Figure. Expression Patterns of the 148 Genes. Each Row Represnet a Noramlized Gene
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -
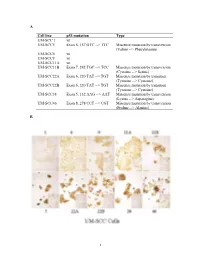
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
![Downloaded from [266]](https://docslib.b-cdn.net/cover/7352/downloaded-from-266-347352.webp)
Downloaded from [266]
Patterns of DNA methylation on the human X chromosome and use in analyzing X-chromosome inactivation by Allison Marie Cotton B.Sc., The University of Guelph, 2005 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY in The Faculty of Graduate Studies (Medical Genetics) THE UNIVERSITY OF BRITISH COLUMBIA (Vancouver) January 2012 © Allison Marie Cotton, 2012 Abstract The process of X-chromosome inactivation achieves dosage compensation between mammalian males and females. In females one X chromosome is transcriptionally silenced through a variety of epigenetic modifications including DNA methylation. Most X-linked genes are subject to X-chromosome inactivation and only expressed from the active X chromosome. On the inactive X chromosome, the CpG island promoters of genes subject to X-chromosome inactivation are methylated in their promoter regions, while genes which escape from X- chromosome inactivation have unmethylated CpG island promoters on both the active and inactive X chromosomes. The first objective of this thesis was to determine if the DNA methylation of CpG island promoters could be used to accurately predict X chromosome inactivation status. The second objective was to use DNA methylation to predict X-chromosome inactivation status in a variety of tissues. A comparison of blood, muscle, kidney and neural tissues revealed tissue-specific X-chromosome inactivation, in which 12% of genes escaped from X-chromosome inactivation in some, but not all, tissues. X-linked DNA methylation analysis of placental tissues predicted four times higher escape from X-chromosome inactivation than in any other tissue. Despite the hypomethylation of repetitive elements on both the X chromosome and the autosomes, no changes were detected in the frequency or intensity of placental Cot-1 holes. -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -
![Downloaded Using the R Package Cgdsr [40] and Were Used](https://docslib.b-cdn.net/cover/7997/downloaded-using-the-r-package-cgdsr-40-and-were-used-457997.webp)
Downloaded Using the R Package Cgdsr [40] and Were Used
Cai et al. BMC Medical Genomics (2020) 13:33 https://doi.org/10.1186/s12920-020-0695-0 RESEARCH ARTICLE Open Access Specific chromatin landscapes and transcription factors couple breast cancer subtype with metastatic relapse to lung or brain Wesley L. Cai1, Celeste B. Greer1,2, Jocelyn F. Chen1, Anna Arnal-Estapé1,3, Jian Cao1,3,4, Qin Yan1,3,5,6*† and Don X. Nguyen1,3,5,6,7*† Abstract Background: Few somatic mutations have been linked to breast cancer metastasis, whereas transcriptomic differences among primary tumors correlate with incidence of metastasis, especially to the lungs and brain. However, the epigenomic alterations and transcription factors (TFs) which underlie these alterations remain unclear. Methods: To identify these, we performed RNA-seq, Chromatin Immunoprecipitation and sequencing (ChIP-seq) and Assay for Transposase-Accessible Chromatin using sequencing (ATAC-seq) of the MDA-MB-231 cell line and its brain (BrM2) and lung (LM2) metastatic sub-populations. We incorporated ATAC-seq data from TCGA to assess metastatic open chromatin signatures, and gene expression data from human metastatic datasets to nominate transcription factor biomarkers. Results: Our integrated epigenomic analyses found that lung and brain metastatic cells exhibit both shared and distinctive signatures of active chromatin. Notably, metastatic sub-populations exhibit increased activation of both promoters and enhancers. We also integrated these data with chromosome conformation capture coupled with ChIP-seq (HiChIP) derived enhancer-promoter interactions to predict enhancer-controlled pathway alterations. We found that enhancer changes are associated with endothelial cell migration in LM2, and negative regulation of epithelial cell proliferation in BrM2. Promoter changes are associated with vasculature development in LM2 and homophilic cell adhesion in BrM2. -

UNIVERSITY of CALIFORNIA RIVERSIDE Investigations Into The
UNIVERSITY OF CALIFORNIA RIVERSIDE Investigations into the Role of TAF1-mediated Phosphorylation in Gene Regulation A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Cell, Molecular and Developmental Biology by Brian James Gadd December 2012 Dissertation Committee: Dr. Xuan Liu, Chairperson Dr. Frank Sauer Dr. Frances M. Sladek Copyright by Brian James Gadd 2012 The Dissertation of Brian James Gadd is approved Committee Chairperson University of California, Riverside Acknowledgments I am thankful to Dr. Liu for her patience and support over the last eight years. I am deeply indebted to my committee members, Dr. Frank Sauer and Dr. Frances Sladek for the insightful comments on my research and this dissertation. Thanks goes out to CMDB, especially Dr. Bachant, Dr. Springer and Kathy Redd for their support. Thanks to all the members of the Liu lab both past and present. A very special thanks to the members of the Sauer lab, including Silvia, Stephane, David, Matt, Stephen, Ninuo, Toby, Josh, Alice, Alex and Flora. You have made all the years here fly by and made them so enjoyable. From the Sladek lab I want to thank Eugene, John, Linh and Karthi. Special thanks go out to all the friends I’ve made over the years here. Chris, Amber, Stephane and David, thank you so much for feeding me, encouraging me and keeping me sane. Thanks to the brothers for all your encouragement and prayers. To any I haven’t mentioned by name, I promise I haven’t forgotten all you’ve done for me during my graduate years. -

