Unit 15 Search Engines and Their Abuse
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Adsense-Blackhat-Edition.Pdf
AdSense.BlackHatEditionV.coinmc e Tan Vince Tan AdSense.BlackHatEdition.com i Copyright Notice All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical. Any unauthorized duplication, reproduction, or distribution is strictly prohibited and prosecutable by the full-extent of the law. Legal Notice While attempts have been made to verify the information contained within this publication, the author, publisher, and anyone associated with its creation, hereby assume absolutely no responsibility as it pertains to its contents and subject matter; nor with regards to it’s usage by the public or in any matters concerning potentially erroneous and/or contradictory information put forth by it. Furthermore, the reader agrees to assume all accountability for the usage of any information obtained from it; and heretofore, completely absolves Vince Tan, the publishers and any associates involved, of any liability for it whatsoever. Additional Notice: This book was obtained at http://AdSense.BlackHatEdition.com . For a limited time, when you register for free, you will be able to earn your way to get the latest updates of this ebook, placement on an invitation-only list to participate in exclusive pre-sales, web seminars, bonuses & giveaways, and be awarded a “special backdoor discount” that you will never find anywhere else! So if you haven’t yet, make sure to visit http://AdSense.BlackHatEdition.com and register now, before it’s too late! i Table of Contents Introduction -

Clique-Attacks Detection in Web Search Engine for Spamdexing Using K-Clique Percolation Technique
International Journal of Machine Learning and Computing, Vol. 2, No. 5, October 2012 Clique-Attacks Detection in Web Search Engine for Spamdexing using K-Clique Percolation Technique S. K. Jayanthi and S. Sasikala, Member, IACSIT Clique cluster groups the set of nodes that are completely Abstract—Search engines make the information retrieval connected to each other. Specifically if connections are added task easier for the users. Highly ranking position in the search between objects in the order of their distance from one engine query results brings great benefits for websites. Some another a cluster if formed when the objects forms a clique. If website owners interpret the link architecture to improve ranks. a web site is considered as a clique, then incoming and To handle the search engine spam problems, especially link farm spam, clique identification in the network structure would outgoing links analysis reveals the cliques existence in web. help a lot. This paper proposes a novel strategy to detect the It means strong interconnection between few websites with spam based on K-Clique Percolation method. Data collected mutual link interchange. It improves all websites rank, which from website and classified with NaiveBayes Classification participates in the clique cluster. In Fig. 2 one particular case algorithm. The suspicious spam sites are analyzed for of link spam, link farm spam is portrayed. That figure points clique-attacks. Observations and findings were given regarding one particular node (website) is pointed by so many nodes the spam. Performance of the system seems to be good in terms of accuracy. (websites), this structure gives higher rank for that website as per the PageRank algorithm. -

Copyrighted Material
00929ftoc.qxd:00929ftoc 3/13/07 2:02 PM Page ix Contents Acknowledgments vii Introduction xvii Chapter 1: You: Programmer and Search Engine Marketer 1 Who Are You? 2 What Do You Need to Learn? 3 SEO and the Site Architecture 4 SEO Cannot Be an Afterthought 5 Communicating Architectural Decisions 5 Architectural Minutiae Can Make or Break You 5 Preparing Your Playground 6 Installing XAMPP 7 Preparing the Working Folder 8 Preparing the Database 11 Summary 12 Chapter 2: A Primer in Basic SEO 13 Introduction to SEO 13 Link Equity 14 Google PageRank 15 A Word on Usability and Accessibility 16 Search Engine Ranking Factors 17 On-Page Factors 17 Visible On-Page Factors 18 Invisible On-Page Factors 20 Time-Based Factors 21 External FactorsCOPYRIGHTED MATERIAL 22 Potential Search Engine Penalties 26 The Google “Sandbox Effect” 26 The Expired Domain Penalty 26 Duplicate Content Penalty 27 The Google Supplemental Index 27 Resources and Tools 28 Web Analytics 28 00929ftoc.qxd:00929ftoc 3/13/07 2:02 PM Page x Contents Market Research 29 Researching Keywords 32 Browser Plugins 33 Community Forums 33 Search Engine Blogs and Resources 34 Summary 35 Chapter 3: Provocative SE-Friendly URLs 37 Why Do URLs Matter? 38 Static URLs and Dynamic URLs 38 Static URLs 39 Dynamic URLs 39 URLs and CTR 40 URLs and Duplicate Content 41 URLs of the Real World 42 Example #1: Dynamic URLs 42 Example #2: Numeric Rewritten URLs 43 Example #3: Keyword-Rich Rewritten URLs 44 Maintaining URL Consistency 44 URL Rewriting 46 Installing mod_rewrite 48 Testing mod_rewrite 49 Introducing -

