Multiple Correlation Coefficient
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

04 – Everything You Want to Know About Correlation but Were
EVERYTHING YOU WANT TO KNOW ABOUT CORRELATION BUT WERE AFRAID TO ASK F R E D K U O 1 MOTIVATION • Correlation as a source of confusion • Some of the confusion may arise from the literary use of the word to convey dependence as most people use “correlation” and “dependence” interchangeably • The word “correlation” is ubiquitous in cost/schedule risk analysis and yet there are a lot of misconception about it. • A better understanding of the meaning and derivation of correlation coefficient, and what it truly measures is beneficial for cost/schedule analysts. • Many times “true” correlation is not obtainable, as will be demonstrated in this presentation, what should the risk analyst do? • Is there any other measures of dependence other than correlation? • Concordance and Discordance • Co-monotonicity and Counter-monotonicity • Conditional Correlation etc. 2 CONTENTS • What is Correlation? • Correlation and dependence • Some examples • Defining and Estimating Correlation • How many data points for an accurate calculation? • The use and misuse of correlation • Some example • Correlation and Cost Estimate • How does correlation affect cost estimates? • Portfolio effect? • Correlation and Schedule Risk • How correlation affect schedule risks? • How Shall We Go From Here? • Some ideas for risk analysis 3 POPULARITY AND SHORTCOMINGS OF CORRELATION • Why Correlation Is Popular? • Correlation is a natural measure of dependence for a Multivariate Normal Distribution (MVN) and the so-called elliptical family of distributions • It is easy to calculate analytically; we only need to calculate covariance and variance to get correlation • Correlation and covariance are easy to manipulate under linear operations • Correlation Shortcomings • Variances of R.V. -

11. Correlation and Linear Regression
11. Correlation and linear regression The goal in this chapter is to introduce correlation and linear regression. These are the standard tools that statisticians rely on when analysing the relationship between continuous predictors and continuous outcomes. 11.1 Correlations In this section we’ll talk about how to describe the relationships between variables in the data. To do that, we want to talk mostly about the correlation between variables. But first, we need some data. 11.1.1 The data Table 11.1: Descriptive statistics for the parenthood data. variable min max mean median std. dev IQR Dan’s grumpiness 41 91 63.71 62 10.05 14 Dan’s hours slept 4.84 9.00 6.97 7.03 1.02 1.45 Dan’s son’s hours slept 3.25 12.07 8.05 7.95 2.07 3.21 ............................................................................................ Let’s turn to a topic close to every parent’s heart: sleep. The data set we’ll use is fictitious, but based on real events. Suppose I’m curious to find out how much my infant son’s sleeping habits affect my mood. Let’s say that I can rate my grumpiness very precisely, on a scale from 0 (not at all grumpy) to 100 (grumpy as a very, very grumpy old man or woman). And lets also assume that I’ve been measuring my grumpiness, my sleeping patterns and my son’s sleeping patterns for - 251 - quite some time now. Let’s say, for 100 days. And, being a nerd, I’ve saved the data as a file called parenthood.csv. -

Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10
International Journal of Environmental Research and Public Health Article Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10 Rudy de Barros Ahrens 1,*, Luciana da Silva Lirani 2 and Antonio Carlos de Francisco 3 1 Department of Business, Faculty Sagrada Família (FASF), Ponta Grossa, PR 84010-760, Brazil 2 Department of Health Sciences Center, State University Northern of Paraná (UENP), Jacarezinho, PR 86400-000, Brazil; [email protected] 3 Department of Industrial Engineering and Post-Graduation in Production Engineering, Federal University of Technology—Paraná (UTFPR), Ponta Grossa, PR 84017-220, Brazil; [email protected] * Correspondence: [email protected] Received: 1 September 2020; Accepted: 29 September 2020; Published: 9 October 2020 Abstract: The purpose of this study was to validate the construct and reliability of an instrument to assess the work environment as a single tool based on quality of life (QL), quality of work life (QWL), and organizational climate (OC). The methodology tested the construct validity through Exploratory Factor Analysis (EFA) and reliability through Cronbach’s alpha. The EFA returned a Kaiser–Meyer–Olkin (KMO) value of 0.917; which demonstrated that the data were adequate for the factor analysis; and a significant Bartlett’s test of sphericity (χ2 = 7465.349; Df = 1225; p 0.000). ≤ After the EFA; the varimax rotation method was employed for a factor through commonality analysis; reducing the 14 initial factors to 10. Only question 30 presented commonality lower than 0.5; and the other questions returned values higher than 0.5 in the commonality analysis. Regarding the reliability of the instrument; all of the questions presented reliability as the values varied between 0.953 and 0.956. -
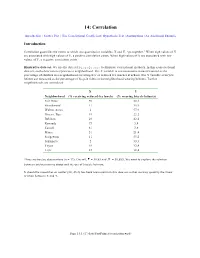
14: Correlation
14: Correlation Introduction | Scatter Plot | The Correlational Coefficient | Hypothesis Test | Assumptions | An Additional Example Introduction Correlation quantifies the extent to which two quantitative variables, X and Y, “go together.” When high values of X are associated with high values of Y, a positive correlation exists. When high values of X are associated with low values of Y, a negative correlation exists. Illustrative data set. We use the data set bicycle.sav to illustrate correlational methods. In this cross-sectional data set, each observation represents a neighborhood. The X variable is socioeconomic status measured as the percentage of children in a neighborhood receiving free or reduced-fee lunches at school. The Y variable is bicycle helmet use measured as the percentage of bicycle riders in the neighborhood wearing helmets. Twelve neighborhoods are considered: X Y Neighborhood (% receiving reduced-fee lunch) (% wearing bicycle helmets) Fair Oaks 50 22.1 Strandwood 11 35.9 Walnut Acres 2 57.9 Discov. Bay 19 22.2 Belshaw 26 42.4 Kennedy 73 5.8 Cassell 81 3.6 Miner 51 21.4 Sedgewick 11 55.2 Sakamoto 2 33.3 Toyon 19 32.4 Lietz 25 38.4 Three are twelve observations (n = 12). Overall, = 30.83 and = 30.883. We want to explore the relation between socioeconomic status and the use of bicycle helmets. It should be noted that an outlier (84, 46.6) has been removed from this data set so that we may quantify the linear relation between X and Y. Page 14.1 (C:\data\StatPrimer\correlation.wpd) Scatter Plot The first step is create a scatter plot of the data. -

CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (Moderately Hard)Or
5 COMPUTING CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (moderately hard)or WHAT YOU WILLpost, LEARN IN THIS CHAPTER • Understanding what correlations are and how they work • Computing a simple correlation coefficient • Interpretingcopy, the value of the correlation coefficient • Understanding what other types of correlations exist and when they notshould be used Do WHAT ARE CORRELATIONS ALL ABOUT? Measures of central tendency and measures of variability are not the only descrip- tive statistics that we are interested in using to get a picture of what a set of scores 76 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 5 ■ Computing Correlation Coefficients 77 looks like. You have already learned that knowing the values of the one most repre- sentative score (central tendency) and a measure of spread or dispersion (variability) is critical for describing the characteristics of a distribution. However, sometimes we are as interested in the relationship between variables—or, to be more precise, how the value of one variable changes when the value of another variable changes. The way we express this interest is through the computation of a simple correlation coefficient. For example, what’s the relationship between age and strength? Income and years of education? Memory skills and amount of drug use? Your political attitudes and the attitudes of your parents? A correlation coefficient is a numerical index that reflects the relationship or asso- ciation between two variables. The value of this descriptive statistic ranges between −1.00 and +1.00. -

Eight Things You Need to Know About Interpreting Correlations
Research Skills One, Correlation interpretation, Graham Hole v.1.0. Page 1 Eight things you need to know about interpreting correlations: A correlation coefficient is a single number that represents the degree of association between two sets of measurements. It ranges from +1 (perfect positive correlation) through 0 (no correlation at all) to -1 (perfect negative correlation). Correlations are easy to calculate, but their interpretation is fraught with difficulties because the apparent size of the correlation can be affected by so many different things. The following are some of the issues that you need to take into account when interpreting the results of a correlation test. 1. Correlation does not imply causality: This is the single most important thing to remember about correlations. If there is a strong correlation between two variables, it's easy to jump to the conclusion that one of the variables causes the change in the other. However this is not a valid conclusion. If you have two variables, X and Y, it might be that X causes Y; that Y causes X; or that a third factor, Z (or even a whole set of other factors) gives rise to the changes in both X and Y. For example, suppose there is a correlation between how many slices of pizza I eat (variable X), and how happy I am (variable Y). It might be that X causes Y - so that the more pizza slices I eat, the happier I become. But it might equally well be that Y causes X - the happier I am, the more pizza I eat. -

