High-Speed Autonomous Drifting with Deep Reinforcement Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Six Adventure Road Trips
Easy Drives, Big Fun, and Planning Tips Six Adventure Road Trips DAY HIKES, FLY-FISHING, SKIING, HISTORIC SITES, AND MUCH MORE A custom guidebook in partnership with Montana Offi ce of Tourism and Business Development and Outside Magazine Montana Contents is the perfect place for road tripping. There are 3 Glacier Country miles and miles of open roads. The landscape is stunning and varied. And its towns are welcoming 6 Roaming the National Forests and alluring, with imaginative hotels, restaurants, and breweries operated by friendly locals. 8 Montana’s Mountain Yellowstone and Glacier National Parks are Biking Paradise the crown jewels, but the Big Sky state is filled with hundreds of equally awesome playgrounds 10 in which to mountain bike, trail run, hike, raft, Gateways to Yellowstone fish, horseback ride, and learn about the region’s rich history, dating back to the days of the 14 The Beauty of Little dinosaurs. And that’s just in summer. Come Bighorn Country winter, the state turns into a wonderland. The skiing and snowboarding are world-class, and the 16 Exploring Missouri state offers up everything from snowshoeing River Country and cross-country skiing to snowmobiling and hot springs. Among Montana’s star attractions 18 Montana on Tap are ten national forests, hundreds of streams, tons of state parks, and historic monuments like 20 Adventure Base Camps Little Bighorn Battlefield and the Lewis and Clark National Historic Trail. Whether it’s a family- 22 friendly hike or a peaceful river trip, there’s an Montana in Winter experience that will recharge your spirit around every corner in Montana. -

Mountain Bike Trail Development Concept Plan
Mountain Bike Trail Development Concept Plan Prepared by Rocky Trail Destination A division of Rocky Trail Entertainment Pty Ltd. ABN: 50 129 217 670 Address: 20 Kensington Place Mardi NSW 2259 Contact: [email protected] Ph 0403 090 952 In consultation with For: Lithgow City Council 2 Page Table of Contents 1 Project Brief ............................................................................................................................................. 6 1.1 Project Management ....................................................................................................................... 7 About Rocky Trail Destination .......................................................................................................... 7 Who we are ......................................................................................................................................... 7 What we do .......................................................................................................................................... 7 Key personnel and assets ................................................................................................................. 8 1.2 Project consultant .......................................................................................................................... 11 Project milestones 2020 .................................................................................................................. 11 2 Lithgow as a Mountain Bike Destination ........................................................................................... -

2021 FIA Motorsport Games: Drifting Cup – Sporting Regulations
2021 FIA MSG: Drifting Cup Sporting Regulations – Approved by WMSC 05.03.2021 _________________________________________________________________________________________ 2021 FIA Motorsport Games: Drifting Cup – Sporting Regulations INTRODUCTION 3 GENERAL INFORMATION 3 COMPETITION DIVISIONS 1. COMPETITION PARTICIPANTS 3 2. COMPETITION CATEGORY 3 3. ENTRY PROCEDURE 4 3.1 COMPETITOR APPLICATIONS 4 3.2 COMPETITOR NATIONALITY 4 3.3 COMPETITOR ELIGIBILITY 4 4. FIA MOTORSPORT GAMES: DRIFTING CUP TITLE 4 5. FIA MOTORSPORT GAMES 5 COMPETITION OFFICIALS 6. COMPETITION OFFICIALS 5 6.1 STEWARDS 5 6.2 CLERK OF THE COURSE AND/OR RACE DIRECTOR 6 6.3 EVENT SECRETARY 6 6.4 TECHNICAL DELEGATE AND/OR CHIEF SCRUTINEER 6 6.5 JUDGES 6 PENALTIES 7. PENALTIES 7 GENERAL PROVISIONS 8. GENERAL PROVISIONS 8 9. COMPETITION NUMBERS AND ADVERTISING ON CARS 8 9.1 COMPETITION NUMBERS 8 9.2 COMPETITION BRANDING 8 9.3 ADVERTISING ON CARS 8 10. SAFETY 8 10.1 GENERAL SAFETY 8 10.2 TRACK CONTROL 9 11. INSURANCE 9 11.1 EVENT INSURANCE 9 11.2 PERSONAL INSURANCE 10 12. SIGNALIZATION 10 13. ADMINISTRATIVE CHECK 10 14. SCRUTINEERING 10 14.1 GENERAL SCRUNTINEERING PRACTICES AND REQUIREMENTS 10 14.2. NOISE RESTRICTIONS 11 COMPETITION 15. BRIEFING 11 16. PRACTICE 11 17. COMPETITION 12 __________________________________________________________________________________________________ Updated on: 12/02/2021 1/34 2021 FIA MSG: Drifting Cup Sporting Regulations – Approved by WMSC 05.03.2021 _________________________________________________________________________________________ 18. START LINE PROCEDURE 12 19. QUALIFICATION 13 19.1 QUALIFYING FORMAT 13 19.2 INITIATION DURING QUALIFYING 13 19.3 QUALIFYING SCORING 13 19.4 QUALIFYING JUDGING CRITERIA 14 19.5 FORCE MAJEURE 17 20. TANDEM BATTLES 17 20.1 ELIMINATION FORMAT 17 20.2 TANDEM JUDGING CRITERIA 17 20.3 INCOMPLETE TANDEM RUNS 18 20.4 PASSING 19 20.5 TANDEM INITIATION PROCEDURE 19 20.6 TANDEM COLLISIONS AND CONTACT 20 20.7 CAR SERVICE DURING TANDEM 21 20.8 TANDEM REPLAYS AND TELEMETRY 22 21. -

