John, It's My Great Pleasure to Have Published Five Books with You, for Which I've Thanked You Five Times in These Books
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Progress in the R Ecosystem for Representing and Handling Spatial Data
Journal of Geographical Systems https://doi.org/10.1007/s10109-020-00336-0 ORIGINAL ARTICLE Progress in the R ecosystem for representing and handling spatial data Roger S. Bivand1 Received: 9 October 2019 / Accepted: 8 September 2020 © The Author(s) 2020 Abstract Twenty years have passed since Bivand and Gebhardt (J Geogr Syst 2(3):307–317, 2000. https ://doi.org/10.1007/PL000 11460 ) indicated that there was a good match between the then nascent open-source R programming language and environment and the needs of researchers analysing spatial data. Recalling the development of classes for spatial data presented in book form in Bivand et al. (Applied spatial data analysis with R. Springer, New York, 2008, Applied spatial data analysis with R, 2nd edn. Springer, New York, 2013), it is important to present the progress now occurring in representation of spatial data, and possible consequences for spatial data handling and the statistical analysis of spatial data. Beyond this, it is imperative to discuss the relationships between R-spatial software and the larger open-source geospatial software community on whose work R packages crucially depend. Keywords Spatial data analysis · Open-source software · R programming language JEL Classifcation C00 · C88 · R15 1 Introduction While Bivand and Gebhardt (2000) did provide an introduction to R as a statistical programming language and to why one might choose to use a scripted language like R (or Python), this article is both retrospective and prospective. It is possible that those approaching the choice of tools for spatial analysis and for handling spatial data will fnd the following less than inviting; in that case, perusal of early chapters of Lovelace et al. -

Advanced R Second Edition Chapman & Hall/CRC the R Series Series Editors John M
Advanced R Second Edition Chapman & Hall/CRC The R Series Series Editors John M. Chambers, Department of Statistics, Stanford University, California, USA Torsten Hothorn, Division of Biostatistics, University of Zurich, Switzerland Duncan Temple Lang, Department of Statistics, University of California, Davis, USA Hadley Wickham, RStudio, Boston, Massachusetts, USA Recently Published Titles Testing R Code Richard Cotton R Primer, Second Edition Claus Thorn Ekstrøm Flexible Regression and Smoothing: Using GAMLSS in R Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda De Bastiani The Essentials of Data Science: Knowledge Discovery Using R Graham J. Williams blogdown: Creating Websites with R Markdown Yihui Xie, Alison Presmanes Hill, Amber Thomas Handbook of Educational Measurement and Psychometrics Using R Christopher D. Desjardins, Okan Bulut Displaying Time Series, Spatial, and Space-Time Data with R, Second Edition Oscar Perpinan Lamigueiro Reproducible Finance with R Jonathan K. Regenstein, Jr. R Markdown The Definitive Guide Yihui Xie, J.J. Allaire, Garrett Grolemund Practical R for Mass Communication and Journalism Sharon Machlis Analyzing Baseball Data with R, Second Edition Max Marchi, Jim Albert, Benjamin S. Baumer Spatio-Temporal Statistics with R Christopher K. Wikle, Andrew Zammit-Mangion, and Noel Cressie Statistical Computing with R, Second Edition Maria L. Rizzo Geocomputation with R Robin Lovelace, Jakub Nowosad, Jannes Münchow Dose-Response Analysis with R Christian Ritz, Signe M. Jensen, Daniel Gerhard, Jens C. Streibig Advanced R, Second Edition Hadley Wickham For more information about this series, please visit: https://www.crcpress.com/go/ the-r-series Advanced R Second Edition Hadley Wickham CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 2019 by Taylor & Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. -

Navigating the R Package Universe by Julia Silge, John C
CONTRIBUTED RESEARCH ARTICLES 558 Navigating the R Package Universe by Julia Silge, John C. Nash, and Spencer Graves Abstract Today, the enormous number of contributed packages available to R users outstrips any given user’s ability to understand how these packages work, their relative merits, or how they are related to each other. We organized a plenary session at useR!2017 in Brussels for the R community to think through these issues and ways forward. This session considered three key points of discussion. Users can navigate the universe of R packages with (1) capabilities for directly searching for R packages, (2) guidance for which packages to use, e.g., from CRAN Task Views and other sources, and (3) access to common interfaces for alternative approaches to essentially the same problem. Introduction As of our writing, there are over 13,000 packages on CRAN. R users must approach this abundance of packages with effective strategies to find what they need and choose which packages to invest time in learning how to use. At useR!2017 in Brussels, we organized a plenary session on this issue, with three themes: search, guidance, and unification. Here, we summarize these important themes, the discussion in our community both at useR!2017 and in the intervening months, and where we can go from here. Users need options to search R packages, perhaps the content of DESCRIPTION files, documenta- tion files, or other components of R packages. One author (SG) has worked on the issue of searching for R functions from within R itself in the sos package (Graves et al., 2017). -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

