Rapid Phenotype-Driven Gene Prioritization for Rare Diseases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplemental Table S1
Entrez Gene Symbol Gene Name Affymetrix EST Glomchip SAGE Stanford Literature HPA confirmed Gene ID Profiling profiling Profiling Profiling array profiling confirmed 1 2 A2M alpha-2-macroglobulin 0 0 0 1 0 2 10347 ABCA7 ATP-binding cassette, sub-family A (ABC1), member 7 1 0 0 0 0 3 10350 ABCA9 ATP-binding cassette, sub-family A (ABC1), member 9 1 0 0 0 0 4 10057 ABCC5 ATP-binding cassette, sub-family C (CFTR/MRP), member 5 1 0 0 0 0 5 10060 ABCC9 ATP-binding cassette, sub-family C (CFTR/MRP), member 9 1 0 0 0 0 6 79575 ABHD8 abhydrolase domain containing 8 1 0 0 0 0 7 51225 ABI3 ABI gene family, member 3 1 0 1 0 0 8 29 ABR active BCR-related gene 1 0 0 0 0 9 25841 ABTB2 ankyrin repeat and BTB (POZ) domain containing 2 1 0 1 0 0 10 30 ACAA1 acetyl-Coenzyme A acyltransferase 1 (peroxisomal 3-oxoacyl-Coenzyme A thiol 0 1 0 0 0 11 43 ACHE acetylcholinesterase (Yt blood group) 1 0 0 0 0 12 58 ACTA1 actin, alpha 1, skeletal muscle 0 1 0 0 0 13 60 ACTB actin, beta 01000 1 14 71 ACTG1 actin, gamma 1 0 1 0 0 0 15 81 ACTN4 actinin, alpha 4 0 0 1 1 1 10700177 16 10096 ACTR3 ARP3 actin-related protein 3 homolog (yeast) 0 1 0 0 0 17 94 ACVRL1 activin A receptor type II-like 1 1 0 1 0 0 18 8038 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 1 0 0 0 0 19 8751 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 1 0 0 0 0 20 8728 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 1 0 0 0 0 21 81792 ADAMTS12 ADAM metallopeptidase with thrombospondin type 1 motif, 12 1 0 0 0 0 22 9507 ADAMTS4 ADAM metallopeptidase with thrombospondin type 1 -

ANKRD11 Gene Ankyrin Repeat Domain 11
ANKRD11 gene ankyrin repeat domain 11 Normal Function The ANKRD11 gene provides instructions for making a protein called ankyrin repeat domain 11 (ANKRD11). As its name suggests, this protein contains multiple regions called ankyrin domains; proteins with these domains help other proteins interact with each other. The ANKRD11 protein interacts with certain proteins called histone deacetylases, which are important for controlling gene activity. Through these interactions, ANKRD11 affects when genes are turned on and off. For example, ANKRD11 brings together histone deacetylases and other proteins called p160 coactivators. This association regulates the ability of p160 coactivators to turn on gene activity. ANKRD11 may also enhance the activity of a protein called p53, which controls the growth and division (proliferation) and the self-destruction (apoptosis) of cells. The ANKRD11 protein is found in nerve cells (neurons) in the brain. During embryonic development, ANKRD11 helps regulate the proliferation of these cells and development of the brain. Researchers speculate that the protein may also be involved in the ability of neurons to change and adapt over time (plasticity), which is important for learning and memory. ANKRD11 may function in other cells in the body and appears to be involved in normal bone development. Health Conditions Related to Genetic Changes KBG syndrome Several ANKRD11 gene mutations have been found to cause KBG syndrome, a condition characterized by large upper front teeth and other unusual facial features, skeletal abnormalities, and intellectual disability. Most of these mutations lead to an abnormally short ANKRD11 protein, which likely has little or no function. Reduction of this protein's function is thought to underlie the signs and symptoms of the condition. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
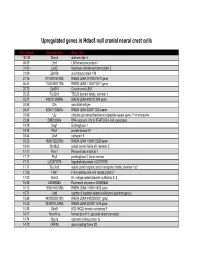
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -

Supplemental Information
Supplemental information Dissection of the genomic structure of the miR-183/96/182 gene. Previously, we showed that the miR-183/96/182 cluster is an intergenic miRNA cluster, located in a ~60-kb interval between the genes encoding nuclear respiratory factor-1 (Nrf1) and ubiquitin-conjugating enzyme E2H (Ube2h) on mouse chr6qA3.3 (1). To start to uncover the genomic structure of the miR- 183/96/182 gene, we first studied genomic features around miR-183/96/182 in the UCSC genome browser (http://genome.UCSC.edu/), and identified two CpG islands 3.4-6.5 kb 5’ of pre-miR-183, the most 5’ miRNA of the cluster (Fig. 1A; Fig. S1 and Seq. S1). A cDNA clone, AK044220, located at 3.2-4.6 kb 5’ to pre-miR-183, encompasses the second CpG island (Fig. 1A; Fig. S1). We hypothesized that this cDNA clone was derived from 5’ exon(s) of the primary transcript of the miR-183/96/182 gene, as CpG islands are often associated with promoters (2). Supporting this hypothesis, multiple expressed sequences detected by gene-trap clones, including clone D016D06 (3, 4), were co-localized with the cDNA clone AK044220 (Fig. 1A; Fig. S1). Clone D016D06, deposited by the German GeneTrap Consortium (GGTC) (http://tikus.gsf.de) (3, 4), was derived from insertion of a retroviral construct, rFlpROSAβgeo in 129S2 ES cells (Fig. 1A and C). The rFlpROSAβgeo construct carries a promoterless reporter gene, the β−geo cassette - an in-frame fusion of the β-galactosidase and neomycin resistance (Neor) gene (5), with a splicing acceptor (SA) immediately upstream, and a polyA signal downstream of the β−geo cassette (Fig. -

De Novo Frameshift Mutation in ASXL3 in a Patient with Global Developmental Delay, Microcephaly, and Craniofacial Anomalies
Children's Mercy Kansas City SHARE @ Children's Mercy Manuscripts, Articles, Book Chapters and Other Papers 9-17-2013 De novo frameshift mutation in ASXL3 in a patient with global developmental delay, microcephaly, and craniofacial anomalies. Darrell L. Dinwiddie Sarah E. Soden Children's Mercy Hospital Carol J. Saunders Children's Mercy Hospital Neil A. Miller Children's Mercy Hospital Emily G. Farrow Children's Mercy Hospital See next page for additional authors Follow this and additional works at: https://scholarlyexchange.childrensmercy.org/papers Part of the Medical Genetics Commons Recommended Citation Dinwiddie, D. L., Soden, S. E., Saunders, C. J., Miller, N. A., Farrow, E. G., Smith, L. D., Kingsmore, S. F. De novo frameshift mutation in ASXL3 in a patient with global developmental delay, microcephaly, and craniofacial anomalies. BMC Med Genomics 6, 32-32 (2013). This Article is brought to you for free and open access by SHARE @ Children's Mercy. It has been accepted for inclusion in Manuscripts, Articles, Book Chapters and Other Papers by an authorized administrator of SHARE @ Children's Mercy. For more information, please contact [email protected]. Creator(s) Darrell L. Dinwiddie, Sarah E. Soden, Carol J. Saunders, Neil A. Miller, Emily G. Farrow, Laurie D. Smith, and Stephen F. Kingsmore This article is available at SHARE @ Children's Mercy: https://scholarlyexchange.childrensmercy.org/papers/1414 Dinwiddie et al. BMC Medical Genomics 2013, 6:32 http://www.biomedcentral.com/1755-8794/6/32 CASE REPORT Open Access De novo frameshift -

