Hubs in Languages' Scale Free Networks of Synonyms 1. Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -
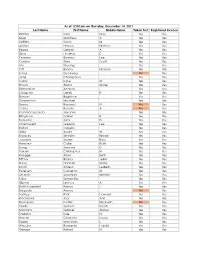
Last Name First Name Middle Name Taken Test Registered License
As of 12:00 am on Thursday, December 14, 2017 Last Name First Name Middle Name Taken Test Registered License Richter Sara May Yes Yes Silver Matthew A Yes Yes Griffiths Stacy M Yes Yes Archer Haylee Nichole Yes Yes Begay Delores A Yes Yes Gray Heather E Yes Yes Pearson Brianna Lee Yes Yes Conlon Tyler Scott Yes Yes Ma Shuang Yes Yes Ott Briana Nichole Yes Yes Liang Guopeng No Yes Jung Chang Gyo Yes Yes Carns Katie M Yes Yes Brooks Alana Marie Yes Yes Richardson Andrew Yes Yes Livingston Derek B Yes Yes Benson Brightstar Yes Yes Gowanlock Michael Yes Yes Denny Racheal N No Yes Crane Beverly A No Yes Paramo Saucedo Jovanny Yes Yes Bringham Darren R Yes Yes Torresdal Jack D Yes Yes Chenoweth Gregory Lee Yes Yes Bolton Isabella Yes Yes Miller Austin W Yes Yes Enriquez Jennifer Benise Yes Yes Jeplawy Joann Rose Yes Yes Harward Callie Ruth Yes Yes Saing Jasmine D Yes Yes Valasin Christopher N Yes Yes Roegge Alissa Beth Yes Yes Tiffany Briana Jekel Yes Yes Davis Hannah Marie Yes Yes Smith Amelia LesBeth Yes Yes Petersen Cameron M Yes Yes Chaplin Jeremiah Whittier Yes Yes Sabo Samantha Yes Yes Gipson Lindsey A Yes Yes Bath-Rosenfeld Robyn J Yes Yes Delgado Alonso No Yes Lackey Rick Howard Yes Yes Brockbank Taci Ann Yes Yes Thompson Kaitlyn Elizabeth No Yes Clarke Joshua Isaiah Yes Yes Montano Gabriel Alonzo Yes Yes England Kyle N Yes Yes Wiman Charlotte Louise Yes Yes Segay Marcinda L Yes Yes Wheeler Benjamin Harold Yes Yes George Robert N Yes Yes Wong Ann Jade Yes Yes Soder Adrienne B Yes Yes Bailey Lydia Noel Yes Yes Linner Tyler Dane Yes Yes -
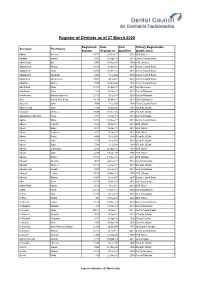
Register of Dentists As of 27 March 2020
Register of Dentists as of 27 March 2020 Registered Date Year Primary Registerable Surname First Name Number Registered Qualified Qualification Abbas Meriem 19317 28-Sep-17 2015 BDS NUIrel Abdalla Eyman 3915 02-Apr-15 2014 Dental Council Exam Abdel-Gadir Sali 5407 14-May-07 2004 BDS UWales Abdelhamid Ahmed 14516 21-Oct-16 2016 Dental Council Exam Abdelrahim Rawa 16916 01-Dec-16 2016 Dental Council Exam Abdelsalam Elsamani 6304 19-Jul-04 2004 Dental Council Exam Abdulrahim Mohammed 10807 09-Jul-07 2007 Dental Council Exam Abraham Shirley 5296 20-Sep-96 2002 Dental Council Exam Abu Farha Rami 18418 04-Oct-18 2017 Dentist Greece Abu Rabia Omar 616 18-Jan-16 2013 Dentist Romania Acornicesei Mihaela-Gabriela 12119 25-Jul-19 2008 Dentist Romania Adel Seyed Amir Reza 19118 19-Oct-18 2018 DMD UBudapest Adeyemi John 7004 23-Jul-04 2004 Dental Council Exam Adye-Curran John 7195 16-Oct-95 1981 BDentSc UDubl Afrasiabi Ali-Reza 15606 18-Dec-06 2006 BDentSc UDubl Aghasizadeh Sherbaf Reza 7317 01-Jun-17 2014 Dentist Hungary Agkhre Shkre 18318 18-Sep-17 2018 Dental Council Exam Agnew Hannah 13416 07-Oct-16 2015 BDS UDund Ahern Aidan 8018 19-Jun-18 2018 BDS NUIrel Ahern Catherine 4112 26-Jun-12 2012 BDS NUIrel Ahern David 4498 03-Jul-98 1998 BDentSc UDubl Ahern John 7310 14-Jul-10 2010 BDentSc UDubl Ahern John 5798 13-Jul-98 1998 BDentSc UDubl Aherne Christopher 2878 22-May-78 1974 BDS NUIrel Aherne John 4100 09-Jun-00 1996 BDS NUIrel Aherne Stuart 15101 17-Dec-01 2001 BDS UWales Ahmad Mustafa 2017 24-Feb-17 2014 Dentist Romania Ahmad Tanzeel 12317 23-Jun-17 -

