Psychometrics Using Stata
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Volume Quantification by Contrast-Enhanced Ultrasound
Herold et al. Cardiovascular Ultrasound 2013, 11:36 http://www.cardiovascularultrasound.com/content/11/1/36 CARDIOVASCULAR ULTRASOUND RESEARCH Open Access Volume quantification by contrast-enhanced ultrasound: an in-vitro comparison with true volumes and thermodilution Ingeborg HF Herold1*, Gianna Russo2, Massimo Mischi2, Patrick Houthuizen3, Tamerlan Saidov2, Marcel van het Veer3, Hans C van Assen2 and Hendrikus HM Korsten1,2 Abstract Background: Contrast-enhanced ultrasound (CEUS) has recently been proposed as a minimally- invasive, alternative method for blood volume measurement. This study aims at comparing the accuracy of CEUS and the classical thermodilution techniques for volume assessment in an in-vitro set-up. Methods: The in-vitro set-up consisted of a variable network between an inflow and outflow tube and a roller pump. The inflow and outflow tubes were insonified with an ultrasound array transducer and a thermistor was placed in each tube. Indicator dilution curves were made by injecting indicator which consisted of an ultrasound- contrast-agent diluted in ice-cold saline. Both acoustic intensity- and thermo-dilution curves were used to calculate the indicator mean transit time between the inflow and outflow tube. The volumes were derived by multiplying the estimated mean transit time by the flow rate. We compared the volumes measured by CEUS with the true volumes of the variable network and those measured by thermodilution by Bland-Altman and intraclass-correlation analysis. Results: The measurements by CEUS and thermodilution showed a very strong correlation (rs=0.94) with a modest volume underestimation by CEUS of −40 ± 28 mL and an overestimation of 84 ± 62 mL by thermodilution compared with the true volumes. -

On the Sampling Variance of Intraclass Correlations and Genetic Correlations
Copyright 1998 by the Genetics Society of America On the Sampling Variance of Intraclass Correlations and Genetic Correlations Peter M. Visscher University of Edinburgh, Institute of Ecology and Resource Management, Edinburgh EH9 3JG, Scotland Manuscript received February 3, 1997 Accepted for publication March 23, 1998 ABSTRACT Widely used standard expressions for the sampling variance of intraclass correlations and genetic correlation coef®cients were reviewed for small and large sample sizes. For the sampling variance of the intraclass correlation, it was shown by simulation that the commonly used expression, derived using a ®rst-order Taylor series performs better than alternative expressions found in the literature, when the between-sire degrees of freedom were small. The expressions for the sampling variance of the genetic correlation are signi®cantly biased for small sample sizes, in particular when the population values, or their estimates, are close to zero. It was shown, both analytically and by simulation, that this is because the estimate of the sampling variance becomes very large in these cases due to very small values of the denominator of the expressions. It was concluded, therefore, that for small samples, estimates of the heritabilities and genetic correlations should not be used in the expressions for the sampling variance of the genetic correlation. It was shown analytically that in cases where the population values of the heritabili- ties are known, using the estimated heritabilities rather than their true values to estimate the genetic correlation results in a lower sampling variance for the genetic correlation. Therefore, for large samples, estimates of heritabilities, and not their true values, should be used. -

An Introduction to Psychometric Theory with Applications in R
What is psychometrics? What is R? Where did it come from, why use it? Basic statistics and graphics TOD An introduction to Psychometric Theory with applications in R William Revelle Department of Psychology Northwestern University Evanston, Illinois USA February, 2013 1 / 71 What is psychometrics? What is R? Where did it come from, why use it? Basic statistics and graphics TOD Overview 1 Overview Psychometrics and R What is Psychometrics What is R 2 Part I: an introduction to R What is R A brief example Basic steps and graphics 3 Day 1: Theory of Data, Issues in Scaling 4 Day 2: More than you ever wanted to know about correlation 5 Day 3: Dimension reduction through factor analysis, principal components analyze and cluster analysis 6 Day 4: Classical Test Theory and Item Response Theory 7 Day 5: Structural Equation Modeling and applied scale construction 2 / 71 What is psychometrics? What is R? Where did it come from, why use it? Basic statistics and graphics TOD Outline of Day 1/part 1 1 What is psychometrics? Conceptual overview Theory: the organization of Observed and Latent variables A latent variable approach to measurement Data and scaling Structural Equation Models 2 What is R? Where did it come from, why use it? Installing R on your computer and adding packages Installing and using packages Implementations of R Basic R capabilities: Calculation, Statistical tables, Graphics Data sets 3 Basic statistics and graphics 4 steps: read, explore, test, graph Basic descriptive and inferential statistics 4 TOD 3 / 71 What is psychometrics? What is R? Where did it come from, why use it? Basic statistics and graphics TOD What is psychometrics? In physical science a first essential step in the direction of learning any subject is to find principles of numerical reckoning and methods for practicably measuring some quality connected with it. -