Gfh 2016 Tagungsband Final.Pdf
27. Jahrestagung der Deutschen Gesellschaft für Humangenetik 27. Jahrestagung der Deutschen Gesellschaft für Humangenetik gemeinsam mit der Österreichischen Gesellschaft für Humangenetik und der Schweizerischen Gesellschaft für Medizinische Genetik 16.–18. 3. 2016, Lübeck Tagungsort Prof. Dr. med. Jörg Epplen, Bochum (Tagungspräsident 2017) Prof. Dr. med. Michael Speicher, Graz (Tagungspräsident 2015) Hotel Hanseatischer Hof Prof. Dr. med. Klaus Zerres, Aachen Wisbystraße 7–9 Prof. Dr. rer. nat. Wolfgang Berger, Zürich (Delegierter der SGMG) 23558 Lübeck Univ.-Prof. DDr. med. univ. Johannes Zschocke, Telefon: (0451) 3 00 20-0 (Innsbruck Delegierter der ÖGH) http://www.hanseatischer- hof.de/ [email protected] Fachgesellschaften Die Jahrestagung fi ndet im Hotel Hanseatischer Hof statt, das sich Deutsche Gesellschaft für Humangenetik (GfH) in in fussläufi ger Entfernung vom Lübecker Hauptbahnhof befi ndet. Vorsitzender: Prof. Dr. med. Klaus Zerres, Aachen Stellvertretende Vorsitzende: Prof. Dr. med. Gabriele Gillessen- Tagungspräsidentin Kaesbach, Lübeck Stellvertretende Vorsitzende: Prof. Dr. biol. hum. Hildegard Prof. Dr. med. Gabriele Gillessen- Kaesbach Kehrer- Sawatzki, Ulm Institut für Humangenetik Schatzmeister: Dr. rer. nat. Wolfram Kress, Würzburg Universität zu Lübeck/UKSH Schrift führerin: Dr. rer. nat. Simone Heidemann, Kiel Ratzeburger Allee 160, Haus 72 23538 Lübeck Österreichische Gesellschaft für Humangenetik (ÖGH) Telefon: 0049-451-500-2620 Univ. Prof. Dr. med. univ. Michael Speicher, Graz (Vorsitzender) Fax: 0049-451-500-4187 Univ. Doz. Dr. med. univ. Hans-Christoph Duba, Linz (Stellvertre- tende Vorsitzende) Tagungsorganisation Univ.-Prof. DDr. med. univ. Johannes Zschocke, Innsbruck (Stellvertretende Vorsitzende) Dr. Christine Scholz (Leitung) Dr. Gerald Webersinke, Linz (Schrift führer) Brigitte Fiedler (Teilnehmerregistrierung) Ass.-Prof. Priv. Doz. Dr. med. univ. Franco Laccone, Wien (Stellver- Deutsche Gesellschaft für Humangenetik e. -

CPTC-CDK1-1 (CAB079974) Immunohistochemistry
CPTC-CDK1-1 (CAB079974) Uniprot ID: P06493 Protein name: CDK1_HUMAN Full name: Cyclin-dependent kinase 1 Tissue specificity: Isoform 2 is found in breast cancer tissues. Function: Plays a key role in the control of the eukaryotic cell cycle by modulating the centrosome cycle as well as mitotic onset; promotes G2-M transition, and regulates G1 progress and G1-S transition via association with multiple interphase cyclins. Required in higher cells for entry into S-phase and mitosis. Phosphorylates PARVA/actopaxin, APC, AMPH, APC, BARD1, Bcl-xL/BCL2L1, BRCA2, CALD1, CASP8, CDC7, CDC20, CDC25A, CDC25C, CC2D1A, CENPA, CSNK2 proteins/CKII, FZR1/CDH1, CDK7, CEBPB, CHAMP1, DMD/dystrophin, EEF1 proteins/EF-1, EZH2, KIF11/EG5, EGFR, FANCG, FOS, GFAP, GOLGA2/GM130, GRASP1, UBE2A/hHR6A, HIST1H1 proteins/histone H1, HMGA1, HIVEP3/KRC, LMNA, LMNB, LMNC, LBR, LATS1, MAP1B, MAP4, MARCKS, MCM2, MCM4, MKLP1, MYB, NEFH, NFIC, NPC/nuclear pore complex, PITPNM1/NIR2, NPM1, NCL, NUCKS1, NPM1/numatrin, ORC1, PRKAR2A, EEF1E1/p18, EIF3F/p47, p53/TP53, NONO/p54NRB, PAPOLA, PLEC/plectin, RB1, TPPP, UL40/R2, RAB4A, RAP1GAP, RCC1, RPS6KB1/S6K1, KHDRBS1/SAM68, ESPL1, SKI, BIRC5/survivin, STIP1, TEX14, beta-tubulins, MAPT/TAU, NEDD1, VIM/vimentin, TK1, FOXO1, RUNX1/AML1, SAMHD1, SIRT2 and RUNX2. CDK1/CDC2-cyclin-B controls pronuclear union in interphase fertilized eggs. Essential for early stages of embryonic development. During G2 and early mitosis, CDC25A/B/C-mediated dephosphorylation activates CDK1/cyclin complexes which phosphorylate several substrates that trigger at least centrosome separation, Golgi dynamics, nuclear envelope breakdown and chromosome condensation. Once chromosomes are condensed and aligned at the metaphase plate, CDK1 activity is switched off by WEE1- and PKMYT1-mediated phosphorylation to allow sister chromatid separation, chromosome decondensation, reformation of the nuclear envelope and cytokinesis. -

