Geometry of High-Dimensional Space
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analytic Geometry
Guide Study Georgia End-Of-Course Tests Georgia ANALYTIC GEOMETRY TABLE OF CONTENTS INTRODUCTION ...........................................................................................................5 HOW TO USE THE STUDY GUIDE ................................................................................6 OVERVIEW OF THE EOCT .........................................................................................8 PREPARING FOR THE EOCT ......................................................................................9 Study Skills ........................................................................................................9 Time Management .....................................................................................10 Organization ...............................................................................................10 Active Participation ...................................................................................11 Test-Taking Strategies .....................................................................................11 Suggested Strategies to Prepare for the EOCT ..........................................12 Suggested Strategies the Day before the EOCT ........................................13 Suggested Strategies the Morning of the EOCT ........................................13 Top 10 Suggested Strategies during the EOCT .........................................14 TEST CONTENT ........................................................................................................15 -

Spheres in Infinite-Dimensional Normed Spaces Are Lipschitz Contractible
PROCEEDINGS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 88. Number 3, July 1983 SPHERES IN INFINITE-DIMENSIONAL NORMED SPACES ARE LIPSCHITZ CONTRACTIBLE Y. BENYAMINI1 AND Y. STERNFELD Abstract. Let X be an infinite-dimensional normed space. We prove the following: (i) The unit sphere {x G X: || x II = 1} is Lipschitz contractible. (ii) There is a Lipschitz retraction from the unit ball of JConto the unit sphere. (iii) There is a Lipschitz map T of the unit ball into itself without an approximate fixed point, i.e. inffjjc - Tx\\: \\x\\ « 1} > 0. Introduction. Let A be a normed space, and let Bx — {jc G X: \\x\\ < 1} and Sx = {jc G X: || jc || = 1} be its unit ball and unit sphere, respectively. Brouwer's fixed point theorem states that when X is finite dimensional, every continuous self-map of Bx admits a fixed point. Two equivalent formulations of this theorem are the following. 1. There is no continuous retraction from Bx onto Sx. 2. Sx is not contractible, i.e., the identity map on Sx is not homotopic to a constant map. It is well known that none of these three theorems hold in infinite-dimensional spaces (see e.g. [1]). The natural generalization to infinite-dimensional spaces, however, would seem to require the maps to be uniformly-continuous and not merely continuous. Indeed in the finite-dimensional case this condition is automatically satisfied. In this article we show that the above three theorems fail, in the infinite-dimen- sional case, even under the strongest uniform-continuity condition, namely, for maps satisfying a Lipschitz condition. -

Examples of Manifolds
Examples of Manifolds Example 1 (Open Subset of IRn) Any open subset, O, of IRn is a manifold of dimension n. One possible atlas is A = (O, ϕid) , where ϕid is the identity map. That is, ϕid(x) = x. n Of course one possible choice of O is IR itself. Example 2 (The Circle) The circle S1 = (x,y) ∈ IR2 x2 + y2 = 1 is a manifold of dimension one. One possible atlas is A = {(U , ϕ ), (U , ϕ )} where 1 1 1 2 1 y U1 = S \{(−1, 0)} ϕ1(x,y) = arctan x with − π < ϕ1(x,y) <π ϕ1 1 y U2 = S \{(1, 0)} ϕ2(x,y) = arctan x with 0 < ϕ2(x,y) < 2π U1 n n n+1 2 2 Example 3 (S ) The n–sphere S = x =(x1, ··· ,xn+1) ∈ IR x1 +···+xn+1 =1 n A U , ϕ , V ,ψ i n is a manifold of dimension . One possible atlas is 1 = ( i i) ( i i) 1 ≤ ≤ +1 where, for each 1 ≤ i ≤ n + 1, n Ui = (x1, ··· ,xn+1) ∈ S xi > 0 ϕi(x1, ··· ,xn+1)=(x1, ··· ,xi−1,xi+1, ··· ,xn+1) n Vi = (x1, ··· ,xn+1) ∈ S xi < 0 ψi(x1, ··· ,xn+1)=(x1, ··· ,xi−1,xi+1, ··· ,xn+1) n So both ϕi and ψi project onto IR , viewed as the hyperplane xi = 0. Another possible atlas is n n A2 = S \{(0, ··· , 0, 1)}, ϕ , S \{(0, ··· , 0, −1)},ψ where 2x1 2xn ϕ(x , ··· ,xn ) = , ··· , 1 +1 1−xn+1 1−xn+1 2x1 2xn ψ(x , ··· ,xn ) = , ··· , 1 +1 1+xn+1 1+xn+1 are the stereographic projections from the north and south poles, respectively. -

