Signal Processing with High Complexity: Prototyping and Industrial Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MA240.LBI.001 Genesis LTE MIMO GPS-GLONASS 3In1 Combination Adhesive Mount Antenna
SPECIFICATION Part No. MA240.LBI.001 Product Name MA240 Genesis 2 x LTE/GNSS 3in1 Adhesive Mount Combination Antenna 1* GNSS – GPS-GLONASS-GALILEO 2* 4G LTE 698 to 896/1710 to 2700MHz Supports 3G Fall-back Features IP65 Antenna 1* GPS-GLONASS: 2 meter RG-174 SMA(M) 2 * LTE: 2 meter Low loss NFC-200 SMA(M)ST Dimensions: 205.8mm x 58mm x 12.4mm RoHS Compliant SPE-14-8-084/E/JW Page 1 of 45 1. Introduction The MA.240 4G Genesis antenna is an omni-directional, fully IP65 waterproof external M2M antenna for use in telematics, transportation and remote monitoring applications worldwide. It is designed to be mounted directly on glass or plastic in the interior of vehicles. Typical applications - HD Video over LTE - First Responder and Emergency Services - Automotive Vehicle Tracking and Telematics This unique antenna delivers powerful dual antenna technology for worldwide 4G LTE bands at 700MHz / 800MHz / 1700MHz / 1800MHz / 2600MHz, plus GPS/GLONASS/GALILEO for next generation location accuracy. 4G wireless applications demand high speed data uplink and downlink. High efficiency and high gain antennas are necessary to achieve the required signal to noise ratio and throughput required to solve these challenges. Taoglas also takes care to have high isolation between the two LTE antennas to prevent self-interference. Low loss cables are used to keep efficiency high over long cable lengths. In contrast, smaller LTE antennas with poorer quality thinner cables will have much reduced efficiency and isolation, which would lead to a large drop in system throughput or drops, and may indeed not make a system connection at all. -

Keysight Technologies PXI and Axie Products and Solutions Catalog
Keysight Technologies PXI and AXIe Products and Solutions Catalog September 2017 02 | PXI and AXIe Products and Solutions Catalog | September 2017 Table of Contents Featured Products 3 Unlocking Measurement M9383A PXIe Microwave Signal Realize pre-5G signal confidence with 1% Insights Generator, 1 MHz to 44 GHz EVM at 28 GHz, 800 MHz bandwidth in your 4-5 Article: More Test in Less Space: design validation test solution, with available Driving Down the Size of Test NEW upgrades of frequency and bandwidth to 6-8 PXI & AXIe Reference Solutions 44 GHz and 1 GHz, respectively. 9-11 PXI Chassis & Controllers 12-13 PXI Data Acquisition For more information, see page 20 14 PXI Digital Input Output 15 PXI Digital Multimeters M9421A PXIe VXT Vector Features exceptional EVM performance Transceiver 16 PXI Digitizers for dense modulation schemes required by 802.11ax design verification and manufac- 17 PXI Oscilloscopes turing test up to 8x8 MIMO. 18-21 PXI Signal Analyzers & Signal Generators For more information, see page 20 22-23 7 Tips for PXI and AXIe Test Solutions 24-25 PXI Switches 26-27 PXI Vector Network Analyzers M9341B/79A PXIe Modules for Purpose-built to improve the noise floor, dy- 28-29 PXI Waveform Generators Vector Network Analyzer namic range or test throughput for our PXIe 30-33 Additional PXI RF/µW & SMU VNA test solutions. Modules NEW 34-39 AXIe Modular Products For more information, see page 27 40-43 Software & Programming 44 Wireless Test Sets 45-46 Index M924xA PXIe Oscilloscopes up Troubleshoot random and intermittent sig- to 1 GHz Bandwidth nals with advanced probing technology and a 1,000,000 waveforms per second update NEW rate. -