Neurologic Outcomes in Friedreich Ataxia: Study of a Single-Site Cohort E415
Volume 6, Number 3, June 2020 Neurology.org/NG A peer-reviewed clinical and translational neurology open access journal ARTICLE Neurologic outcomes in Friedreich ataxia: Study of a single-site cohort e415 ARTICLE Prevalence of RFC1-mediated spinocerebellar ataxia in a North American ataxia cohort e440 ARTICLE Mutations in the m-AAA proteases AFG3L2 and SPG7 are causing isolated dominant optic atrophy e428 ARTICLE Cerebral autosomal dominant arteriopathy with subcortical infarcts and leukoencephalopathy revisited: Genotype-phenotype correlations of all published cases e434 Academy Officers Neurology® is a registered trademark of the American Academy of Neurology (registration valid in the United States). James C. Stevens, MD, FAAN, President Neurology® Genetics (eISSN 2376-7839) is an open access journal published Orly Avitzur, MD, MBA, FAAN, President Elect online for the American Academy of Neurology, 201 Chicago Avenue, Ann H. Tilton, MD, FAAN, Vice President Minneapolis, MN 55415, by Wolters Kluwer Health, Inc. at 14700 Citicorp Drive, Bldg. 3, Hagerstown, MD 21742. Business offices are located at Two Carlayne E. Jackson, MD, FAAN, Secretary Commerce Square, 2001 Market Street, Philadelphia, PA 19103. Production offices are located at 351 West Camden Street, Baltimore, MD 21201-2436. Janis M. Miyasaki, MD, MEd, FRCPC, FAAN, Treasurer © 2020 American Academy of Neurology. Ralph L. Sacco, MD, MS, FAAN, Past President Neurology® Genetics is an official journal of the American Academy of Neurology. Journal website: Neurology.org/ng, AAN website: AAN.com CEO, American Academy of Neurology Copyright and Permission Information: Please go to the journal website (www.neurology.org/ng) and click the Permissions tab for the relevant Mary E. -

Hereditary Spastic Paraplegias
Hereditary Spastic Paraplegias Authors: Doctors Enza Maria Valente1 and Marco Seri2 Creation date: January 2003 Update: April 2004 Scientific Editor: Doctor Franco Taroni 1Neurogenetics Istituto CSS Mendel, Viale Regina Margherita 261, 00198 Roma, Italy. e.valente@css- mendel.it 2Dipartimento di Medicina Interna, Cardioangiologia ed Epatologia, Università degli studi di Bologna, Laboratorio di Genetica Medica, Policlinico S.Orsola-Malpighi, Via Massarenti 9, 40138 Bologna, Italy.mailto:[email protected] Abstract Keywords Disease name and synonyms Definition Classification Differential diagnosis Prevalence Clinical description Management including treatment Diagnostic methods Etiology Genetic counseling Antenatal diagnosis References Abstract Hereditary spastic paraplegias (HSP) comprise a genetically and clinically heterogeneous group of neurodegenerative disorders characterized by progressive spasticity and hyperreflexia of the lower limbs. Clinically, HSPs can be divided into two main groups: pure and complex forms. Pure HSPs are characterized by slowly progressive lower extremity spasticity and weakness, often associated with hypertonic urinary disturbances, mild reduction of lower extremity vibration sense, and, occasionally, of joint position sensation. Complex HSP forms are characterized by the presence of additional neurological or non-neurological features. Pure HSP is estimated to affect 9.6 individuals in 100.000. HSP may be inherited as an autosomal dominant, autosomal recessive or X-linked recessive trait, and multiple recessive and dominant forms exist. The majority of reported families (70-80%) displays autosomal dominant inheritance, while the remaining cases follow a recessive mode of transmission. To date, 24 different loci responsible for pure and complex HSP have been mapped. Despite the large and increasing number of HSP loci mapped, only 9 autosomal and 2 X-linked genes have been so far identified, and a clear genetic basis for most forms of HSP remains to be elucidated.