Efficient Ensemble Data Assimilation for Coupled Models with the Parallel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ocean Circulation Models and Modeling
2512-5 Fundamentals of Ocean Climate Modelling at Global and Regional Scales (Hyderabad - India) 5 - 14 August 2013 Ocean Circulation Models and Modeling GRIFFIES Stephen Princeton University U.S. Department of Commerce N.O.A.A., Geophysical Fluid Dynamics Laboratory, 201 Forrestal Road, Forrestal Campus P.O. Box 308, 08542-6649 Princeton NJ U.S.A. 5.1: Ocean Circulation Models and Modeling Stephen.Griffi[email protected] NOAA/Geophysical Fluid Dynamics Laboratory Princeton, USA [email protected] Laboratoire de Physique des Oceans,´ LPO Brest, France Draft from May 24, 2013 1 5.1.1. Scope of this chapter 2 We focus in this chapter on numerical models used to understand and predict large- 3 scale ocean circulation, such as the circulation comprising basin and global scales. It 4 is organized according to two themes, which we consider the “pillars” of numerical 5 oceanography. The first addresses physical and numerical topics forming a foundation 6 for ocean models. We focus here on the science of ocean models, in which we ask 7 questions about fundamental processes and develop the mathematical equations for 8 ocean thermo-hydrodynamics. We also touch upon various methods used to represent 9 the continuum ocean fluid with a discrete computer model, raising such topics as the 10 finite volume formulation of the ocean equations; the choice for vertical coordinate; 11 the complementary issues related to horizontal gridding; and the pervasive questions 12 of subgrid scale parameterizations. The second theme of this chapter concerns the 13 applications of ocean models, in particular how to design an experiment and how to 14 analyze results. -

UNIVERSITY of CALIFORNIA Los Angeles Exploring the Wind-Driven
UNIVERSITY OF CALIFORNIA Los Angeles Exploring the Wind-Driven Near-Antarctic Circulation A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Atmospheric and Oceanic Sciences by Julia Eileen Hazel 2019 c Copyright by Julia Eileen Hazel 2019 ABSTRACT OF THE DISSERTATION Exploring the Wind-Driven Near-Antarctic Circulation by Julia Eileen Hazel Doctor of Philosophy in Atmospheric and Oceanic Sciences University of California, Los Angeles, 2019 Professor Andrew Leslie Stewart, Chair The circulation at the margins of Antarctica closes the meridional overturning circulation, venti- lating the abyssal ocean with 02 and modulating deep CO2 storage on millennial timescales. This circulation also mediates the melt rates of Antarctica’s floating ice shelves, and thereby exerts a strong influence on future global sea level rise. The near-Antarctic circulation has been hypothe- sized to respond sensitively to changes in the easterly winds that encircle the Antarctic coastline. In particular, the easterlies may be expected to weaken in response to the ongoing strengthening and poleward shifting of the mid-latitude westerlies, associated with a trend toward the positive index of the Southern Annular Mode (SAM). However, multi-decadal changes in the easterlies have not been systematically quantified, and previous studies have yielded limited insight into the oceanic response to such changes. In this work we first quantify multi-decadal changes in wind forcing of the near-Antarctic ocean using a suite of reanalysis products that compare favorably with local meteorological mea- surements. Contrary to expectations, we find that the circumpolar-averaged easterly wind stress has not weakened over the past 3-4 decades, and if anything has slightly strengthened. -
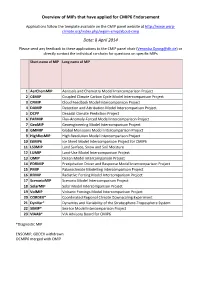
Overview of Mips That Have Applied for CMIP6 Endorsement Date: 8
Overview of MIPs that have applied for CMIP6 Endorsement Applications follow the template available on the CMIP panel website at http://www.wcrp‐ climate.org/index.php/wgcm‐cmip/about‐cmip Date: 8 April 2014 Please send any feedback to these applications to the CMIP panel chair ([email protected]) or directly contact the individual co‐chairs for questions on specific MIPs Short name of MIP Long name of MIP 1 AerChemMIP Aerosols and Chemistry Model Intercomparison Project 2 C4MIP Coupled Climate Carbon Cycle Model Intercomparison Project 3 CFMIP Cloud Feedback Model Intercomparison Project 4 DAMIP Detection and Attribution Model Intercomparison Project 5 DCPP Decadal Climate Prediction Project 6 FAFMIP Flux‐Anomaly‐Forced Model Intercomparison Project 7 GeoMIP Geoengineering Model Intercomparison Project 8 GMMIP Global Monsoons Model Intercomparison Project 9 HighResMIP High Resolution Model Intercomparison Project 10 ISMIP6 Ice Sheet Model Intercomparison Project for CMIP6 11 LS3MIP Land Surface, Snow and Soil Moisture 12 LUMIP Land‐Use Model Intercomparison Project 13 OMIP Ocean Model Intercomparison Project 14 PDRMIP Precipitation Driver and Response Model Intercomparison Project 15 PMIP Palaeoclimate Modelling Intercomparison Project 16 RFMIP Radiative Forcing Model Intercomparison Project 17 ScenarioMIP Scenario Model Intercomparison Project 18 SolarMIP Solar Model Intercomparison Project 19 VolMIP Volcanic Forcings Model Intercomparison Project 20 CORDEX* Coordinated Regional Climate Downscaling Experiment 21 DynVar* Dynamics -

