Table-To-Text Generation Via Row-Aware Hierarchical Encoder
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Probable Starters
UTAH JAZZ (35-30) at MEMPHIS GRIZZLIES (18-46) Game #66 • ROAD Game #34 • FedExForum • MEMPHIS March 9, 2018 • 6 p.m. (MT) • TV: AT&T SportsNet RADIO: 1280 AM/97.5 FM DATE OPP. TIME (MT) RECORD/TV 10/18 DEN W, 106-96 1-0 10/20 @MIN L, 97-100 1-1 LAST GAME’S STARTERS (2017-18 averages) 10/21 OKC W, 96-87 2-1 10/24 @LAC L, 84-102 2-2 • Notched first career double-double (11 points, 10/25 @PHX L, 88-97 2-3 career-high 10 assists) at IND on 3/7 10/28 LAL W, 96-81 3-3 PPG • 10.9 10/30 DAL W, 104-89 4-3 2 • Second in the league in three-point 11/1 POR W, 112-103 (OT) 5-3 RPG • 4.1 percentage (.445) 11/3 TOR L, 100-109 5-4 JOE INGLES • Has eight games this season with 5+ 3FG 11/5 @HOU L, 110-137 5-5 11/7 PHI L, 97-104 5-6 F • 6-8 • 226 • Australia APG • 4.3 • Appeared in his 200th straight game on 2/24 11/10 MIA L, 74-84 5-7 vs. DAL 11/11 BKN W, 114-106 6-7 11/13 MIN L, 98-109 6-8 • Has made a three-pointer in consecutive 11/15 @NYK L, 101-106 6-9 PPG • 12.2 games for just the second time in his career 11/17 @BKN L, 107-118 6-10 15 11/18 @ORL W, 125-85 7-10 RPG • 7.4 • Ranks seventh in Jazz history in blocked shots 11/20 @PHI L, 86-107 7-11 DERRICK FAVORS (641) 11/22 CHI W, 110-80 8-11 Jazz are 11-3 when he records a double- 11/25 MIL W, 121-108 9-11 • APG • 1.3 11/28 DEN W, 106-77 10-11 F • 6-10 • 265 • Georgia Tech double 11/30 @LAC W, 126-107 11-11 st 12/1 NOP W, 114-108 12-11 • Posted his 21 double-double of the season 12/4 WAS W, 116-69 13-11 27 PPG • 13.6 (23 points and 14 rebounds) at IND (3/7) 12/5 @OKC L, 94-100 13-12 • Made a career-high 12 free throws and scored 12/7 HOU L, 101-112 13-13 RPG • 10.5 12/9 @MIL L, 100-117 13-14 RUDY GOBERT a season-high 26 points vs. -

June 7 Redemption Update
SET SUBSET/INSERT # PLAYER 2019 Donruss Baseball Signature Series Pink Firework 27 Jonathan Loaisiga 2019 Donruss Baseball Signature Series Pink Firework 7 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures 15 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures Holo Silver 15 Michael Kopech 2019 Diamond Kings Baseball DK Material Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures Holo Blue 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Gold 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 36 Michael Kopech Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Purple 67 Yusei Kikuchi 2018 Chronicles Baseball Contenders Season Tickets Red 6 Gleyber Torres 2018 National Treasures Baseball Hometown Heroes 23 Aaron Judge 2018 National Treasures Baseball Hometown Heroes Platinum 23 Aaron Judge 2018 National Treasures Baseball Treasured Signatures 14 Aaron Judge 2018 National Treasures Baseball Treasured Signatures Platinum 14 Aaron Judge Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Holo Gold 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Platinum 6 Johnny Bench 2013 Elite Extra Edition Baseball -

2009-10 Wright State Basketball Game Notes