W1918 LTE-Advanced Baseband Verification Library
Keysight EEsof EDA W1918 LTE-Advanced Baseband Verification Library Data Sheet Baseband PHY Libraries for SystemVue 02 | Keysight | W1918 LTE-Advanced Baseband Verification Library - Data Sheet Offering the Fastest Path from Algorithms to R&D Verification The W1918 LTE-Advanced Baseband Verification Library saves time, reduces engineering Key benefits: effort and accelerates the maturity of 4G baseband PHY designs for next-generation 3rd Generation Partnership Project (3GPP) Long Term Evolution LTE-Advanced systems. It – Accelerate your Physical Layer enables system architects, algorithm developers and baseband hardware designers to (PHY) design process with a investigate, implement and verify their Layer 1 signal processing designs in the presence superior modeling environment of meaningful RF and test signals. The library gives the user piece of mind that a physical – Save time with a trusted, layer (PHY) meets or exceeds real-world performance requirements from the European independent IP reference from Telecommunications Standards Institute (ETSI). Keysight – Validate BB & RF integration The W1918 LTE-A Baseband Verification Library is a Layer 1 simulation reference library early, reducing project risk option for Keysight SystemVue. The blockset, reference designs, and test benches assist – Reduce functional verification the design and verification of next-generation communication systems, by providing and NRE in R&D, with a configurable physical layer waveforms and data for 3GPP Releases 8/9 (LTE) and 10-13 streamlined process (LTE-Advanced). The library is useful for simulation-based exploration of challenging – Fill strategic gaps using algorithms, up to 8x8 MIMO throughput verification, and can be easily integrated with simulation, such as missing Keysight signal sources and analyzers. -

Performance Analysis of Wireless Dynamic Cooperative Relay Networks Using Fountain Codes
JOURNAL OF COMMUNICATIONS, VOL. 5, NO. 4, APRIL 2010 307 Performance Analysis of Wireless Dynamic Cooperative Relay Networks Using Fountain Codes Weijia Lei 1, Xianzhong Xie 2 and Guangjun Li 1 1 School of Comm. and Info. Engineering, University of Electronic Science and Technology of China, Chengdu, China 2 Institute of Personal Communications, Chongqing University of Posts and Telecommunications, Chongqing, China Email: [email protected], [email protected], [email protected] Abstract—The use of fountain codes in wireless cooperative fallen in and how others fill theirs. With the digital relay networks can improve the system performance in fountain code, the transmitter is just like a fountain, aspects such as transmission time, energy consumption, which encodes the original information to get potentially transmission efficiency and outage probability etc. This has infinite encoded symbols and sends them out; for the been proved when the number of the relay nodes and their receivers, only if they have received enough encoded relaying capabilities are stationary. But in practical networks the relay nodes are variable and dynamic. This symbols, they can reconstruct the original information. paper proposes a simple relay scheme adopting fountain An idealized digital fountain code should have two codes, and its performance in the case when the number of properties [6]: (1) infinite encoded data can be generated the relay nodes and their capabilities to relay data are from finite source data. (2) if the length of the source data randomly changing is analyzed. The performance of a is M, the receiver can reconstruct the source data from normal relay scheme in the same network condition is also any M encoded data, and the decoding process should be analyzed for comparison. -

Fundamentals of RF and Microwave Communications Engineering 2-Day Classroom Course
2019 Course Brochure Fundamentals of RF and Microwave Communications Engineering 2-Day Classroom Course COURSE OVERVIEW This popular 2-day classroom course provides a thorough introduction to the fundamentals of modern radio frequency (RF), wireless and microwave communications engineering. The course begins by discussing basic RF characteristics, including electromagnetic waves, free-space propagation and transmission lines. Key terms defined include RF power (dBm), characteristic impedance and S-parameters. Modulation is then described, first fundamental concepts followed by increasingly complex but important methods such as QAM, CDMA and OFDM. The course then addresses a range of key RF and microwave system building blocks (mixers, oscillators, filters and power amplifiers etc.) describing and discussing their individual properties and how they combine to form complete RF and microwave systems. The course concludes by defining a range of important test and measurement terms and methods used to characterise RF component and system performance. This includes a series of practical demonstrations using the latest RF and microwave test and measurement instruments. The course is delivered in partnership with leading test and measurement equipment manufacturer Rohde & Schwarz at their UK office in Fleet. Throughout the course, there will be plenty of opportunities to ask the instructor questions to help clarify understanding. WHAT YOU WILL LEARN Understand the basic characteristics of RF and microwaves Describe different types of transmission line and their characteristics Understand the fundamentals of RF propagation Understand modulation and different modulation methods Describe various components used in RF communications systems Explain the basic characteristics of RF and wireless transceiver systems Define common terms used to characterise RF and wireless systems Understand how to perform a range of basic RF and wireless measurements © The Technology Academy 2019. -