Journal of Asia Cross Country Rally
KYB TECHNICAL REVIEW No. 56 APR. 2018 Introduction Journal of Asia Cross Country Rally TANAKA Kazuhiro 1 Introduction attack racing. To compare, this would be like driving from Tokyo to Nagoya on general roads in a day of which the The Asia Cross Country Rally (hereinafter "AXCR") is section between Kanagawa and Shizuoka Prefectures is a South East Asia's largest four-/two-wheel rally raid race competition. certified by the International Automobile Federation (FIA) and the International Motorcycling Federation (FIM). Starting from the Kingdom of Thailand, partici- pants drive through its neighboring countries. The 2017 AXCR marked 22 years of history. This is a formal inter- national competition of this kind that is geographically closest to Japan and can be expected for the country to deliver a tremendous advertisement effect in the Asian region. Many Japanese teams with business strategies enter the rally, including those based on Japanese automo- bile manufacturers or four-wheel drive (4WD) vehicle related companies. Particularly in recent years, AXCR has seen a fierce battle for championships by international cars for emerging countries manufactured by various Photo 1 Bad road surface due to rainfall automobile makers. The participating teams have substan- tially raised their racing level in their rally vehicles with dramatically improved performance. From Japan, a lot of private teams also participate in the rally probably because 2 Position of Cross Country Rallies AXCR takes place during the summer holiday season in Japan and the costs incurred for participation is reason- Motorsports of four-wheel cars can be roughly classi- able. fied into three types: racing, rallying and trials. -

Drifting Performance
Racelogic Ltd Introduction Congratulations on your purchase and welcome to the worldwide DriftBox community. Drifting With your DriftBox you will be able to display and log your drifting performance. DriftBox also generates a performance related Drifting Score, which you can submit to the DriftBox website for inclusion in the worldwide DriftBox drifting league tables. See how your skills compare to other DriftBox users from around the world at www.driftbox.com Performance With DriftBox it is very easy to measure acceleration times, braking distances, quarter mile times and many more. There are a number of configurable screens that show specific test results such as 0-60, 0-100, 0-100-0, ½ mile and ¼ mile etc. DriftBox is based on the Racelogic VBOX, which is used by the majority of Car Manufacturers, Tyre Manufacturers and car magazines around the world to assess performance. Because it is very easy to edit the test ranges, DriftBox is a very powerful tool for use in many different kinds of vehicle testing. - 1 - Racelogic Ltd Introduction Lap Timing Displaying your Lap times as you drive around a circuit is simple with DriftBox. You can display your last and best Lap times and Lap count, and also display split times for up to six specified split points around the lap. Through the DriftBox website and forum you are able to download circuit overlays from around the world, compare lap times, and share lap overlay data with other users. Speed Display DriftBox has a display screen mode that shows a large digital speed value and compass. In open conditions, DriftBox has a velocity accuracy of 0.1km/h, which is useful for checking the accuracy of your vehicle’s speedometer. -