2009-10 Wright State Basketball Game Notes Game #11 * Saturday, December 19, 2009 2009-10 Schedule Wright State (6-4) vs Maryland Eastern Shore (3-5) 7:00 pm EST * Ervin J. Nutter Center November Athletes In Action Classic (Seattle, WA) WONE, 980 AM/WIZE, 1340 AM/teamline.cc 13 at #14 Washington L 74-69 14 vs Portland State W 75-70 Video: horizonleaguenetwork.tv 15 vs Belmont W 82-73 Last Time Out: Wright Team Stats Comparison 24 Central Michigan W 69-53 State lost 80-69 at 2009 WSU UMES 28 at Northeastern L 70-67 SEC Champions Missis- Overall Record 6-4 3-5 Conference Record 2-0 1-0 December sippi State Wednesday 3 Cleveland State (ESPNU) W 73-64 night. Four Raiders scored Points Per Game 69.2 60.1 5 Youngstown State W 67-54 Opponent Points Per Game 65.0 71.9 8 at Toledo W 66-56 in double figures, led by Rebounds 28.3 34.0 13 at Miami L 56-55 Troy Tabler’s 22 points-- Opponent Rebounds Per Game 29.7 37.8 16 at Mississippi State (ESPN2) L 80-69 his third straight game of Field Goal % .444 .380 19 Maryland Eastern Shore 7 pm Opponent Field Goal % .464 .474 22 Arkansas-Little Rock 7 pm 20 points or more. Ronnie Three Point % .373 .275 28 Sam Houston State 7 pm Thomas finished with 14 31 at Loyola* 4 pm Opponent Three Point % .392 .344 points while Todd Brown Free Throw % .782 .628 January had 12 and Vaughn Dug- Fouls 194 148 2 at UIC* 4 pm Opponent Fouls 198 155 8 Butler* 7 pm gins ended with 10. -

Box Score Wizards
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Saturday, May 1, 2021 American Airlines Center, Dallas, TX Officials: #24 Kevin Scott, #3 Nick Buchert, #17 Jonathan Sterling Game Duration: 2:14 Attendance: 4351 (Sellout) VISITOR: Washington Wizards (29-35) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 3 Bradley Beal F 36:45 9 20 1 5 10 11 1 3 4 3 4 2 3 0 0 29 8 Rui Hachimura F 28:34 7 11 1 2 3 5 1 1 2 0 3 0 2 0 -3 18 27 Alex Len C 04:47 0 2 0 0 0 0 0 1 1 1 1 0 0 0 -11 0 19 Raul Neto G 29:27 3 5 0 1 2 2 1 8 9 4 3 0 0 0 12 8 4 Russell Westbrook G 40:12 17 30 3 6 5 7 2 8 10 9 4 2 2 0 -3 42 21 Daniel Gafford 25:09 4 5 0 0 1 2 5 2 7 0 2 0 0 2 -7 9 42 Davis Bertans 25:34 1 5 1 5 2 3 0 3 3 0 1 0 0 1 4 5 14 Ish Smith 23:59 3 8 0 0 0 0 1 3 4 2 3 1 2 0 -3 6 1 Chandler Hutchison 07:38 1 2 0 0 0 0 1 1 2 0 1 0 0 0 -11 2 15 Robin Lopez 17:55 2 3 0 0 1 1 2 2 4 0 1 0 1 0 17 5 17 Isaac Bonga DNP - Coach's decision 16 Anthony Gill DNP - Coach's decision 24 Garrison Mathews DNP - Coach's decision 5 Cassius Winston DNP - Coach's decision 240:00 47 91 6 19 24 31 14 32 46 19 23 5 10 3 -1 124 51.6% 31.6% 77.4% TM REB: 6 TOT TO: 11 (12 PTS) HOME: DALLAS MAVERICKS (36-27) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 10 Dorian Finney-Smith F 40:29 8 12 6 9 0 0 1 4 5 2 2 1 3 0 4 22 42 Maxi Kleber F 27:07 5 9 5 9 2 2 0 1 1 1 2 0 1 1 -6 17 7 Dwight Powell C 18:52 3 5 0 0 5 6 1 2 3 0 3 0 0 0 1 11 0 Josh Richardson G 23:18 3 11 1 5 1 1 0 0 0 2 0 2 4 1 -6 8 77 Luka Doncic G 39:13 12 23 1 6 6 11 2 10 12 20 4 0 1 0 6 31 33 Willie Cauley-Stein 26:46 3 5 0 1 0 0 3 9 12 0 4 2 1 2 -3 6 11 Tim Hardaway Jr. -

Nfap Policy Brief » J U N E 2 0 1 4