Recombinant Human FLRT2 Protein Catalog Number: ATGP3291
Recombinant human FLRT2 protein Catalog Number: ATGP3291 PRODUCT INPORMATION Expression system Baculovirus Domain 36-541aa UniProt No. O43155 NCBI Accession No. NP_037363 Alternative Names FLRT2 PRODUCT SPECIFICATION Molecular Weight 57.5 kDa (514aa) Concentration 0.25mg/ml (determined by absorbance at 280nm) Formulation Liquid in. Phosphate-Buffered Saline (pH 7.4) containing 10% glycerol Purity > 90% by SDS-PAGE Endotoxin level < 1 EU per 1ug of protein (determined by LAL method) Tag His-Tag Application SDS-PAGE Storage Condition Can be stored at +2C to +8C for 1 week. For long term storage, aliquot and store at -20C to -80C. Avoid repeated freezing and thawing cycles. BACKGROUND Description FLRT2, also known as leucine-rich repeat transmembrane protein FLRT2, is one of three FLRT (fibronectin, leucine rich repeat, transmembrane) glycoproteins expressed in distinct areas of the developing brain and other tissues. Human FLRT1 and FLRT3 ECDs (extracellular domain) share approximately 47% aa identity with FLRT2. The fibronectin domain of all three FLRTs can bind to FGF receptors. Recombinant human FLRT2, fused to His-tag 1 Recombinant human FLRT2 protein Catalog Number: ATGP3291 at C-terminus, was expressed in insect cell and purified by using conventional chromatography techniques. Amino acid Sequence CPSVCRCDRN FVYCNERSLT SVPLGIPEGV TVLYLHNNQI NNAGFPAELH NVQSVHTVYL YGNQLDEFPM NLPKNVRVLH LQENNIQTIS RAALAQLLKL EELHLDDNSI STVGVEDGAF REAISLKLLF LSKNHLSSVP VGLPVDLQEL RVDENRIAVI SDMAFQNLTS LERLIVDGNL LTNKGIAEGT FSHLTKLKEF SIVRNSLSHP PPDLPGTHLI RLYLQDNQIN HIPLTAFSNL RKLERLDISN NQLRMLTQGV FDNLSNLKQL TARNNPWFCD CSIKWVTEWL KYIPSSLNVR GFMCQGPEQV RGMAVRELNM NLLSCPTTTP GLPLFTPAPS TASPTTQPPT LSIPNPSRSY TPPTPTTSKL PTIPDWDGRE RVTPPISERI QLSIHFVNDT SIQVSWLSLF TVMAYKLTWV KMGHSLVGGI VQERIVSGEK QHLSLVNLEP RSTYRICLVP LDAFNYRAVE DTICSEATTH ASYLNNGSNT ASSHEQTTSH SMGSPFLEHH HHHH General References Haines B.P., et al. (2006) Dev. -

Identification of Potential Key Genes and Pathway Linked with Sporadic Creutzfeldt-Jakob Disease Based on Integrated Bioinformatics Analyses
medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Identification of potential key genes and pathway linked with sporadic Creutzfeldt-Jakob disease based on integrated bioinformatics analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Abstract Sporadic Creutzfeldt-Jakob disease (sCJD) is neurodegenerative disease also called prion disease linked with poor prognosis. The aim of the current study was to illuminate the underlying molecular mechanisms of sCJD. The mRNA microarray dataset GSE124571 was downloaded from the Gene Expression Omnibus database. Differentially expressed genes (DEGs) were screened. -

