The Organization of Criminal Identification Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reference Guides for Registering Students with Non English Names
Getting It Right Reference Guides for Registering Students With Non-English Names Jason Greenberg Motamedi, Ph.D. Zafreen Jaffery, Ed.D. Allyson Hagen Education Northwest June 2016 U.S. Department of Education John B. King Jr., Secretary Institute of Education Sciences Ruth Neild, Deputy Director for Policy and Research Delegated Duties of the Director National Center for Education Evaluation and Regional Assistance Joy Lesnick, Acting Commissioner Amy Johnson, Action Editor OK-Choon Park, Project Officer REL 2016-158 The National Center for Education Evaluation and Regional Assistance (NCEE) conducts unbiased large-scale evaluations of education programs and practices supported by federal funds; provides research-based technical assistance to educators and policymakers; and supports the synthesis and the widespread dissemination of the results of research and evaluation throughout the United States. JUNE 2016 This project has been funded at least in part with federal funds from the U.S. Department of Education under contract number ED‐IES‐12‐C‐0003. The content of this publication does not necessarily reflect the views or policies of the U.S. Department of Education nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government. REL Northwest, operated by Education Northwest, partners with practitioners and policymakers to strengthen data and research use. As one of 10 federally funded regional educational laboratories, we conduct research studies, provide training and technical assistance, and disseminate information. Our work focuses on regional challenges such as turning around low-performing schools, improving college and career readiness, and promoting equitable and excellent outcomes for all students. -

Norwegian Surnames in America
Norwegian Surnames in America Surnames During the Immigration Period From 1825, the year of the first organized Norwegian immigration to the USA on the sloop Restauration, until the beginning of the next century, about 900,000 Norwegians immigrated to America. For most of them, the destination was the USA. During the 1800s , most Norwegians did not have a set surname. They had a given name (Anna, Knut), which was their actual name, and a patronymic, which consisted of the father’s name and the suffix son/sen (English son) as in Knut Andersen or dotter/datter (English daughter) as in Anna Larsdatter. This name provided information as to whose daughter or son the person was. If the individual lived on a farm, the name of the farm was added to the two previous names, more like an address than a surname. In an official document the name might look like this: Anna Larsdatter Helland, i.e. Anna is the daughter of Lars and lives on the farm Helland. Among the gentry during the 1800s, it had become customary to have a set surname. Gradually, society was becoming more organized with a growing bureaucracy, which put demands on a more dependable system for identifying its citizens, but it wasn’t until 1923 that the Norwegian Parliament, Stortinget, passed a law requiring all Norwegians to take a set surname or family name. When emigrants were registered on departure from Norway, and on their entry into America, they needed to have a surname. The choice of name could vary a great deal within a family, and it could also be changed during the first decades in the new country. -

Place-Names of Inverness and Surrounding Area Ainmean-Àite Ann an Sgìre Prìomh Bhaile Na Gàidhealtachd
Place-Names of Inverness and Surrounding Area Ainmean-àite ann an sgìre prìomh bhaile na Gàidhealtachd Roddy Maclean Place-Names of Inverness and Surrounding Area Ainmean-àite ann an sgìre prìomh bhaile na Gàidhealtachd Roddy Maclean Author: Roddy Maclean Photography: all images ©Roddy Maclean except cover photo ©Lorne Gill/NatureScot; p3 & p4 ©Somhairle MacDonald; p21 ©Calum Maclean. Maps: all maps reproduced with the permission of the National Library of Scotland https://maps.nls.uk/ except back cover and inside back cover © Ashworth Maps and Interpretation Ltd 2021. Contains Ordnance Survey data © Crown copyright and database right 2021. Design and Layout: Big Apple Graphics Ltd. Print: J Thomson Colour Printers Ltd. © Roddy Maclean 2021. All rights reserved Gu Aonghas Seumas Moireasdan, le gràdh is gean The place-names highlighted in this book can be viewed on an interactive online map - https://tinyurl.com/ybp6fjco Many thanks to Audrey and Tom Daines for creating it. This book is free but we encourage you to give a donation to the conservation charity Trees for Life towards the development of Gaelic interpretation at their new Dundreggan Rewilding Centre. Please visit the JustGiving page: www.justgiving.com/trees-for-life ISBN 978-1-78391-957-4 Published by NatureScot www.nature.scot Tel: 01738 444177 Cover photograph: The mouth of the River Ness – which [email protected] gives the city its name – as seen from the air. Beyond are www.nature.scot Muirtown Basin, Craig Phadrig and the lands of the Aird. Central Inverness from the air, looking towards the Beauly Firth. Above the Ness Islands, looking south down the Great Glen. -
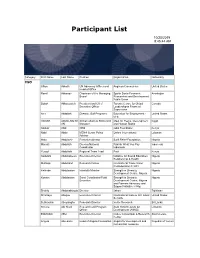
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