Challenges and Prospects in Ocean Circulation Models
Challenges and Prospects in Ocean Circulation Models The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Fox-Kemper, Baylor, et al. “Challenges and Prospects in Ocean Circulation Models.” Frontiers in Marine Science 6 (February 2019): 65. © The Authors As Published http://dx.doi.org/10.3389/fmars.2019.00065 Publisher Frontiers Media SA Version Final published version Citable link https://hdl.handle.net/1721.1/125142 Terms of Use Creative Commons Attribution 4.0 International license Detailed Terms https://creativecommons.org/licenses/by/4.0/ REVIEW published: 26 February 2019 doi: 10.3389/fmars.2019.00065 Challenges and Prospects in Ocean Circulation Models Baylor Fox-Kemper 1*, Alistair Adcroft 2,3, Claus W. Böning 4, Eric P. Chassignet 5, Enrique Curchitser 6, Gokhan Danabasoglu 7, Carsten Eden 8, Matthew H. England 9, Rüdiger Gerdes 10,11, Richard J. Greatbatch 4, Stephen M. Griffies 2,3, Robert W. Hallberg 2,3, Emmanuel Hanert 12, Patrick Heimbach 13, Helene T. Hewitt 14, Christopher N. Hill 15, Yoshiki Komuro 16, Sonya Legg 2,3, Julien Le Sommer 17, Simona Masina 18, Simon J. Marsland 9,19,20, Stephen G. Penny 21,22,23, Fangli Qiao 24, Todd D. Ringler 25, Anne Marie Treguier 26, Hiroyuki Tsujino 27, Petteri Uotila 28 and Stephen G. Yeager 7 1 Department of Earth, Environmental, and Planetary Sciences, Brown University, Providence, RI, United States, 2 Atmospheric and Oceanic Sciences Program, Princeton University, Princeton, NJ, United States, 3 NOAA Geophysical -

Meteorology and Oceanography of the Atlantic Sector of the Southern Ocean—A Review of German Achievements from the Last Decade
Ocean Dynamics DOI 10.1007/s10236-016-0988-1 Meteorology and oceanography of the Atlantic sector of the Southern Ocean—a review of German achievements from the last decade Hartmut H. Hellmer1 & Monika Rhein2 & Günther Heinemann3 & Janna Abalichin4 & Wafa Abouchami5 & Oliver Baars6 & Ulrich Cubasch4 & Klaus Dethloff7 & Lars Ebner3 & Eberhard Fahrbach1 & Martin Frank8 & Gereon Gollan8 & Richard J. Greatbatch8 & Jens Grieger4 & Vladimir M. Gryanik1,9 & Micha Gryschka10 & Judith Hauck1 & Mario Hoppema1 & Oliver Huhn2 & Torsten Kanzow1 & Boris P. Koch1 & Gert König-Langlo1 & Ulrike Langematz4 & Gregor C. Leckebusch11 & Christof Lüpkes1 & Stephan Paul3 & Annette Rinke7 & Bjoern Rost1 & Michiel Rutgers van der Loeff1 & Michael Schröder1 & Gunther Seckmeyer10 & Torben Stichel 12 & Volker Strass 1 & Ralph Timmermann1 & Scarlett Trimborn 1 & Uwe Ulbrich4 & Celia Venchiarutti13 & Ulrike Wacker1 & Sascha Willmes 3 & Dieter Wolf-Gladrow1 Received: 18 March 2016 /Accepted: 29 August 2016 # The Author(s) 2016. This article is published with open access at Springerlink.com Abstract In the early 1980s, Germany started a new era of German universities and the AWI as well as other institutes in- modern Antarctic research. The Alfred Wegener Institute volved in polar research. Here, we review the main findings in Helmholtz Centre for Polar and Marine Research (AWI) was meteorology and oceanography of the last decade, funded by the founded and important research platforms such as the German priority program. The paper presents field observations and permanent station in Antarctica, today called Neumayer III, and modelling efforts, extending from the stratosphere to the deep the research icebreaker Polarstern were installed. The research ocean. The research spans a large range of temporal and spatial primarily focused on the Atlantic sector of the Southern Ocean. -

