Video Transcoding Using Machine Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reviewer's Guide
Episode® 6.5 Affordable transcoding for individuals and workgroups Multiformat encoding software with uncompromising quality, speed and control. The Episode Product Guide is designed to provide an overview of the features and functions of Telestream’s Episode products. This guide also provides product information, helpful encoding scenarios and other relevant information to assist in the product review process. Please review this document along with the associated Episode User Guide, which provides complete product details. Telestream provides this guide for informational purposes only; it is not a product specification. The information in this document is subject to change at any time. 1 CONTENTS EPISODE OVERVIEW ........................................................................................................... 3 Episode ($495 USD) ........................................................................................................... 3 Episode Pro ($995 USD) .................................................................................................... 3 Episode Engine ($4995 USD) ............................................................................................ 3 KEY BENEFITS ..................................................................................................................... 4 FEATURES ............................................................................................................................ 5 Highest quality ................................................................................................................... -

Datasheet Media Server
Flussonic Media Server A multi-format and multi-protocol transcoder, packager, and origin server with a consistent, high density channel count independent of input or output encoding formats and protocols. FEATURES SRT, RTMP, RTSP, HLS, Low Latency Efficient video archive that can store HLS, HDS, HTTP MPEG-TS, years of uninterrupted video MPEG-DASH, and WebRTC recordings. streaming protocols. Live Video archives and VOD content High-performance graphics core. can be stored on local disk drives, CEPH, NFS, or in S3/Swift clouds. H.264, H.265, AV1, MPEG-2 Video, AAC, MP3, VP6, Speex, and G711 a/u Instant access to live video feed codecs for ingress and egress. and to archived recordings. Flussonic can form a cluster with Advanced monitoring system that unlimited number of ingest, origin, controls system load and performance. and streaming servers. Support for all major DRM systems Smart routing of video streams and Cloud Multi-DRM providers. between servers in cluster. Full support for DVB-Subtitles Multiple redundancy options based and Closed Captions. on Flussonic Cluster mechanism, including N+1, N+M, Source Stream User-friendly Web-UI. Failover, and many others. Rich and well-defined API for 3000+ simultaneous connections per programmatically controlling single Edge server. and managing all functions of the Media Server. TECHNICAL SPECIFICATIONS Protocols and formats support MPEG TS Ingest SPTS, MPTS, Data PID Passthrough MPEG TS Monitoring TR101290 MPEG TS electronic EPG EIT program guide MPEG TS advertising SCTE35 MPEG TS constant PCR -
Download the Inspector Product Sheet (Pdf)
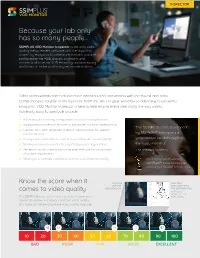
INSPECTOR Because your lab only has so many people... SSIMPLUS VOD Monitor Inspector is the only video quality measurement software with the algorithm trusted by Hollywood to determine the best possible configuration for R&D groups, engineers and architects who set up VOD encoding and processing workflows or make purchasing recommendations. Video professionals can evaluate more encoders and transcoders with the fastest and most comprehensive solution in the business. From the start of your workflow to delivering to consumer endpoints, VOD Monitor Inspector is here to help ensure every step along the way works flawlessly. Easy-to-use tools provide: A/B testing for encoding configurations and purchasing decisions Sandbox environment for encoder or transcoder output troubleshooting “The SSIMPLUS score developed Creation of custom templates to identify best practices for specific content libraries by SSIMWAVE represents a Configurable automation to save time and eliminate manual QA/QC generational breakthrough in Side-by-side visual inspector to subjectively assess degradations the video industry.” Perceptual quality maps that provide pixel level graphic visualization –The Television Academy of content impairments Allows you to optimize network performance and improve quality Our Emmy Award-winning SSIMPLUS™ score mimics the accuracy of 100,000 human eyes. Know the score when it YOU CAN HOW OUR SEE THE SOFTWARE SEES DEGRADATION THE DEGRADATION comes to video quality NARROW IT DOWN TO THE The SSIMPLUS score is the most accurate measurement PIXEL LEVEL representing how end-viewers perceive video quality. Our score can tell exactly where video quality degrades. 18 34 59 72 87 10 20 30 40 50 60 70 80 90 100 BAD POOR FAIR GOOD EXCELLENT Helping your workflow, work SSIMPLUS VOD Monitor Inspector helps ensure your video infrastructure is not negatively impacting content anywhere in your workflow. -

