Statistical Arbitrage on the KOSPI 200: an Exploratory Analysis of Classification and Prediction Machine Learning Algorithms for Day Trading
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
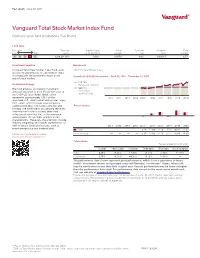
Vanguard Total Stock Market Index Fund
Fact sheet | June 30, 2021 Vanguard® Vanguard Total Stock Market Index Fund Domestic stock fund | Institutional Plus Shares Fund facts Risk level Total net Expense ratio Ticker Turnover Inception Fund Low High assets as of 04/29/21 symbol rate date number 1 2 3 4 5 $269,281 MM 0.02% VSMPX 8.0% 04/28/15 1871 Investment objective Benchmark Vanguard Total Stock Market Index Fund seeks CRSP US Total Market Index to track the performance of a benchmark index that measures the investment return of the Growth of a $10,000 investment : April 30, 2015—D ecember 31, 2020 overall stock market. $20,143 Investment strategy Fund as of 12/31/20 The fund employs an indexing investment $20,131 approach designed to track the performance of Benchmark the CRSP US Total Market Index, which as of 12/31/20 represents approximately 100% of the 2011 2012 2013 2014 2015* 2016 2017 2018 2019 2020 investable U.S. stock market and includes large-, mid-, small-, and micro-cap stocks regularly traded on the New York Stock Exchange and Annual returns Nasdaq. The fund invests by sampling the index, meaning that it holds a broadly diversified collection of securities that, in the aggregate, approximates the full Index in terms of key characteristics. These key characteristics include industry weightings and market capitalization, as well as certain financial measures, such as Annual returns 2011 2012 2013 2014 2015* 2016 2017 2018 2019 2020 price/earnings ratio and dividend yield. Fund — — — — -3.28 12.69 21.19 -5.15 30.82 21.02 For the most up-to-date fund data, Benchmark — — — — -3.29 12.68 21.19 -5.17 30.84 20.99 please scan the QR code below. -
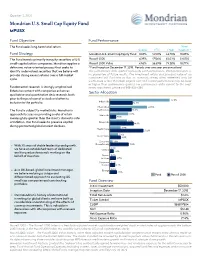
Current Fact Sheet
Quarter 2, 2021 Mondrian U.S. Small Cap Equity Fund MPUSX Fund Objective Fund Performance The Fund seeks long-term total return. Since Quarter YTD 1 Year Inception * Fund Strategy Mondrian U.S. Small Cap Equity Fund 0.65%14.50% 44.76% 10.85% The Fund invests primarily in equity securities of U.S. Russell 2000 4.29%17.54% 62.03% 23.05% small-capitalization companies. Mondrian applies a Russell 2000 Value 4.56%26.69% 73.28% 18.77% defensive, value-oriented process that seeks to * Fund Inception December 17, 2018. Periods over one year are annualized identify undervalued securities that we believe will The performance data quoted represents past performance. Past performance is provide strong excess returns over a full market no guarantee of future results. The investment return and principal value of an cycle. investment will fluctuate so that an investor's shares, when redeemed, may be worth more or less than their original cost and current performance may be lower or higher than performance quoted. For performance data current to the most Fundamental research is strongly emphasized. recent month end, please call 888-832-4386. Extensive contact with companies enhances Sector Allocation qualitative and quantitative desk research, both prior to the purchase of a stock and after its 37.9% Industrials inclusion in the portfolio. 14.3% Information 23.6% The Fund is subject to market risks. Mondrian’s Technology 13.6% 11.8% approach focuses on providing a rate of return Materials meaningfully greater than the client’s domestic rate 3.8% 11.1% of inflation. -

Bank of Japan's Exchange-Traded Fund Purchases As An