BUSMGT 7331: Descriptive Analytics and Visualization
BUSMGT 7331: Descriptive Analytics and Visualization Spring 2019, Term 1 January 7, 2019 Instructor: Hyunwoo Park (https://fisher.osu.edu/people/park.2706) Office: Fisher Hall 632 Email: [email protected] Phone: 614-292-3166 Class Schedule: 8:30am-12:pm Saturday 1/19, 2/2, 2/16 Recitation/Office Hours: Thursdays 6:30pm-8pm at Gerlach 203 (also via WebEx) 1 Course Description Businesses and organizations today collect and store unprecedented quantities of data. In order to make informed decisions with such a massive amount of the accumulated data, organizations seek to adopt and utilize data mining and machine learning techniques. Applying advanced techniques must be preceded by a careful examination of the raw data. This step becomes increasingly important and also easily overlooked as the amount of data increases because human examination is prone to fail without adequate tools to describe a large dataset. Another growing challenge is to communicate a large dataset and complicated models with human decision makers. Descriptive analytics, and visualizations in particular, helps find patterns in the data and communicate the insights in an effective manner. This course aims to equip students with methods and techniques to summarize and communicate the underlying patterns of different types of data. This course serves as a stepping stone for further predictive and prescriptive analytics. 2 Course Learning Outcomes By the end of this course, students should successfully be able to: • Identify various distributions that frequently occur in observational data. • Compute key descriptive statistics from data. • Measure and interpret relationships among variables. • Transform unstructured data such as texts into structured format. -

Data Analysis in R
Data Analysis in R Course at a Glance This course will provide an introduction to reproducible data analysis with R (see Syllabus). Instructor Gabriel Baud-Bovy ([email protected] ) Credits: 5 Synopsis This course aims at giving to the student a methodology to analyze experimental results, from how to organize data to the writing of a report. It includes: an introduction to R an introduction to reproducible research with R examples of statistical analysis with R During this course, the student will have to analyze his own data and is expected to read before each course the material that will be made available on this page. The final grade will consist in the evaluation of a report demonstrating familiarity with the concepts and methods presented in the course. As an editor, the instructor will use Notepad++ (together with NppToR) on a Windows Machines but the student might use other ones (e.g., R studio, EMACS+ESS, Lyx, TexWork). The course will use Mardown as typesetting language. For those desirous to work with Latex and/or generate pdf, you will need to install also MikeTex. Syllabus Total of 15 hours Class 1: Case study, Reproducible research Class 2: R fundamental Class 3: Exploratory data analysis and graphical methods in R Class 4: Basic statistics Class 5: To be determined There will be a final examination decided by the instructor. Prerequisites The course assumes some familiarity with programming concepts and data structures (MATLAB, C/C++, Java or any other programming language). Contact the instructor if you have never programmed anything. -

A History of R (In 15 Minutes… and Mostly in Pictures)
A history of R (in 15 minutes… and mostly in pictures) JULY 23, 2020 Andrew Zief!ler Lunch & Learn Department of Educational Psychology RMCC University of Minnesota LATIS Who am I and Some Caveats Andy Zie!ler • I teach statistics courses in the Department of Educational Psychology • I have been using R since 2005, when I couldn’t put Me (on the EPSY faculty board) SAS on my computer (it didn’t run natively on a Me Mac), and even if I could have gotten it to run, I (everywhere else) couldn’t afford it. Some caveats • Although I was alive during much of the era I will be talking about, I was not working as a statistician at that time (not even as an elementary student for some of it). • My knowledge is second-hand, from other people and sources. Statistical Computing in the 1970s Bell Labs In 1976, scientists from the Statistics Research Group were actively discussing how to design a language for statistical computing that allowed interactive access to routines in their FORTRAN library. John Chambers John Tukey Home to Statistics Research Group Rick Becker Jean Mc Rae Judy Schilling Doug Dunn Introducing…`S` An Interactive Language for Data Analysis and Graphics Chambers sketch of the interface made on May 5, 1976. The GE-635, a 36-bit system that ran at a 0.5MIPS, starting at $2M in 1964 dollars or leasing at $45K/month. ’S’ was introduced to Bell Labs in November, but at the time it did not actually have a name. The Impact of UNIX on ’S' Tom London Ken Thompson and Dennis Ritchie, creators of John Reiser the UNIX operating system at a PDP-11. -