The Complete Stories
The Complete Stories by Franz Kafka a.b.e-book v3.0 / Notes at the end Back Cover : "An important book, valuable in itself and absolutely fascinating. The stories are dreamlike, allegorical, symbolic, parabolic, grotesque, ritualistic, nasty, lucent, extremely personal, ghoulishly detached, exquisitely comic. numinous and prophetic." -- New York Times "The Complete Stories is an encyclopedia of our insecurities and our brave attempts to oppose them." -- Anatole Broyard Franz Kafka wrote continuously and furiously throughout his short and intensely lived life, but only allowed a fraction of his work to be published during his lifetime. Shortly before his death at the age of forty, he instructed Max Brod, his friend and literary executor, to burn all his remaining works of fiction. Fortunately, Brod disobeyed. Page 1 The Complete Stories brings together all of Kafka's stories, from the classic tales such as "The Metamorphosis," "In the Penal Colony" and "The Hunger Artist" to less-known, shorter pieces and fragments Brod released after Kafka's death; with the exception of his three novels, the whole of Kafka's narrative work is included in this volume. The remarkable depth and breadth of his brilliant and probing imagination become even more evident when these stories are seen as a whole. This edition also features a fascinating introduction by John Updike, a chronology of Kafka's life, and a selected bibliography of critical writings about Kafka. Copyright © 1971 by Schocken Books Inc. All rights reserved under International and Pan-American Copyright Conventions. Published in the United States by Schocken Books Inc., New York. Distributed by Pantheon Books, a division of Random House, Inc., New York. -

First-Time Snowboarders D/02
D/01 Section D - teaching beginner snowboarders In this chapter we 12 will explore... An example progression for first-timers. All first time lessons should begin on flat terrain, with as First-Time much space as possible and minimal traffic. Generic goals for any Snowboarders first-timer lesson include: staying safe whilst becoming familiar with the snowboard, learning Equipment intro, board how to move around mobility & basic stance on flat ground with one foot strapped in; learning Skating, gliding, climbing how to stop and change direction on both the heel and toe edge. Straight runs & direction changes (J-turns) The order of the following exercises will change relative to the available Two-footed orientation terrain and snow conditions, and your students’ physical ability, Side Slipping age and fitness. All of these exercises may not be needed in every lesson Floating leaf so make sensible decisions to maximise the students’ learning time. Lift riding CHAPTER 12 / FIRST-TIME SNOWBOARDERS D/02 Equipment intro, board mobility & basic stance What, why, how Getting to know the equipment (board, boots and bindings etc.), strapping the board on with one foot to get used to how it feels, and introducing an action-ready stance to use when snowboarding. To understand how to use equipment safely, to get comfortable balancing and moving around with the snowboard attached to the leading foot, and to build a stable position to move from when snowboarding. EQUIPMENT Start by checking everyone’s boots are tight enough. Hold the snowboard nose up so that the bindings are facing the group and introduce the nose and tail, toe and heel edges, then turn the snowboard over, base out, and explain the side-cut and edges. -

Spirit Mountain Task Force
SPIRIT MOUNTAIN TASK FORCE RECOMMENDATIONS MARCH 2021 0 SPIRIT MOUNTAIN TASK FORCE MEMBERS Co-Chairs: City Councilor Arik Forsman, Parks, Libraries and Authorities Chair City Councilor Janet Kennedy, Fifth District Task Force Members: Matt Baumgartner Amy Brooks Barbara Carr Michele Dressel Mark Emmel Daniel Hartman Hansi Johnson Noah Kramer Dale Lewis Sam Luoma Chris Rubesch Scott Youngdahl Aaron Stolp, Spirit Mountain Recreation Area Authority Board Chair Wayne DuPuis, an Indigenous representative with expertise in Indigenous cultural resources Ex officio members: Gretchen Ransom, Dave Wadsworth and Jane Kaiser (retired), directors at Spirit Mountain Anna Tanski, executive director of Visit Duluth Tim Miller and Bjorn Reed, representatives of the Spirit Mountain workforce selected in consultation with the AFSCME collective bargaining unit 1 CONTENTS Spirit Mountain Task Force Members ........................................................................................................................... 1 Introduction ................................................................................................................................................................... 3 Executive Summary ....................................................................................................................................................... 4 Fulfilling the Charge ....................................................................................................................................................... 5 Business -