ADBI Working Paper Series BANK OF JAPAN’S EXCHANGE-TRADED FUND PURCHASES AS AN UNPRECEDENTED MONETARY EASING POLICY Sayuri Shirai No. 865 August 2018 Asian Development Bank Institute Sayuri Shirai is a professor of Keio University and a visiting scholar at the Asian Development Bank Institute. The views expressed in this paper are the views of the author and do not necessarily reflect the views or policies of ADBI, ADB, its Board of Directors, or the governments they represent. ADBI does not guarantee the accuracy of the data included in this paper and accepts no responsibility for any consequences of their use. Terminology used may not necessarily be consistent with ADB official terms. Working papers are subject to formal revision and correction before they are finalized and considered published. The Working Paper series is a continuation of the formerly named Discussion Paper series; the numbering of the papers continued without interruption or change. ADBI’s working papers reflect initial ideas on a topic and are posted online for discussion. Some working papers may develop into other forms of publication. Suggested citation: Shirai, S.2018.Bank of Japan’s Exchange-Traded Fund Purchases as an Unprecedented Monetary Easing Policy.ADBI Working Paper 865. Tokyo: Asian Development Bank Institute. Available: https://www.adb.org/publications/boj-exchange-traded-fund-purchases- unprecedented-monetary-easing-policy Please contact the authors for information about this paper. Email: [email protected] Asian Development Bank Institute Kasumigaseki Building, 8th Floor 3-2-5 Kasumigaseki, Chiyoda-ku Tokyo 100-6008, Japan Tel: +81-3-3593-5500 Fax: +81-3-3593-5571 URL: www.adbi.org E-mail: [email protected] © 2018 Asian Development Bank Institute ADBI Working Paper 865 S. -

Monthly Economic Update
In this month’s recap: Stocks moved higher as investors looked past accelerating inflation and the Fed’s pivot on monetary policy. Monthly Economic Update Presented by Ray Lazcano, July 2021 U.S. Markets Stocks moved higher last month as investors looked past accelerating inflation and the Fed’s pivot on monetary policy. The Dow Jones Industrial Average slipped 0.07 percent, but the Standard & Poor’s 500 Index rose 2.22 percent. The Nasdaq Composite led, gaining 5.49 percent.1 Inflation Report The May Consumer Price Index came in above expectations. Prices increased by 5 percent for the year-over-year period—the fastest rate in nearly 13 years. Despite the surprise, markets rallied on the news, sending the S&P 500 to a new record close and the technology-heavy Nasdaq Composite higher.2 Fed Pivot The Fed indicated that two interest rate hikes in 2023 were likely, despite signals as recently as March 2021 that rates would remain unchanged until 2024. The Fed also raised its inflation expectations to 3.4 percent, up from its March projection of 2.4 percent. This news unsettled 3 the markets, but the shock was short-lived. News-Driven Rally In the final full week of trading, stocks rallied on the news of an agreement regarding the $1 trillion infrastructure bill and reports that banks had passed the latest Federal Reserve stress tests. Sector Scorecard 07072021-WR-3766 Industry sector performance was mixed. Gains were realized in Communication Services (+2.96 percent), Consumer Discretionary (+3.22 percent), Energy (+1.92 percent), Health Care (+1.97 percent), Real Estate (+3.28 percent), and Technology (+6.81 percent). -

Vanguard Total Stock Market Index Fund
Fact sheet | June 30, 2021 Vanguard® Vanguard Total Stock Market Index Fund Domestic stock fund | Institutional Shares Fund facts Risk level Total net Expense ratio Ticker Turnover Inception Fund Low High assets as of 04/29/21 symbol rate date number 1 2 3 4 5 $227,984 MM 0.03% VITSX 8.0% 07/07/97 0855 Investment objective Benchmark Vanguard Total Stock Market Index Fund seeks Spliced Total Stock Market Index to track the performance of a benchmark index that measures the investment return of the Growth of a $10,000 investment : January 31, 2011—D ecember 31, 2020 overall stock market. $35,603 Investment strategy Fund as of 12/31/20 The fund employs an indexing investment $35,628 approach designed to track the performance of Benchmark the CRSP US Total Market Index, which as of 12/31/20 represents approximately 100% of the 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 investable U.S. stock market and includes large-, mid-, small-, and micro-cap stocks regularly traded on the New York Stock Exchange and Annual returns Nasdaq. The fund invests by sampling the index, meaning that it holds a broadly diversified collection of securities that, in the aggregate, approximates the full Index in terms of key characteristics. These key characteristics include industry weightings and market capitalization, as well as certain financial measures, such as Annual returns 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 price/earnings ratio and dividend yield. Fund 1.09 16.42 33.49 12.56 0.42 12.67 21.17 -5.16 30.81 21.00 For the most up-to-date fund data, Benchmark 1.08 16.44 33.51 12.58 0.40 12.68 21.19 -5.17 30.84 20.99 please scan the QR code below. -