Given Name Alternatives for Irish Research
Given Name Alternatives for Irish Research Name Abreviations Nicknames Synonyms Irish Latin Abigail Abig Ab, Abbie, Abby, Aby, Bina, Debbie, Gail, Abina, Deborah, Gobinet, Dora Abaigeal, Abaigh, Abigeal, Gobnata Gubbie, Gubby, Libby, Nabby, Webbie Gobnait Abraham Ab, Abm, Abr, Abe, Abby, Bram Abram Abraham Abrahame Abra, Abrm Adam Ad, Ade, Edie Adhamh Adamus Agnes Agn Aggie, Aggy, Ann, Annot, Assie, Inez, Nancy, Annais, Anneyce, Annis, Annys, Aigneis, Mor, Oonagh, Agna, Agneta, Agnetis, Agnus, Una Nanny, Nessa, Nessie, Senga, Taggett, Taggy Nancy, Una, Unity, Uny, Winifred Una Aidan Aedan, Edan, Mogue, Moses Aodh, Aodhan, Mogue Aedannus, Edanus, Maodhog Ailbhe Elli, Elly Ailbhe Aileen Allie, Eily, Ellie, Helen, Lena, Nel, Nellie, Nelly Eileen, Ellen, Eveleen, Evelyn Eibhilin, Eibhlin Helena Albert Alb, Albt A, Ab, Al, Albie, Albin, Alby, Alvy, Bert, Bertie, Bird,Elvis Ailbe, Ailbhe, Beirichtir Ailbertus, Alberti, Albertus Burt, Elbert Alberta Abertina, Albertine, Allie, Aubrey, Bert, Roberta Alberta Berta, Bertha, Bertie Alexander Aler, Alexr, Al, Ala, Alec, Ales, Alex, Alick, Allister, Andi, Alaster, Alistair, Sander Alasdair, Alastar, Alsander, Alexander Alr, Alx, Alxr Ec, Eleck, Ellick, Lex, Sandy, Xandra, Zander Alusdar, Alusdrann, Saunder Alfred Alf, Alfd Al, Alf, Alfie, Fred, Freddie, Freddy Albert, Alured, Alvery, Avery Ailfrid Alberedus, Alfredus, Aluredus Alice Alc Ailse, Aisley, Alcy, Alica, Alley, Allie, Allison, Alicia, Alyssa, Eileen, Ellen Ailis, Ailise, Aislinn, Alis, Alechea, Alecia, Alesia, Aleysia, Alicia, Alitia Ally, -

PMA Polonica Catalog
PMA Polonica Catalog PLACE OF AUTHOR TITLE PUBLISHER DATE DESCRIPTION CALL NR PUBLICATION Concerns the Soviet-Polish War of Eighteenth Decisive Battle Abernon, De London Hodder & Stoughton, Ltd. 1931 1920, also called the Miracle on the PE.PB-ab of the World-Warsaw 1920 Vistula. Illus., index, maps. Ackermann, And We Are Civilized New York Covici Friede Publ. 1936 Poland in World War I. PE.PB-ac Wolfgang Form letter to Polish-Americans asking for their help in book on Appeal: "To Polish Adamic, Louis New Jersey 1939 immigration author is planning to PE.PP-ad Americans" write. (Filed with PP-ad-1, another work by this author). Questionnaire regarding book Plymouth Rock and Ellis author is planning to write. (Filed Adamic, Louis New Jersey 1939 PE.PP-ad-1 Island with PE.PP-ad, another work by this author). A factual report affecting the lives Adamowski, and security of every citizen of the It Did Happen Here. Chicago unknown 1942 PA.A-ad Benjamin S. U.S. of America. United States in World War II New York Biography of Jan Kostanecki, PE.PC-kost- Adams , Dorothy We Stood Alone Longmans, Green & Co. 1944 Toronto diplomat and economist. ad Addinsell, Piano solo. Arranged from the Warsaw Concerto New York Chappell & Co. Inc. 1942 PE.PG-ad Richard original score by Henry Geehl. Great moments of Kosciuszko's life Ajdukiewicz, Kosciuszko--Hero of Two New York Cosmopolitan Art Company 1945 immortalized in 8 famous paintings PE.PG-aj Zygumunt Worlds by the celebrated Polish artist. Z roznymi ludzmi o roznych polsko- Ciekawe Gawedy Macieja amerykanskich sprawach. -

