Measuring Spatial Allocative Efficiency in Basketball
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Auf Der Falschen Fahrte
NBA-TOPTHEMA WARUM DER KLASSISCHE POINT GUARD VOM AUSSTERBEN BEDROHT IST ANALYSE AUF DER FALSCHEN.. FAHRTE TEXT TIMO BÖCKENHÜSER Was haben Russell Westbrook, Derrick Rose, John Wall und Eric Bledsoe gemeinsam? Sie sind alle Top-Playmaker. Sie sind alle maximal 25 Jahre alt. Und sie verbindet alle ein Schicksal: Ihre Körper kapitulieren schon jetzt vor ihrer brachialen Athletik. Denn die neue Point-Guard- Generation spielt ein sehr riskantes Spiel! s ist nur ein kleines Rechteck. Gerade mal 5,80 Meter lang und 4,90 Meter breit und doch ein Bereich, der im Basketball immense Bedeutung hat. Denn jene meist bunt gefärbten 28,42 Quadratmeter markieren an beiden Enden des Courts die Zone. Von jeher ist „The Paint“, wie der Amerikaner sie nennt, das Reich der Großen, der Büffel unter den Basket- E ballern. Länge beschützt den Korb, daran ist nicht zu rütteln. Deshalb beherrschen Big Men die Zone, kleine Spieler haben vor allem im Set-Play dort wenig zu lachen. Die langen Leute lauern darauf, dass Guards es wagen, in ihr Reich einzudringen und zum Korb zu ziehen. Dann prallen Welten aufeinander. Bulldozer auf Smarts. Büffel auf Gazellen. Dwight Howards auf Eric Bledsoes. Ein starker Drive zum Ring heißt dorthin gehen, wo es wehtut. Trainer lieben diese aggressiven, tollkühnen Akte, denn sie bedeuten, dass ihre Backcourt-Player nicht nur auf Distanzwürfe setzen, die weniger Erfolgsaussichten haben als Layups. Und das hat zusammen mit den Regeländerungen wie Defensive-Three-Seconds und Handchecking, die für mehr Freiräume in der Zone und dadurch auch für mehr Penetrationen über die Mitte gesorgt haben, zu einem gefährlichen Umdenken im Basketball geführt. -

Probable Starters
UTAH JAZZ (35-30) at MEMPHIS GRIZZLIES (18-46) Game #66 • ROAD Game #34 • FedExForum • MEMPHIS March 9, 2018 • 6 p.m. (MT) • TV: AT&T SportsNet RADIO: 1280 AM/97.5 FM DATE OPP. TIME (MT) RECORD/TV 10/18 DEN W, 106-96 1-0 10/20 @MIN L, 97-100 1-1 LAST GAME’S STARTERS (2017-18 averages) 10/21 OKC W, 96-87 2-1 10/24 @LAC L, 84-102 2-2 • Notched first career double-double (11 points, 10/25 @PHX L, 88-97 2-3 career-high 10 assists) at IND on 3/7 10/28 LAL W, 96-81 3-3 PPG • 10.9 10/30 DAL W, 104-89 4-3 2 • Second in the league in three-point 11/1 POR W, 112-103 (OT) 5-3 RPG • 4.1 percentage (.445) 11/3 TOR L, 100-109 5-4 JOE INGLES • Has eight games this season with 5+ 3FG 11/5 @HOU L, 110-137 5-5 11/7 PHI L, 97-104 5-6 F • 6-8 • 226 • Australia APG • 4.3 • Appeared in his 200th straight game on 2/24 11/10 MIA L, 74-84 5-7 vs. DAL 11/11 BKN W, 114-106 6-7 11/13 MIN L, 98-109 6-8 • Has made a three-pointer in consecutive 11/15 @NYK L, 101-106 6-9 PPG • 12.2 games for just the second time in his career 11/17 @BKN L, 107-118 6-10 15 11/18 @ORL W, 125-85 7-10 RPG • 7.4 • Ranks seventh in Jazz history in blocked shots 11/20 @PHI L, 86-107 7-11 DERRICK FAVORS (641) 11/22 CHI W, 110-80 8-11 Jazz are 11-3 when he records a double- 11/25 MIL W, 121-108 9-11 • APG • 1.3 11/28 DEN W, 106-77 10-11 F • 6-10 • 265 • Georgia Tech double 11/30 @LAC W, 126-107 11-11 st 12/1 NOP W, 114-108 12-11 • Posted his 21 double-double of the season 12/4 WAS W, 116-69 13-11 27 PPG • 13.6 (23 points and 14 rebounds) at IND (3/7) 12/5 @OKC L, 94-100 13-12 • Made a career-high 12 free throws and scored 12/7 HOU L, 101-112 13-13 RPG • 10.5 12/9 @MIL L, 100-117 13-14 RUDY GOBERT a season-high 26 points vs. -

The Maturation of Russell Westbrook