Download Download
The Journal of Applied Business Research – September/October 2017 Volume 33, Number 5 The Effect Of Corporate Governance On Unfaithful Disclosure Designation And Unfaithful Disclosure Penalty Points Bo Young Moon, Dankook University, South Korea Soo Yeon Park, Korea University, South Korea ABSTRACT This paper investigates the relation between Unfaithful Disclosure Corporations (“UDC”) and corporate governance using listed firm (KOSPI and KOSDAQ) data in Korea. Prior literature reports that corporate governance has an impact on the level of disclosure and the quality of disclosure provided by companies. However, it is hard to find the studies about corporate governance and UDC at the term of disclosure quality. Compare to some financially advanced countries, Korea established corporate governance in a relatively short period of time; hence concerns have been raised the corporate governance have not played effective role to monitor management. We question how corporate governance affects companies’ unfaithful disclosure by using several corporate governance proxy variables and UDC data which is unique system in Korea. From the empirical tests, we find a negative association between the proportion of outside directors, an indicator of the board’s independence, and UDC designation, among companies listed on both KOSPI and KOSDAQ. On the other hand, there is a significant positive association between the proportion of outside directors and UDCs’ imposed and accumulated penalty points among KOSDAQ-listed companies. This implies that outside director system effectively play a monitoring role however due to different natures of members included in outside directors, the system often fails to control regarding based reasons for penalty points imposition. In addition, we find the percentage of foreign equity ownership showed statistically significant positive association with UDC designation and a significant positive association with the imposed and accumulated penalty points among KOSPI-listed companies. -

Does the Market React Differently to Chaebol Firms?
The Journal of Applied Business Research – September/October 2014 Volume 30, Number 5 Does The Market React Differently To Chaebol Firms? Heejin Park, Hanyang University, South Korea Jinsoo Kim, Hanyang University, South Korea Mihye Ha, Hanyang University, South Korea Sambock Park, Hanyang University, South Korea ABSTRACT Based on a sample of Korean firms listed on the KOSPI and KOSDAQ from 2001 to 2011, we examined whether the affiliation of a firm with a Chaebol group affects the sensitivity of stock prices to earnings surprises. We found that the market response to positive (negative) earnings surprises is more positive (negative) for Chaebol firms than for non-Chaebol firms. In addition, we investigated how intra-group transactions affect the ERCs of Chaebol firms by comparing with those of non-Chaebol firms. Our results show that the intra-group transactions of Chaebol firms are positively related to ERCs under both positive and negative earnings surprises. However, we did not find the same results from the analyses of non-Chaebol firms. Keywords: Chaebol Firms; Earnings Response Coefficient (ERC); Earnings Surprises; KOSPI; KOSDAQ 1. INTRODUCTION he aim of this study is to examine how differently the market reacts to earnings surprises of Chaebol firms compared to those of non-Chaebol firms. Although there is no official definition of Chaebol, T firms are perceived as Chaebol if they consist of a large group and operate in many different industries, maintain substantial business ties with other firms in their group, and are controlled by the largest shareholder as a whole. The definition used to identify Chaebol firms is that of a large business group established by the Korea Fair Trade Commission (KFTC) and a group of companies of which more than 30% of the shares are owned by the group’s controlling shareholders and its affiliated companies. -

