to know quickly and easily what is currently available. Each item listed is preceded by a four-digit item number. To expedite and improve the handling of each congregation’s monthly literature request, please use the four-digit item number when requesting literature using the jw.org Web site or listing items on page 4 of the Literature Request Form (S-14). Special- request items, which are marked by an asterisk (*), should only be submitted when specifically requested by a publisher. Special-request items should not be stocked in anticipation of requests. Languages are listed alphabetically in the Watchtower Publications List, with the language that it is being generated in at the beginning. Items in the Watchtower Publications List are divided into appropriate categories for each language. Within each category, items are alphabetized by the first word in the title of the publication. The catego- ries are: Annual Items Dramas Calendars Empty -

Prose & Cons Braille
PROSE & CONS BRAILLE ,,PROSE @& ,,CONS ,,BRL SERVING THE BRAILLE COMMUNITY SINCE 1980 2018 CATALOG Braille Transcription (Literary, Textbook, Nemeth, & Music) Large Print Reproduction Braille Writer Repair PROSE AND CONS BRAILLE ATTN: Julie Erickson 800 Pioneers Blvd. Lincoln, Nebraska 68502-5335 Phone: (402) 471-3161 Ext. 3373 E-mail: [email protected] Website: www.csi.nebraska.gov Direct Link: https://csi.nebraska.gov/products/braille products Revised 6-13-2014 ABOUT PROSE & CONS BRAILLE In 1985 Cornhusker State Industries, the industries division of the Nebraska Department of Correctional Services, took over a small, but promising Braille project begun by the Nebraska State Penitentiary Five years earlier. In the twenty-five years since, Prose and Cons Braille has grown dramatically and now employs 30-35 men. Prose and Cons Braille performs essential tasks including Braille Transcribing, Tactile Graphics Design, Braille Writer Repair, Large Print Enlargement, and Thermoform Production. Prose and Cons Braille has enabled a number of workers to achieve formal Braille certifications through the Library of Congress. We have people certified in the following areas: Music, Nemeth, NBA Formats Course, Proofreading, and Literary Braille, as well as others who are currently working toward their Nemeth and Literary Braille certifications. Prose and Cons Braille is proud to offer quality transcription work with tactile diagrams for math, geography, science, and any other diagram that can be feasibly recreated in a tactile format. Our goal is to provide quality educational materials for school systems nationwide and continued expansion of our operation in order to better serve the blind and visually-impaired community. Our Braille/Large Print textbooks are listed on the American Printing House database LOUIS. -

(SIRS) Manual School Year
New York State Student Information Repository System (SIRS) Manual Reporting Data for the 2010–11 School Year October 15, 2010 Version 6.0 The University of the State of New York THE STATE EDUCATION DEPARTMENT Information and Reporting Services Albany, New York 12234 Revision History Revision History Version Date Revisions Initial Release. Please pay particular attention to revisions to guidance on: • Role of District Data Coordinator. • New race/ethnicity reporting rules. • New teacher/course reporting rules. • Implementation of new federal rules (one-day enrollment criterion, assignment of grade 9 entry date for ungraded students with a disability, and outcome status determinations for court placements of incarcerated students) for 2006 (non-accountability) and 2007 total cohort graduation October 15, 6.0 rate reporting purposes. 2010 • New Reason for Ending Enrollment Code 8338 – Incarcerated student, no participation in a program culminating in a regular diploma. • New test accommodation codes. • Deleted CTE Codes. • Student Grades, Staff Snapshot, Course, and Marking Period Templates. • Component Retests, SLPs, Reading First, and Grades 5 & 8 NYSTP and NYSAA Social Studies no longer available. ii Student Information Repository System Manual for 2010–11 Version 6.0 Table of Contents Table of Contents INTRODUCTION...........................................................................................................................................1 New York State Education Department E-mail Queries ..........................................................................3 -