The Maturation of Russell Westbrook Khris Matthews-Marion Contributing Writer, Sports Radio America “I think Russell’s demeanor and his aggression is what the DNA of a team should be. He’s aggressive and he’s unapologetic about the way he plays. “I believe Russell has the same mentality that I have had, which is that criticism doesn’t matter.” -- Kobe Bryant on Russell Westbrook’s development. Oklahoma City – When he was drafted fourth overall by the Seattle Supersonics in the 2008 NBA draft, analysts struggled to come up with a player comparison for him. Marc Jackson compared him to Gary Payton and because of his rebounding ability; the media tabbed Rajon Rondo as the best example of what he could turn into. Still, others thought he was built in the Steve Francis mold. However, it may be the Black Mamba, in terms of intensity and eye- popping athletic ability, who may be the closest and best equivalent when looking at the future of Russell Westbrook. Kobe Bryant is arguably the greatest player the NBA has seen in the last thirty years not named Michael Jordan. He has been the heartbeat of LA's most historic team for almost two decades and has hoisted the Larry O'Brien trophy five separate times. His comments during ESPN Grantland's Basketball Hour were revealing about the level of respect he has for a man who is walking down a similar path. His experience, success, basketball acumen and specifically his relationship with Shaquille O'Neal made him a perfect candidate to judge the maturation of man who is escaping the shadow of an established star. -

Difference-Based Analysis of the Impact of Observed Game Parameters on the Final Score at the FIBA Eurobasket Women 2019
Original Article Difference-based analysis of the impact of observed game parameters on the final score at the FIBA Eurobasket Women 2019 SLOBODAN SIMOVIĆ1 , JASMIN KOMIĆ2, BOJAN GUZINA1, ZORAN PAJIĆ3, TAMARA KARALIĆ1, GORAN PAŠIĆ1 1Faculty of Physical Education and Sport, University of Banja Luka, Bosnia and Herzegovina 2Faculty of Economy, University of Banja Luka, Bosnia and Herzegovina 3Faculty of Physical Education and Sport, University of Belgrade, Serbia ABSTRACT Evaluation in women's basketball is keeping up with developments in evaluation in men’s basketball, and although the number of studies in women's basketball has seen a positive trend in the past decade, it is still at a low level. This paper observed 38 games and sixteen variables of standard efficiency during the FIBA EuroBasket Women 2019. Two regression models were obtained, a set of relative percentage and relative rating variables, which are used in the NBA league, where the dependent variable was the number of points scored. The obtained results show that in the first model, the difference between winning and losing teams was made by three variables: true shooting percentage, turnover percentage of inefficiency and efficiency percentage of defensive rebounds, which explain 97.3%, while for the second model, the distinguishing variables was offensive efficiency, explaining for 96.1% of the observed phenomenon. There is a continuity of the obtained results with the previous championship, played in 2017. Of all the technical elements of basketball, it is still the shots made, assists and defensive rebounds that have the most significant impact on the final score in European women’s basketball. -

Hawks' Trio Headlines Reserves for 2015 Nba All
