A Note on Conditional Covariance Matrices for Elliptical Distributions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 22: Bivariate Normal Distribution Distribution
6.5 Conditional Distributions General Bivariate Normal Let Z1; Z2 ∼ N (0; 1), which we will use to build a general bivariate normal Lecture 22: Bivariate Normal Distribution distribution. 1 1 2 2 f (z1; z2) = exp − (z1 + z2 ) Statistics 104 2π 2 We want to transform these unit normal distributions to have the follow Colin Rundel arbitrary parameters: µX ; µY ; σX ; σY ; ρ April 11, 2012 X = σX Z1 + µX p 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 1 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - Marginals General Bivariate Normal - Cov/Corr First, lets examine the marginal distributions of X and Y , Second, we can find Cov(X ; Y ) and ρ(X ; Y ) Cov(X ; Y ) = E [(X − E(X ))(Y − E(Y ))] X = σX Z1 + µX h p i = E (σ Z + µ − µ )(σ [ρZ + 1 − ρ2Z ] + µ − µ ) = σX N (0; 1) + µX X 1 X X Y 1 2 Y Y 2 h p 2 i = N (µX ; σX ) = E (σX Z1)(σY [ρZ1 + 1 − ρ Z2]) h 2 p 2 i = σX σY E ρZ1 + 1 − ρ Z1Z2 p 2 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY = σX σY ρE[Z1 ] p 2 = σX σY ρ = σY [ρN (0; 1) + 1 − ρ N (0; 1)] + µY = σ [N (0; ρ2) + N (0; 1 − ρ2)] + µ Y Y Cov(X ; Y ) ρ(X ; Y ) = = ρ = σY N (0; 1) + µY σX σY 2 = N (µY ; σY ) Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 2 / 22 Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 3 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - RNG Multivariate Change of Variables Consequently, if we want to generate a Bivariate Normal random variable Let X1;:::; Xn have a continuous joint distribution with pdf f defined of S. -

On Multivariate Runs Tests for Randomness
On Multivariate Runs Tests for Randomness Davy Paindaveine∗ Universit´eLibre de Bruxelles, Brussels, Belgium Abstract This paper proposes several extensions of the concept of runs to the multi- variate setup, and studies the resulting tests of multivariate randomness against serial dependence. Two types of multivariate runs are defined: (i) an elliptical extension of the spherical runs proposed by Marden (1999), and (ii) an orig- inal concept of matrix-valued runs. The resulting runs tests themselves exist in various versions, one of which is a function of the number of data-based hyperplanes separating pairs of observations only. All proposed multivariate runs tests are affine-invariant and highly robust: in particular, they allow for heteroskedasticity and do not require any moment assumption. Their limit- ing distributions are derived under the null hypothesis and under sequences of local vector ARMA alternatives. Asymptotic relative efficiencies with respect to Gaussian Portmanteau tests are computed, and show that, while Marden- type runs tests suffer severe consistency problems, tests based on matrix-valued ∗Davy Paindaveine is Professor of Statistics, Universit´eLibre de Bruxelles, E.C.A.R.E.S. and D´epartement de Math´ematique, Avenue F. D. Roosevelt, 50, CP 114, B-1050 Bruxelles, Belgium, (e-mail: [email protected]). The author is also member of ECORE, the association between CORE and ECARES. This work was supported by a Mandat d’Impulsion Scientifique of the Fonds National de la Recherche Scientifique, Communaut´efran¸caise de Belgique. 1 runs perform uniformly well for moderate-to-large dimensions. A Monte-Carlo study confirms the theoretical results and investigates the robustness proper- ties of the proposed procedures. -