04 – Everything You Want to Know About Correlation but Were
EVERYTHING YOU WANT TO KNOW ABOUT CORRELATION BUT WERE AFRAID TO ASK F R E D K U O 1 MOTIVATION • Correlation as a source of confusion • Some of the confusion may arise from the literary use of the word to convey dependence as most people use “correlation” and “dependence” interchangeably • The word “correlation” is ubiquitous in cost/schedule risk analysis and yet there are a lot of misconception about it. • A better understanding of the meaning and derivation of correlation coefficient, and what it truly measures is beneficial for cost/schedule analysts. • Many times “true” correlation is not obtainable, as will be demonstrated in this presentation, what should the risk analyst do? • Is there any other measures of dependence other than correlation? • Concordance and Discordance • Co-monotonicity and Counter-monotonicity • Conditional Correlation etc. 2 CONTENTS • What is Correlation? • Correlation and dependence • Some examples • Defining and Estimating Correlation • How many data points for an accurate calculation? • The use and misuse of correlation • Some example • Correlation and Cost Estimate • How does correlation affect cost estimates? • Portfolio effect? • Correlation and Schedule Risk • How correlation affect schedule risks? • How Shall We Go From Here? • Some ideas for risk analysis 3 POPULARITY AND SHORTCOMINGS OF CORRELATION • Why Correlation Is Popular? • Correlation is a natural measure of dependence for a Multivariate Normal Distribution (MVN) and the so-called elliptical family of distributions • It is easy to calculate analytically; we only need to calculate covariance and variance to get correlation • Correlation and covariance are easy to manipulate under linear operations • Correlation Shortcomings • Variances of R.V. -

11. Correlation and Linear Regression
11. Correlation and linear regression The goal in this chapter is to introduce correlation and linear regression. These are the standard tools that statisticians rely on when analysing the relationship between continuous predictors and continuous outcomes. 11.1 Correlations In this section we’ll talk about how to describe the relationships between variables in the data. To do that, we want to talk mostly about the correlation between variables. But first, we need some data. 11.1.1 The data Table 11.1: Descriptive statistics for the parenthood data. variable min max mean median std. dev IQR Dan’s grumpiness 41 91 63.71 62 10.05 14 Dan’s hours slept 4.84 9.00 6.97 7.03 1.02 1.45 Dan’s son’s hours slept 3.25 12.07 8.05 7.95 2.07 3.21 ............................................................................................ Let’s turn to a topic close to every parent’s heart: sleep. The data set we’ll use is fictitious, but based on real events. Suppose I’m curious to find out how much my infant son’s sleeping habits affect my mood. Let’s say that I can rate my grumpiness very precisely, on a scale from 0 (not at all grumpy) to 100 (grumpy as a very, very grumpy old man or woman). And lets also assume that I’ve been measuring my grumpiness, my sleeping patterns and my son’s sleeping patterns for - 251 - quite some time now. Let’s say, for 100 days. And, being a nerd, I’ve saved the data as a file called parenthood.csv. -

Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10
International Journal of Environmental Research and Public Health Article Construct Validity and Reliability of the Work Environment Assessment Instrument WE-10 Rudy de Barros Ahrens 1,*, Luciana da Silva Lirani 2 and Antonio Carlos de Francisco 3 1 Department of Business, Faculty Sagrada Família (FASF), Ponta Grossa, PR 84010-760, Brazil 2 Department of Health Sciences Center, State University Northern of Paraná (UENP), Jacarezinho, PR 86400-000, Brazil; [email protected] 3 Department of Industrial Engineering and Post-Graduation in Production Engineering, Federal University of Technology—Paraná (UTFPR), Ponta Grossa, PR 84017-220, Brazil; [email protected] * Correspondence: [email protected] Received: 1 September 2020; Accepted: 29 September 2020; Published: 9 October 2020 Abstract: The purpose of this study was to validate the construct and reliability of an instrument to assess the work environment as a single tool based on quality of life (QL), quality of work life (QWL), and organizational climate (OC). The methodology tested the construct validity through Exploratory Factor Analysis (EFA) and reliability through Cronbach’s alpha. The EFA returned a Kaiser–Meyer–Olkin (KMO) value of 0.917; which demonstrated that the data were adequate for the factor analysis; and a significant Bartlett’s test of sphericity (χ2 = 7465.349; Df = 1225; p 0.000). ≤ After the EFA; the varimax rotation method was employed for a factor through commonality analysis; reducing the 14 initial factors to 10. Only question 30 presented commonality lower than 0.5; and the other questions returned values higher than 0.5 in the commonality analysis. Regarding the reliability of the instrument; all of the questions presented reliability as the values varied between 0.953 and 0.956. -
14: Correlation
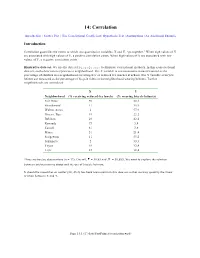
14: Correlation Introduction | Scatter Plot | The Correlational Coefficient | Hypothesis Test | Assumptions | An Additional Example Introduction Correlation quantifies the extent to which two quantitative variables, X and Y, “go together.” When high values of X are associated with high values of Y, a positive correlation exists. When high values of X are associated with low values of Y, a negative correlation exists. Illustrative data set. We use the data set bicycle.sav to illustrate correlational methods. In this cross-sectional data set, each observation represents a neighborhood. The X variable is socioeconomic status measured as the percentage of children in a neighborhood receiving free or reduced-fee lunches at school. The Y variable is bicycle helmet use measured as the percentage of bicycle riders in the neighborhood wearing helmets. Twelve neighborhoods are considered: X Y Neighborhood (% receiving reduced-fee lunch) (% wearing bicycle helmets) Fair Oaks 50 22.1 Strandwood 11 35.9 Walnut Acres 2 57.9 Discov. Bay 19 22.2 Belshaw 26 42.4 Kennedy 73 5.8 Cassell 81 3.6 Miner 51 21.4 Sedgewick 11 55.2 Sakamoto 2 33.3 Toyon 19 32.4 Lietz 25 38.4 Three are twelve observations (n = 12). Overall, = 30.83 and = 30.883. We want to explore the relation between socioeconomic status and the use of bicycle helmets. It should be noted that an outlier (84, 46.6) has been removed from this data set so that we may quantify the linear relation between X and Y. Page 14.1 (C:\data\StatPrimer\correlation.wpd) Scatter Plot The first step is create a scatter plot of the data. -

Fatigue and Psychological Distress in the Working Population Psychometrics, Prevalence, and Correlates
Journal of Psychosomatic Research 52 (2002) 445–452 Fatigue and psychological distress in the working population Psychometrics, prevalence, and correlates Ute Bu¨ltmanna,*, Ijmert Kanta, Stanislav V. Kaslb, Anna J.H.M. Beurskensa, Piet A. van den Brandta aDepartment of Epidemiology, Maastricht University, P.O. Box 616, 6200 MD Maastricht, The Netherlands bDepartment of Epidemiology and Public Health, Yale University School of Medicine, New Haven, CT, USA Received 11 October 2000 Abstract Objective: The purposes of this study were: (1) to explore the distinct pattern of associations was found for fatigue vs. relationship between fatigue and psychological distress in the psychological distress with respect to demographic factors. The working population; (2) to examine associations with demographic prevalence was 22% for fatigue and 23% for psychological and health factors; and (3) to determine the prevalence of fatigue distress. Of the employees reporting fatigue, 43% had fatigue only, and psychological distress. Methods: Data were taken from whereas 57% had fatigue and psychological distress. Conclusions: 12,095 employees. Fatigue was measured with the Checklist The results indicate that fatigue and psychological distress are Individual Strength, and the General Health Questionnaire (GHQ) common in the working population. Although closely associated, was used to measure psychological distress. Results: Fatigue was there is some evidence suggesting that fatigue and psychological fairly well associated with psychological distress. A separation -

When Psychometrics Meets Epidemiology and the Studies V1.Pdf
When psychometrics meets epidemiology, and the studies which result! Tom Booth [email protected] Lecturer in Quantitative Research Methods, Department of Psychology, University of Edinburgh Who am I? • MSc and PhD in Organisational Psychology – ESRC AQM Scholarship • Manchester Business School, University of Manchester • Topic: Personality psychometrics • Post-doctoral Researcher • Centre for Cognitive Ageing and Cognitive Epidemiology, Department of Psychology, University of Edinburgh. • Primary Research Topic: Cognitive ageing, brain imaging. • Lecturer Quantitative Research Methods • Department of Psychology, University of Edinburgh • Primary Research Topics: Individual differences and health; cognitive ability and brain imaging; Psychometric methods and assessment. Journey of a talk…. • Psychometrics: • Performance of likert-type response scales for personality data. • Murray, Booth & Molenaar (2015) • Epidemiology: • Allostatic load • Measurement: Booth, Starr & Deary (2013); (Unpublished) • Applications: Early life adversity (Unpublished) • Further applications Journey of a talk…. • Methodological interlude: • The issue of optimal time scales. • Individual differences and health: • Personality and Physical Health (review: Murray & Booth, 2015) • Personality, health behaviours and brain integrity (Booth, Mottus et al., 2014) • Looking forward Psychometrics My spiritual home… Middle response options Strongly Agree Agree Neither Agree nor Disagree Strong Disagree Disagree 1 2 3 4 5 Strongly Agree Agree Unsure Disagree Strong Disagree -

CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (Moderately Hard)Or
5 COMPUTING CORRELATION COEFFICIENTS Ice Cream and Crimedistribute Difficulty Scale ☺ ☺ (moderately hard)or WHAT YOU WILLpost, LEARN IN THIS CHAPTER • Understanding what correlations are and how they work • Computing a simple correlation coefficient • Interpretingcopy, the value of the correlation coefficient • Understanding what other types of correlations exist and when they notshould be used Do WHAT ARE CORRELATIONS ALL ABOUT? Measures of central tendency and measures of variability are not the only descrip- tive statistics that we are interested in using to get a picture of what a set of scores 76 Copyright ©2020 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. Chapter 5 ■ Computing Correlation Coefficients 77 looks like. You have already learned that knowing the values of the one most repre- sentative score (central tendency) and a measure of spread or dispersion (variability) is critical for describing the characteristics of a distribution. However, sometimes we are as interested in the relationship between variables—or, to be more precise, how the value of one variable changes when the value of another variable changes. The way we express this interest is through the computation of a simple correlation coefficient. For example, what’s the relationship between age and strength? Income and years of education? Memory skills and amount of drug use? Your political attitudes and the attitudes of your parents? A correlation coefficient is a numerical index that reflects the relationship or asso- ciation between two variables. The value of this descriptive statistic ranges between −1.00 and +1.00. -

Properties and Psychometrics of a Measure of Addiction Recovery Strengths
bs_bs_banner REVIEW Drug and Alcohol Review (March 2013), 32, 187–194 DOI: 10.1111/j.1465-3362.2012.00489.x The Assessment of Recovery Capital: Properties and psychometrics of a measure of addiction recovery strengths TEODORA GROSHKOVA1, DAVID BEST2 & WILLIAM WHITE3 1National Addiction Centre, Institute of Psychiatry, King’s College London, London, UK, 2Turning Point Drug and Alcohol Centre, Monash University, Melbourne, Australia, and 3Chestnut Health Systems, Bloomington, Illinois, USA Abstract Introduction and Aims. Sociological work on social capital and its impact on health behaviours have been translated into the addiction field in the form of ‘recovery capital’ as the construct for assessing individual progress on a recovery journey.Yet there has been little attempt to quantify recovery capital.The aim of the project was to create a scale that assessed addiction recovery capital. Design and Methods. Initial focus group work identified and tested candidate items and domains followed by data collection from multiple sources to enable psychometric assessment of a scale measuring recovery capital. Results. The scale shows moderate test–retest reliability at 1 week and acceptable concurrent validity. Principal component analysis determined single factor structure. Discussion and Conclusions. The Assessment of Recovery Capital (ARC) is a brief and easy to administer measurement of recovery capital that has acceptable psychometric properties and may be a useful complement to deficit-based assessment and outcome monitoring instruments for substance dependent individuals in and out of treatment. [Groshkova T, Best D, White W. The Assessment of Recovery Capital: Properties and psychometrics of a measure of addiction recovery strengths. Drug Alcohol Rev 2013;32:187–194] Key words: addiction, recovery capital measure, assessment, psychometrics. -

Eight Things You Need to Know About Interpreting Correlations
Research Skills One, Correlation interpretation, Graham Hole v.1.0. Page 1 Eight things you need to know about interpreting correlations: A correlation coefficient is a single number that represents the degree of association between two sets of measurements. It ranges from +1 (perfect positive correlation) through 0 (no correlation at all) to -1 (perfect negative correlation). Correlations are easy to calculate, but their interpretation is fraught with difficulties because the apparent size of the correlation can be affected by so many different things. The following are some of the issues that you need to take into account when interpreting the results of a correlation test. 1. Correlation does not imply causality: This is the single most important thing to remember about correlations. If there is a strong correlation between two variables, it's easy to jump to the conclusion that one of the variables causes the change in the other. However this is not a valid conclusion. If you have two variables, X and Y, it might be that X causes Y; that Y causes X; or that a third factor, Z (or even a whole set of other factors) gives rise to the changes in both X and Y. For example, suppose there is a correlation between how many slices of pizza I eat (variable X), and how happy I am (variable Y). It might be that X causes Y - so that the more pizza slices I eat, the happier I become. But it might equally well be that Y causes X - the happier I am, the more pizza I eat.