NATIONALN A T I O N A L FOUNDATION FOR AMERICAN POLICY NFAP POLICY BRIEF » J U N E 2 0 1 4 IMMIGRANT CONTRIBUTIONS IN THE NBA AND MAJOR LEAGUE BASEBALL EXECUTIVE SUMMARY The 2014 NBA champion San Antonio Spurs are an example of how successful American enterprises today combine native-born and foreign-born talent to compete at the highest level. With 7 foreign-born players, the Spurs led the NBA with the most foreign-born players on their roster. Tony Parker (France), Boris Diaw (France) and Manu Ginobili (Argentina) played alongside Tim Duncan (U.S. Virgin Islands) and Kawhi Leonard (U.S.) to bring the team its 5th NBA championship since 1999. The San Antonio Spurs are part of a larger trend of globalization in the NBA. In the 2013-14 season, the National Basketball Association (NBA) set a record with 90 international players, representing 20 percent of the players on the opening-night NBA rosters, compared to 21 international players (and 5 percent of rosters) in 1992. Professional baseball started blending foreign-born players with native-born talent earlier than the NBA. On the 2014 Major League Baseball (MLB) opening-day roster there were 213 foreign-born players, representing 25 percent of the total, an increase of 2 percentage points from an NFAP analysis of MLB rosters performed in 2006. Leading foreign-born baseball players include 2013 American League MVP Miguel Cabrera, 2013 World Series MVP David Ortiz and Texas Rangers pitcher Yu Darvish. San Antonio Spurs Coach Gregg Popovich (l) with Tony Parker (c) and Manu Ginobili (r). -

PDF Numbers and Names
CeLoMiManca Checklist NBA 2018/2019 - Sticker & Card Collection 1 Oct. 28, 2017 - 17 - Jersey Away Jefferson 70 Jeremy Lamb Russell Westbrook 18 - 36 Kyrie Irving 54 Spencer Dinwiddie 71 Frank Kaminsky 2 Dec. 18, 2017 - Kobe 19 - 37 Jaylen Brown 55 Caris LeVert 72 James Borrego (head Bryant 20 - 38 Al Horford 56 Rondae Hollis- coach) 3 Lauri Markkanen Jefferson 21 - 39 Team Logo 73 Nicolas Batum 4 Jan. 30, 2018 - James 57 Shabazz Napier 22 a - Jersey Home / b - 40 Jason Tatum 74 a - Jersey Home / b - Harden Jersey Away 41 Gordon Hayward 58 Allen Crabbe Jersey Away 5 Feb. 15, 2018 - Nikola 23 Kent Bazemore 42 Marcus Morris 59 Kenny Atkinson 75 Robin Lopez Jokic (head coach) 24 Jeremy Lin 43 Jason Tatum 76 Bobby Portis 6 Feb. 28, 2018 - Dirk 60 D'Angelo Russell 77 Justin Holiday Nowitzki 25 Dewayne Dedmon 44 Terry Rozier 61 a - Jersey Home / b - 26 Team Logo 45 Marcus Smart 78 Team Logo 7 - Jersey Away 27 Taurean Prince 46 Brad Stevens (head 79 Lauri Markkanen 8 - 62 Nicolas Batum 28 De Andrè Bembry coach) 80 Kris Dunn 9 - 63 Tony Parker 29 John Collins 47 Kyrie Irving 81 Denzel Valentine 10 - 64 Cody Zeller 30 Kent Bazemore 48 a - Jersey Home / b - 82 Lauri Markkanen 11 - 65 Team Logo Jersey Away 83 Zach LaVine 12 - 31 Miles Plumlee 49 Jarrett Allen 66 Marvin Williams 32 Tyler Dorsey 84 Jabari Parker 13 - 67 Michael Kidd- 50 DeMarre Carroll 85 Fred Hoiberg (head 14 - 33 Lloyd Pierce (head Gilchrist coach) 51 D'Angelo Russell coach) 15 - 68 Kemba Walker 34 John Collins 52 Team Logo 86 Zach LaVine 16 - 69 Kemba Walker 35 a - Jersey Home -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -

National Basketball Association Official