1 One Parameter Exponential Families
1 One parameter exponential families The world of exponential families bridges the gap between the Gaussian family and general dis- tributions. Many properties of Gaussians carry through to exponential families in a fairly precise sense. • In the Gaussian world, there exact small sample distributional results (i.e. t, F , χ2). • In the exponential family world, there are approximate distributional results (i.e. deviance tests). • In the general setting, we can only appeal to asymptotics. A one-parameter exponential family, F is a one-parameter family of distributions of the form Pη(dx) = exp (η · t(x) − Λ(η)) P0(dx) for some probability measure P0. The parameter η is called the natural or canonical parameter and the function Λ is called the cumulant generating function, and is simply the normalization needed to make dPη fη(x) = (x) = exp (η · t(x) − Λ(η)) dP0 a proper probability density. The random variable t(X) is the sufficient statistic of the exponential family. Note that P0 does not have to be a distribution on R, but these are of course the simplest examples. 1.0.1 A first example: Gaussian with linear sufficient statistic Consider the standard normal distribution Z e−z2=2 P0(A) = p dz A 2π and let t(x) = x. Then, the exponential family is eη·x−x2=2 Pη(dx) / p 2π and we see that Λ(η) = η2=2: eta= np.linspace(-2,2,101) CGF= eta**2/2. plt.plot(eta, CGF) A= plt.gca() A.set_xlabel(r'$\eta$', size=20) A.set_ylabel(r'$\Lambda(\eta)$', size=20) f= plt.gcf() 1 Thus, the exponential family in this setting is the collection F = fN(η; 1) : η 2 Rg : d 1.0.2 Normal with quadratic sufficient statistic on R d As a second example, take P0 = N(0;Id×d), i.e. -

Basic Econometrics / Statistics Statistical Distributions: Normal, T, Chi-Sq, & F
Basic Econometrics / Statistics Statistical Distributions: Normal, T, Chi-Sq, & F Course : Basic Econometrics : HC43 / Statistics B.A. Hons Economics, Semester IV/ Semester III Delhi University Course Instructor: Siddharth Rathore Assistant Professor Economics Department, Gargi College Siddharth Rathore guj75845_appC.qxd 4/16/09 12:41 PM Page 461 APPENDIX C SOME IMPORTANT PROBABILITY DISTRIBUTIONS In Appendix B we noted that a random variable (r.v.) can be described by a few characteristics, or moments, of its probability function (PDF or PMF), such as the expected value and variance. This, however, presumes that we know the PDF of that r.v., which is a tall order since there are all kinds of random variables. In practice, however, some random variables occur so frequently that statisticians have determined their PDFs and documented their properties. For our purpose, we will consider only those PDFs that are of direct interest to us. But keep in mind that there are several other PDFs that statisticians have studied which can be found in any standard statistics textbook. In this appendix we will discuss the following four probability distributions: 1. The normal distribution 2. The t distribution 3. The chi-square (2 ) distribution 4. The F distribution These probability distributions are important in their own right, but for our purposes they are especially important because they help us to find out the probability distributions of estimators (or statistics), such as the sample mean and sample variance. Recall that estimators are random variables. Equipped with that knowledge, we will be able to draw inferences about their true population values. -

D. Normal Mixture Models and Elliptical Models
D. Normal Mixture Models and Elliptical Models 1. Normal Variance Mixtures 2. Normal Mean-Variance Mixtures 3. Spherical Distributions 4. Elliptical Distributions QRM 2010 74 D1. Multivariate Normal Mixture Distributions Pros of Multivariate Normal Distribution • inference is \well known" and estimation is \easy". • distribution is given by µ and Σ. • linear combinations are normal (! VaR and ES calcs easy). • conditional distributions are normal. > • For (X1;X2) ∼ N2(µ; Σ), ρ(X1;X2) = 0 () X1 and X2 are independent: QRM 2010 75 Multivariate Normal Variance Mixtures Cons of Multivariate Normal Distribution • tails are thin, meaning that extreme values are scarce in the normal model. • joint extremes in the multivariate model are also too scarce. • the distribution has a strong form of symmetry, called elliptical symmetry. How to repair the drawbacks of the multivariate normal model? QRM 2010 76 Multivariate Normal Variance Mixtures The random vector X has a (multivariate) normal variance mixture distribution if d p X = µ + WAZ; (1) where • Z ∼ Nk(0;Ik); • W ≥ 0 is a scalar random variable which is independent of Z; and • A 2 Rd×k and µ 2 Rd are a matrix and a vector of constants, respectively. > Set Σ := AA . Observe: XjW = w ∼ Nd(µ; wΣ). QRM 2010 77 Multivariate Normal Variance Mixtures Assumption: rank(A)= d ≤ k, so Σ is a positive definite matrix. If E(W ) < 1 then easy calculations give E(X) = µ and cov(X) = E(W )Σ: We call µ the location vector or mean vector and we call Σ the dispersion matrix. The correlation matrices of X and AZ are identical: corr(X) = corr(AZ): Multivariate normal variance mixtures provide the most useful examples of elliptical distributions. -
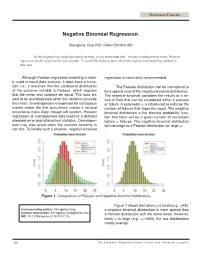
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Section 1: Regression Review
Section 1: Regression review Yotam Shem-Tov Fall 2015 Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 1 / 58 Contact information Yotam Shem-Tov, PhD student in economics. E-mail: [email protected]. Office: Evans hall room 650 Office hours: To be announced - any preferences or constraints? Feel free to e-mail me. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 2 / 58 R resources - Prior knowledge in R is assumed In the link here is an excellent introduction to statistics in R . There is a free online course in coursera on programming in R. Here is a link to the course. An excellent book for implementing econometric models and method in R is Applied Econometrics with R. This is my favourite for starting to learn R for someone who has some background in statistic methods in the social science. The book Regression Models for Data Science in R has a nice online version. It covers the implementation of regression models using R . A great link to R resources and other cool programming and econometric tools is here. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 3 / 58 Outline There are two general approaches to regression 1 Regression as a model: a data generating process (DGP) 2 Regression as an algorithm (i.e., an estimator without assuming an underlying structural model). Overview of this slides: 1 The conditional expectation function - a motivation for using OLS. 2 OLS as the minimum mean squared error linear approximation (projections). 3 Regression as a structural model (i.e., assuming the conditional expectation is linear). -