Information Retrieval and Web Search Engines
Information Retrieval and Web Search Engines Lecture 13: Miscellaneous July 23th, 2020 Wolf-Tilo Balke and Janus Wawrzinek Institut für Informationssysteme Technische Universität Braunschweig Lecture 13: Miscellaneous 1. Spamdexing 2. Hardware for Large Scale Web Search 3. Metasearch 4. Privacy Issues Information Retrieval and Web Search Engines — Wolf-Tilo Balke and José Pinto — Technische Universität Braunschweig 2 Spamdexing • Spamdexing = The practice of modifying the Web to get certain Web resources unjustifiably ranked high on search engine result lists • Often a synonym of SEO (“search engine optimization”) Information Retrieval and Web Search Engines — Wolf-Tilo Balke and José Pinto — Technische Universität Braunschweig 3 Spamdexing (2) • Spamdexing usually means finding weaknesses in ranking algorithms and exploiting them • Usually, it looks like this: Finds a new loophole Spammer Search Engine Fills the loophole • There are two classes of spamdexing techniques: – Content spam: Alter a page’s contents – Link spam: Alter the link structure between pages Information Retrieval and Web Search Engines — Wolf-Tilo Balke and José Pinto — Technische Universität Braunschweig 4 Content Spam Idea: – Exploit TF–IDF Method: – Repeatedly place the keywords to be found in the text, title, or URI of your page – Place the keywords in anchor texts of pages linking to your page – Weave your content into high-quality content taken from (possibly a lot of) other pages Countermeasures: – Train classification algorithms to detect patterns that are “typical” -

Cloak and Dagger: Dynamics of Web Search Cloaking
Cloak and Dagger: Dynamics of Web Search Cloaking David Y. Wang, Stefan Savage, and Geoffrey M. Voelker Deptartment of Computer Science and Engineering University of California, San Diego ABSTRACT of markets, either via “organic” search results or sponsored search Cloaking is a common “bait-and-switch” technique used to hide the placements—together comprising a $14B marketing sector [16]. true nature of a Web site by delivering blatantly different semantic Not surprisingly, the underlying value opportunities have created content to different user segments. It is often used in search engine strong incentives to influence search results—a field called “search optimization (SEO) to obtain user traffic illegitimately for scams. engine optimization” or SEO. Some of these techniques are be- In this paper, we measure and characterize the prevalence of cloak- nign and even encouraged by search engine operators (e.g., simpli- ing on different search engines, how this behavior changes for tar- fying page content, optimizing load times, etc.) while others are geted versus untargeted advertising and ultimately the response to designed specifically to manipulate page ranking algorithms with- site cloaking by search engine providers. Using a custom crawler, out regard to customer interests (e.g., link farms, keyword stuffing, called Dagger, we track both popular search terms (e.g., as identi- blog spamming, etc.) Thus, a cat and mouse game has emerged fied by Google, Alexa and Twitter) and targeted keywords (focused between search engine operators and scammers where search oper- on pharmaceutical products) for over five months, identifying when ators try to identify and root out pages deemed to use “black hat” distinct results were provided to crawlers and browsers. -

Identifying Javascript Skimmers on High-Value Websites
Imperial College of Science, Technology and Medicine Department of Computing CO401 - Individual Project MEng Identifying JavaScript Skimmers on High-Value Websites Author: Supervisor: Thomas Bower Dr. Sergio Maffeis Second marker: Dr. Soteris Demetriou June 17, 2019 Identifying JavaScript Skimmers on High-Value Websites Thomas Bower Abstract JavaScript Skimmers are a new type of malware which operate by adding a small piece of code onto a legitimate website in order to exfiltrate private information such as credit card numbers to an attackers server, while also submitting the details to the legitimate site. They are impossible to detect just by looking at the web page since they operate entirely in the background of the normal page operation and display no obvious indicators to their presence. Skimmers entered the public eye in 2018 after a series of high-profile attacks on major retailers including British Airways, Newegg, and Ticketmaster, claiming the credit card details of hundreds of thousands of victims between them. To date, there has been little-to-no work towards preventing websites becoming infected with skimmers, and even less so for protecting consumers. In this document, we propose a novel and effective solution for protecting users from skimming attacks by blocking attempts to contact an attackers server with sensitive information, in the form of a Google Chrome web extension. Our extension takes a two-pronged approach, analysing both the dynamic behaviour of the script such as outgoing requests, as well as static analysis by way of a number of heuristic techniques on scripts loaded onto the page which may be indicative of a skimmer. -