Arctic ECRA Strategy and Work Plan
Arctic ECRA Strategy and Work Plan “Advancing European Arctic climate research for the benefit of society” www.ecra-climate.eu Version: 19.06.2014 EXECUTIVE SUMMARY The Arctic climate is changing at a rate, which takes many people – including climate scientists – by surprise. The ongoing and anticipated changes provide vast economic opportunities; but at the same time they pose significant threats to the environment. Important decisions will need to be made in the coming years which take into account economic, societal and environmental issues. In this context, a reliable knowledge base, on which decisions can be based, is a prerequisite to provide sustainable solutions. It is increasingly being recognised that what happens in the Arctic does not stay in the Arctic. A prominent example is the proposed atmospheric link between Arctic sea ice decline and the severity of cold European winters. Therefore, Arctic climate change is likely to affect the weather and climate of Europe. It is argued that gaps in our scientific understanding and predictive capabilities are still hampering the evidence-based decision-making processes by stakeholders. There is an urgent need to accelerate progress in building a reliable knowledge base, and it is recommended that the EU funds collaborative research that aims to provide answers to the following three central issues: Why is Arctic sea ice disappearing so rapidly? What are the local and global impacts of Arctic climate change? How to advance environmental prediction capabilities for the Arctic and beyond? Arctic ECRA is one of four Collaborative Programmes of the European Climate Research Alliance (ECRA). It aims to advance Arctic climate research for the benefit of society by raising awareness of key scientific challenges, carrying out coordinated research activities using existing resources, and writing joint proposals to secure external funding for coordinated, cutting-edge European polar research and education projects. -

Ice Flow Modelling of Ice Shelves and Ice Caps
ICE FLOW MODELLING OF ICE SHELVES AND ICE CAPS Yongmei Gong ACADEMIC DISSERTATION IN GEOPHYSICS To be presented, with the permission of the Faculty of Science of the University of Helsinki for public criticism in Auditorium CK112 of Exactum, Gustaf Hällströmin katu 2 b, on February 13rd, 2018, at 12 o´clock noon. ISBN 978-951-51-4043-2 (paperback) ISBN 978-951-51-4044-9 (PDF) ISSN 0355-8630 Helsinki 2018 Unigrafia Abstract Ice shelves and ice caps constitute a great proportion of the glacial ice mass that covers 10% of the global land surface and is vulnerable to climate change. Large scale ice flow models are widely used to investigate the mechanisms behind the observed physical processes and predict their future stability and variability under climate change. This thesis aims at providing general remarks on the application of ice flow models in studying glaciological problems through investigating the evolution of an Antarctic ice shelf under climate change and the mechanisms of fast ice flowing events (surges) in an Arctic ice cap. In addition discussions of the equivalence of two significantly different expressions for the rate factor in Glen’s flow are also provided. Off-line coupling between the Lambert Glacier-Amery Ice Shelf (LG-AIS) drainage system, East Antarctica, and the climate system by employing a hierarchy of models from general circulation models, through high resolution regional atmospheric and oceanic models, to a vertically integrated ice flow model has been carried out. The adaptive mesh refinement technique is specifically implemented for resolving the problem concerning grounding line migration. -