Simple Infinite Presentations for the Mapping Class Group of a Compact
SIMPLE INFINITE PRESENTATIONS FOR THE MAPPING CLASS GROUP OF A COMPACT NON-ORIENTABLE SURFACE RYOMA KOBAYASHI Abstract. Omori and the author [6] have given an infinite presentation for the mapping class group of a compact non-orientable surface. In this paper, we give more simple infinite presentations for this group. 1. Introduction For g ≥ 1 and n ≥ 0, we denote by Ng,n the closure of a surface obtained by removing disjoint n disks from a connected sum of g real projective planes, and call this surface a compact non-orientable surface of genus g with n boundary components. We can regard Ng,n as a surface obtained by attaching g M¨obius bands to g boundary components of a sphere with g + n boundary components, as shown in Figure 1. We call these attached M¨obius bands crosscaps. Figure 1. A model of a non-orientable surface Ng,n. The mapping class group M(Ng,n) of Ng,n is defined as the group consisting of isotopy classes of all diffeomorphisms of Ng,n which fix the boundary point- wise. M(N1,0) and M(N1,1) are trivial (see [2]). Finite presentations for M(N2,0), M(N2,1), M(N3,0) and M(N4,0) ware given by [9], [1], [14] and [16] respectively. Paris-Szepietowski [13] gave a finite presentation of M(Ng,n) with Dehn twists and arXiv:2009.02843v1 [math.GT] 7 Sep 2020 crosscap transpositions for g + n > 3 with n ≤ 1. Stukow [15] gave another finite presentation of M(Ng,n) with Dehn twists and one crosscap slide for g + n > 3 with n ≤ 1, applying Tietze transformations for the presentation of M(Ng,n) given in [13]. -

An Introduction to Topology the Classification Theorem for Surfaces by E
An Introduction to Topology An Introduction to Topology The Classification theorem for Surfaces By E. C. Zeeman Introduction. The classification theorem is a beautiful example of geometric topology. Although it was discovered in the last century*, yet it manages to convey the spirit of present day research. The proof that we give here is elementary, and its is hoped more intuitive than that found in most textbooks, but in none the less rigorous. It is designed for readers who have never done any topology before. It is the sort of mathematics that could be taught in schools both to foster geometric intuition, and to counteract the present day alarming tendency to drop geometry. It is profound, and yet preserves a sense of fun. In Appendix 1 we explain how a deeper result can be proved if one has available the more sophisticated tools of analytic topology and algebraic topology. Examples. Before starting the theorem let us look at a few examples of surfaces. In any branch of mathematics it is always a good thing to start with examples, because they are the source of our intuition. All the following pictures are of surfaces in 3-dimensions. In example 1 by the word “sphere” we mean just the surface of the sphere, and not the inside. In fact in all the examples we mean just the surface and not the solid inside. 1. Sphere. 2. Torus (or inner tube). 3. Knotted torus. 4. Sphere with knotted torus bored through it. * Zeeman wrote this article in the mid-twentieth century. 1 An Introduction to Topology 5. -

