Advanced-R.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Advanced R Second Edition Chapman & Hall/CRC the R Series Series Editors John M
Advanced R Second Edition Chapman & Hall/CRC The R Series Series Editors John M. Chambers, Department of Statistics, Stanford University, California, USA Torsten Hothorn, Division of Biostatistics, University of Zurich, Switzerland Duncan Temple Lang, Department of Statistics, University of California, Davis, USA Hadley Wickham, RStudio, Boston, Massachusetts, USA Recently Published Titles Testing R Code Richard Cotton R Primer, Second Edition Claus Thorn Ekstrøm Flexible Regression and Smoothing: Using GAMLSS in R Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda De Bastiani The Essentials of Data Science: Knowledge Discovery Using R Graham J. Williams blogdown: Creating Websites with R Markdown Yihui Xie, Alison Presmanes Hill, Amber Thomas Handbook of Educational Measurement and Psychometrics Using R Christopher D. Desjardins, Okan Bulut Displaying Time Series, Spatial, and Space-Time Data with R, Second Edition Oscar Perpinan Lamigueiro Reproducible Finance with R Jonathan K. Regenstein, Jr. R Markdown The Definitive Guide Yihui Xie, J.J. Allaire, Garrett Grolemund Practical R for Mass Communication and Journalism Sharon Machlis Analyzing Baseball Data with R, Second Edition Max Marchi, Jim Albert, Benjamin S. Baumer Spatio-Temporal Statistics with R Christopher K. Wikle, Andrew Zammit-Mangion, and Noel Cressie Statistical Computing with R, Second Edition Maria L. Rizzo Geocomputation with R Robin Lovelace, Jakub Nowosad, Jannes Münchow Dose-Response Analysis with R Christian Ritz, Signe M. Jensen, Daniel Gerhard, Jens C. Streibig Advanced R, Second Edition Hadley Wickham For more information about this series, please visit: https://www.crcpress.com/go/ the-r-series Advanced R Second Edition Hadley Wickham CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 2019 by Taylor & Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. -

Supplementary Materials
Tomic et al, SIMON, an automated machine learning system reveals immune signatures of influenza vaccine responses 1 Supplementary Materials: 2 3 Figure S1. Staining profiles and gating scheme of immune cell subsets analyzed using mass 4 cytometry. Representative gating strategy for phenotype analysis of different blood- 5 derived immune cell subsets analyzed using mass cytometry in the sample from one donor 6 acquired before vaccination. In total PBMC from healthy 187 donors were analyzed using 7 same gating scheme. Text above plots indicates parent population, while arrows show 8 gating strategy defining major immune cell subsets (CD4+ T cells, CD8+ T cells, B cells, 9 NK cells, Tregs, NKT cells, etc.). 10 2 11 12 Figure S2. Distribution of high and low responders included in the initial dataset. Distribution 13 of individuals in groups of high (red, n=64) and low (grey, n=123) responders regarding the 14 (A) CMV status, gender and study year. (B) Age distribution between high and low 15 responders. Age is indicated in years. 16 3 17 18 Figure S3. Assays performed across different clinical studies and study years. Data from 5 19 different clinical studies (Study 15, 17, 18, 21 and 29) were included in the analysis. Flow 20 cytometry was performed only in year 2009, in other years phenotype of immune cells was 21 determined by mass cytometry. Luminex (either 51/63-plex) was performed from 2008 to 22 2014. Finally, signaling capacity of immune cells was analyzed by phosphorylation 23 cytometry (PhosphoFlow) on mass cytometer in 2013 and flow cytometer in all other years. -

The Split-Apply-Combine Strategy for Data Analysis
JSS Journal of Statistical Software April 2011, Volume 40, Issue 1. http://www.jstatsoft.org/ The Split-Apply-Combine Strategy for Data Analysis Hadley Wickham Rice University Abstract Many data analysis problems involve the application of a split-apply-combine strategy, where you break up a big problem into manageable pieces, operate on each piece inde- pendently and then put all the pieces back together. This insight gives rise to a new R package that allows you to smoothly apply this strategy, without having to worry about the type of structure in which your data is stored. The paper includes two case studies showing how these insights make it easier to work with batting records for veteran baseball players and a large 3d array of spatio-temporal ozone measurements. Keywords: R, apply, split, data analysis. 1. Introduction What do we do when we analyze data? What are common actions and what are common mistakes? Given the importance of this activity in statistics, there is remarkably little research on how data analysis happens. This paper attempts to remedy a very small part of that lack by describing one common data analysis pattern: Split-apply-combine. You see the split-apply- combine strategy whenever you break up a big problem into manageable pieces, operate on each piece independently and then put all the pieces back together. This crops up in all stages of an analysis: During data preparation, when performing group-wise ranking, standardization, or nor- malization, or in general when creating new variables that are most easily calculated on a per-group basis. -

Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 Views · More Stats
12/15/2017 Hadley Wickham, the Man Who Revolutionized R Hadley Wickham, the Man Who Revolutionized R · 51,321 views · More stats Share https://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/ 1/10 12/15/2017 Hadley Wickham, the Man Who Revolutionized R “Fundamentally learning about the world through data is really, really cool.” ~ Hadley Wickham, prolific R developer *** If you don’t spend much of your time coding in the open-source statistical programming language R, his name is likely not familiar to you -- but the statistician Hadley Wickham is, in his own words, “nerd famous.” The kind of famous where people at statistics conferences line up for selfies, ask him for autographs, and are generally in awe of him. “It’s utterly utterly bizarre,” he admits. “To be famous for writing R programs? It’s just crazy.” Wickham earned his renown as the preeminent developer of packages for R, a programming language developed for data analysis. Packages are programming tools that simplify the code necessary to complete common tasks such as aggregating and plotting data. He has helped millions of people become more efficient at their jobs -- something for which they are often grateful, and sometimes rapturous. The packages he has developed are used by tech behemoths like Google, Facebook and Twitter, journalism heavyweights like the New York Times and FiveThirtyEight, and government agencies like the Food and Drug Administration (FDA) and Drug Enforcement Administration (DEA). Truly, he is a giant among data nerds. *** Born in Hamilton, New Zealand, statistics is the Wickham family business: His father, Brian Wickham, did his PhD in the statistics heavy discipline of Animal Breeding at Cornell University and his sister has a PhD in Statistics from UC Berkeley. -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

Data Analysis in R
Data Analysis in R Course at a Glance This course will provide an introduction to reproducible data analysis with R (see Syllabus). Instructor Gabriel Baud-Bovy ([email protected] ) Credits: 5 Synopsis This course aims at giving to the student a methodology to analyze experimental results, from how to organize data to the writing of a report. It includes: an introduction to R an introduction to reproducible research with R examples of statistical analysis with R During this course, the student will have to analyze his own data and is expected to read before each course the material that will be made available on this page. The final grade will consist in the evaluation of a report demonstrating familiarity with the concepts and methods presented in the course. As an editor, the instructor will use Notepad++ (together with NppToR) on a Windows Machines but the student might use other ones (e.g., R studio, EMACS+ESS, Lyx, TexWork). The course will use Mardown as typesetting language. For those desirous to work with Latex and/or generate pdf, you will need to install also MikeTex. Syllabus Total of 15 hours Class 1: Case study, Reproducible research Class 2: R fundamental Class 3: Exploratory data analysis and graphical methods in R Class 4: Basic statistics Class 5: To be determined There will be a final examination decided by the instructor. Prerequisites The course assumes some familiarity with programming concepts and data structures (MATLAB, C/C++, Java or any other programming language). Contact the instructor if you have never programmed anything. -

Changes on CRAN 2014-07-01 to 2014-12-31
NEWS AND NOTES 192 Changes on CRAN 2014-07-01 to 2014-12-31 by Kurt Hornik and Achim Zeileis New packages in CRAN task views Bayesian BayesTree. Cluster fclust, funFEM, funHDDC, pgmm, tclust. Distributions FatTailsR, RTDE, STAR, predfinitepop, statmod. Econometrics LinRegInteractive, MSBVAR, nonnest2, phtt. Environmetrics siplab. Finance GCPM, MSBVAR, OptionPricing, financial, fractal, riskSimul. HighPerformanceComputing GUIProfiler, PGICA, aprof. MachineLearning BayesTree, LogicForest, hdi, mlr, randomForestSRC, stabs, vcrpart. MetaAnalysis MAVIS, ecoreg, ipdmeta, metaplus. NumericalMathematics RootsExtremaInflections, Rserve, SimplicialCubature, fastGHQuad, optR. OfficialStatistics CoImp, RecordLinkage, rworldmap, tmap, vardpoor. Optimization RCEIM, blowtorch, globalOptTests, irace, isotone, lbfgs. Phylogenetics BAMMtools, BoSSA, DiscML, HyPhy, MPSEM, OutbreakTools, PBD, PCPS, PHYLOGR, RADami, RNeXML, Reol, Rphylip, adhoc, betapart, dendextend, ex- pands, expoTree, jaatha, kdetrees, mvMORPH, outbreaker, pastis, pegas, phyloTop, phyloland, rdryad, rphast, strap, surface, taxize. Psychometrics IRTShiny, PP, WrightMap, mirtCAT, pairwise. ReproducibleResearch NMOF. Robust TEEReg, WRS2, robeth, robustDA, robustgam, robustloggamma, robustreg, ror, rorutadis. Spatial PReMiuM. SpatioTemporal BayesianAnimalTracker, TrackReconstruction, fishmove, mkde, wildlifeDI. Survival DStree, ICsurv, IDPSurvival, MIICD, MST, MicSim, PHeval, PReMiuM, aft- gee, bshazard, bujar, coxinterval, gamboostMSM, imputeYn, invGauss, lsmeans, multipleNCC, paf, penMSM, spBayesSurv, -