Intermediation in Open Display Advertising
Appendix M: intermediation in open display advertising Introduction 1. This appendix discusses intermediation in open display advertising. It provides background information to the analysis of the open display market developed in Chapter 5, presents the evidence supporting the claims we make in the chapter, and develops the analysis of some issues that, although useful for a full understanding of open display intermediation, have not been included in the main report. This is an updated version of Appendix H to our interim report. Compared to the interim report, the scope of the appendix has been expanded: • We include an analysis of advertiser ad servers. • We do not just describe how the intermediation industry works, but also develop a detailed analysis of the issues affecting competition between intermediaries, looking at lack of transparency, conflicts of interests and leveraging practices. • We discuss how competitive dynamics can be affected by the future evolution of the industry. 2. The appendix is divided into eight sections. In the first section, we describe how advertising intermediation works. We outline the overall structure of the industry, analyse its evolution in the course of the last ten years, present the different types of transactions that publishers use to sell their advertising inventory, describe the activities performed by the different types of intermediaries and discuss the technical advantages of vertical integration across the intermediation chain. 3. The second section deals with competition among providers at each stage of the intermediation chain. For each type of intermediary, we discuss the main dimensions of competition and the main factors affecting the strength of competition, such as customers’ homing behaviour, economies of scale and scope, and switching costs. -
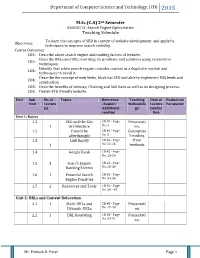
Department of Computer Science and Technology, UTU 2015
Department of Computer Science and Technology, UTU 2015 M.Sc.(C.A) 2nd Semester 040020213 : Search Engine Optimization Teaching Schedule To learn the concepts of SEO in context of website development, and apply its Objectives: techniques to improve search visibility. Course Outcomes: CO1: Describe about search engine and ranking factors of website. Describe URLs and URL rewriting, its problems and solutions using redirection CO2: techniques. Identify that when search engine consider content as a duplicate content and CO3: techniques to avoid it. Describe the concept of web feeds, black hat SEO and able to implement RSS feeds and CO4: syndication. CO5: Describe benefits of sitemap, Cloaking and link baits as well as its designing process. CO6: Design SEO friendly website. Unit Sub No. of Topics Reference Teaching Date of Evaluation Unit Lecture chapter/ Methodolo Lecture Parameter (s) Additional gy Conduc reading tion Unit 1: Basics 1.1 SEO and the Site CD #1 - Page Presentati 1 Architecture No. 4 on, 1.2 Cannot be CD #1 - Page Conceptua afterthought No. 5 l reading 1.3 Link Equity CD #2 - Page from 1 No. 22-23 textbook 1.4 Google Rank CD #2 - Page No. 23-24 1.5 3 Search Engine CD #2 - Page Ranking Factors No. 25-34 1.6 1 Potential Search CD #2 - Page Engine Penalties No. 34-36 1.7 2 Resources and Tools CD #2 - Page No. 28 - 43 Unit 2: URLs and Content Relocation 2.1 1 Static URLs and CD #3 - Page Presentati Dynamic URLs No. 47-49 on 2.2 1 URL Rewriting CD #3 - Page Presentati No. -

Phishprint: Evading Phishing Detection Crawlers by Prior Profiling
PhishPrint: Evading Phishing Detection Crawlers by Prior Profiling Bhupendra Acharya and Phani Vadrevu, UNO Cyber Center, University of New Orleans https://www.usenix.org/conference/usenixsecurity21/presentation/acharya This paper is included in the Proceedings of the 30th USENIX Security Symposium. August 11–13, 2021 978-1-939133-24-3 Open access to the Proceedings of the 30th USENIX Security Symposium is sponsored by USENIX. PhishPrint: Evading Phishing Detection Crawlers by Prior Profiling Bhupendra Acharya Phani Vadrevu UNO Cyber Center UNO Cyber Center University of New Orleans University of New Orleans [email protected] [email protected] Abstract Firefox, Safari, and Samsung Internet web browsers which Security companies often use web crawlers to detect together account for about 90% of the market share use the phishing and other social engineering attack websites. We GSB blocklist [3]. GSB is deployed in about four billion built a novel, scalable, low-cost framework named PhishPrint devices worldwide and shows millions of browser warnings to enable the evaluation of such web security crawlers against every day protecting users from web attacks. Such blocklists multiple cloaking attacks. PhishPrint is unique in that it are populated with the help of web security crawlers that completely avoids the use of any simulated phishing sites and regularly scout web-pages to evaluate them. However, in blocklisting measurements. Instead, it uses web pages with order to evade these crawlers, miscreants employ many benign content to profile security crawlers. cloaking techniques [23, 38, 39, 49, 52]. We used PhishPrint to evaluate 23 security crawlers Despite such great importance, security crawlers have including highly ubiquitous services such as Google Safe been left understudied for a long time. -