Extending the 3GPP Spatial Channel Model (SCM)
An Interim Channel Model for Beyond-3G Systems Extending the 3GPP Spatial Channel Model (SCM) Daniel S. Baum and Jan Hansen Jari Salo ETH Zürich, Zürich, Switzerland Helsinki University of Technology, Espoo, Finland {dsbaum,hansen}@nari.ee.ethz.ch [email protected] Giovanni Del Galdo and Marko Milojevic Pekka Kyösti Ilmenau University of Technology, Ilmenau, Germany Elektrobit Ltd., Oulu, Finland {giovanni.delgaldo,marko.milojevic}@tu-ilmenau.de [email protected] Abstract— This paper reports on the interim beyond-3G (B3G) While the WINNER project only started recently, there is channel model developed by and used within the European an immediate demand for models suitable for initial usage. WINNER project. The model is a comprehensive spatial channel This document presents the result of our studies in form of a model for 2 and 5 GHz frequency bands and supports band- model that is used for initial evaluation of B3G technologies in widths up to 100 MHz in three different outdoor environments. It outdoor scenarios within the WINNER project. further features time-evolution of system-level parameters for challenging advanced communication algorithms, as well as a Contributions. Our specific contributions are as follows: reduced-variability tapped delay-line model for improved usabili- • ty in calibration and comparison simulations. We analyze shortcomings of a selected spatial channel model standard with respect to the identified require- Keywords- channel model, beyond-3G, MIMO, SCM, 3GPP ments from other WINNER Work Packages. • We evaluated results found from literature search and I. INTRODUCTION derived from our own measurement data to devise In recent years Multiple-Input Multiple-Output (MIMO) missing parameters. -
Sony Ericsson Xperia X8 Black
X8 Rozšířená uživatelská příručka Obsah Uživatelská podpora....................................................................5 Uživatelská příručka v telefonu............................................................5 Aplikace uživatelské podpory..............................................................5 Zažijte více. Zjistěte jak........................................................................5 Začínáme......................................................................................6 Uvedení do provozu............................................................................6 Zapnutí a vypnutí telefonu...................................................................7 První zapnutí telefonu..........................................................................7 Seznámení s telefonem.............................................................10 Přehled telefonu................................................................................10 Nabíjení baterie.................................................................................11 Použití hardwarových tlačítek............................................................11 Domovská obrazovka........................................................................12 Stavový řádek...................................................................................12 Panel Upozornění..............................................................................14 Podokna aplikací...............................................................................15 -
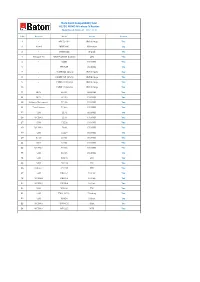
Data Card Compatibility List 4G/3G MIMO Wireless-N Router
Data Card Compatibility List 4G/3G MIMO Wireless-N Router Model No : iB-W4G311N . (Ver:. 2.0.0) Sr No Network Model Brand Remark 1 - 4G15L-16** iBall Airway Yes 2 Airtel MMX444L Micromax Yes 3 - DWM-222 D-Link Yes 4 Reliance 4G WD670 (Mi-FI Router) ZTE Yes 5 - E3531 HUAWEI Yes 6 - K4203Z HUAWEI Yes 7 - 21.0MP-58 (3.0.0) iBall Airway Yes 8 - 21.0MP-58 (2.0.0) iBall Airway Yes 9 - 7.2MP-18 (4.0.0) iBall Airway Yes 10 - 7.2MP-18 (2.0.0) iBall Airway Yes 11 MTS EC122 HUAWEI Yes 12 MTS EC156 HUAWEI Yes 13 Reliance Netconnect EC159 HUAWEI Yes 14 Tata Photon EC306 HUAWEI Yes 15 GSM E171 HUAWEI Yes 16 WCDMA E261 HUAWEI Yes 17 GSM E353s HUAWEI Yes 18 WCDMA E368 HUAWEI Yes 19 GSM E1550 HUAWEI Yes 20 Airtel E1731 HUAWEI Yes 21 IDEA E1732 HUAWEI Yes 22 WCDMA E1750 HUAWEI Yes 23 GSM E1756 HUAWEI Yes 24 GSM MF190 ZTE Yes 25 GSM MF112 ZTE Yes 26 Reliance AC2738 ZTE Yes 27 GSM PHS101 Prolink Yes 28 WCDMA PHS100 Prolink Yes 29 WCDMA PHS300 Prolink Yes 30 GSM WU260 TW Yes 31 GSM TWA-137A+ T-linking Yes 32 GSM MF636 Telstra Yes 33 WCDMA DWM156 Dlink Yes 34 WCDMA MT6225 MTK Yes Note: 1) For better performance suggested to use 3G enabled GSM / CDMA data Card with iBall Baton 3G Routers. 2G enable GSM / CDMA network data card will support on selected router but performace may vary from network to network and Service provider to service provider. -