FLV File Format
Video File Format Specification Version 10 Copyright © 2008 Adobe Systems Incorporated. All rights reserved. This manual may not be copied, photocopied, reproduced, translated, or converted to any electronic or machine-readable form in whole or in part without written approval from Adobe Systems Incorporated. Notwithstanding the foregoing, a person obtaining an electronic version of this manual from Adobe may print out one copy of this manual provided that no part of this manual may be printed out, reproduced, distributed, resold, or transmitted for any other purposes, including, without limitation, commercial purposes, such as selling copies of this documentation or providing paid-for support services. Trademarks Adobe, ActionScript, Flash, Flash Media Server, XMP, and Flash Player are either registered trademarks or trademarks of Adobe Systems Incorporated and may be registered in the United States or in other jurisdictions including internationally. Other product names, logos, designs, titles, words, or phrases mentioned within this publication may be trademarks, service marks, or trade names of Adobe Systems Incorporated or other entities and may be registered in certain jurisdictions including internationally. No right or license is granted to any Adobe trademark. Third-Party Information This guide contains links to third-party websites that are not under the control of Adobe Systems Incorporated, and Adobe Systems Incorporated is not responsible for the content on any linked site. If you access a third-party website mentioned in this guide, then you do so at your own risk. Adobe Systems Incorporated provides these links only as a convenience, and the inclusion of the link does not imply that Adobe Systems Incorporated endorses or accepts any responsibility for the content on those third- party sites. -

20130218 Technical White Paper.Bw.Jp
Sending, Storing & Sharing Video With latakoo © Copyright latakoo. All rights reserved. Revised 11/12/2012 Table of contents Table of contents ................................................................................................... 1 1. Introduction ...................................................................................................... 2 2. Sending video & files with latakoo ...................................................................... 3 2.1 The latakoo app ............................................................................................ 3 2.2 Compression & upload ................................................................................. 3 2.3 latakoo minutes ............................................................................................ 4 3. The latakoo web interface .................................................................................. 4 3.1 Web interface requirements .......................................................................... 4 3.2 Logging into the dashboard .......................................................................... 4 3.3 Streaming video previews ............................................................................. 4 3.4 Downloading video ...................................................................................... 5 3.5 latakoo Pilot ................................................................................................. 5 3.6 Search and tagging ...................................................................................... -

The Essentials of Video Transcoding Enabling Acquisition, Interoperability, and Distribution in Digital Media
Telestream Whitepaper The Essentials of Video Transcoding Enabling Acquisition, Interoperability, and Distribution in Digital Media The intent of this paper is to Contents provide an overview of the Introduction Page 1 transcoding basics you’ll need to Digital media formats Page 2 know in order to make informed The essence of compression Page 3 decisions about implementing The right tool for the job Page 4 transcoding in your workflow. That Bridging the gaps Page 5 involves explaining the elements of (media exchange between diverse systems) the various types of digital media Transcoding workflows Page 6 files used for different purposes, Conclusion Page 7 how transcoding works upon those elements, what challenges might arise in moving from one Introduction format to another, and what It’s been more than three decades now since digital media emerged from the workflows might be most effective lab into real-world applications, igniting a communications revolution that for transcoding in various common continues to play out today. First up was the Compact Disc, featuring situations. compression-free LPCM digital audio that was designed to fully reconstruct the source at playback. With digital video, on the other hand, it was clear from the outset that most recording, storage, and playback situations wouldn’t have the data capacity required to describe a series of images with complete accuracy. And so the race was on to develop compression/decompression algorithms (codecs) that could adequately capture a video source while requiring as little data bandwidth as possible. 1 Telestream Whitepaper The good news is that astonishing progress has been Transcoding bypasses this tedious, inefficient scenario. -