Author Template for Journal Articles
Long term ocean simulations in FESOM: Evaluation and application in studying the impact of Greenland Ice Sheet melting Xuezhu Wang, Qiang Wang, Dmitry Sidorenko, Sergey Danilov, Jens Schröter, Thomas Jung Alfred Wegener Institute for Polar and Marine Research, Bremerhaven, 27568, Germany +49-471-4831-1855 +49-471-4831-1797 [email protected] Abstract The Finite Element Sea-ice Ocean Model (FESOM) is formulated on unstructured meshes and offers geometrical flexibility which is difficult to achieve on traditional structured grids. In this work the performance of FESOM in the North Atlantic and Arctic Ocean on large time scales is evaluated in a hindcast experiment. A water-hosing experiment is also conducted to study the model sensitivity to increased freshwater input from Greenland Ice Sheet (GrIS) melting in a 0.1 Sv discharge rate scenario. The variability of the Atlantic Meridional Overturning Circulation (AMOC) in the hindcast experiment can be explained by the variability of the thermohaline forcing over deep convection sites. The model also reproduces realistic freshwater content variability and sea ice extent in the Arctic Ocean. The anomalous freshwater in the water-hosing experiment leads to significant changes in the ocean circulation and local dynamical sea level (DSL). The most pronounced DSL rise is in the northwest North Atlantic as shown in previous studies, and also in the Arctic Ocean. The released GrIS freshwater mainly remains in the North Atlantic, Arctic Ocean and the west South Atlantic after 120 model years. The pattern of ocean freshening is similar to that of the GrIS water distribution, but changes in ocean circulation also contribute to the ocean salinity change. -

The Finite-Volume Sea Ice–Ocean Model (FESOM2)
Geosci. Model Dev., 10, 765–789, 2017 www.geosci-model-dev.net/10/765/2017/ doi:10.5194/gmd-10-765-2017 © Author(s) 2017. CC Attribution 3.0 License. The Finite-volumE Sea ice–Ocean Model (FESOM2) Sergey Danilov1,2, Dmitry Sidorenko1, Qiang Wang1, and Thomas Jung1 1Alfred Wegener Institute for Polar and Marine Research, Bremerhaven, Germany 2A. M. Obukhov Institute of Atmospheric Physics RAS, Moscow, Russia Correspondence to: Sergey Danilov ([email protected]) Received: 7 October 2016 – Discussion started: 24 October 2016 Revised: 20 December 2016 – Accepted: 21 December 2016 – Published: 17 February 2017 Abstract. Version 2 of the unstructured-mesh Finite-Element erle et al., 2016) indicate that the multi-resolution approach Sea ice–Ocean circulation Model (FESOM) is presented. It advocated by FESOM is successful and allows one to explore builds upon FESOM1.4 (Wang et al., 2014) but differs by its the impact of local processes on the global ocean with mod- dynamical core (finite volumes instead of finite elements), erate computational effort (see Sein et al., 2016). Other new and is formulated using the arbitrary Lagrangian Eulerian global multi-resolution models are appearing (see Ringler (ALE) vertical coordinate, which increases model flexibility. et al., 2013), and new knowledge on unstructured-mesh mod- The model inherits the framework and sea ice model from the eling has accumulated (for a review, see Danilov, 2013). Al- previous version, which minimizes the efforts needed from a though FESOM1.4 (Wang et al., 2014) already offers a very user to switch from one version to the other. The ocean states competitive throughput compared to structured-mesh mod- simulated with FESOM1.4 and FESOM2.0 driven by CORE- els in massively parallel applications (Sein et al., 2016), we II forcing are compared on a mesh used for the CORE-II in- continue to explore the ways to further increase the numeri- tercomparison project. -

Towards Multi‑Resolution Global Climate Modeling With
Clim Dyn DOI 10.1007/s00382-014-2290-6 Towards multi-resolution global climate modeling with ECHAM6–FESOM. Part I: model formulation and mean climate D. Sidorenko · T. Rackow · T. Jung · T. Semmler · D. Barbi · S. Danilov · K. Dethloff · W. Dorn · K. Fieg · H. F. Goessling · D. Handorf · S. Harig · W. Hiller · S. Juricke · M. Losch · J. Schröter · D. V. Sein · Q. Wang Received: 15 August 2013 / Accepted: 5 August 2014 © The Author(s) 2014. This article is published with open access at Springerlink.com Abstract A new climate model has been developed that shortcomings with other climate models when it comes to employs a multi-resolution dynamical core for the sea simulating the North Atlantic circulation. ice-ocean component. In principle, the multi-resolution approach allows one to use enhanced horizontal resolu- Keywords Multi-resolution model · Climate model · tion in dynamically active regions while keeping a coarse- Unstructured mesh · Finite elements · Climate model bias resolution setup otherwise. The coupled model consists of the atmospheric model ECHAM6 and the finite element sea ice-ocean model (FESOM). In this study only moder- 1 Introduction ate refinement of the unstructured ocean grid is applied and the resolution varies from about 25 km in the north- Climate models are used to simulate the climate system by ern North Atlantic and in the tropics to about 150 km in numerically solving the fundamental governing equations parts of the open ocean; the results serve as a benchmark on supercomputers. They are becoming more and more upon which future versions that exploit the potential of important to a wider group of users. -