Rapid Industrial Prototyping and Soc Design of 3G/4G Wireless Systems Using an HLS Methodology
Hindawi Publishing Corporation EURASIP Journal on Embedded Systems Volume 2006, Article ID 14952, Pages 1–25 DOI 10.1155/ES/2006/14952 Rapid Industrial Prototyping and SoC Design of 3G/4G Wireless Systems Using an HLS Methodology Yuanbin Guo,1 Dennis McCain,1 Joseph R. Cavallaro,2 and Andres Takach3 1 Nokia Networks Strategy and Technology, Irving, TX 75039, USA 2 Department of Electrical and Computer Engineering, Rice University, Houston, TX 77005, USA 3 Mentor Graphics, Portland, OR 97223, USA Received 4 November 2005; Revised 10 May 2006; Accepted 22 May 2006 Many very-high-complexity signal processing algorithms are required in future wireless systems, giving tremendous challenges to real-time implementations. In this paper, we present our industrial rapid prototyping experiences on 3G/4G wireless systems using advanced signal processing algorithms in MIMO-CDMA and MIMO-OFDM systems. Core system design issues are studied and advanced receiver algorithms suitable for implementation are proposed for synchronization, MIMO equalization, and detection. We then present VLSI-oriented complexity reduction schemes and demonstrate how to interact these high-complexity algorithms with an HLS-based methodology for extensive design space exploration. This is achieved by abstracting the main effort from hard- ware iterations to the algorithmic C/C++ fixed-point design. We also analyze the advantages and limitations of the methodology. Our industrial design experience demonstrates that it is possible to enable an extensive architectural analysis in a short-time frame using HLS methodology, which significantly shortens the time to market for wireless systems. Copyright © 2006 Yuanbin Guo et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. -

LTE ANTENNA Antenna)
SPECIFICATION Part No. : MA240.LBI.001 Product Name : MA240 Genesis 2 x LTE/GNSS 3in1 Adhesive Mount Combination Antenna 1* GNSS – GPS-GLONASS-GALILEO 2* 4G LTE 698 to 896/1710 to 2700MHz Supports 3G Fall-back Features : IP67 Antenna 1* GPS-GLONASS-GALILEO: 2 meter RG-174 SMA(M) 2 * LTE: 2 meter Low loss NFC-200 SMA(M)ST Dimensions: 205.8mm x 58mm x 12.4mm RoHS Compliant SPE-14-8-084/B/JW Page 1 of 43 1. Introduction The MA.240 4G Genesis antenna is an omni-directional, fully IP67 waterproof external M2M antenna for use in telematics, transportation and remote monitoring applications worldwide. It is designed to be mounted directly on glass or plastic in the interior of vehicles. Typical applications - HD Video over LTE - First Responder and Emergency Services - Automotive Vehicle Tracking and Telematics This unique antenna delivers powerful dual antenna technology for worldwide 4G LTE bands at 700MHz / 800MHz / 1700MHz / 1800MHz / 2600MHz, plus GPS/GLONASS/GALILEO for next generation location accuracy. 4G wireless applications demand high speed data uplink and downlink. High efficiency and high gain antennas are necessary to achieve the required signal to noise ratio and throughput required to solve these challenges. Taoglas also takes care to have high isolation between the two LTE antennas to prevent self-interference. Low loss cables are used to keep efficiency high over long cable lengths. In contrast, smaller LTE antennas with poorer quality thinner cables will have much reduced efficiency and isolation, which would lead to a large drop in system throughput or drops, and may indeed not make a system connection at all. -