PLATT FAMILY RECORDS CENTER NOTES Volume 3.1 Compiled by Lyman D
PLATT FAMILY RECORDS CENTER NOTES Volume 3.1 compiled by Lyman D. Platt, Ph.D. Platt Family Records Center The Redwoods, New Harmony, Utah 2008 2 The Platt Family Records Center Copyright © 2008 The Lyman D. Platt Family Protection Trust All Rights Reserved Manufactured in the U.S.A. 3 INTRODUCTION Over many years the collections that comprise the Platt Family Records Center (PFRC) have been gathered from a diversity of sources and locations. These have been cataloged as they have been received, or in the order that they were initially organized. It was not felt in preparing this final version that a re-cataloging was necessary due to the versatility of the indexing systems used. There are twelve divisions to the PFRC: 1) Documents; 2) Letters; 3) Notes; 4) Family Histories; 5) Journals & Diaries; 6) Manuscripts; 7) Photographs; 8) Maps; 9) Books; 10) Genealogies; 11) Bibliography; and 12) Indexes. The collection that follows - Notes - is divided into several volumes, 3.1, 3.2, 3.3, etc. These notes do not contain all of the material that I have collected, but they are a compilation of much of it. Some information went directly into histories, family group records, pedigree charts and short biographies. Copies of these volumes have been given to: 1) Special Collections, Marriott Library, Brigham Young University, Provo, Utah; 2) The Church Historical Library, Salt Lake City, Utah; 3) Special Collections, Southern Utah University, Cedar City, Utah; and 4) The Daughters of the Utah Pioneers Museum, Salt Lake City, Utah. Additional copies have been given to each of my siblings and to some of our children. -

2017 Purge List LAST NAME FIRST NAME MIDDLE NAME SUFFIX
2017 Purge List LAST NAME FIRST NAME MIDDLE NAME SUFFIX AARON LINDA R AARON-BRASS LORENE K AARSETH CHEYENNE M ABALOS KEN JOHN ABBOTT JOELLE N ABBOTT JUNE P ABEITA RONALD L ABERCROMBIA LORETTA G ABERLE AMANDA KAY ABERNETHY MICHAEL ROBERT ABEYTA APRIL L ABEYTA ISAAC J ABEYTA JONATHAN D ABEYTA LITA M ABLEMAN MYRA K ABOULNASR ABDELRAHMAN MH ABRAHAM YOSEF WESLEY ABRIL MARIA S ABUSAED AMBER L ACEVEDO MARIA D ACEVEDO NICOLE YNES ACEVEDO-RODRIGUEZ RAMON ACEVES GUILLERMO M ACEVES LUIS CARLOS ACEVES MONICA ACHEN JAY B ACHILLES CYNTHIA ANN ACKER CAMILLE ACKER PATRICIA A ACOSTA ALFREDO ACOSTA AMANDA D ACOSTA CLAUDIA I ACOSTA CONCEPCION 2/23/2017 1 of 271 2017 Purge List ACOSTA CYNTHIA E ACOSTA GREG AARON ACOSTA JOSE J ACOSTA LINDA C ACOSTA MARIA D ACOSTA PRISCILLA ROSAS ACOSTA RAMON ACOSTA REBECCA ACOSTA STEPHANIE GUADALUPE ACOSTA VALERIE VALDEZ ACOSTA WHITNEY RENAE ACQUAH-FRANKLIN SHAWKEY E ACUNA ANTONIO ADAME ENRIQUE ADAME MARTHA I ADAMS ANTHONY J ADAMS BENJAMIN H ADAMS BENJAMIN S ADAMS BRADLEY W ADAMS BRIAN T ADAMS DEMETRICE NICOLE ADAMS DONNA R ADAMS JOHN O ADAMS LEE