Rum Cay Article
THEKITEBOARDER.COM The Best Kept Secret of the Bahamas Rum Cay: FROM REP TO DESIGNER: SLINGSHOt’S AMERY BERNARD MAKING A DIFFERENCE SOUTH OF THE BORDER HOT NEW PRODUCTS 23FOR 2011 THIS LIQUID IS FORCE SURF rider: JULIEN photo: SKIP BOARDS FILLION BANKS LIQUIDFORCEKITES.COM 2 THEKITEBOARDER.COM THEKITEBOARDER.COM 3 DEPARTMENTS Liquid Force 30 Close Up rider Jan Wainman Hawaii’s Spencer Lujan and North’s THEKITEBOARDER.COM Schiegnitz called Megan O’Leary. this session at Harmanus in 58 Designer’s Corner South Africa the Tech out with designers on seven new The Best Kept spring releases. best session of Secret of the Bahamas his life. Photo Rum Cay: 64 Analyze This Jens Hogenkamp TKB’s verdict on seven new 2011 products. FROM REP TO DESIGNER: SLINGSHOt’S AMERY BERNARD 71 Workbench MAKING A DIFFERENCE SOUTH OF THE BORDER Rider: Peter Schiebel HOT NEW PRODUCTS 23FOR 2011 Ghetto fixes to get you back on the water. Kirsty Jones grabs a surf session in Mauritius. Photo Ocean Therapy 5’10” TRESPASS 9M SPITFIRE 5’10” TRESPASS LAUNCH Zach Kleppe entertains the crowd with a particularly good wipeout. The new Kitehero Fin Mount is a solid way to attach your BOARD MOUNTS FEATURESGoPro to your twin tip. Photo Jim Stringfellow For mounting a GoPro to your twin tip, the all new Kitehero Fin Mount is a much safer and more secure alternative solution to GoPro’s adhesive disk mount. Utilizing the standard fin holes on virtually any kiteboard or wakeboard, the durable low profile plastic base gives riders an unobtrusive way to mount a camera to their deck. -
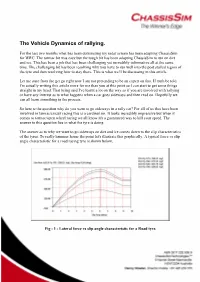
The Vehicle Dynamics of Rallying
The Vehicle Dynamics of rallying. For the last two months what has been dominating my radar screen has been adapting ChassisSim for WRC. The tarmac bit was easy but the tough bit has been adapting ChassisSim to run on dirt and ice. This has been a job that has been challenging yet incredibly informative all at the same time. The challenging bit has been resolving why you have to run well into the post stalled region of the tyre and then resolving how to stay there. This is what we'll be discussing in this article. Let me state from the get go right now I am not pretending to be an expert on this. If truth be told I'm actually writing this article more for me than you at this point so I can start to get some things straight in my head. That being said I've learnt a lot on the way so if you are involved with rallying or have any interest as to what happens when a car goes sideways and then read on. Hopefully we can all learn something in the process. So here is the question why do you want to go sideways in a rally car? For all of us that have been involved in tarmac/circuit racing this is a cardinal sin. It looks incredibly impressive but when it comes to tarmac/open wheel racing we all know it's a guaranteed way to kill your speed. The answer to this question lies in what the tyre is doing. The answer as to why we want to go sideways on dirt and ice comes down to the slip characteristics of the tyres. -