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Tuesday, October 24, 2017 Staples Center, Los Angeles, CA Officials: #33 Sean Corbin, #18 Matt Boland, #64 Justin Van Duyne Game Duration: 2:02 Attendance: 16607 VISITOR: Utah Jazz (2-2) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 2 Joe Ingles F 18:11 1 5 1 5 0 0 0 2 2 1 3 1 4 0 -14 3 15 Derrick Favors F 24:14 3 7 0 0 0 0 0 3 3 2 2 0 1 0 -9 6 27 Rudy Gobert C 31:17 5 5 0 0 2 3 2 5 7 2 1 0 1 3 -26 12 45 Donovan Mitchell G 29:55 7 20 3 9 2 2 1 1 2 1 4 1 4 0 -5 19 3 Ricky Rubio G 31:17 5 10 0 2 0 0 1 4 5 5 1 1 3 0 -26 10 10 Alec Burks 15:20 3 10 1 5 0 0 0 4 4 3 3 0 3 0 -12 7 6 Joe Johnson 22:06 4 6 0 1 2 2 0 2 2 2 2 1 1 0 -7 10 22 Thabo Sefolosha 26:02 4 7 1 3 2 2 2 10 12 1 2 0 1 0 -9 11 25 Raul Neto 16:43 2 5 1 2 0 0 1 0 1 0 1 2 0 0 8 5 33 Ekpe Udoh 16:43 0 2 0 0 1 2 1 1 2 3 3 0 0 4 8 1 23 Royce O'Neale 06:32 0 2 0 1 0 0 0 1 1 0 1 1 0 0 4 0 8 Jonas Jerebko 01:40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -2 0 13 Tony Bradley DNP - Coach's decision 240:00 34 79 7 28 9 11 8 33 41 20 23 7 18 7 -18 84 43% 25% 81.8% TM REB: 6 TOT TO: 18 (26 PTS) HOME: LA CLIPPERS (3-0) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 8 Danilo Gallinari F 38:44 5 11 0 2 4 4 0 6 6 3 1 3 2 0 15 14 32 Blake Griffin F 36:43 8 17 2 7 4 6 1 8 9 6 1 0 2 1 24 22 6 DeAndre Jordan C 36:54 5 9 0 0 1 4 6 12 18 1 3 2 0 0 23 11 25 Austin Rivers G 34:39 7 13 2 6 0 1 0 0 0 2 3 1 1 0 16 16 21 Patrick Beverley G 42:28 7 14 4 7 1 2 2 2 4 5 1 3 7 1 18 19 23 Lou Williams 18:53 3 10 1 4 2 2 1 1 2 4 1 1 -

Men's Basketball All-Americans
HOFSTRA UNIVERSITY 2010-11 men’s basketball media guide men’s basketball UNIVERSITY 2010-11 HOFSTRA Senior Charles Jenkins All-America Candidate 2010 CAA Player of the Year Two-Time Haggerty Award Winner 2010-11 Hofstra University Men 's BaskEe tBall Media Guide Senior Greg Senior Washington Nathaniel Lester Hofstra’s All-Time Leader in Blocked Shots 43 Career Starts 22 Games in Double Figure Scoring Two-Time CAA All-Defensive Team Selection washington lester 2010-11 HOFSTRA UNIVERSITY MEN'S BASKETBALL SCHEDULE NOVEMBER 7 Sun. MOLLOY COLLEGE (Exhibition) 2 p.m. 13 Sat. FARMINGDALE STATE COLLEGE 4 p.m. Puerto Rico Tip-Off (San Juan, PR) 18 Thu. vs. University of North Carolina 5 p.m. 19 Fri. vs. Minnesota/Western Kentucky TBA 21 Sun. vs. Davidson/West Virginia/Nebraska/Vanderbilt TBA 26 Fri. WAGNER COLLEGE 7 p.m. 29 Mon. at Rider University 7 p.m. DECEMBER 4 Sat. TOWSON UNIVERSITY* 7 p.m. 8 Wed. at Binghamton University 7 p.m. 11 Sat. FLORIDA ATLANTIC UNIVERSITY 4 p.m. 18 Sat. at Manhattan College 7 p.m. 22 Wed. COLLEGE OF THE HOLY CROSS 7 p.m. 29 Wed. at Iona College 7:30 p.m. JANUARY 3 Mon. at Drexel University* 7 p.m. 5 Wed. GEORGE MASON UNIVERSITY* 7 p.m. 8 Sat. at Northeastern University* Noon 12 Wed. at Towson University* 7 p.m. 1 15 Sat. OLD DOMINION UNIVERSITY* 4 p.m. 19 Wed. UNC WILMINGTON* 7 p.m. 22 Sat. at College of William & Mary* 2 p.m. 24 Mon. JAMES MADISON UNIVERSITY* 7 p.m. -
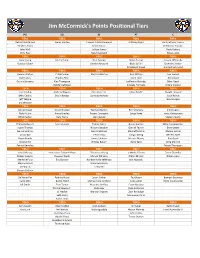
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -
Page 5 Dec. 9