H ADAMS PONTUS JOEL ADAMS STEPHANIE JO ADAMS VALORI ELIZABETH ADAMSKI DONALD J ADDARI SANDRA ADEE LAUREN SUN ADKINS NICHOLA ANTIONETTE ADKINS OSCAR ALBERTO ADOLPHO BERENICE ADOLPHO QUINLINN K 2/23/2017 2 of 271 2017 Purge List AGBULOS ERIC PINILI AGBULOS TITUS PINILI AGNEW HENRY E AGUAYO RITA AGUILAR CRYSTAL ASHLEY AGUILAR DAVID AGUILAR AGUILAR MARIA LAURA AGUILAR MICHAEL R AGUILAR RAELENE D AGUILAR ROSANNE DENE AGUILAR RUBEN F AGUILERA ALEJANDRA D AGUILERA FAUSTINO H AGUILERA GABRIEL -

Given Name Alternatives for Irish Research Name Abreviations
Given Name Alternatives for Irish Research Name Abreviations Nicknames Synonyms Irish Latin Abigail Abig Ab, Abbie, Abby, Bina, Debbie, Gail, Abina, Deborah, Gobinet, Dora Abaigeal, Abaigh, Gobnata Gubbie, Gubby, Libby, Nabby, Webbie Gobnait Abraham Ab, Abm, Abr, Abe, Abby Abram Abraham Abrahame Abra, Abrm Adam Edie Adhamh Adamus Agnes Agn Aggie, Aggy, Annot, Assie, Inez, Nanny, Annais, Anneyce, Annis, Annys, Aigneis, Mor, Oonagh, Agna, Agneta, Agnetis, Agnus, Una Nessa, Nessie, Taggett, Taggy Nancy,Una,Unity,Uny,Winifred Una Aidan Aedan,Edan, Mogue, Moses Aodh, Aodhan, Mogue Aedannus, Edanus Ailbhe Elli, Elly Ailbhe Aileen Allie, Eily, Ellie, Lena, Nel, Nellie, Nelly Eileen, Ellen, Eveleen, Evelyn Eibhilin, Eibhlin Helena Albert Al, Albie, Alby, Alvy, Bert, Bertie, Burt Ailbe, Ailbhe, Beirichtir Ailbertus, Alberti, Albertus Alberta Aubrey, Berta, Bertha, Bertie Roberta Alberta Alexander Aler, Alexr, Al, Ala, Alec, Ales, Alex, Alick, Allister, Alaster, Alistair, Sander Alasdair, Alastar, Alusdar, Alexander Alr, Alx, Alxr Andi, Ec, Ellick, Lex, Sandy, Xandra Saunder Alfred Alf Al, Alfie, Fred, Freddie, Freddy Albert, Alured, Alvery, Avery Ailfrid Alfredus, Aluredus Alice Ailse, Alcy, Alica, Alley, Allie, Ally, Alicia, Ellen Ailis, Aislinn, Alis, Eilish Alechea, Alecia, Alesia, Alicia, Alitia Eily, Elly, Elsie, Lisa, Lizzie Alicia Allie, Elsie, Lisa Alice, Alisha, Elisha Ailis, Ailise Alicia Allowshis Allow Aloyisius, Aloysius Aloysius Al, Alley, Allie, Ally, Lou, Louie Lewis, Louis Alabhaois, Alaois, Lugaid Aloisius, Aloysius, Helewise -

Cultural Identity Represented: Celticness in Ireland
Ethnologie Cultural identity represented: Celticness in Ireland Inaugural-Dissertation zur Erlangung des Doktorgrades der Philosophischen Fakultät der Westfälischen Wilhelms-Universität zu Münster (Westf.) vorgelegt von Sabine Hezel aus Oberhausen 2006 Tag des Abschlusses: 16.11.2006 Dekan: Univ.-Prof. Dr. Dr. Wichard Woyke Referent: Univ.-Prof. Dr. Josephus D.M. Platenkamp Korreferent: Univ.-Prof. Dr. Andreas Hartmann Acknowledgements I would like to express my thanks to all the people in Ireland who gave me valuable assistance in the researching of this thesis. First of all I want to thank Ann Tighe and Claire Sheridan. Without their friendship and help in distributing questionnaires and introducing me to a number of people, my stay in Galway would have been a lot less informative (and less pleasant). Thanks also to all the people who filled out questionnaires and were willing to give interviews. I am especially grateful for the opportunity to work in my own office, which