Mcpherson County Marriages 1870-1915 Sorted by Bride's
McPherson County Marriages 1870-1915 Sorted by Bride's Surname Groom Last Groom First Bride Last Bride First Date Year Location Baldwin Edgar Haberlein Emma 4-Jul 1911 McPherson Champlin Robert Haberlein Louise 6-Nov 1912 McPherson Gilchrist Neal Haberlein Mollie 16-Jan 1902 Inman Beutler Christian Hackenburg Maggie 5-Oct 1913 Moundridge Burks John Hafesty Mary 9-Oct 1873 Sharps Creek Satterlee John A. Hagar Nancy J. 27-Dec 1881 McPherson Nelson Ben Hagberg Christine 29-May 1892 McPherson Co. Cedarholm John O. Hagberg Emma 12-Dec 1889 Smoky Hill Alstatt Andrew J. Hageberg Ida A. 10-Dec 1881 McPherson Harstick Adison M. Hagelstine Emma 18-Nov 1886 McPherson Millner George Hager Lucia 4-May 1898 Canton Hall W.A. Hagstrom Emily 27-Nov 1906 McPherson Belden S.I. Hahn Carrie 15-Feb 1884 McPherson Bonney F.E. Haight Fannie 14-Feb 1899 McPherson Norris Raymond Haight Ina 3-Apr 1907 McPherson Nixon Albert Hailing Mary 29-Sep 1895 Marquette Hannlton Jesse Hailings Jennie 13-Feb 1915 Marquette Roberts S.H. Halbrook Mollie A. 23-Apr 1873 Residence of Mr. & Mrs. Halbrook Yowell Charles Halferty Iowa 11-Apr 1876 Jackson Naymire Wm. H. Haling Mary E. 7-Jul 1883 McPherson Hawthorne E.W. Hall Bertha 16-Mar 1890 Inman Richcreek George Hall Effie 16-Mar 1888 McPherson Banks Benson Hall Elizabeth 28-Sep 1875 Gypsum Creek Carlander Gust Hall Ella 28-Dec 1884 McPherson Lancaster James Hall Frances 31-Oct 1914 McPherson Aurell John Hall Hannah 4-May 1904 Lindsborg Lawson James Hall Helen 26-Nov 1905 McPherson Gregory William Hall Jennie 2-Aug 1898 McPherson Potter F.H. -