www.theaustinvillager.com THE VILLAGER Page 5 ~December 9, 2011 SPORTS Huston-Tillotson split VILLAGER SPOTLIGHT games with Paul Quinn Thompson looking to make an impact in the NBA By: Terry Davis had a scoring average of 13 The National Basket- points per game. “We’re very ball Association and their excited for Tristan and his player union finally reached family,” Texas coach Rick a handshake agreement in Barnes said. “I’m not sure principal on a new Collective we’ve seen a player improve Bargaining Agreement. As a so quickly once he came to result, some future player’s campus last June. I often tell people jokingly that Tristan By: Terry Davis dreams will be coming true. That is the case the for improved too much, as our former Texas Longhorn staff would have loved the @terryd515 standout Tristan Thompson. opportunity to coach Tristan Thompson was selected with for several more years. The Lady Rams the four overall pick in this exciting thing is Tristan is The Huston-Tillotson year’s NBA Draft by the truly just getting started in his Lady Rams took on the Paul Cleveland Cavaliers. Al- development. Tristan is a Quinn College Tigers of Dal- though only playing one sea- wonderful person and Cleve- las, Texas at their gym this son with Texas, Thompson land is getting a special indi- week. The Lady Tigers only was the third highest Long- vidual who will work hard has five members on their bas- horn ever drafted by the every day, both on the court ketball team, despite this fact NBA. -

Team Training Program
TEAM TRAINING Impact Basketball is very proud of our extensive productive tradition of training teams from around the world as they prepare for upcoming events, seasons, or tournament competition. It is with great honor that we help your team to be at its very best through our comprehensive training and team-building program. The Impact Basketball Team Training Program will give your players a chance to train together in a focused environment with demanding on-court offensive and defensive skill training along with intense off-court strength and conditioning training. The experienced Impact Basketball staff will provide the team with a truly unique bonding experience through training and competition, as well as off-court team building activities. Designated team practice times and live games against high-level American players, including NBA players, provide teams with an opportunity to prepare for their upcoming competition while also developing individually. Each team’s program will be completely customized to fit their schedule, with direct consultation from the team’s coaching staff and management. We will integrate any and all concepts that the coaching staff would like to implement and focus the training on areas that the team’s coaches have deemed deficient. Our incorporation of off-site training and team-building exercises make this a one-of-a-kind opportunity for team and individual development. We have the ability to provide training options for the entire team or for a smaller group of the team’s players. The Impact staff can help set up all the housing, food, and transportation needs for the team.