Investing in the Marketplace
Investing in the Marketplace Prudential Retirement When you hear people talk about “the market,” you might think Did you know... we agree on what that means. Truth is, there are many indexes that represent differing segments of the market. And these …there is even indexes don’t always move in tandem. Understanding some of an index that the key ones can help you diversify your investments to better represent the economy as a whole. purports to track The Dow Jones Industrial Average (The Dow) is one of the oldest, most investor anxiety? well-know indexes and is often used to represent the economy as a Dubbed “The Fear whole. Truth is, though, The Dow only includes 30 stocks of the world’s largest, most influential companies. Why is it called an “average?” Index,” the proper Originally, it was computed by adding up the per-share price of its stocks, and dividing by the number of companies. name of the Chicago The Standard & Poor’s 500 Index (made up of 500 of the most widely- Board Options traded U.S. stocks) is larger and more diverse than The Dow. Because it represents about 70% of the total value of the U.S. stock market, the Exchange’s index is S&P 500 is a better indication of how the U.S. marketplace is moving as a whole. the VIX Index, Sometimes referred to as the “total stock market index,” the Wilshire and measures the 5000 Index includes about 7,000 of the more than 10,000 publicly traded companies with headquarters in the U.S. -
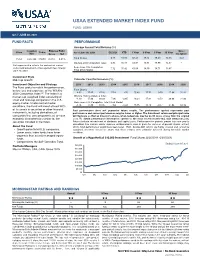
USAA Extended Market Index Fund Fact Sheet
USAA EXTENDED MARKET INDEX FUND FUND: USMIX Q2 // JUNE 30, 2021 FUND FACTS PERFORMANCE Average Annual Total Returns (%) Inception Expense Ratio: Since Class Ticker As of June 30, 2021 Q2 2021 YTD 1 Year 3 Year 5 Year 10 Year Date Gross Net Inception Fund Shares 6.71 15.83 62.43 18.33 18.49 13.55 9.33 Fund 10/27/00 USMIX 0.42% 0.42% Wilshire 4500 Completion Index 6.83 16.11 63.07 18.81 18.99 14.32 – Net expense ratio reflects the contractual waiver Dow Jones U.S. Completion and/or reimbursement of management fees through 7.12 15.42 61.60 18.50 18.71 13.87 – June 30, 2023. Total Stock Market Investment Style Mid-Cap Growth Calendar Year Performance (%) Investment Objective and Strategy 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 The Fund seeks to match the performance, before fees and expenses, of the Wilshire Fund Shares -4.03 17.47 37.26 7.18 -3.76 15.48 17.72 -9.70 27.94 31.20 4500 Completion IndexSM. The Index is a market cap-weighted index consisting of Wilshire 4500 Completion Index -4.10 17.99 38.39 7.96 -2.65 17.84 -9.53 28.06 31.99 small and mid-cap companies in the U.S. 18.54 equity market. Under normal market Dow Jones U.S. Completion Total Stock Market conditions, the Fund will invest at least 80% -3.76 17.89 38.05 7.63 -3.42 15.75 18.12 -9.57 27.94 32.16 of its assets in securities or other financial Past performance does not guarantee future results. -
For Additional Information
April 2015 Attached please find the updated Foreign Listed Stock Index Futures and Options Approvals Chart, current as of April 2015. All prior versions are superseded and should be discarded. Please note the following developments since we last distributed the Approvals Chart: (1) The CFTC has approved the following contracts for trading by U.S. Persons: (i) Singapore Exchange Derivatives Trading Limited’s futures contract based on the MSCI Malaysia Index; (ii) Osaka Exchange’s futures contract based on the JPX-Nikkei Index 400; (iii) ICE Futures Europe’s futures contract based on the MSCI World Index; (iv) Eurex’s futures contracts based on the Euro STOXX 50 Variance Index, MSCI Frontier Index and TA-25 Index; (v) Mexican Derivatives Exchange’s mini futures contract based on the IPC Index; (vi) Australian Securities Exchange’s futures contract based on the S&P/ASX VIX Index; and (vii) Moscow Exchange’s futures contract based on the MICEX Index. (2) The SEC has not approved any new foreign equity index options since we last distributed the Approvals Chart. However, the London Stock Exchange has claimed relief under the LIFFE A&M and Class Relief SEC No-Action Letter (Jul. 1, 2013) to offer Eligible Options to Eligible U.S. Institutions. See note 16. For Additional Information The information on the attached Approvals Chart is subject to change at any time. If you have questions or would like confirmation of the status of a specific contract, please contact: James D. Van De Graaff +1.312.902.5227 [email protected] Kenneth M. -