The Sphere Project
;OL :WOLYL 7YVQLJ[ +XPDQLWDULDQ&KDUWHUDQG0LQLPXP 6WDQGDUGVLQ+XPDQLWDULDQ5HVSRQVH ;OL:WOLYL7YVQLJ[ 7KHULJKWWROLIHZLWKGLJQLW\ ;OL:WOLYL7YVQLJ[PZHUPUP[PH[P]L[VKL[LYTPULHUK WYVTV[LZ[HUKHYKZI`^OPJO[OLNSVIHSJVTT\UP[` /\THUP[HYPHU*OHY[LY YLZWVUKZ[V[OLWSPNO[VMWLVWSLHMMLJ[LKI`KPZHZ[LYZ /\THUP[HYPHU >P[O[OPZ/HUKIVVR:WOLYLPZ^VYRPUNMVYH^VYSKPU^OPJO [OLYPNO[VMHSSWLVWSLHMMLJ[LKI`KPZHZ[LYZ[VYLLZ[HISPZO[OLPY *OHY[LYHUK SP]LZHUKSP]LSPOVVKZPZYLJVNUPZLKHUKHJ[LK\WVUPU^H`Z[OH[ YLZWLJ[[OLPY]VPJLHUKWYVTV[L[OLPYKPNUP[`HUKZLJ\YP[` 4PUPT\T:[HUKHYKZ This Handbook contains: PU/\THUP[HYPHU (/\THUP[HYPHU*OHY[LY!SLNHSHUKTVYHSWYPUJPWSLZ^OPJO HUK YLÅLJ[[OLYPNO[ZVMKPZHZ[LYHMMLJ[LKWVW\SH[PVUZ 4PUPT\T:[HUKHYKZPU/\THUP[HYPHU9LZWVUZL 9LZWVUZL 7YV[LJ[PVU7YPUJPWSLZ *VYL:[HUKHYKZHUKTPUPT\TZ[HUKHYKZPUMV\YRL`SPMLZH]PUN O\THUP[HYPHUZLJ[VYZ!>H[LYZ\WWS`ZHUP[H[PVUHUKO`NPLUL WYVTV[PVU"-VVKZLJ\YP[`HUKU\[YP[PVU":OLS[LYZL[[SLTLU[HUK UVUMVVKP[LTZ"/LHS[OHJ[PVU;OL`KLZJYPILwhat needs to be achieved in a humanitarian response in order for disaster- affected populations to survive and recover in stable conditions and with dignity. ;OL:WOLYL/HUKIVVRLUQV`ZIYVHKV^ULYZOPWI`HNLUJPLZHUK PUKP]PK\HSZVMMLYPUN[OLO\THUP[HYPHUZLJ[VYH common language for working together towards quality and accountability in disaster and conflict situations ;OL:WOLYL/HUKIVVROHZHU\TILYVMºJVTWHUPVU Z[HUKHYKZ»L_[LUKPUNP[ZZJVWLPUYLZWVUZL[VULLKZ[OH[ OH]LLTLYNLK^P[OPU[OLO\THUP[HYPHUZLJ[VY ;OL:WOLYL7YVQLJ[^HZPUP[PH[LKPU I`HU\TILY VMO\THUP[HYPHU5.6ZHUK[OL9LK*YVZZHUK 9LK*YLZJLU[4V]LTLU[ ,+0;065 7KHB6SKHUHB3URMHFWBFRYHUBHQBLQGG The Sphere Project Humanitarian Charter and Minimum Standards in Humanitarian Response Published by: The Sphere Project Copyright@The Sphere Project 2011 Email: [email protected] Website : www.sphereproject.org The Sphere Project was initiated in 1997 by a group of NGOs and the Red Cross and Red Crescent Movement to develop a set of universal minimum standards in core areas of humanitarian response: the Sphere Handbook. -
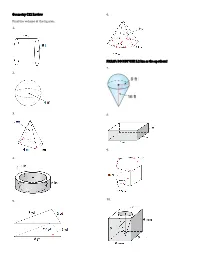
Geometry C12 Review Find the Volume of the Figures. 1. 2. 3. 4. 5. 6
Geometry C12 Review 6. Find the volume of the figures. 1. PREAP: DO NOT USE 5.2 km as the apothem! 7. 2. 3. 8. 9. 4. 10. 5. 11. 16. 17. 12. 18. 13. 14. 19. 15. 20. 21. A sphere has a volume of 7776π in3. What is the radius 33. Two prisms are similar. The ratio of their volumes is of the sphere? 8:27. The surface area of the smaller prism is 72 in2. Find the surface area of the larger prism. 22a. A sphere has a volume of 36π cm3. What is the radius and diameter of the sphere? 22b. A sphere has a volume of 45 ft3. What is the 34. The prisms are similar. approximate radius of the sphere? a. What is the scale factor? 23. The scale factor (ratio of sides) of two similar solids is b. What is the ratio of surface 3:7. What are the ratios of their surface areas and area? volumes? c. What is the ratio of volume? d. Find the volume of the 24. The scale factor of two similar solids is 12:5. What are smaller prism. the ratios of their surface areas and volumes? 35. The prisms are similar. 25. The scale factor of two similar solids is 6:11. What are a. What is the scale factor? the ratios of their surface areas and volumes? b. What is the ratio of surface area? 26. The ratio of the volumes of two similar solids is c. What is the ratio of 343:2197. What is the scale factor (ratio of sides)? volume? d. -