Immigration, Identity, and Genealogy: a Case Study
genealogy Article Immigration, Identity, and Genealogy: A Case Study Thomas Daniel Knight Department of History, The University of Texas—Rio Grande Valley, Edinburg, TX 78539-2999, USA; [email protected] Received: 31 August 2018; Accepted: 18 December 2018; Published: 2 January 2019 Abstract: This paper examines the life and experiences of a 19th-century immigrant from the British Isles to the United States and his family. It examines his reasons for immigrating, as well as his experiences after arrival. In this case, the immigrant chose to create a new identity for himself after immigration. Doing so both severed his ties with his birth family and left his American progeny without a clear sense of identity and heritage. The essay uses a variety of sources, including oral history and folklore, to investigate the immigrant’s origins and examine how this uncertainty shaped the family’s history in the 19th and 20th centuries. New methodologies centering on DNA analysis have recently offered insights into the family’s past. The essay ends by positing a birth identity for the family’s immigrant ancestor. Importantly, the family’s post-immigration experiences reveal that the immigrant and his descendants made a deliberate effort to retain aspects of their pre-immigration past across both time and distance. These actions underscore a growing body of literature on the limits of post-immigration assimilation by immigrants and their families, and indicate the value of genealogical study for analyzing the immigrant experience. Keywords: immigration; identity; genealogy; name-change 1. Introduction This paper examines the life and experiences of a 19th-century immigrant from the British Isles to the United States. -
SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Jacaway
SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Jacaway Augusta Ellen 1956 Jacaway Louis A 1976 Jack Davidson 1917 Jack Jeane 1933 Jack Rosanna 1924 Jacklett Claude Leo 1949 Jacklin Velma 1938 Jackson Greta 1901 Jackson S B 1902 Jackson Thomas 1903 Jackson Alfred W 1961 Jackson Ann F 1978 Jackson Belle Charlotte 1945 Jackson Bert Stanley 1953 Jackson Bertha 1963 Jackson Bertha Grace 1960 Jackson Billy 1952 Jackson Breard 1965 Jackson Charles Henry 1934 Jackson Charles Willis 1953 Jackson Daisy Belle 1982 Jackson David W 1956 Jackson Earl 1955 Jackson Ellsworth 1928 Jackson Eula M 1975 Jackson Frank Stanton 1954 Jackson Fred Henry 1965 Jackson George 1949 Jackson George Columbus 1968 Jackson George Radbourn 1963 Jackson Gerald 1968 Jackson Gladys 1942 Jackson Hannah 1961 Jackson Harold Douglas 1972 Jackson Harold Joseph 1980 Jackson Harry Melville 1949 Jackson Hattie E 1938 Jackson Herbert LeRoy 1977 Jackson Irene A 1972 Jackson Leslie W 1964 Jackson Lisa Renee 1967 Jackson Mary 1960 Jackson Mary Gray 1913 Jackson Mats Sanford 1940 Jackson Maxey 1935 Jackson Ora Vernard 1963 Jackson Phillip 1940 Jackson Robert Gardner 1961 Jackson Robert L 1966 Jackson Robert M 1967 Jackson Robert W 1930 Jackson Samuel H 1933 SURNAME GIVEN NAME MIDDLE NAME DEATH YEAR Jackson Shawn Gary 1970 Jackson Theresa 1953 Jackson Thomas 1909 Jackson Thomas Roy 1981 Jackson Timothy 1978 Jackson Vernard 1970 Jackson Willard Joshua 1939 Jackson William Henry 1973 Jacob Andrew Christopher 1951 Jacob William 1932 Jacobs Bessie L 1902 Jacobs Bessie L 1902 Jacobs Clarence LeRoy -

Hamilton County (Ohio) Will Index - Surnames J
Hamilton County (Ohio) Will Index - Surnames J Surname Given Name Residence Date Filed Box Case No Executor Beneficiaries Julia Jackson, Francis Jackson, Julia Ann Jackson David Jr. Cincinnati, OH 01/18/1841 4 Julia Jackson, Henry Cutter Jackson, Mary Jackson, et al Jackson Edmund Storres Township 03/30/1878 37 21632 No Information Rosana Jackson Jackson Ethan Harrison, OH 06/08/1892 90 38361 Margaret Jackson Margaret Jackson Peter J. Sullivan, John H. Peter J. Sullivan, John H. Ewing, Various Jackson Fanny B.C. Cincinnati, OH 02/08/1854 9 1454 Ewing Friends A. L. Voorhes, Hezekiah Jackson George Cincinnati, OH 11/06/1838 4 Kiesste Samuel White, Mary A. Jackson, et al Thomas M. Jackson, Sidney L. Jackson, Thomas M. Jackson, Sidney John R. Jackson, William Andrews, Jackson Isaac H. Green Township 10/29/1849 4 L. Jackson, John R. Jackson Daughter, Deborah Jackson John Jackson, Patrick Jackson, Michael Jackson John Madisonville, OH 07/11/1894 101 41262 No Information Jackson, Thomas Jackson, Maria Jackson Jackson John Cincinnati, OH 11/07/1884 54 29091 Lydia A. Jackson Lydia A. Jackson Ann Jane Jackson, Elizabeth Jackson McSniggis, James Jackson, Hugh Jackson, George Jackson, Thomas Jackson, William Jackson, John R. Thomas Jackson, Ann Jane Jackson, Mary Mullen, Elizabeth Jackson John Cincinnati, OH 08/08/1890 80 35811 Jackson Jackson, Bridget Jackson, et al Florence Jackson, John Jackson, Sarah A. Jackson, Navine C. Jackson, Morris Jackson John A. Cincinnati, OH 11/29/1881 46 25828 John W. Herron Jackson Jackson John W. Cincinnati, OH 10/19/1878 38 22517 Eveline Jackson Eveline Jackson, Unnamed Children Florence Jackson, Elmore W. -