Conversion of MP3 to AAC in the Compressed Domain
Conversion of MP3 to AAC in the Compressed Domain Koichi Takagi Satoshi Miyaji Shigeyuki Sakazawa Yasuhiro Takishima KDDI R&D Labs. Inc. Fujimino-shi, Saitama 356-8502 Japan Abstract— In this paper, we propose an efficient algorithm transcoding, even in transcoding for bit rate conversion where the for conversion of an MP3 stream into AAC. Generally, this kind encoding method is not changed. of conversion, transcoding, requires full decoding and re- Therefore, in this paper, we propose a novel algorithm for encoding. However, the re-encoding based transcoding process conversion of MP3 to AAC in the compressed data domain with may result in degradation of quality and take longer than the least quality degradation. We analyzed the encoding parameters encoding from a PCM signal. This paper proposes a method to of MP3 and AAC, which consists of side information, scale factors, inherit the frame structure and quantization scale from MP3 to and MDCT coefficients, and then tried to figure out the differences AAC. This enables a reduction in the iteration process, which and similarities. Consequently, we realized faster conversion of requires the most time in the AAC encoding process, without MP3 to AAC compared with the simple transcoding technique. incurring degradation in quality. Experimental results show that the proposed method can perform bitstream domain transcoding This paper is organized as follows. Section II provides an at high speed while maintaining a high level of audio quality. overview of the related techniques and outlines the proposed method. In Section III, performance of the proposed algorithm is Keywords—MP3; AAC; Transcoding; Audio conversion; Scale compared with the existing transcoding technique. -

Video Compression Optimized for Racing Drones
Video compression optimized for racing drones Henrik Theolin Computer Science and Engineering, master's level 2018 Luleå University of Technology Department of Computer Science, Electrical and Space Engineering Video compression optimized for racing drones November 10, 2018 Preface To my wife and son always! Without you I'd never try to become smarter. Thanks to my supervisor Staffan Johansson at Neava for providing room, tools and the guidance needed to perform this thesis. To my examiner Rickard Nilsson for helping me focus on the task and reminding me of the time-limit to complete the report. i of ii Video compression optimized for racing drones November 10, 2018 Abstract This thesis is a report on the findings of different video coding tech- niques and their suitability for a low powered lightweight system mounted on a racing drone. Low latency, high consistency and a robust video stream is of the utmost importance. The literature consists of multiple comparisons and reports on the efficiency for the most commonly used video compression algorithms. These reports and findings are mainly not used on a low latency system but are testing in a laboratory environment with settings unusable for a real-time system. The literature that deals with low latency video streaming and network instability shows that only a limited set of each compression algorithms are available to ensure low complexity and no added delay to the coding process. The findings re- sulted in that AVC/H.264 was the most suited compression algorithm and more precise the x264 implementation was the most optimized to be able to perform well on the low powered system. -

(Flash Video Format). Uestions.Php
page 84 Digitized video in formats, such as Quicktime, MPEG, AVI or DV and its http://www.flvplayer.com/q own FLV (Flash Video format). uestions.php Linking your video file as an Embedding your video file into external file to the flash file the flash file flash flash Streaming video You cannot use the original one. You need to compress it. Video Different compression method: Size (for example 320 by 240 pixels) Audio: Video You need to bring a video clip into the library. 0) Create a folder “videoLJW” under the “assign- ment” folder. 1)Copy “lmh.mov” from the class homepage to “videoLJW” folder. (Hold down the “Option” key and click the link to the file. 2) Open a flash file. (File/New) 3) Save it as “videoLJW.fla” under the assignment folder. 4) Rename “Layer 1” “video” 5) Select “File/Import/Import Video”. Select Video Flash looks for the location of your video file. If your video file is on your computer. click “Choose” to locate the file. If it is already on a commercial Flash Video Streaming Service or Macromedia Flash Communication Server, you need to select the second option and provide the file’s URL. Select the “lmh.mov” under the folder of “videoLJW”. Click “Open”. You will see the location of (File path to) “lmh.mov”. Click “Continue”. Deployment -- How would you tap into the lvideo file. Select “Progressive download from a web server”. First opton: Progressive download displays video when enough information to play is downloaded rather than the entire video is downloaded.Viewers have to play sdquentially. -

