1 Transition from MAC Address to IP Address
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Spanning Tree Protocol by George Thomas, Contemporary Controls
Volume6•Issue5 SEPTEMBER–OCTOBER 2005 © 2005 Contemporary Control Systems, Inc. Introduction to Spanning Tree Protocol By George Thomas, Contemporary Controls Introduction powered and its memory cleared (Bridge 2 will be added later). In an industrial automation application that relies heavily Station 1 sends a message to on the health of the Ethernet network that attaches all the station 11 followed by Station 2 controllers and computers together, a concern exists about sending a message to Station 11. what would happen if the network fails? Since cable failure is These messages will traverse the the most likely mishap, cable redundancy is suggested by bridge from one LAN to the configuring the network in either a ring or by carrying parallel other. This process is called branches. If one of the segments is lost, then communication “relaying” or “forwarding.” The will continue down a parallel path or around the unbroken database in the bridge will note portion of the ring. The problem with these approaches is the source addresses of Stations that Ethernet supports neither of these topologies without 1 and 2 as arriving on Port A. This special equipment. However, this issue is addressed in an process is called “learning.” When IEEE standard numbered 802.1D that covers bridges, and in Station 11 responds to either this standard the concept of the Spanning Tree Protocol Station 1 or 2, the database will (STP) is introduced. note that Station 11 is on Port B. IEEE 802.1D If Station 1 sends a message to Figure 1. The addition of Station 2, the bridge will do ANSI/IEEE Std 802.1D, 1998 edition addresses the Bridge 2 creates a loop. -
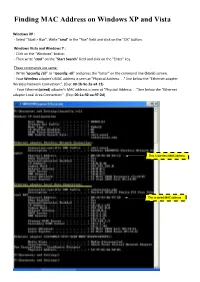
Finding MAC Address on Windows XP and Vista
Finding MAC Address on Windows XP and Vista Windows XP : - Select "Start > Run". Write "cmd" in the "Run" field and click on the "OK" button. Windows Vista and Windows 7 : - Click on the "Windows" button. - Then write "cmd" on the "Start Search" field and click on the "Enter" key. These commands are same: - Write "ipconfig /all" or "ipconfig -all" and press the "Enter" on the command line (blank) screen. - Your Wireless adapter’s MAC address is seen at "Physical Address. ." line below the “Ethernet adapter Wireless Network Connection:”. (Exp: 00-1b-9e-2a-a4-13) - Your Ethernet(wired) adapter's MAC address is seen at "Physical Address. ." line below the “Ethernet adapter Local Area Connection:”. (Exp: 00-1a-92-aa-97-2d) This is wireless MAC address This is wired MAC address Finding MAC Address on Linux root@test:/ > ifconfig –a eth0 Link encap:Ethernet HWaddr 00:01:02:AE:9A:85 <----- This is wired MAC address inet addr:10.92.52.10 Bcast:10.92.255.255 Mask:255.255.248.0 inet6 addr: fe80::1:2ae:9a85/10 Scope:Link inet6 addr: fe80::201:2ff:feae:9a85/10 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 wlan0 Link encap:Ethernet HWaddr 00:01:02:AE:9A:95 <----- This is wireless MAC address inet addr:10.80.2.94 Bcast:10.80.255.255 Mask:255.255.252.0 inet6 addr: fe80::1:2ae:9a95/10 Scope:Link inet6 addr: fe80::201:2ff:feae:9a95/10 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Finding MAC Address on Macintosh OS 10.1 - 10.4 Please note: Wired and Wireless MAC addresses are different. -

Ipv6 Addresses
56982_CH04II 12/12/97 3:34 PM Page 57 CHAPTER 44 IPv6 Addresses As we already saw in Chapter 1 (Section 1.2.1), the main innovation of IPv6 addresses lies in their size: 128 bits! With 128 bits, 2128 addresses are available, which is ap- proximately 1038 addresses or, more exactly, 340.282.366.920.938.463.463.374.607.431.768.211.456 addresses1. If we estimate that the earth’s surface is 511.263.971.197.990 square meters, the result is that 655.570.793.348.866.943.898.599 IPv6 addresses will be available for each square meter of earth’s surface—a number that would be sufficient considering future colo- nization of other celestial bodies! On this subject, we suggest that people seeking good hu- mor read RFC 1607, “A View From The 21st Century,” 2 which presents a “retrospective” analysis written between 2020 and 2023 on choices made by the IPv6 protocol de- signers. 56982_CH04II 12/12/97 3:34 PM Page 58 58 Chapter Four 4.1 The Addressing Space IPv6 designers decided to subdivide the IPv6 addressing space on the ba- sis of the value assumed by leading bits in the address; the variable-length field comprising these leading bits is called the Format Prefix (FP)3. The allocation scheme adopted is shown in Table 4-1. Table 4-1 Allocation Prefix (binary) Fraction of Address Space Allocation of the Reserved 0000 0000 1/256 IPv6 addressing space Unassigned 0000 0001 1/256 Reserved for NSAP 0000 001 1/128 addresses Reserved for IPX 0000 010 1/128 addresses Unassigned 0000 011 1/128 Unassigned 0000 1 1/32 Unassigned 0001 1/16 Aggregatable global 001 -