Chapter 11 -- Correlation
Contents 11 Association Between Variables 795 11.4 Correlation . 795 11.4.1 Introduction . 795 11.4.2 Correlation Coe±cient . 796 11.4.3 Pearson's r . 800 11.4.4 Test of Signi¯cance for r . 810 11.4.5 Correlation and Causation . 813 11.4.6 Spearman's rho . 819 11.4.7 Size of r for Various Types of Data . 828 794 Chapter 11 Association Between Variables 11.4 Correlation 11.4.1 Introduction The measures of association examined so far in this chapter are useful for describing the nature of association between two variables which are mea- sured at no more than the nominal scale of measurement. All of these measures, Á, C, Cramer's xV and ¸, can also be used to describe association between variables that are measured at the ordinal, interval or ratio level of measurement. But where variables are measured at these higher levels, it is preferable to employ measures of association which use the information contained in these higher levels of measurement. These higher level scales either rank values of the variable, or permit the researcher to measure the distance between values of the variable. The association between rankings of two variables, or the association of distances between values of the variable provides a more detailed idea of the nature of association between variables than do the measures examined so far in this chapter. While there are many measures of association for variables which are measured at the ordinal or higher level of measurement, correlation is the most commonly used approach. -

Alternatives to Pearson's and Spearman's Correlation Coefficients
Alternatives To Pearson’s and Spearman’s Correlation Coefficients Florentin Smarandache Chair of Math & Sciences Department University of New Mexico Gallup, NM 87301, USA Abstract. This article presents several alternatives to Pearson’s correlation coefficient and many examples. In the samples where the rank in a discrete variable counts more than the variable values, the mixture of Pearson’s and Spearman’s gives a better result. Introduction Let’s consider a bivariate sample, which consists of n ≥ 2 pairs (x,y). We denote these pairs by: (x1, y1), (x2, y2), … , (xn,yn), where xi = the value of x for the i-th observation, and yi = the value of y for the i-th observation, for any 1 < i < n. We can construct a scatter plot in order to detect any relationship between variables x and y, drawing a horizontal x-axis and a vertical y-axis, and plotting points of coordinates (xi, yi) for all i ∈{1, 2, …, n}. We use the standard statistics notations, mostly used in regression analysis: n n n ∑ x = ∑ xi , ∑∑y = yi , ∑∑xyxy= ()ii , i=1 i=1 i=1 n n 2 2 2 2 ∑ x = ∑ xi , ∑ y = ∑ yi , (1) i=1 i=1 n ∑ xi X = i=1 = the mean of sample variable x, n n ∑ yi Y = i=1 = the mean of sample variable y. n Let’s introduce a notation for the median: XM = the median of sample variable x, (2) YM = the median of sample variable y. Correlation Coefficients. Correlation coefficient of variables x and y shows how strongly the values of these variables are related to one another. -

Pearson's Correlation Was Run to Determine the Relationship Between 14 Females' Hb and PCV Values
Pearson’s correlation Introduction Often several quantitative variables are measured on each member of a sample. If we consider a pair of such variables, it is frequently of interest to establish if there is a relationship between the two; i.e. to see if they are correlated. We can categorise the type of correlation by considering as one variable increases what happens to the other variable: Positive correlation – the other variable has a tendency to also increase; Negative correlation – the other variable has a tendency to decrease; No correlation – the other variable does not tend to either increase or decrease. The starting point of any such analysis should thus be the construction and subsequent examination of a scatterplot. Examples of negative, no and positive correlation are as follows. Negative No Positive correlation correlation correlation Example Let us now consider a specific example. The following data concerns the blood haemoglobin (Hb) levels and packed cell volumes (PCV) of 14 female blood bank donors. It is of interest to know if there is a relationship between the two variables Hb and PCV when considered in the female population. Hb PCV 15.5 0.450 13.6 0.420 13.5 0.440 13.0 0.395 13.3 0.395 12.4 0.370 11.1 0.390 13.1 0.400 16.1 0.445 16.4 0.470 13.4 0.390 13.2 0.400 14.3 0.420 16.1 0.450 The scatterplot suggests a definite relationship between PVC and Hb, with larger values of Hb tending to be associated with larger values of PCV. -