September 2020
From the desk of GS Wealth Management MONTHLY ECONOMIC UPDATE September 2020 MONTHLY QUOTE “You’ve got to get up every morning with THE MONTH IN BRIEF determination if you are going to go to bed with satisfaction.” U.S. Markets Stock prices surged in August as investors cheered positive news of a - George Lorimer potential COVID-19 treatment and welcomed a month-long succession of upbeat economic data. The Dow Jones Industrial Average rose 7.57 percent, the Standard & Poor’s 500 Index climbed 7.01 percent, and the Nasdaq Composite soared 9.59 MONTHLY TIP 1 percent. If you have a son or daughter graduating from college next Solid Foundation year, remind them to try and build an emergency fund. The month’s foundation was set by a series of strong economic reports, Those with the least including an increase in manufacturing activity, better-than-anticipated seniority can be the factory orders, and a lessening of new jobless claims.2,3,4 first to be laid off in the workplace, and sometimes that first Notching Highs job after college doesn’t work out. The S&P 500 index finally broke through resistance, ending the third week of August at a record high and completing the fastest bear market recovery in history. The Nasdaq Composite, having set multiple record highs during 5,6 the same week, also ended the month at a record high. Strong Close to the Month The final full week of trading was remarkable. Investors were encouraged by news of a potential COVID-19 treatment and a report suggesting U.S. -

Mr. Alp Eroglu International Organization of Securities Commissions (IOSCO) Calle Oquendo 12 28006 Madrid Spain
1301 Second Avenue tel 206-505-7877 www.russell.com Seattle, WA 98101 fax 206-505-3495 toll-free 800-426-7969 Mr. Alp Eroglu International Organization of Securities Commissions (IOSCO) Calle Oquendo 12 28006 Madrid Spain RE: IOSCO FINANCIAL BENCHMARKS CONSULTATION REPORT Dear Mr. Eroglu: Frank Russell Company (d/b/a “Russell Investments” or “Russell”) fully supports IOSCO’s principles and goals outlined in the Financial Benchmarks Consultation Report (the “Report”), although Russell respectfully suggests several alternative approaches in its response below that Russell believes will better achieve those goals, strengthen markets and protect investors without unduly burdening index providers. Russell is continuously raising the industry standard for index construction and methodology. The Report’s goals accord with Russell’s bedrock principles: • Index providers’ design standards must be objective and sound; • Indices must provide a faithful and unbiased barometer of the market they represent; • Index methodologies should be transparent and readily available free of charge; • Index providers’ operations should be governed by an appropriate governance structure; and • Index providers’ internal controls should promote efficient and sound index operations. These are all principles deeply ingrained in Russell’s heritage, practiced daily and they guide Russell as the premier provider of indices and multi-asset solutions. Russell is a leader in constructing and maintaining securities indices and is the publisher of the Russell Indexes. Russell operates through subsidiaries worldwide and is a subsidiary of The Northwestern Mutual Life Insurance Company. The Russell Indexes are constructed to provide a comprehensive and unbiased barometer of the market segment they represent. All of the Russell Indexes are reconstituted periodically, but not less frequently than annually or more frequently than monthly, to ensure new and growing equities and fixed income securities are reflected in its indices.