Attacking the Spanning Tree Protocol
C H A P T E R 3 Attacking the Spanning Tree Protocol Radia Perlman, a distinguished engineer at Sun Microsystems, named as one of the 20 most influential people in the industry in the 25th anniversary issue of Data Communications magazine and the original inventor of the 802.1D spanning-tree specification recently had a few words to say about the protocol: “It’s time to redo (one of the Internet’s most widely used technologies) in a way that is more robust and gives more efficient paths.”1 Introducing Spanning Tree Protocol Chapter 2, “Defeating a Learning Bridge’s Forwarding Process,” explained how Ethernet switches build their forwarding tables by learning source MAC addresses from data traffic. When an Ethernet frame arrives on a switch port in VLAN X with a destination MAC address for which there is no entry in the forwarding table, the switch floods the frame. That is, it sends a copy of the frame to every single port in VLAN X (except the port that originally received the frame). Although this is perfectly fine in a single-switch environment, interesting side effects are observed in multiswitch topologies, as Figure 3-1 shows. The figure represents a simple network composed of two LAN switches interconnected by two Ethernet links. 44 Chapter 3: Attacking the Spanning Tree Protocol Figure 3-1 Basic Network Setup MAC-address 0000.0000.000A 0/1 A B All Interfaces Are Switch 1 in VLAN 5 Link Y Link X Switch 2 0/2 MAC-address 0000.0000.000B In the next steps, MAC addresses are conveniently shortened to a single-letter format for clarity. -
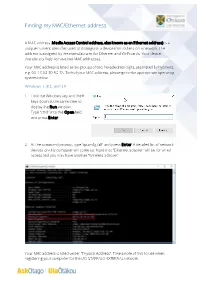
Finding My MAC/Ethernet Address
Finding my MAC/Ethernet address A MAC address (Media Access Control address, also known as an Ethernet address) is a unique numeric identifier used to distinguish a device from others on a network. The address is assigned by the manufacturer for Ethernet and Wi-Fi cards. Your device therefore is likely to have two MAC addresses. Your MAC address is listed as six groups of two hexadecimal digits, separated by hyphens, e.g. 00-13-02-80-92-7A. To find your MAC address, please go to the appropriate operating system below. Windows 7, 8.1, and 10 1. Hold the Windows key and the R keys down at the same time to display the Run window. Type "cmd" into the Open field and press Enter. 2. At the command prompt, type "ipconfig /all" and press Enter. A detailed list of network devices on this computer will come up. Note that "Ethernet adapter" will be for wired access and you may have another "Wireless adapter". Your MAC address is listed under "Physical Address". Take a note of this to use when registering your computer for the UO-STAFF/UO-EXTERNAL network. Mac OS X 1. From the Apple drop-down menu open System Preferences and click on Network. 2. If you want to register for wired access, select Ethernet from the list on the left. 3. Click the Advanced… button and select the Hardware tab to see the MAC address for your Ethernet card. 4. If you need to register for wireless access, click Cancel then select Wi-Fi from the list on the left. -

1.2. OSI Model
1.2. OSI Model The OSI model classifies and organizes the tasks that hosts perform to prepare data for transport across the network. You should be familiar with the OSI model because it is the most widely used method for understanding and talking about network communications. However, remember that it is only a theoretical model that defines standards for programmers and network administrators, not a model of actual physical layers. Using the OSI model to discuss networking concepts has the following advantages: Provides a common language or reference point between network professionals Divides networking tasks into logical layers for easier comprehension Allows specialization of features at different levels Aids in troubleshooting Promotes standards interoperability between networks and devices Provides modularity in networking features (developers can change features without changing the entire approach) However, you must remember the following limitations of the OSI model: OSI layers are theoretical and do not actually perform real functions. Industry implementations rarely have a layer‐to‐layer correspondence with the OSI layers. Different protocols within the stack perform different functions that help send or receive the overall message. A particular protocol implementation may not represent every OSI layer (or may spread across multiple layers). To help remember the layer names of the OSI model, try the following mnemonic devices: Mnemonic Mnemonic Layer Name (Bottom to top) (Top to bottom) Layer 7 Application Away All Layer 6 Presentation Pizza People Layer 5 Session Sausage Seem Layer 4 Transport Throw To Layer 3 Network Not Need Layer 2 Data Link Do Data Layer 1 Physical Please Processing Have some fun and come up with your own mnemonic for the OSI model, but stick to just one so you don't get confused. -