R Programming for Data Science
R Programming for Data Science Roger D. Peng This book is for sale at http://leanpub.com/rprogramming This version was published on 2015-07-20 This is a Leanpub book. Leanpub empowers authors and publishers with the Lean Publishing process. Lean Publishing is the act of publishing an in-progress ebook using lightweight tools and many iterations to get reader feedback, pivot until you have the right book and build traction once you do. ©2014 - 2015 Roger D. Peng Also By Roger D. Peng Exploratory Data Analysis with R Contents Preface ............................................... 1 History and Overview of R .................................... 4 What is R? ............................................ 4 What is S? ............................................ 4 The S Philosophy ........................................ 5 Back to R ............................................ 5 Basic Features of R ....................................... 6 Free Software .......................................... 6 Design of the R System ..................................... 7 Limitations of R ......................................... 8 R Resources ........................................... 9 Getting Started with R ...................................... 11 Installation ............................................ 11 Getting started with the R interface .............................. 11 R Nuts and Bolts .......................................... 12 Entering Input .......................................... 12 Evaluation ........................................... -

Thesis Entire.Pdf (12.90Mb)
Faculty OF Science AND TECHNOLOGY Department OF Computer Science TOWARD ReprODUCIBLE Analysis AND ExplorATION OF High-ThrOUGHPUT Biological Datasets — Bjørn Fjukstad A DISSERTATION FOR THE DEGREE OF Philosophiae Doctor – 2018 This thesis document was typeset using the UiT Thesis LaTEX Template. © 2018 – http://github.com/egraff/uit-thesis “Ta aldri problemene på forskudd, for da får du dem to ganger, men ta gjerne seieren på forskudd, for hvis ikke er det altfor sjelden du får oppleve den.” –Ivar Tollefsen AbstrACT There is a rapid growth in the number of available biological datasets due to the advent of high-throughput data collection instruments combined with cheap compute infrastructure. Modern instruments enable the analysis of biological data at different levels, from small DNA sequences through larger cell structures, and up to the function of entire organs. These new datasets have brought the need to develop new software packages to enable novel insights into the underlying biological mechanisms in the development and progression of diseases such as cancer. The heterogeneity of biological datasets require researchers to tailor the explo- ration and analyses with a wide range of different tools and systems. However, despite the need for their integration, few of them provide standard inter- faces for analyses implemented using different programming languages and frameworks. In addition, because of the many tools, different input parame- ters, and references to databases, it is necessary to record these correctly. The lack of such details complicates reproducing the original results and the reuse of the analyses on new datasets. This increases the analysis time and leaves unrealized potential for scientific insights. -