Google Adsense Secrets 5.0.Pdf
What Google Never Told You About Making Money with AdSense: 5th Edition Joel Comm www.AdSense-Secrets.com www.JoelComm.com Copyright © 2011 Joel Comm and Flying Monkey Media, Inc. – All Rights Reserved 1 INDEX LEGALESE .......................................................................................... 8 INTRODUCTION ................................................................................. 9 MY EXPERIMENTS WITH ADSENSE .................................................................10 WHAT IS ADSENSE? ................................................................................12 WHAT ADSENSE IS NOT ............................................................................15 HOW TO USE THIS BOOK ..........................................................................16 1. THE BASICS: BUILDING AN ADSENSE-READY WEBSITE ............... 19 1.1 UP AND ROLLING WITH TRAINING WHEELS ...............................................20 1.2 OFF WITH THE TRAINING WHEELS! ........................................................27 1.3 DESIGNING A SITE FROM SCRATCH ..........................................................32 1.4 THE BASICS OF SEARCH ENGINE OPTIMIZATION ...........................................33 1.5 FROM BLOGGER TO PUBLISHER ...............................................................34 2. ADSENSE — MAKING THE MONEY! .............................................. 35 2.1 SIGNING UP MADE EASY ......................................................................35 2.2 GOOGLE’S POLICIES — THEY’RE IMPORTANT! .............................................37 -

Sunrise to Sunset: Analyzing the End-To-End Life Cycle and E Ectiveness of Phishing Attacks at Scale
Sunrise to Sunset: Analyzing the End-to-end Life Cycle and Eectiveness of Phishing Attacks at Scale Adam Oest*, Penghui Zhang*, Brad Wardman†, Eric Nunes†, Jakub Burgis†, Ali Zand‡, Kurt Thomas‡, Adam Doupé*, and Gail-Joon Ahn*,§ *Arizona State University, †PayPal, Inc., ‡Google, Inc., §Samsung Research *{aoest, pzhang57, doupe, gahn}@asu.edu, †{bwardman, enunes, jburgis}@paypal.com, ‡{zand, kurtthomas}@google.com Abstract primary stepping stones to even more harmful scams [21]. Despite an extensive anti-phishing ecosystem, phishing In an adversarial race—fueled in part by the underground attacks continue to capitalize on gaps in detection to reach economy [59]—phishers collectively seek to stay one step a signicant volume of daily victims. In this paper, we isolate ahead of the security community through a myriad of evasion and identify these detection gaps by measuring the end-to- techniques [52]. Recent work has shown how cloaking and end life cycle of large-scale phishing attacks. We develop a related strategies signicantly delay browser-based phishing unique framework—Golden Hour—that allows us to passively detection and warnings—a defense layer adopted by every measure victim trac to phishing pages while proactively major browser [51]. However, the implications of such delays protecting tens of thousands of accounts in the process. Overa on the success of each attack are not yet well-understood, nor one year period, our network monitor recorded 4.8 million vic- is the precise window of opportunity available to attackers tims who visited phishing pages, excluding crawler trac. We between the launch and detection of their phishing websites. -

Phishfarm: a Scalable Framework for Measuring the Effectiveness of Evasion Techniques Against Browser Phishing Blacklists
PhishFarm: A Scalable Framework for Measuring the Effectiveness of Evasion Techniques Against Browser Phishing Blacklists Adam Oest˚, Yeganeh Safaei˚, Adam Doupe´˚, Gail-Joon Ahn˚x, Brad Wardman:, Kevin Tyers: ˚Arizona State University, x Samsung Research, :PayPal, Inc. faoest, ysafaeis, doupe, [email protected], fbwardman, [email protected] Abstract—Phishing attacks have reached record volumes in lucrative data, phishers are engaged in a tireless cat-and- recent years. Simultaneously, modern phishing websites are grow- mouse game with the ecosystem and seek to stay a step ahead ing in sophistication by employing diverse cloaking techniques of mitigation efforts to maximize the effectiveness of their to avoid detection by security infrastructure. In this paper, we present PhishFarm: a scalable framework for methodically testing attacks. Although new phishing attack vectors are emerging the resilience of anti-phishing entities and browser blacklists to (e.g. via social media as a distribution channel [5]), malicious attackers’ evasion efforts. We use PhishFarm to deploy 2,380 actors still primarily deploy “classic” phishing websites [2]. live phishing sites (on new, unique, and previously-unseen .com These malicious sites are ultimately accessed by victim users domains) each using one of six different HTTP request filters who are tricked into revealing sensitive information. based on real phishing kits. We reported subsets of these sites to 10 distinct anti-phishing entities and measured both the Today’s major web browsers, both on desktop and mobile occurrence and timeliness of native blacklisting in major web platforms, natively incorporate anti-phishing blacklists and browsers to gauge the effectiveness of protection ultimately display prominent warnings when a user attempts to visit a extended to victim users and organizations.