Thermodynamics of Spacetime: the Einstein Equation of State
gr-qc/9504004 UMDGR-95-114 Thermodynamics of Spacetime: The Einstein Equation of State Ted Jacobson Department of Physics, University of Maryland College Park, MD 20742-4111, USA [email protected] Abstract The Einstein equation is derived from the proportionality of entropy and horizon area together with the fundamental relation δQ = T dS connecting heat, entropy, and temperature. The key idea is to demand that this relation hold for all the local Rindler causal horizons through each spacetime point, with δQ and T interpreted as the energy flux and Unruh temperature seen by an accelerated observer just inside the horizon. This requires that gravitational lensing by matter energy distorts the causal structure of spacetime in just such a way that the Einstein equation holds. Viewed in this way, the Einstein equation is an equation of state. This perspective suggests that it may be no more appropriate to canonically quantize the Einstein equation than it would be to quantize the wave equation for sound in air. arXiv:gr-qc/9504004v2 6 Jun 1995 The four laws of black hole mechanics, which are analogous to those of thermodynamics, were originally derived from the classical Einstein equation[1]. With the discovery of the quantum Hawking radiation[2], it became clear that the analogy is in fact an identity. How did classical General Relativity know that horizon area would turn out to be a form of entropy, and that surface gravity is a temperature? In this letter I will answer that question by turning the logic around and deriving the Einstein equation from the propor- tionality of entropy and horizon area together with the fundamental relation δQ = T dS connecting heat Q, entropy S, and temperature T . -

The Boundary Manifold of a Complex Line Arrangement
Geometry & Topology Monographs 13 (2008) 105–146 105 The boundary manifold of a complex line arrangement DANIEL CCOHEN ALEXANDER ISUCIU We study the topology of the boundary manifold of a line arrangement in CP2 , with emphasis on the fundamental group G and associated invariants. We determine the Alexander polynomial .G/, and more generally, the twisted Alexander polynomial associated to the abelianization of G and an arbitrary complex representation. We give an explicit description of the unit ball in the Alexander norm, and use it to analyze certain Bieri–Neumann–Strebel invariants of G . From the Alexander polynomial, we also obtain a complete description of the first characteristic variety of G . Comparing this with the corresponding resonance variety of the cohomology ring of G enables us to characterize those arrangements for which the boundary manifold is formal. 32S22; 57M27 For Fred Cohen on the occasion of his sixtieth birthday 1 Introduction 1.1 The boundary manifold Let A be an arrangement of hyperplanes in the complex projective space CPm , m > 1. Denote by V S H the corresponding hypersurface, and by X CPm V its D H A D n complement. Among2 the origins of the topological study of arrangements are seminal results of Arnol’d[2] and Cohen[8], who independently computed the cohomology of the configuration space of n ordered points in C, the complement of the braid arrangement. The cohomology ring of the complement of an arbitrary arrangement A is by now well known. It is isomorphic to the Orlik–Solomon algebra of A, see Orlik and Terao[34] as a general reference. -

Slices, Slabs, and Sections of the Unit Hypercube
Slices, Slabs, and Sections of the Unit Hypercube Jean-Luc Marichal Michael J. Mossinghoff Institute of Mathematics Department of Mathematics University of Luxembourg Davidson College 162A, avenue de la Fa¨ıencerie Davidson, NC 28035-6996 L-1511 Luxembourg USA Luxembourg [email protected] [email protected] Submitted: July 27, 2006; Revised: August 6, 2007; Accepted: January 21, 2008; Published: January 29, 2008 Abstract Using combinatorial methods, we derive several formulas for the volume of convex bodies obtained by intersecting a unit hypercube with a halfspace, or with a hyperplane of codimension 1, or with a flat defined by two parallel hyperplanes. We also describe some of the history of these problems, dating to P´olya’s Ph.D. thesis, and we discuss several applications of these formulas. Subject Class: Primary: 52A38, 52B11; Secondary: 05A19, 60D05. Keywords: Cube slicing, hyperplane section, signed decomposition, volume, Eulerian numbers. 1 Introduction In this note we study the volumes of portions of n-dimensional cubes determined by hyper- planes. More precisely, we study slices created by intersecting a hypercube with a halfspace, slabs formed as the portion of a hypercube lying between two parallel hyperplanes, and sections obtained by intersecting a hypercube with a hyperplane. These objects occur natu- rally in several fields, including probability, number theory, geometry, physics, and analysis. In this paper we describe an elementary combinatorial method for calculating volumes of arbitrary slices, slabs, and sections of a unit cube. We also describe some applications that tie these geometric results to problems in analysis and combinatorics. Some of the results we obtain here have in fact appeared earlier in other contexts. -