Recombinant Human Fibronectin Leucine Rich Transmembrane Protein 2/FLRT2 (C-6His)
9853 Pacific Heights Blvd. Suite D. San Diego, CA 92121, USA Tel: 858-263-4982 Email: [email protected] 32-7320: Recombinant Human Fibronectin Leucine Rich Transmembrane Protein 2/FLRT2 (C-6His) Gene : FLRT2 Gene ID : 23768 Uniprot ID : O43155 Description Source: Human Cells. MW :57.3kD. Recombinant Human FLRT2 is produced by our Mammalian expression system and the target gene encoding Cys36-Ser539 is expressed with a 6His tag at the C-terminus. Fibronectin Leucine Rich Transmembrane protein 2 (FLRT2) is a member of the fibronectin leucine rich transmembrane protein (FLRT) family. The three fibronectin leucine-rich repeat transmembrane (FLRT) proteins: FLRT1, FLRT2 and FLRT3, all contain 10 leucine-rich repeats (LRR), a type III fibronectin (FN) domain, followed by the transmembrane region, and a short cytoplasmic tail. FLRT proteins have dual properties as regulators of cell adhesion and potentiators of fibroblast growth factor (FGF) mediated signalling. The fibronectin domain of all three FLRTs can bind FGF receptors. This binding is thought to regulate FGF signaling during development. The LRR domains are responsible for both the localization of FLRTs in areas of cell contact and homotypic cell cell association. FLRT2 is expressed in a subset of the sclerotome, adjacent to the region that forms the syndetome, suggesting its involvement in the FGF signalling pathway. Product Info Amount : 10 µg / 50 µg Content : Lyophilized from a 0.2 µm filtered solution of 20mM PB, 150mM NaCl, pH 7.2. Lyophilized protein should be stored at -20°C, though stable at room temperature for 3 weeks. Storage condition : Reconstituted protein solution can be stored at 4-7°C for 2-7 days. -

Emerging Role of ODC1 in Neurodevelopmental Disorders and Brain Development
G C A T T A C G G C A T genes Article Emerging Role of ODC1 in Neurodevelopmental Disorders and Brain Development Jeremy W. Prokop 1,2,3,*, Caleb P. Bupp 1,4 , Austin Frisch 1, Stephanie M. Bilinovich 1 , Daniel B. Campbell 1,3,5, Daniel Vogt 1,3,5, Chad R. Schultz 1, Katie L. Uhl 1, Elizabeth VanSickle 4, Surender Rajasekaran 1,6,7 and André S. Bachmann 1,* 1 Department of Pediatrics and Human Development, Michigan State University, Grand Rapids, MI 49503, USA; [email protected] (C.P.B.); [email protected] (A.F.); [email protected] (S.M.B.); [email protected] (D.B.C.); [email protected] (D.V.); [email protected] (C.R.S.); [email protected] (K.L.U.); [email protected] (S.R.) 2 Department of Pharmacology and Toxicology, Michigan State University, East Lansing, MI 48824, USA 3 Center for Research in Autism, Intellectual, and Other Neurodevelopmental Disabilities, Michigan State University, East Lansing, MI 48824, USA 4 Spectrum Health Medical Genetics, Grand Rapids, MI 49503, USA; [email protected] 5 Neuroscience Program, Michigan State University, East Lansing, MI 48824, USA 6 Pediatric Intensive Care Unit, Helen DeVos Children’s Hospital, Grand Rapids, MI 49503, USA 7 Office of Research, Spectrum Health, Grand Rapids, MI 49503, USA * Correspondence: [email protected] (J.W.P.); [email protected] (A.S.B.) Abstract: Ornithine decarboxylase 1 (ODC1 gene) has been linked through gain-of-function variants Citation: Prokop, J.W.; Bupp, C.P.; to a rare disease featuring developmental delay, alopecia, macrocephaly, and structural brain anoma- Frisch, A.; Bilinovich, S.M.; Campbell, lies. -

Identification of Differentially Expressed Genes in Human Bladder Cancer Through Genome-Wide Gene Expression Profiling
521-531 24/7/06 18:28 Page 521 ONCOLOGY REPORTS 16: 521-531, 2006 521 Identification of differentially expressed genes in human bladder cancer through genome-wide gene expression profiling KAZUMORI KAWAKAMI1,3, HIDEKI ENOKIDA1, TOKUSHI TACHIWADA1, TAKENARI GOTANDA1, KENGO TSUNEYOSHI1, HIROYUKI KUBO1, KENRYU NISHIYAMA1, MASAKI TAKIGUCHI2, MASAYUKI NAKAGAWA1 and NAOHIKO SEKI3 1Department of Urology, Graduate School of Medical and Dental Sciences, Kagoshima University, 8-35-1 Sakuragaoka, Kagoshima 890-8520; Departments of 2Biochemistry and Genetics, and 3Functional Genomics, Graduate School of Medicine, Chiba University, 1-8-1 Inohana, Chuo-ku, Chiba 260-8670, Japan Received February 15, 2006; Accepted April 27, 2006 Abstract. Large-scale gene expression profiling is an effective CKS2 gene not only as a potential biomarker for diagnosing, strategy for understanding the progression of bladder cancer but also for staging human BC. This is the first report (BC). The aim of this study was to identify genes that are demonstrating that CKS2 expression is strongly correlated expressed differently in the course of BC progression and to with the progression of human BC. establish new biomarkers for BC. Specimens from 21 patients with pathologically confirmed superficial (n=10) or Introduction invasive (n=11) BC and 4 normal bladder samples were studied; samples from 14 of the 21 BC samples were subjected Bladder cancer (BC) is among the 5 most common to microarray analysis. The validity of the microarray results malignancies worldwide, and the 2nd most common tumor of was verified by real-time RT-PCR. Of the 136 up-regulated the genitourinary tract and the 2nd most common cause of genes we detected, 21 were present in all 14 BCs examined death in patients with cancer of the urinary tract (1-7).