HAWKS’ TRIO HEADLINES RESERVES FOR 2015 NBA ALL-STAR GAME -- Duncan Earns 15 th Selection, Tied for Third Most in All-Star History -- NEW YORK, Jan. 29, 2015 – Three members of the Eastern Conference-leading Atlanta Hawks -- Al Horford , Paul Millsap and Jeff Teague -- headline the list of 14 players selected by the coaches as reserves for the 2015 NBA All-Star Game, the NBA announced today. Klay Thompson of the Golden State Warriors earned his first All-Star selection, joining teammate and starter Stephen Curry to give the Western Conference-leading Warriors two All-Stars for the first time since Chris Mullin and Tim Hardaway in 1993. The 64 th NBA All-Star Game will tip off Sunday, Feb. 15, at Madison Square Garden in New York City. The game will be seen by fans in 215 countries and territories and will be heard in 47 languages. TNT will televise the All-Star Game for the 13th consecutive year, marking Turner Sports' 30 th year of NBA All- Star coverage. The Hawks’ trio is joined in the East by Dwyane Wade and Chris Bosh of the Miami Heat, the Chicago Bulls’ Jimmy Butler and the Cleveland Cavaliers’ Kyrie Irving . This is the 11 th consecutive All-Star selection for Wade and the 10 th straight nod for Bosh, who becomes only the third player in NBA history to earn five trips to the All-Star Game with two different teams (Kareem Abdul-Jabbar, Kevin Garnett). Butler, who leads the NBA in minutes (39.5 per game) and has raised his scoring average from 13.1 points in 2013-14 to 20.1 points this season, makes his first All-Star appearance. -

Evaluating Lineups and Complementary Play Styles in the NBA
Evaluating Lineups and Complementary Play Styles in the NBA The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:38811515 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Contents 1 Introduction 1 2 Data 13 3 Methods 20 3.1 Model Setup ................................. 21 3.2 Building Player Proles Representative of Play Style . 24 3.3 Finding Latent Features via Dimensionality Reduction . 30 3.4 Predicting Point Diferential Based on Lineup Composition . 32 3.5 Model Selection ............................... 34 4 Results 36 4.1 Exploring the Data: Cluster Analysis .................... 36 4.2 Cross-Validation Results .......................... 42 4.3 Comparison to Baseline Model ....................... 44 4.4 Player Ratings ................................ 46 4.5 Lineup Ratings ............................... 51 4.6 Matchups Between Starting Lineups .................... 54 5 Conclusion 58 Appendix A Code 62 References 65 iv Acknowledgments As I complete this thesis, I cannot imagine having completed it without the guidance of my thesis advisor, Kevin Rader; I am very lucky to have had a thesis advisor who is as interested and knowledgable in the eld of sports analytics as he is. Additionally, I sincerely thank my family, friends, and roommates, whose love and support throughout my thesis- writing experience have kept me going. v Analytics don’t work at all. It’s just some crap that people who were really smart made up to try to get in the game because they had no talent. -

Lebron, Stephen and the Essence of Florida Non-Competes Published May 18, 2017
LeBron, Stephen and the Essence of Florida Non-Competes Published May 18, 2017 As this blog post goes to press, the Cleveland Cavaliers and the Boston Celtics just began their series to determine which team will face the winner of the series between the Golden State Warriors and the San Antonio Spurs. To the surprise of very few, the Stephen Curry-led Warriors are leading the Spurs in the series and are widely expected to return to the NBA Finals. The LeBron James-led Cavaliers are expected to defeat the Celtics. (New Englanders widely disagree with this prediction, although the first-game