JPEG 2000 for Video Archiving
The Pros and Cons of JPEG 2000 for Video Archiving Katty Van Mele November, 2010 Overview • Introduction – Current situation – Multiple challenges • Archiving challenges for cinema and video content • JPEG 2000 for Video Archiving • intoPIX Solutions • Conclusions INTOPIX PRIVATE & CONFIDENTIAL © 2010 JPEG 2000 SOLUTIONS 2 Current Situation • Most museums, film archiving and broadcast organizations – digitizing available content considered or initiated • Both movie content (reels) and analog video content (tapes) – Digitization process and constraints are very different. – More than 10.000.000 Hours Film (analog = film) • 30 to 40 % will disappear in the next 10 years ( Vinager syndrom) • Digitization process is complex – More than 6.000.000H ? Video ( 90% analog = tape) • x% will disappear because of the magnetic tape (binder) • Natural digitization process taking place due to the technology evolution. • Technical constraints are easier. INTOPIX PRIVATE & CONFIDENTIAL © 2010 JPEG 2000 SOLUTIONS 3 Multiple challenges • The goal of the digitization process : – Ensure the long term preservation of the content – Ensure the sharing and commercialization of the content. • Based on these different viewpoints and needs – Different technical challenges and choices – Different workflows utilized – Different commercial constraints – Different cultural and legal issues INTOPIX PRIVATE & CONFIDENTIAL © 2010 J PEG 2000 SOLUTIONS 4 Overview • Introduction • Archiving challenges for cinema and video content – General archiving concerns – Benefits of -

Input Formats & Codecs
Input Formats & Codecs Pivotshare offers upload support to over 99.9% of codecs and container formats. Please note that video container formats are independent codec support. Input Video Container Formats (Independent of codec) 3GP/3GP2 ASF (Windows Media) AVI DNxHD (SMPTE VC-3) DV video Flash Video Matroska MOV (Quicktime) MP4 MPEG-2 TS, MPEG-2 PS, MPEG-1 Ogg PCM VOB (Video Object) WebM Many more... Unsupported Video Codecs Apple Intermediate ProRes 4444 (ProRes 422 Supported) HDV 720p60 Go2Meeting3 (G2M3) Go2Meeting4 (G2M4) ER AAC LD (Error Resiliant, Low-Delay variant of AAC) REDCODE Supported Video Codecs 3ivx 4X Movie Alaris VideoGramPiX Alparysoft lossless codec American Laser Games MM Video AMV Video Apple QuickDraw ASUS V1 ASUS V2 ATI VCR-2 ATI VCR1 Auravision AURA Auravision Aura 2 Autodesk Animator Flic video Autodesk RLE Avid Meridien Uncompressed AVImszh AVIzlib AVS (Audio Video Standard) video Beam Software VB Bethesda VID video Bink video Blackmagic 10-bit Broadway MPEG Capture Codec Brooktree 411 codec Brute Force & Ignorance CamStudio Camtasia Screen Codec Canopus HQ Codec Canopus Lossless Codec CD Graphics video Chinese AVS video (AVS1-P2, JiZhun profile) Cinepak Cirrus Logic AccuPak Creative Labs Video Blaster Webcam Creative YUV (CYUV) Delphine Software International CIN video Deluxe Paint Animation DivX ;-) (MPEG-4) DNxHD (VC3) DV (Digital Video) Feeble Files/ScummVM DXA FFmpeg video codec #1 Flash Screen Video Flash Video (FLV) / Sorenson Spark / Sorenson H.263 Forward Uncompressed Video Codec fox motion video FRAPS: -

Team Officials, Game Leaders/Referee and Parents
• To provide a pilot initiative that evaluates the effectiveness of a Game Leader and Referee at the U9 Age Group. 2 • Festivals with U9 Age Groups will be tracked and evaluated. • Festivals will either use a Referee or a Game Leaders • Game Leader can either be 3rd party or can be the two Coaches involved in the game. 3 • Develop survey to be distributed by host organizations • U9 Festival games will be received and reviewed by Ontario Soccer staff • Games will be evaluated by Ontario Soccer for measuring of: • “ball rolling time,” • quantity and the quality of the stoppages and their impact on flow of the game 4 • Organizations are to identify festivals for the pilot project • Festival host will record all U9 Games • Games must be recorded in one of the following format: • MP4 (H.26x, MPEG-2, MPEG-4) • 3GP (H.26x, MPEG-4) • AVI (Divx, XviD etc) • WMV • MOV/QT (MPEG-2, MPEG-4) • MKV • WEBM (H.26x, MPEG-2, MPEG-4, DivX, XviD, VP6) • FLV (VP6, H.264, MPEG-4). • Video can zoom in on any stoppages the Referee or Game Leader makes (must include sound) • Send all video files to Ontario Soccer for review • Distribute survey link to the Team Officials, Game Leaders/Referee and parents 5 • Ontario Soccer will evaluate all videos provided via an online platform • Host will survey the team officials, Game Leaders/ Referees and parents post game by providing them with online survey. • Results will be submitted directly to Ontario Soccer 6 • Team Officials, Game Leader/ Referees and parents will complete an online survey immediately after the game.