Generalized Skew-Elliptical Distributions and Their Quadratic Forms
Ann. Inst. Statist. Math. Vol. 57, No. 2, 389-401 (2005) @2005 The Institute of Statistical Mathematics GENERALIZED SKEW-ELLIPTICAL DISTRIBUTIONS AND THEIR QUADRATIC FORMS MARC G. GENTON 1 AND NICOLA M. R. LOPERFIDO2 1Department of Statistics, Texas A ~M University, College Station, TX 77843-3143, U.S.A., e-mail: genton~stat.tamu.edu 2 Instituto di scienze Econoraiche, Facoltd di Economia, Universit~ degli Studi di Urbino, Via SaJ~ 42, 61029 Urbino ( PU), Italy, e-mail: nicolaQecon.uniurb.it (Received February 10, 2003; revised March 1, 2004) Abstract. This paper introduces generalized skew-elliptical distributions (GSE), which include the multivariate skew-normal, skew-t, skew-Cauchy, and skew-elliptical distributions as special cases. GSE are weighted elliptical distributions but the dis- tribution of any even function in GSE random vectors does not depend on the weight function. In particular, this holds for quadratic forms in GSE random vectors. This property is beneficial for inference from non-random samples. We illustrate the latter point on a data set of Australian athletes. Key words and phrases: Elliptical distribution, invariance, kurtosis, selection model, skewness, weighted distribution. 1. Introduction Probability distributions that are more flexible than the normal are often needed in statistical modeling (Hill and Dixon (1982)). Skewness in datasets, for example, can be modeled through the multivariate skew-normal distribution introduced by Azzalini and Dalla Valle (1996), which appears to attain a reasonable compromise between mathe- matical tractability and shape flexibility. Its probability density function (pdf) is (1.1) 2~)p(Z; ~, ~-~) . O(ozT(z -- ~)), Z E ]~P, where Cp denotes the pdf of a p-dimensional normal distribution centered at ~ C ]~P with scale matrix ~t E ]~pxp and denotes the cumulative distribution function (cdf) of a standard normal distribution. -

(Introduction to Probability at an Advanced Level) - All Lecture Notes
Fall 2018 Statistics 201A (Introduction to Probability at an advanced level) - All Lecture Notes Aditya Guntuboyina August 15, 2020 Contents 0.1 Sample spaces, Events, Probability.................................5 0.2 Conditional Probability and Independence.............................6 0.3 Random Variables..........................................7 1 Random Variables, Expectation and Variance8 1.1 Expectations of Random Variables.................................9 1.2 Variance................................................ 10 2 Independence of Random Variables 11 3 Common Distributions 11 3.1 Ber(p) Distribution......................................... 11 3.2 Bin(n; p) Distribution........................................ 11 3.3 Poisson Distribution......................................... 12 4 Covariance, Correlation and Regression 14 5 Correlation and Regression 16 6 Back to Common Distributions 16 6.1 Geometric Distribution........................................ 16 6.2 Negative Binomial Distribution................................... 17 7 Continuous Distributions 17 7.1 Normal or Gaussian Distribution.................................. 17 1 7.2 Uniform Distribution......................................... 18 7.3 The Exponential Density...................................... 18 7.4 The Gamma Density......................................... 18 8 Variable Transformations 19 9 Distribution Functions and the Quantile Transform 20 10 Joint Densities 22 11 Joint Densities under Transformations 23 11.1 Detour to Convolutions...................................... -