blowout suggests the Cavaliers are playing with a champion’s confidence.) A Cavaliers series victory could set up a rematch of the pre-season division favorites. You may wonder how basketball rivalries and the NBA playoffs relate to non-competition agreements Florida. It’s simple. Both Cleveland and Golden State loaded their teams with talent to out-perform the competition. Cleveland added LeBron James and Kevin Love to join Kyrie Irving. Together, the three of them form a consistent and formidable foundation for the Cavaliers’ success. Golden State pulled off perhaps an equally impressive coup. With the possibility of an immediate championship, Golden State lured Kevin Durant away from adoring fans (and away from NBA All-Star Russell Westbrook) in Oklahoma City. Under the NBA rules, once a player is eligible for trade, there is very little that a team can do to stop that player from leaving to join a team that he prefers. Usually higher salaries incentivize players to move. -

PJ Savoy Complete
PJ SAVOY 6-4/210 GUARD LAS VEGAS, NEVADA CHAPARRAL HIGH SCHOOL (CHANCELLOR DAVIS) LAS VEGAS HIGH SCHOOL (JASON WILSON) SHERIDAN COLLEGE (MATT HAMMER) FLORIDA STATE UNIVERSITY (LEONARD HAMILTON) PJ Savoy’s Career Statistics Year G-GS FG-A PCT. 3FG-3FGA PCT. FT-FTA PCT. PTS.-AVG. OR DR TR-AVG. PF-D AST TO BLK STL MIN 2016-17 28-0 47-114 .412 40-100 .400 21-30 .700 155-5.5 4 19 23-0.8 15-0 7 9 1 10 228-8.1 2017-18 27-4 58-158 .367 50-135 .370 16-22 .727 182-6.7 5 33 38-1.4 28-0 15 17 1 6 355-13.1 2018-19 37-18 68-187 .364 52-158 .329 32-39 .821 220-5.9 7 37 44-1.2 44-0 18 30 4 17 542-14.6 Totals 92-22 173-459 .381 142-393 .366 69-91 .749 557-6.03 16 89 105-1.1 87-0 40 56 6 33 1125-25.2 PJ Savoy’s Conference Statistics Year G-GS FG-A PCT. 3FG-3FGA PCT. FT-FTA PCT. PTS.-AVG. OR DR TR-AVG. PF-D AST TO BLK STL MIN 2016-17 17-0 27-63 .429 21-54 .389 10-15 .667 85-5.0 4 15 19-1.1 6-0 2 5 1 6 279-15.5 2017-18 11-1 20-56 .357 18-51 .353 8-11 .727 66-6.0 2 7 9-0.8 11-0 7 7 0 1 147-13.4 2018-19 18-5 30-85 .353 24-74 .324 13-15 .867 97-5.4 3 14 17-0.9 21-0 5 11 1 9 218-12.1 Totals 46-6 77-204 .378 63-179 .352 31-41 .756 248-5.4 9 36 45-1 38-0 14 23 2 16 644-14.0 PJ Savoy’s NCAA Tournament Statistics Year G-GS FG-A PCT. -

Probable Starting Lineups This Game by the Numbers
Louisville Basketball Quick Facts Location Louisville, Ky. 40292 Founded / Enrollment 1798 / 22,000 Nickname/Colors Cardinals / Red and Black Sports Information University of Louisville Louisville, KY 40292 www.UofLSports.com Conference BIG EAST Phone: (502) 852-6581 Fax: (502) 852-7401 email: [email protected] Home Court KFC Yum! Center (22,000) President Dr. James Ramsey Louisville Cardinals vs. Notre Dame Fighting Irish Vice President for Athletics Tom Jurich Head Coach Rick Pitino (UMass '74) U of L Record 238-91 (10th yr.) PROBABLE STARTING LINEUPS Overall Record 590-215 (25th yr.) Louisville (18-5, 7-3) Ht. Wt. Yr. PPG RPG Hometown Asst. Coaches Steve Masiello,Tim Fuller, Mark Lieberman F 5 Chris SMITH 6-2 200 Jr. 9.8 4.5 Millstone, N.J. Dir. of Basketball Operations Ralph Willard F 44 Stephan VAN TREESE 6-9 220 So. 3.5 3.9 Indianapolis, Ind. All-Time Record 1,625-849 (97 yrs.) C 23 Terrence JENNINGS 6-9 220 Jr. 9.3 5.4 Sacramento, Calif. All-Time NCAA Tournament Record 60-38 G 2 Preston KNOWLES 6-1 190 Sr. 14.9 3.7 Winchester, Ky. (36 Appearances, Eight Final Fours, G 3 Peyton SIVA 5-11 180 So. 10.7 2.9 Seattle, Wash. Two NCAA Championships - 1980, 1986) Important Phone Numbers Notre Dame (19-4, 8-3) Ht. Wt. Yr. PPG RPG Hometown Athletic Office (502) 852-5732 F 1 Tyrone NASH 6-8 232 Sr. 9.7 5.8 Queens, N.Y. Basketball Office (502) 852-6651 F 21 Tim ABROMAITIS 6-8 235 Sr. -