High-Speed Internet Connection Guide Welcome
High-Speed Internet Connection Guide Welcome Welcome to Suddenlink High-Speed Internet Thank you for choosing Suddenlink as your source for quality home entertainment and communications! There is so much to enjoy with Suddenlink High-Speed Internet including: + Easy self-installation + WiFi@Home availability + Easy access to your Email + Free access to Watch ESPN This user guide will help you get up and running in an instant. If you have any other questions about your service please visit help.suddenlink.com or contact our 24/7 technical support. Don’t forget to register online for a Suddenlink account at suddenlink.net for great features and access to email, billing statements, Suddenlink2GO® and more! 1 Table of Contents Connecting Your High Speed Internet Connecting Your High-Speed Internet Your Suddenlink Self-Install Kit includes Suddenlink Self-Install Kit ..................................................................................... 3 Connecting your computer to a Suddenlink modem ....................................... 4 the following items: Connecting a wireless router or traditional router to Suddenlink ................. 5 Getting Started Microsoft Windows XP or Higher ......................................................................... 6 Cable Modem Power Adapter Mac OS X ................................................................................................................. 6 Register Your Account Online ................................................................................7 Suddenlink WiFi@Home -

CM500 High Speed Cable Modem User Manual
High Speed Cable Modem Model CM500 User Manual January 2017 202-11477-05 350 East Plumeria Drive San Jose, CA 95134 USA CM500 High Speed Cable Modem Support Thank you for purchasing this NETGEAR product. You can visit www.netgear.com/support to register your product, get help, access the latest downloads and user manuals, and join our community. We recommend that you use only official NETGEAR support resources. If you are experiencing trouble installing your cable modem, contact NETGEAR at 1-866-874-8924. If you are experiencing trouble connecting your router, contact the router manufacturer. Conformity For the current EU Declaration of Conformity, visit http://kb.netgear.com/app/answers/detail/a_id/11621. Compliance For regulatory compliance information, visit http://www.netgear.com/about/regulatory. See the regulatory compliance document before connecting the power supply. Trademarks © NETGEAR, Inc., NETGEAR and the NETGEAR Logo are trademarks of NETGEAR, Inc. Any non-NETGEAR trademarks are used for reference purposes only. 2 Contents Chapter 1 Hardware and Internet Setup Unpack Your Cable Modem . 5 Front Panel . 5 Back Panel. 6 Product Label . 7 Install and Activate Your Cable Modem . 7 Connect Your Cable Modem to a Computer. 7 Activate Your Internet Service . 9 Perform a Speed Test . 10 Connect Your Cable Modem to a Router After Installation and Activation . 11 Chapter 2 Manage and Monitor Log In to the Cable Modem . 13 View Cable Modem Initialization. 13 View Cable Modem Status. 14 View and Clear Event Logs. 15 Change the admin Password . 16 Reboot the Cable Modem . 17 Reset the Cable Modem to Factory Default Settings . -

Back to the Future: Revisiting Ipv6 Privacy Extensions
Back to the Future: Revisiting IPv6 Privacy Extensions DAVID BARRERA, GLENN WURSTER, AND P.C. VAN OORSCHOT David Barrera is a PhD Network stacks on most operating systems are configured by default to use the student in computer science interface MAC address as part of the IPv6 address . This allows adversaries to at Carleton University under track systems as they roam between networks . The proposed solution to this prob- the direction of Paul Van lem—IPv6 privacy extensions—suffers from design and implementation issues Oorschot. His research interests include that limit its potential benefits . Our solution creates a more usable and configu- network security, data visualization, and rable approach to IPv6 privacy extensions that helps protect users from being smartphone security. tracked . [email protected] With more people adopting IPv6, some features of the protocol are slowly being explored by a small user-base . Security issues related to IP packet fragmentation Glenn Wurster completed and malicious route headers [4] have been identified, and new RFCs addressing his PhD in computer science those issues have been published (e .g ,. RFC 5095 and RFC 5722) . Over many years, (2010) at Carleton University the iterative process of identifying flaws and creating fixes led to IPv4 becoming a under the direction of Paul stable and mature protocol . Since IPv6 is much newer and only now being broadly Van Oorschot. His interests include software deployed, many of its features have not enjoyed broad testing or security analysis . security, system administration, operating In this article we concentrate on one such feature: IPv6 privacy extensions . systems, and Web security. -