CANBERRA MOUNTAIN BIKE REPORT Draft December 2019
N CANBERRA MOUNTAIN BIKE REPORT Draft December 2019 Prepared by The Canberra Mountain Bike Report has been prepared by TRC Tourism Pty Ltd for ACT Parks and Conservation Service. Acknowledgements We acknowledge the Traditional Custodians of the ACT, the Ngunnawal people. We acknowledge and respect their continuing culture and the contribution they make to the life of Canberra and the region. TRC Tourism would also like to acknowledge the contribution of the many stakeholders involved in this project, particularly the Project Reference Group: Rod Griffiths, National Parks Association, Jake Hannah, Majura Pines Trail Alliance, Mic Longhurst, Dynamic Motivation, Raynie McNee, Cycle Education, Lisa Morisset, Mountain Bike Australia, Kelly Ryan, Visit Canberra, Darren Stewart CORC, Jeff VanAalst, Stromlo Forest Park, Alan Vogt, Kowalski Brothers, Ryan Walsch, Fixed by Ryan and Claire Whiteman. Images: Courtesy of ACT Government, Spring Photo Competition, credits shown with image Front Cover Photos: Spring Photo Competition ACT Government (see credits in document) Map Design: TRC Tourism and Alan Vogt Disclaimer Any representation, statement, opinion or advice, expressed or implied in this document is made in good faith and on the basis that TRC Tourism Pty Ltd is not liable to any person for any damage or loss whatsoever which has occurred or may occur in relation to that person taking or not taking action in respect of any representation, statement or advice referred to in this document. www.trctourism.com DRAFT Canberra Mountain Bike Report| December 2019 i Contents Executive Summary v 1 Introduction 1 2 Strategic Context 5 3 The Mountain Bike Tourism Market 9 4 The Characteristics of Mountain Bikers 15 5 What Makes a Successful Mountain Bike Destination? 21 6 Canberra as a Mountain Bike Destination 24 7 Investing in New Trails - Potential Locations 43 8 The Canberra Mountain Bike Report 60 9 A Sustainable Management Model for the ACT 70 10 Benefits of the Report 75 11 Conclusion 79 Appendices 80 a. -

Iheludttta Camfiie&M&Tve
^ S O C IA ^ O c t o S e r 1 9 9 % iHeludttta camfiie&m&tve Main picture: Karen Taylor of Rochdale at Whittle Pike (photo - Steve Bateson) Inset: Three Lakeland Classics ........~ Top: John Humble on the Wasdale Horseslictt*(fikoto - Steve Bateson) Middle : Fit-sfo/40 lady at Borrowdale,Jane Smith, Bingley - (photo Dave Woodhead) Bottom : Buttermere Sailheck :..Br<^ Connor descending W hiteless Pike (photo - Petjr H artley) G ET A GRI? ! - lightweight fell, cross country and orienteering shoe - emphasis on comfort and grip, with a unique sole design - anatomical shaped footbed and durable Cambrelle lining - hard wearing, low water retention and quick drying VELON upper material Specifications include : • superior comfort • specially designed sole with moulded protective toe band • top quality EVA midsole for long life cushioning • U. K. sizes 4-14 (including Vi sizes) • R. R. P. STILL ONLY £ 49.99 FELLDANCE R NOW AVAILABLE AT LEADING DUTDDDR AND RUNNING SHOPS, OR CONTACT 27 S t . J a m es S t ., Ba c u p , La n c s ., DL1 3 9NJ TEL./Fa x (□ 1 YDS) 8 7 B 7 3 B THE ULTIMATE FELL SHOE — ,&fEaRUV/te> The World Trophy, being on a tropical island some Advertising Rates: Bit at the Front - Neil Denby where off the coast of South America, was even more V £ 160 Ful1 Pa"c- £ 100 Half Page Sacrilege to suggest it, I know, but with the sys elitist this year than usual - certainly no prospect of a 4ssoaftT\0^ 4~>5.00 Quarter Page. £30 Eighth Page tem for collecting results running so efficiently, that bus trip! centre section is starting to take over the whole Founded 4th April 1970 Early information filtering back seems to indicate Classified Advertisements: magazine.