Conference Brochure S P E a K E R S
04.07.2017 – 07.07.2017 www.user2017.brussels @useR_Brussels #user2017 CONFERENCE BROCHURE S P E A K E R S 2 As a student my use of R for data analyses was frowned upon - the suggestion was to stick with the existing software. P Access to R related literature was difficult. To admire R the very first R books one had to travel far, to the few enlightened universities. As a researcher I needed the help E of a secret floppy disk to dual boot into a GNU/Linux system with R, in order to escape from unnamed products. As a F starter in industry, people from unnamed companies made clear to my management that setting up R events for customers was A giving a ‘wrong signal to the market’. C Look how ‘wrong’ we have been... Fifteen years later R is shining brightly in the data science field. Students are E learning R before anything else and if statistics research is published without accompanying R package, it is considered a bad sign. Publishers have hundreds of books on display and major software houses are in a constant race against time to further integrate R into their product offerings. And now, more than 1000 people from all over the world have come to Brussels to discover the state of R at this conference. R has come a great way and the community that formed around the R project is and has always been critical to its success. The community has evolved in many ways and is active in many places throughout the year, but of all things the official useR conference still is the major community event of the year. -

August 12-14, Dortmund, Germany
AASC Austrian Association for Statistical Computing 2008 Program August 12-14, Dortmund, Germany useR! 2008, Dortmund, Germany 1 Contents Greetings and Miscellaneous 2 Maps 5 Social Program 8 Program 9 Tutorials 9 Schedule 10 List of Talks 14 2 useR! 2008, Dortmund, Germany Dear useRs, the following pages provide you with some useful information about useR! 2008, the R user con- ference, taking place at the Fakultät Statistik, Technische Universität Dortmund, Germany from 2008-08-12 to 2008-08-14. Pre-conference tutorials will take place on August 11. The confer- ence is organized by the Fakultät Statistik, Technische Universität Dortmund and the Austrian Association for Statistical Computing (AASC). Apart from challenging and likewise exciting scientific contributions we hope to offer you an attractive conference site and a pleasant social program. With best regards from the organizing team: Uwe Ligges (conference), Achim Zeileis (program), Claus Weihs, Gerd Kopp (local organiza- tion), Friedrich Leisch, and Torsten Hothorn Address / Contact Address: Uwe Ligges Fakultät Statistik Technische Universität Dortmund 44221 Dortmund Germany Phone: +49 231 755 4353 Fax: +49 231 755 4387 e-mail: [email protected] URL: http://www.R-Project.org/useR-2008/ Program Committee Micah Altman, Roger Bivand, Peter Dalgaard, Jan de Leeuw, Ramón Díaz-Uriarte, Spencer Graves, Leonhard Held, Torsten Hothorn, François Husson, Christian Kleiber, Friedrich Leisch, Andy Liaw, Martin Mächler, Kate Mullen, Ei-ji Nakama, Thomas Petzoldt, Martin Theus, and Heather Turner Conference Location Technische Universität Dortmund Campus Nord Mathematikgebäude / Audimax Vogelpothsweg 87 44227 Dortmund Conference Office Opening hours: Monday, August 11: 08:30–19:30 Tuesday, August 12: 08:30–18:30 Wednesday, August 13: 08:30–18:30 Thursday, August 14: 08:30–15:30 useR! 2008, Dortmund, Germany 3 Public Transport The conference site at the university campus and the city hall are best to be reached by public transport. -