Spanning Tree (STP) Feature Overview and Configuration Guide
Technical Guide Spanning Tree Protocols: STP, RSTP, and MSTP FEATURE OVERVIEW AND CONFIGURATION GUIDE Introduction This guide describes and provides configuration procedures for: Spanning Tree Protocol (STP) Rapid Spanning Tree Protocol (RSTP) Multiple Spanning Tree Protocol (MSTP) For detailed information about the commands used to configure spanning trees, see the switch’s Command Reference on our website at alliedtelesis.com. Products and software version that apply to this guide This guide applies to AlliedWare Plus™ products that support STP, RSTP and/or MSTP, running version 5.4.4 or later. However, support varies between products. To see whether a product supports a particular feature or command, see the following documents: The product’s Datasheet The AlliedWare Plus Datasheet The product’s Command Reference These documents are available from the above links on our website at alliedtelesis.com. Feature support may change in later software versions. For the latest information, see the above documents. C613-22026-00 REV A alliedtelesis.com x Introduction Content Introduction.............................................................................................................................................................................1 Products and software version that apply to this guide .......................................................................1 Overview of Spanning Trees..........................................................................................................................................3 -

Tracking Anonymized Bluetooth Devices
Proceedings on Privacy Enhancing Technologies ..; .. (..):1–17 Johannes K Becker*, David Li, and David Starobinski Tracking Anonymized Bluetooth Devices Abstract: Bluetooth Low Energy (BLE) devices use regularly broadcasted in the clear, leading to major pri- public (non-encrypted) advertising channels to an- vacy concerns over the possibility of unwanted track- nounce their presence to other devices. To prevent track- ing [3]. This was addressed in the Bluetooth Core Spec- ing on these public channels, devices may use a peri- ification 4.0 with the introduction of the Bluetooth Low odically changing, randomized address instead of their Energy (BLE) standard also known as Bluetooth Smart. permanent Media Access Control (MAC) address. In BLE allows device manufacturers to use temporary ran- this work we show that many state-of-the-art devices dom addresses in over-the-air communication instead of which are implementing such anonymization measures their permanent address to prevent tracking [4]. How- are vulnerable to passive tracking that extends well be- ever, these anonymization features are defined in a way yond their address randomization cycles. We show that that leaves a certain degree of flexibility to manufactur- it is possible to extract identifying tokens from the pay- ers. The optionality of such privacy protecting features load of advertising messages for tracking purposes. We is of special relevance, as the BLE standard was de- present an address-carryover algorithm which exploits signed specifically to support low-energy devices such as the asynchronous nature of payload and address changes smart watches and other wearable devices, which are an to achieve tracking beyond the address randomization of attractive target for adversarial tracking of their users. -

1.7 Link-Layer Addressing
ROHINI COLLEGE OF ENGINEERING &TECHNOLOGY 1.7 LINK-LAYER ADDRESSING A link-layer address is called a link address, called a physical address, and sometimes a MAC address. Since a link is controlled at the data-link layer, the addresses need to belong to the data-link layer. When a datagram passes from the network layer to the data-link layer,the datagram will be encapsulated in a frame and two data-link addresses are added to the frame header.These two addresses are changed every time the frame moves from one link to another. Figure 1.7.1 shows, IP addresses and link-layer addresses in a small internet. This is easy to understand. Fig1.7.1: IP addresses and link-layer addresses in a small internet. [Source :”Data Communications and Networking” by Behrouz A. Forouzan,Page-243] Here we have three links and two routers. We have two hosts: Alice (source) and Bob (destination). For each host, we have shown two addresses, the IP addresses (N) and the link-layer addresses (L). EC8551 COMMUNICATION NETWORKS ROHINI COLLEGE OF ENGINEERING &TECHNOLOGY We have three frames, one in each link.Each frame carries the same datagram with the same source and destination addresses (N1 and N8), but the link-layer addresses of the frame change from link to link. In link 1, the link-layer addresses are L1 and L2. In link 2, they are L4 and L5. In link 3, they are L7 and L8. Note that the IP addresses and the link-layer addresses are not in the same order.