Impact of Model Resolution on Arctic Sea Ice and North Atlantic Ocean Heat Transport
Climate Dynamics https://doi.org/10.1007/s00382-019-04840-y Impact of model resolution on Arctic sea ice and North Atlantic Ocean heat transport David Docquier1 · Jeremy P. Grist2 · Malcolm J. Roberts3 · Christopher D. Roberts3,4 · Tido Semmler5 · Leandro Ponsoni1 · François Massonnet1 · Dmitry Sidorenko5 · Dmitry V. Sein5,6 · Doroteaciro Iovino7 · Alessio Bellucci7 · Thierry Fichefet1 Received: 29 October 2018 / Accepted: 30 May 2019 © The Author(s) 2019 Abstract Arctic sea-ice area and volume have substantially decreased since the beginning of the satellite era. Concurrently, the pole- ward heat transport from the North Atlantic Ocean into the Arctic has increased, partly contributing to the loss of sea ice. Increasing the horizontal resolution of general circulation models (GCMs) improves their ability to represent the complex interplay of processes at high latitudes. Here, we investigate the impact of model resolution on Arctic sea ice and Atlantic Ocean heat transport (OHT) by using fve diferent state-of-the-art coupled GCMs (12 model confgurations in total) that include dynamic representations of the ocean, atmosphere and sea ice. The models participate in the High Resolution Model Intercomparison Project (HighResMIP) of the sixth phase of the Coupled Model Intercomparison Project (CMIP6). Model results over the period 1950–2014 are compared to diferent observational datasets. In the models studied, a fner ocean resolution drives lower Arctic sea-ice area and volume and generally enhances Atlantic OHT. The representation of ocean surface characteristics, such as sea-surface temperature (SST) and velocity, is greatly improved by using a fner ocean reso- lution. This study highlights a clear anticorrelation at interannual time scales between Arctic sea ice (area and volume) and ◦ Atlantic OHT north of 60 N in the models studied. -

Joint Regional Climate System Modelling for the European Sea Regions ENEA, Rome, Italy, 5- 6 November 2015 Programme, Abstracts, Participants Impressum
International Baltic Earth Secretariat Publication No. 7, October 2015 HyMex-Baltic Earth Workshop Joint regional climate system modelling for the European sea regions ENEA, Rome, Italy, 5- 6 November 2015 Programme, Abstracts, Participants Impressum International Baltic Earth Secretariat Publications ISSN 2198-4247 International Baltic Earth Secretariat Helmholtz-Zentrum Geesthacht GmbH Max-Planck-Str. 1 D-21502 Geesthacht, Germany www.baltic-earth.eu [email protected] Font cover, upper plot: Sea surface height in the Mediterranean Sea as reproduced by a hindcast simulation 1958-2004 (Sannino et al. 2014, Proceedings of the MedClivar Conference 2014 in Ankara, Turkey). Lower plot: Projected change in spring mean ensemble average sea surface height in the Baltic Sea by the end of the century (Meier et al. 2012, SMHI Report Oceanografi No112). Photo: The Colloseum at dusk (photo by David Iliff.; license CC-BY-SA 3.0) Inside plot: Map of SST warming at the end of the 21st century: minimum and maximum warming expected from an ensemble of scenario simulations (Adloff et al. 2015, Clim Dyn). Inside photo: The LION buoy, measuring air-sea exchanges in the Gulf of Lions, one of the deep water formation areas in the Mediterranean Sea (photo: Meteo-France) Table of Contents Introduction 1 Programme 3 Abstracts 9 Participants 99 International Baltic Earth Secretariat Publication Series 103 A HyMex-Baltic Earth Workshop Joint regional climate system modelling for the European sea regions ENEA, Rome, Italy 5-6 November 2015 Co-Organized by Scientific