Naming in Arabic Samir A
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1977 Naming in Arabic Samir A. Hawana Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the English Language and Literature Commons, and the Near Eastern Languages and Societies Commons Recommended Citation Hawana, Samir A., "Naming in Arabic" (1977). Retrospective Theses and Dissertations. 82. https://lib.dr.iastate.edu/rtd/82 This Thesis is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Naming in Arabic by Samir A. Hawana A Thesis Submitted to the Graduate Faculty in Partial Fulfillment of The Requirements for the Degree of MASTER OF ARTS Major: English Iowa State University Ames, Iowa 1977 ii TABLE OF CONTENTS Page CHAPTER I. INTRODUCTION 1 CHAPTER II. WHAT'S IN A NAME? 6 CHAPTER III. RELIGIOUS NAMES 11 CHAPTER IV. NAMING IN ARABIC 15 FOOTNOTES 27 BIBLIOGRAPHY 30 ACKNOWLEDGMENTS 32 APPENDIX 33 1 CHAPTER I. INTRODUCTION When Benjamin L. Whorf said that speech is the best show 1 man ever puts on, he could have modified his statement by adding that personal names are the cleverest manifestations of that show. Many of us tend to accept our names as bestowed by our parents and exert little effort, if any, to understand their significance or even their literal meaning. -

Surname Database.Xlsx
Surname First Name File Description Jaber Amir Ja General Newspaper Clipping Jacklin Donna Marie Ja General Obituary Jacklin Floyd Ross Ja General Obituary Jacklin Walter Ja General Obituary Jackson Don Jackson Surname Obituary Jackson Frank and Mary Percy Jackson Surname Photograph Jackson Frank Daniel Jackson Surname Memorial Card Jackson Frank Daniel Jackson Surname Obituary Jackson Geraldine Jackson Surname Newspaper Clipping Jackson Geraldine Jackson Surname Obituary Jackson James "Jim" Almer Jackson Surname Obituary Jackson Mary Percy Dr. Jackson Surname Obituary Jackson Mary Percy Dr. Jackson Surname Magazine Article Jackson Mary Percy Dr. Jackson Surname Correspondence Jackson Mary Percy Dr. Jackson Surname Photograph Jackson Mary Percy Dr. Jackson Surname Newspaper Clippings Jackson Wendy Patricia (Armitage) Jackson Surname Obituary Jacob George Jacob(s) Surname Newspaper Clipping Jacobs Anne Elizabeth (Kinderwater) Jacob(s) Surname Obituary Jacobs Joannie (Dr.) Jacob(s) Surname Newspaper Clipping Jacobs Pat Jacob(s) Surname Newspaper Clipping Jacobs Patricia "Pat" Jacob(s) Surname Newspaper Clipping Jacobs Patricia Irene Jacob(s) Surname Obituary Jacobsen Christine G Ja General Funeral Card, Obituary Jacobson Morris and Kathleen Ja General Newspaper Clipping Jacques Wayne Ja General Newspaper Clipping Jaeger Clem Ja General Obituary Jaeger Michael James Ja General Obituary Jaffray Christian "Howie" Jaffray Surname Correspondence Jama Arte Abdille Ja General Newspaper Clipping James Arthur James and Margaret James Surname Biographical