Language-Agnostic Data Analysis Workflows and Reproducible Research
Language-agnostic data analysis workflows and reproducible research Andrew John Lowe 28 April 2017 Abstract This is the abstract for a document that briefly describes methods for interacting with different programming languages within the same data analysis workflow. 0.1 Overview • This talk: language-agnostic (or polyglot) analysis workflows • I’ll show how it is possible to work in multiple languages and switch between them without leaving the workflow you started • Additionally, I’ll demonstrate how an entire workflow can be encapsulated in a markdown file that is rendered to a publishable paper with cross-references and a bibliography (and with raw a LATEX file produced as a by-product) in a simple process, making the whole analysis workflow reproducible 0.2 Which tool/language is best? • TMVA, scikit-learn, h2o, caret, mlr, WEKA, Shogun, . • C++, Python, R, Java, MATLAB/Octave, Julia, . • Many languages, environments and tools • People may have strong opinions • A false polychotomy? • Be a polyglot! 0.3 Approaches • Save-and-load • Language-specific bindings • Notebook • knitr 1 Save-and-load approach 1.1 Flat files • Language agnostic • Formats like text, CSV, and JSON are well-supported • Breaks workflow • Data types may not be preserved (e.g., datetime, NULL) • New binary format Feather solves this 1 1.2 Feather Feather: A fast on-disk format for data frames for R and Python, powered by Apache Arrow, developed by Wes McKinney and Hadley Wickham # In R: library(feather) path <- "my_data.feather" write_feather(df, path) # In Python: import feather -
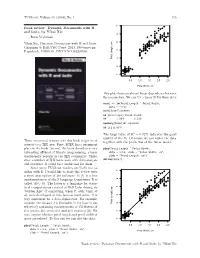
Dynamic Documents with R and Knitr, by Yihui Xie 116 Tugboat, Volume 35 (2014), No
TUGboat, Volume 35 (2014), No. 1 115 ● ● ● Book review: Dynamic Documents with R ● ● ● and knitr, by Yihui Xie ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Boris Veytsman ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Yihui Xie, Dynamic Documents with R and knitr. ● ● ● ● ● ● ● ● ● ● ● ● ● ● Chapman & Hall/CRC Press, 2013, 190+xxvi pp. ● ● ● ● ● ● ● ● ● US$ ISBN ● Paperback, 59.95. 978-1482203530. ● ● ● ● Petal Length, cm Petal ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 6 7 0.5 1.0 1.5 2.0 2.5 Petal Width, cm This plot shows an almost linear dependence between the parameters. We can try a linear fit for these data: model <- lm(Petal.Length ˜ Petal.Width, data = iris) model$coefficients ## (Intercept) Petal.Width ## 1.084 2.230 summary(model)$r.squared ## [1] 0.9271 The large value of R2 = 0.9271 indicates the good quality of the fit. Of course we can replot the data There are several reasons why this book might be of together with the prediction of the linear model: interest to a TEX user. First, LATEX has a prominent place in the book. Second, the book describes a very plot(Petal.Length ˜ Petal.Width, interesting offshoot of literate programming, a topic data = iris, xlab = "Petal Width, cm", traditionally popular in the TEX community. Third, ylab = "Petal Length, cm") abline(model) since a number of TEX users work with data analysis and statistics, R could be a useful tool for them. Since some TUGboat readers are likely not fa- ● ● ● miliar with R, I would like to start this review with ● ● a short description of the software. R [1] is a free ● ● ● ● ● ● ● ● ● ● ● implementation of the S language (sometimes R is ● ● ● ● ● ● ● ● ● ● ● ● ● ● called GNU S). -

LYX and Knitr
knitr.1 LYX and knitr The knitr package allows one to embed R code within LYX and LATEX documents. When a document is compiled into a PDF, LYX/LATEX connects to R to run the R code and the code/output is automatically put into the PDF. In addition to this being a convenient way to use both LYX/LATEX with R, it also provides an important component to the reproducibility of research (RR). For example, one can include the code for a data analysis de- scribed in a paper. This ensures that there would be no “copying and pasting errors” and also provide readers of the paper an im- mediate way to reproduce the research. RR continues to become more important and fortunately more tools are being developed to make it possible. Below are some discussions on the topic: • AMSTAT News column on RR at http://magazine. amstat.org/blog/2011/01/01/scipolicyjan11. • CRAN task view for RR and R at http://cran.r-project. org/web/views/ReproducibleResearch.html. • Yihui Xie: Author of knitr – First and second editions of his Dynamic Documents with R and knitr book. Note that this book was typed in LYX. – Website for knitr at http://yihui.name/knitr The Sweave environment is another way to include R code inside of LYX/LATEX. This was developed prior to knitr, but it is more difficult to use. The purpose of this section is to examine the main compo- nents of knitr so that you will be able to complete the rest of the semester using LYX and knitr together for all assign- ments in our course! Also, a very important purpose is to give you the tools needed to complete all assignments in other R- based courses by using knitr and LYX together! The files used knitr.2 here are intro_example_cereal.lyx, intro_example_cereal.pdf, cereal.csv, ExternalCode.R, FirstBeamer-knitr.zip, JSM2015.zip, and RMarkdown.zip.