Random Variables and Applications
Random Variables and Applications OPRE 6301 Random Variables. As noted earlier, variability is omnipresent in the busi- ness world. To model variability probabilistically, we need the concept of a random variable. A random variable is a numerically valued variable which takes on different values with given probabilities. Examples: The return on an investment in a one-year period The price of an equity The number of customers entering a store The sales volume of a store on a particular day The turnover rate at your organization next year 1 Types of Random Variables. Discrete Random Variable: — one that takes on a countable number of possible values, e.g., total of roll of two dice: 2, 3, ..., 12 • number of desktops sold: 0, 1, ... • customer count: 0, 1, ... • Continuous Random Variable: — one that takes on an uncountable number of possible values, e.g., interest rate: 3.25%, 6.125%, ... • task completion time: a nonnegative value • price of a stock: a nonnegative value • Basic Concept: Integer or rational numbers are discrete, while real numbers are continuous. 2 Probability Distributions. “Randomness” of a random variable is described by a probability distribution. Informally, the probability distribution specifies the probability or likelihood for a random variable to assume a particular value. Formally, let X be a random variable and let x be a possible value of X. Then, we have two cases. Discrete: the probability mass function of X specifies P (x) P (X = x) for all possible values of x. ≡ Continuous: the probability density function of X is a function f(x) that is such that f(x) h P (x < · ≈ X x + h) for small positive h. -

Elliptical Symmetry
Elliptical symmetry Abstract: This article first reviews the definition of elliptically symmetric distributions and discusses identifiability issues. It then presents results related to the corresponding characteristic functions, moments, marginal and conditional distributions, and considers the absolutely continuous case. Some well known instances of elliptical distributions are provided. Finally, inference in elliptical families is briefly discussed. Keywords: Elliptical distributions; Mahalanobis distances; Multinormal distributions; Pseudo-Gaussian tests; Robustness; Shape matrices; Scatter matrices Definition Until the 1970s, most procedures in multivariate analysis were developed under multinormality assumptions, mainly for mathematical convenience. In most applications, however, multinormality is only a poor approximation of reality. In particular, multinormal distributions do not allow for heavy tails, that are so common, e.g., in financial data. The class of elliptically symmetric distributions extends the class of multinormal distributions by allowing for both lighter-than-normal and heavier-than-normal tails, while maintaining the elliptical geometry of the underlying multinormal equidensity contours. Roughly, a random vector X with elliptical density is obtained as the linear transformation of a spherically distributed one Z| namely, a random vector with spherical equidensity contours, the distribution of which is invariant under rotations centered at the origin; such vectors always can be represented under the form Z = RU, where -

UNIT NUMBER 19.4 PROBABILITY 4 (Measures of Location and Dispersion)
“JUST THE MATHS” UNIT NUMBER 19.4 PROBABILITY 4 (Measures of location and dispersion) by A.J.Hobson 19.4.1 Common types of measure 19.4.2 Exercises 19.4.3 Answers to exercises UNIT 19.4 - PROBABILITY 4 MEASURES OF LOCATION AND DISPERSION 19.4.1 COMMON TYPES OF MEASURE We include, here three common measures of location (or central tendency), and one common measure of dispersion (or scatter), used in the discussion of probability distributions. (a) The Mean (i) For Discrete Random Variables If the values x1, x2, x3, . , xn of a discrete random variable, x, have probabilities P1,P2,P3,....,Pn, respectively, then Pi represents the expected frequency of xi divided by the total number of possible outcomes. For example, if the probability of a certain value of x is 0.25, then there is a one in four chance of its occurring. The arithmetic mean, µ, of the distribution may therefore be given by the formula n X µ = xiPi. i=1 (ii) For Continuous Random Variables In this case, it is necessary to use the probability density function, f(x), for the distribution which is the rate of increase of the probability distribution function, F (x). For a small interval, δx of x-values, the probability that any of these values occurs is ap- proximately f(x)δx, which leads to the formula Z ∞ µ = xf(x) dx. −∞ (b) The Median (i) For Discrete Random Variables The median provides an estimate of the middle value of x, taking into account the frequency at which each value occurs.