The Sacramento/San Joaquin Literary Watershed": Charting the Publications of the Region's Small Presses and Regional Authors
"The Sacramento/San Joaquin Literary Watershed": Charting the Publications of the Region's Small Presses and Regional Authors. A Geographically Arranged Bibliography focused on the Publications of Regional Small Presses and Local Authors of the Sacramento and San Joaquin Valleys and Sierra Nevada. Second Edition. Revised and Expanded. John Sherlock University of California, Davis 2010 1 "The Sacramento/San Joaquin Literary Watershed": Regional Small Presses and Local Authors of the Sacramento and San Joaquin Valleys and Sierra Nevada TABLE OF CONTENTS. PUBLICATIONS OF REGIONAL SMALL PRESSES. Arranged Geographically by Place Of Publication. A. SACRAMENTO VALLEY SMALL PRESSES. 3 - 75 B. SAN JOAQUIN VALLEY SMALL PRESSES. 76 - 100 C. SIERRA NEVADA SMALL PRESSES. 101 - 127 D. SHASTA REGION SMALL PRESSES. 128 - 131 E. LITERARY MAGAZINES - CENTRAL VALLEY 132 - 145 F. LITERARY MAGAZINES - SIERRA NEVADA. 146 - 148 G. LOCAL AND REGIONAL ANTHOLOGIES. 149 - 155 PUBLICATIONS OF REGIONAL AUTHORS. Arranged Alphabetically by Author. REGIONAL AUTHORS. 156 - 253 APPENDIXES I. FICTION SET IN THE CENTRAL VALLEY. 254 - 262 II. FICTION SET IN THE SIERRA NEVADA. 263 - 272 III. SELECTED REGIONAL ANTHOLOGIES. 273 - 278 2 Part I. SACRAMENTO VALLEY SMALL LITERARY PRESSES. ANDERSON. DAVIS BUSINESS SERVICES (Anderson). BLACK, Donald J. In the Silence. [poetry] 1989 MORRIS PUB. (Anderson). ALDRICH, Linda. The Second Coming of Santa Claus and other stories. 2005 RIVER BEND BOOKS (Anderson, 1998). MADGIC, Bob. Pursuing Wilds Trout: a journey in wilderness values. 1998 SPRUCE CIRCLE PRESS (Anderson, 2002-present?). PECK, Barbara. Blue Mansion & Other Pieces of Time. 2002 PECK, Barbara. Vanishig Future: Forgotten Past. 2003 PECK, Barbara. Hot Shadows.: whispers from the vanished. -

HTML 4.0 Specification
HTML 4.0 Specification REC-html40-971218 HTML 4.0 Specification W3C Recommendation 18-Dec-1997 This version: http://www.w3.org/TR/REC-html40-971218 Latest version: http://www.w3.org/TR/REC-html40 Previous version: http://www.w3.org/TR/PR-html40-971107 Editors: Dave Raggett <[email protected]> Arnaud Le Hors <[email protected]> Ian Jacobs <[email protected]> Abstract This specification defines the HyperText Markup Language (HTML), version 4.0, the publishing language of the World Wide Web. In addition to the text, multimedia, and hyperlink features of the previous versions of HTML, HTML 4.0 supports more multimedia options, scripting languages, style sheets, better printing facilities, and documents that are more accessible to users with disabilities. HTML 4.0 also takes great strides towards the internationalization of documents, with the goal of making the Web truly World Wide. HTML 4.0 is an SGML application conforming to International Standard ISO 8879 -- Standard Generalized Markup Language [ISO8879] [p.323] . Status of this document This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C’s role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the Web. W3C recommends that user agents and authors (and in particular, authoring tools) produce HTML 4.0 documents rather than HTML 3.2 documents (see [HTML32] [p.325] ). -

Artwork Creation Guide Standardization for Digital Files
Artwork Creation Guide Standardization for Digital Files Artwork Creation Guide Standardization for Digital Files Disclaimer GlobalVision is a registered trademark of GlobalVision Inc. in Canada and/or other countries. All other company and product names are registered trademarks and/or trademarks of their respective owners. Artwork Creation Guide | Standardization for Digital Files This document contains information that is proprietary to the Artwork Creation Guide Group and the legal entity GlobalVision Inc. The work Artwork Creation Guide - Standardization for Digital Files is protected by copyright and/or other applicable laws. Any use of the work other than as authorized in writing or copyright law is prohibited. Contents I Preface ..................................................................................................................... 07 Section 1 Standardization ...................................................................................................... 09 1.1 Standardize on the operating system and its version ........................................ 11 1.2 Create a regular upgrade schedule for all software ........................................ 12 1.3 Standardize on office software ............................................................................ 13 1.4 Standardize on design software ........................................................................... 14 1.5 Centralize communication within the marketing department ........................ 15 Section 2 PDF Creation ...........................................................................................................