Joint Pilot and Data Loading Technique for Mimo Systems Operating with Covariance Feedback
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Joint Pilot and Data Loading Technique for Mimo Systems Operating with Covariance Feedback Digham, F.; Mehta, N.; Molisch, A.; Zhang, J. TR2004-105 October 2004 Abstract We consider a multiple input multiple output (MIMO) system wherein channel correlation as well as noisy channel estimation are both taken into account. For a given block fading duration, pilot-assisted channel estimation is carried out with the aid of a minimum mean square error estimator. The pilot sequences and data are jointly optimized to maximize the ergodic capacity while fulfilling a total transmit energy constraint. Using the optimization results, we study the effect of various system parameters and different types of channel knowledge. We show that systems with channel covariance knowledge and imperfect channel estimates can even outper- form those with perfect channel estimation at the receiver, but without any channel knowledge at the transmitter. Further, we show that the signal to noise ratio and the block fading duration determine the qualitative behavior of ergodic capacity as a function of antenna spacing or angular spread. Finally, we find that the optimum pilot-to-data power ratio is always greater than one. It increases as the total transmit power decreases or as the block fading length increases. 3G 2004 This work may not be copied or reproduced in whole or in part for any commercial purpose. Permission to copy in whole or in part without payment of fee is granted for nonprofit educational and research purposes provided that all such whole or partial copies include the following: a notice that such copying is by permission of Mitsubishi Electric Research Laboratories, Inc.; an acknowledgment of the authors and individual contributions to the work; and all applicable portions of the copyright notice. -

US 2012/0071157 A1 MARKOULDAKS (43) Pub
US 2012007 1157A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2012/0071157 A1 MARKOULDAKS (43) Pub. Date: Mar. 22, 2012 (54) METHOD FORMOBILE NETWORK (52) U.S. Cl. ...................................... 455/423:455/422.1 COVERAGE EXPERIENCE ANALYSIS AND MONITORING (57) ABSTRACT (76) Inventor: Yannis MARKOULIDAKIS. Nea In a telecommunications network including a plurality of Smyrni (GR) s mobile terminals, a system and method of providing an indi y cation of network coverage in relation to at least one of the plurality of mobile terminals, the method and system being (21) Appl. No.: 13/101479 configured to: determine the occurrence of incoming call events in relation to the at least one terminal; record the (22) Filed: May 5, 2011 occurrences together with an identity of at least one appli O O cable terminal, a location and/or a time associated with the (30) Foreign Application Priority Data communication event; and analyse the recorded incoming May 5, 2010 (GB) 1OO7507.5 call event data, particularly unreachable terminal events, to determine an indication of experienced network coverage for each of the at least one terminal. In this way, an indication of Publication Classification actual user experience can be determined, which is usable in (51) Int. Cl. indicatively treating customer complaints, making network H04/24/00 (2009.01) improvements and analysing mobile terminal performance. &ixi: 388xx:k::::::: Patent Application Publication Mar. 22, 2012 Sheet 1 of 4 US 2012/0071157 A1 FIGURE Patent Application Publication Mar. 22, 2012 Sheet 2 of 4 US 2012/0071157 A1 (RE 888 & 38 3xx88 ::::::::::::::::::::: 8:38& Patent Application Publication Mar.