was provided by the Department of Political Science and Sociology of the National University Ireland, Galway, and the help that was provided by Dr. Niall O Dochartaigh. Special thanks also to my PhD tutor Prof. Dr. J. Platenkamp. His continually constructive and helpful critique substantially contributed to the completion of this thesis. But above all my thanks go to Dave Hegarty. His love, patience and understanding were an inexhaustible source for strength and support. Ohne die Hilfe meiner Eltern, Anne und Johann Hezel, wäre es mir nicht möglich gewesen, ein Jahr in Irland zu verbringen. Ihnen gilt daher mein ganz besonderer Dank. Ohne ihr stets wohlwollendes Verständnis und ihre Unterstützung wäre diese Arbeit nicht zustande gekommen. -
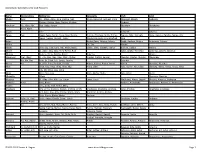
Given Name Alternatives for Irish Research
Given Name Alternatives for Irish Research Name Abreviations Nicknames Synonyms Irish Latin Abigail Abig Ab, Abbie, Abby, Bina, Debbie, Gail, Abina, Deborah, Gobinet, Dora Abaigeal, Abaigh, Gobnata Gubbie, Gubby, Libby, Nabby, Webbie Gobnait Abraham Ab, Abm, Abr, Abe, Abby, Abram Abraham Abrahame Abra, Abrm Adam Edie Adhamh Adamus Agnes Agn Aggie, Aggy, Annot, Assie, Inez, Nanny, Annais, Anneyce, Annis, Annys, Aigneis, Mor, Oonagh, Agna, Agneta, Agnetis, Agnus, Una Nessa, Nessie, Taggett, Taggy Nancy,Una,Unity,Uny,Winifred Una Aidan Aedan,Edan, Mogue, Moses Aodh, Aodhan, Mogue Aedannus, Edanus Ailbhe Elli, Elly Ailbhe Aileen Allie, Eily, Ellie, Lena, Nel, Nellie, Nelly Eileen, Ellen, Eveleen, Evelyn Eibhilin, Eibhlin Helena Albert Al, Albie, Alby, Alvy, Bert, Bertie, Burt Ailbe, Ailbhe, Beirichtir Ailbertus, Alberti, Albertus Alberta Aubrey, Berta, Bertha, Bertie Roberta Alberta Alexander Aler, Alexr, Al, Ala, Alec, Ales, Alex, Alick, Allister, Alaster, Alistair, Sander Alasdair, Alastar, Alusdar, Alexander Alr, Alx, Alxr Andi, Ec, Ellick, Lex, Sandy, Xandra Saunder Alfred Alf Al, Alfie, Fred, Freddie, Freddy Albert, Alured, Alvery, Avery Ailfrid Alfredus, Aluredus Alice Ailse, Alcy, Alica, Alley, Allie, Ally, Alicia, Ellen Ailis, Aislinn, Alis, Eilish Alechea, Alecia, Alesia, Alicia, Alitia Eily, Elly, Elsie, Lisa, Lizzie Alicia Allie, Elsie, Lisa Alice, Alisha, Elisha Ailis, Ailise Alicia Allowshis Allow Aloyisius, Aloysius Aloysius Al, Alley, Allie, Ally, Lou, Louie Lewis, Louis Alabhaois, Alaois, Lugaid Aloisius, Aloysius, Helewise -

About Confirmation Names How to Choose a Saints Name
About Confirmation Names Confirmation names are a special part of the confirmation process for Roman Catholics, especially those in English-speaking countries. Before the ritual of being confirmed, those seeking confirmation choose to take a saint's name with whom they identify. After confirmation the confirmed can pray to the saint for guidance and protection. Significance Confirmation is a rite or sacrament in the Christian tradition. For Roman Catholics, confirmation usually occurs in early adolescence. Other Christian denominations place confirmation soon after baptism. Coming from the New Testament, confirmation is related to the receiving of the Holy Spirit by the apostles on Pentecost. At