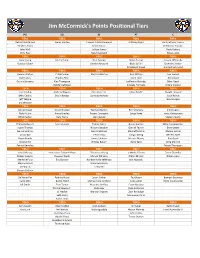
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -
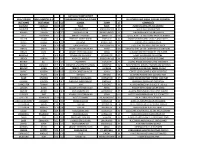
July 10-11 Camp Report (A-B-C Order) Bold Denotes D-1
JULY 10-11 CAMP REPORT (A-B-C ORDER) BOLD DENOTES D-1 UNDERLINED/ITALICS=D-2/NAIA ALL OTHERS HAVE SMALL COLLEGE POTENTIAL LAST NAME FIRST NAME HT CL SCHOOL TOWN ST COMMENTS ASHFORD MARCUS 5'10 12 PARIS PARIS KY POINT CREATES OFF THE DRIBBLE BALDWIN TYLER 6'1 10 GRACE BAPTIST MADISONVILLE KY SOLID ROLE PLAYER TYPE BARNES JOSHUA 5'10 11 SIMON KENTON INDEPENDENCE KY LEAD MAN HANDLES AND PASSES BELL CAMAYAN 5'5 8 MARIETTA MIDDLE MARIETTA GA QUICK, ATHLETIC AND LONG BACKCOURTMAN BILITER EVAN 5'8 7 PINEVILLE INDEPENDENT PINEVILLE KY HARD WORKER WHO SHOOTS AND PASSES BOLES ISAIAH 6'5 12 CAVERNA HORSE CAVE KY STRONG POST BANGS INSIDE BOX LIAM 5'10 10 GRACE BAPTIST MADISONVILLE KY EXCELS AT DISTRIBUTING THE ROCK BRADS JAMES 5'9 12 LEGACY CHRISTIAN ACAD XENIA OH POSSESSES ALL OF THE INGREDIENTS FOR POINT BRADS CLINT LEGACY CHRISTIAN ACAD XENIA OH A LEADER ON BOTH ENDS OF THE FLOOR BRANNEN CJ 6'2 11 COVINGTON CATHOLIC COVINGTON KY LANKY SWINGMAN CAN SCORE BROCK ABRAM 5'7 8 KNOX CO. MIDDLE BARBOURVILLE KY CRAFTY POINT GUARD GOT GAME BROWN ELI 5'7 9 TILGHMAN PADUCAH KY A LONG RANGE SHOOTER WHO STROKES IT BROWN DOMINIC 5'7 9 MEMPHIS UNIVERSITY SCHOOL MEMPHIS TN POINT SHOOTS, DRIVES, FINISHES AND DEFENDS BRYANT VANN 6'7 12 TRINITY CHRISTIAN JACKSON TN MOBILE 3-4 CAN PLAY INSIDE OR OUT BURKE ASHTON 5'10 12 LEGACY CHRISTIAN ACAD XENIA OH CRAFTY LEAD GUARD IS VERY VERSATILE BURNEY KYLAN 6'0 12 ANTIOCH ANTIOCH TN SLASHING PENETRATOR DEFENDS TOO BUSH LINCOLN 6'5 10 FREDERICK DOUGLASS LEXINGTON KY GOOD INSIDE/OUTSIDE THREAT CAN PLAY CALLEBS HAYDEN 5'9 8 PINEVILLE INDEPENDENT PINEVILLE KY POSSESSES EXCELLENT POTENTIAL CARPENTER TOMMY 5'9 8 IHM FLORENCE KY A HARD WORKER WHO GIVES IT HIS ALL CARSON BLAKE LEGACY CHRISTIAN ACAD XENIA OH PASSER WITH GOOD COURT SENSE CARVER ASHER 6'0 9 MUHLENBERG CO. -
Page 5 Dec. 9
www.theaustinvillager.com THE VILLAGER Page 5 ~December 9, 2011 SPORTS Huston-Tillotson split VILLAGER SPOTLIGHT games with Paul Quinn Thompson looking to make an impact in the NBA By: Terry Davis had a scoring average of 13 The National Basket- points per game. “We’re very ball Association and their excited for Tristan and his player union finally reached family,” Texas coach Rick a handshake agreement in Barnes said. “I’m not sure principal on a new Collective we’ve seen a player improve Bargaining Agreement. As a so quickly once he came to result, some future player’s campus last June. I often tell people jokingly that Tristan By: Terry Davis dreams will be coming true. That is the case the for improved too much, as our former Texas Longhorn staff would have loved the @terryd515 standout Tristan Thompson. opportunity to coach Tristan Thompson was selected with for several more years. The Lady Rams the four overall pick in this exciting thing is Tristan is The Huston-Tillotson year’s NBA Draft by the truly just getting started in his Lady Rams took on the Paul Cleveland Cavaliers. Al- development. Tristan is a Quinn College Tigers of Dal- though only playing one sea- wonderful person and Cleve- las, Texas at their gym this son with Texas, Thompson land is getting a special indi- week. The Lady Tigers only was the third highest Long- vidual who will work hard has five members on their bas- horn ever drafted by the every day, both on the court ketball team, despite this fact NBA.