Introduction to Data Science for Transportation Researchers, Planners, and Engineers
Portland State University PDXScholar Transportation Research and Education Center TREC Final Reports (TREC) 1-2017 Introduction to Data Science for Transportation Researchers, Planners, and Engineers Liming Wang Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/trec_reports Part of the Transportation Commons, Urban Studies Commons, and the Urban Studies and Planning Commons Let us know how access to this document benefits ou.y Recommended Citation Wang, Liming. Introduction to Data Science for Transportation Researchers, Planners, and Engineers. NITC-ED-854. Portland, OR: Transportation Research and Education Center (TREC), 2018. https://doi.org/ 10.15760/trec.192 This Report is brought to you for free and open access. It has been accepted for inclusion in TREC Final Reports by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. FINAL REPORT Introduction to Data Science for Transportation Researchers, Planners, and Engineers NITC-ED-854 January 2018 NITC is a U.S. Department of Transportation national university transportation center. INTRODUCTION TO DATA SCIENCE FOR TRANSPORTATION RESEARCHERS, PLANNERS, AND ENGINEERS Final Report NITC-ED-854 by Liming Wang Portland State University for National Institute for Transportation and Communities (NITC) P.O. Box 751 Portland, OR 97207 January 2017 Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient’s Catalog No. NITC-ED-854 4. Title and Subtitle 5. Report Date Introduction to Data Science for Transportation Researchers, Planners, and Engineers January 2017 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Liming Wang 9. -

Language-Agnostic Data Analysis Workflows and Reproducible Research
Language-agnostic data analysis workflows and reproducible research Andrew John Lowe 28 April 2017 Abstract This is the abstract for a document that briefly describes methods for interacting with different programming languages within the same data analysis workflow. 0.1 Overview • This talk: language-agnostic (or polyglot) analysis workflows • I’ll show how it is possible to work in multiple languages and switch between them without leaving the workflow you started • Additionally, I’ll demonstrate how an entire workflow can be encapsulated in a markdown file that is rendered to a publishable paper with cross-references and a bibliography (and with raw a LATEX file produced as a by-product) in a simple process, making the whole analysis workflow reproducible 0.2 Which tool/language is best? • TMVA, scikit-learn, h2o, caret, mlr, WEKA, Shogun, . • C++, Python, R, Java, MATLAB/Octave, Julia, . • Many languages, environments and tools • People may have strong opinions • A false polychotomy? • Be a polyglot! 0.3 Approaches • Save-and-load • Language-specific bindings • Notebook • knitr 1 Save-and-load approach 1.1 Flat files • Language agnostic • Formats like text, CSV, and JSON are well-supported • Breaks workflow • Data types may not be preserved (e.g., datetime, NULL) • New binary format Feather solves this 1 1.2 Feather Feather: A fast on-disk format for data frames for R and Python, powered by Apache Arrow, developed by Wes McKinney and Hadley Wickham # In R: library(feather) path <- "my_data.feather" write_feather(df, path) # In Python: import feather -
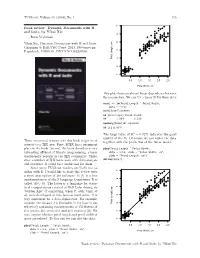
Dynamic Documents with R and Knitr, by Yihui Xie 116 Tugboat, Volume 35 (2014), No
TUGboat, Volume 35 (2014), No. 1 115 ● ● ● Book review: Dynamic Documents with R ● ● ● and knitr, by Yihui Xie ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Boris Veytsman ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Yihui Xie, Dynamic Documents with R and knitr. ● ● ● ● ● ● ● ● ● ● ● ● ● ● Chapman & Hall/CRC Press, 2013, 190+xxvi pp. ● ● ● ● ● ● ● ● ● US$ ISBN ● Paperback, 59.95. 978-1482203530. ● ● ● ● Petal Length, cm Petal ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 6 7 0.5 1.0 1.5 2.0 2.5 Petal Width, cm This plot shows an almost linear dependence between the parameters. We can try a linear fit for these data: model <- lm(Petal.Length ˜ Petal.Width, data = iris) model$coefficients ## (Intercept) Petal.Width ## 1.084 2.230 summary(model)$r.squared ## [1] 0.9271 The large value of R2 = 0.9271 indicates the good quality of the fit. Of course we can replot the data There are several reasons why this book might be of together with the prediction of the linear model: interest to a TEX user. First, LATEX has a prominent place in the book. Second, the book describes a very plot(Petal.Length ˜ Petal.Width, interesting offshoot of literate programming, a topic data = iris, xlab = "Petal Width, cm", traditionally popular in the TEX community. Third, ylab = "Petal Length, cm") abline(model) since a number of TEX users work with data analysis and statistics, R could be a useful tool for them. Since some TUGboat readers are likely not fa- ● ● ● miliar with R, I would like to start this review with ● ● a short description of the software. R [1] is a free ● ● ● ● ● ● ● ● ● ● ● implementation of the S language (sometimes R is ● ● ● ● ● ● ● ● ● ● ● ● ● ● called GNU S).