the time of confirmation, the Holy Spirit is thought to descend on the person and bestow spiritual gifts. Features Roman Catholics going through confirmation choose a saint they feel an affinity for as their confirmation name. The patron saint then serves as their guide and protector. Choosing a confirmation name is not biblical and does not come from the official Catholic liturgical book. The custom originated in the United Kingdom and is also practiced in the United States, Germany and Poland. Types The set of confirmation names is as long as the list of saints that can be found in the resources section below. Some of the more popular confirmation names for girls are Mary, Teresa and Catherine. For boys they are Michael, Thomas and Francis. Considerations The common advice for those trying to decide on a name is to research saint names and find one that fits their personality or spiritual goals. Those seeking confirmation are also encouraged to pray and seek a saint that is willing to guide them as they seek a closer relationship with God. -

Part I: Comparative Linguistic Gender Louise O. Vasvári Abstract T
1 Grammatical Gender Trouble and Hungarian Gender[lessness]. Part I: Comparative Linguistic Gender Louise O. Vasvári Abstract The aim of this study is to define linguistic gender[lessness], with particular reference in the latter part of the article to Hungarian, and to show why it is a feminist issue. I will discuss the [socio]linguistics of linguistic gender in three types of languages, those, like German and the Romance languages, among others, which possess grammatical gender, languages such as English, with only pronominal gender (sometimes misnamed ‘natural gender’), and languages such as Hungarian and other Finno-Ugric languages, as well as many other languages in the world, such as Turkish and Chinese, which have no linguistic or pronomial gender, but, like all languages, can make lexical gender distinctions. While in a narrow linguistic sense linguistic gender can be said to be afunctional, this does not take into account the ideological ramifications in gendered languages of the “leakage” between gender and sex[ism], while at the same time so- called genderless languages can express societal sexist assumptions linguistically through, for example, lexical gender, semantic derogation of women, and naming conventions. Thus, both languages with overt grammatical gender and those with gender- related asymmetries of a more covert nature show language to represent traditional cultural expectations, illustrating that linguistic gender is a feminist issue. The aim of this study is to define linguistic gender[lessness], with particular reference (ultimately) to Hungarian, and to show why it is a feminist issue. I will discuss the [socio]linguistics of gender in three types of languages, those, like the classical Indo- European languages, plus German and the Romance languages, among others, which possess grammatical gender, languages such as English, with only pronominal gender (sometimes misnamed ‘natural gender’), and languages such as Hungarian and other Finno-Ugric languages, and Turkish.