Relationship Between Two Variables: Correlation, Covariance and R-Squared
FEEG6017 lecture: Relationship between two variables: correlation, covariance and r-squared Markus Brede [email protected] Relationships between variables • So far we have looked at ways of characterizing the distribution of a single variable, and testing hypotheses about the population based on a sample. • We're now moving on to the ways in which two variables can be examined together. • This comes up a lot in research! Relationships between variables • You might want to know: o To what extent the change in a patient's blood pressure is linked to the dosage level of a drug they've been given. o To what degree the number of plant species in an ecosystem is related to the number of animal species. o Whether temperature affects the rate of a chemical reaction. Relationships between variables • We assume that for each case we have at least two real-valued variables. • For example: both height (cm) and weight (kg) recorded for a group of people. • The standard way to display this is using a dot plot or scatterplot. Positive Relationship Negative Relationship No Relationship Measuring relationships? • We're going to need a way of measuring whether one variable changes when another one does. • Another way of putting it: when we know the value of variable A, how much information do we have about variable B's value? Recap of the one-variable case • Perhaps we can borrow some ideas about the way we characterized variation in the single-variable case. • With one variable, we start out by finding the mean, which is also the expectation of the distribution. -

Chapter 9: Serial Correlation
CHAPTER 9: SERIAL CORRELATION Serial correlation (or autocorrelation) is the violation of Assumption 4 (observations of the error term are uncorrelated with each other). Pure Serial Correlation This type of correlation tends to be seen in time series data. To denote a time series data set we will use a subscript. This type of serial correlation occurs when the error in one period is correlated with the errors in other periods. The model is assumed to be correctly specified. The most common form of serial correlation is called first-order serial correlation in which the error in time is related to the previous (1 period’s error: , 11 The new parameter is called the first-order autocorrelation coefficient. The process for the error term is referred to as a first-order autoregressive process or AR(1). Page 1 of 19 CHAPTER 9: SERIAL CORRELATION The magnitude of tells us about the strength of the serial correlation and the sign indicates the nature of the serial correlation. 0 indicates no serial correlation 0 indicates positive serial correlation – the error terms will tend to have the same sign from one period to the next Page 2 of 19 CHAPTER 9: SERIAL CORRELATION 0 indicates negative serial correlation – the error terms will tend to have a different sign from one period to the next Page 3 of 19 CHAPTER 9: SERIAL CORRELATION Impure Serial Correlation This type of serial correlation is caused by a specification error such as an omitted variable or ignoring nonlinearities. Suppose the true regression equation is given by but in our model we do not include . -

Sampling Variance in the Correlation Coefficient Under Indirect Range Restriction: Implications for Validity Generalization
Journal of Applied Psychology Copyright 1997 by the American Psychological Association, Inc. 1997, Vol. 82, No. 4, 528-538 0021-9010/97/$3.00 Sampling Variance in the Correlation Coefficient Under Indirect Range Restriction: Implications for Validity Generalization Herman Aguinis and Roger Whitehead University of Colorado at Denver The authors conducted Monte Carlo simulations to investigate whether indirect range restriction (IRR) on 2 variables X and Y increases the sampling error variability in the correlation coefficient between them. The manipulated parameters were (a) IRR on X and Y (i.e., direct restriction on a third variable Z), (b) population correlations pxv, Pxz, and pvz, and (c) sample size. IRR increased the sampling error variance in r^y to values as high as 8.50% larger than the analytically derived expected values. Thus, in the presence of IRR, validity generalization users need to make theory-based decisions to ascertain whether the effects of IRR are artifactual or caused by situational-specific moderating effects. Meta-analysis constitutes a set of procedures used to in an X- Y relationship across individual studies is the quantitatively integrate a body of literature. Validity gener- result of sources of variance not explicitly considered in alization (VG) is one of the most commonly used meta- a study design. Consequently, to better estimate an X- analytic techniques in industrial and organizational (I&O) Y relationship in the population, researchers should (a) psychology, management, and numerous other disciplines attempt to control the impact of these extraneous sources (e.g., Hunter & Schmidt, 1990; Hunter, Schmidt, & Jack- of variance by implementing sound research designs and son, 1982; Mendoza & Reinhardt, 1991; Schmidt, 1992).