Graph Manifolds and Taut Foliations Mark Brittenham1, Ramin Naimi, and Rachel Roberts2 Introduction
Graph manifolds and taut foliations 1 2 Mark Brittenham , Ramin Naimi, and Rachel Roberts UniversityofTexas at Austin Abstract. We examine the existence of foliations without Reeb comp onents, taut 1 1 foliations, and foliations with no S S -leaves, among graph manifolds. We show that each condition is strictly stronger than its predecessors, in the strongest p os- sible sense; there are manifolds admitting foliations of eachtyp e which do not admit foliations of the succeeding typ es. x0 Introduction Taut foliations have b een increasingly useful in understanding the top ology of 3-manifolds, thanks largely to the work of David Gabai [Ga1]. Many 3-manifolds admit taut foliations [Ro1],[De],[Na1], although some do not [Br1],[Cl]. To date, however, there are no adequate necessary or sucient conditions for a manifold to admit a taut foliation. This pap er seeks to add to this confusion. In this pap er we study the existence of taut foliations and various re nements, among graph manifolds. What we show is that there are many graph manifolds which admit foliations that are as re ned as wecho ose, but which do not admit foliations admitting any further re nements. For example, we nd manifolds which admit foliations without Reeb comp onents, but no taut foliations. We also nd 0 manifolds admitting C foliations with no compact leaves, but which do not admit 2 any C such foliations. These results p oint to the subtle nature b ehind b oth top ological and analytical assumptions when dealing with foliations. A principal motivation for this work came from a particularly interesting exam- ple; the manifold M obtained by 37/2 Dehn surgery on the 2,3,7 pretzel knot K . -

A TEXTBOOK of TOPOLOGY Lltld
SEIFERT AND THRELFALL: A TEXTBOOK OF TOPOLOGY lltld SEI FER T: 7'0PO 1.OG 1' 0 I.' 3- Dl M E N SI 0 N A I. FIRERED SPACES This is a volume in PURE AND APPLIED MATHEMATICS A Series of Monographs and Textbooks Editors: SAMUELEILENBERG AND HYMANBASS A list of recent titles in this series appears at the end of this volunie. SEIFERT AND THRELFALL: A TEXTBOOK OF TOPOLOGY H. SEIFERT and W. THRELFALL Translated by Michael A. Goldman und S E I FE R T: TOPOLOGY OF 3-DIMENSIONAL FIBERED SPACES H. SEIFERT Translated by Wolfgang Heil Edited by Joan S. Birman and Julian Eisner @ 1980 ACADEMIC PRESS A Subsidiary of Harcourr Brace Jovanovich, Publishers NEW YORK LONDON TORONTO SYDNEY SAN FRANCISCO COPYRIGHT@ 1980, BY ACADEMICPRESS, INC. ALL RIGHTS RESERVED. NO PART OF THIS PUBLICATION MAY BE REPRODUCED OR TRANSMITTED IN ANY FORM OR BY ANY MEANS, ELECTRONIC OR MECHANICAL, INCLUDING PHOTOCOPY, RECORDING, OR ANY INFORMATION STORAGE AND RETRIEVAL SYSTEM, WITHOUT PERMISSION IN WRITING FROM THE PUBLISHER. ACADEMIC PRESS, INC. 11 1 Fifth Avenue, New York. New York 10003 United Kingdom Edition published by ACADEMIC PRESS, INC. (LONDON) LTD. 24/28 Oval Road, London NWI 7DX Mit Genehmigung des Verlager B. G. Teubner, Stuttgart, veranstaltete, akin autorisierte englische Ubersetzung, der deutschen Originalausgdbe. Library of Congress Cataloging in Publication Data Seifert, Herbert, 1897- Seifert and Threlfall: A textbook of topology. Seifert: Topology of 3-dimensional fibered spaces. (Pure and applied mathematics, a series of mono- graphs and textbooks ; ) Translation of Lehrbuch der Topologic. Bibliography: p. Includes index. 1.