Improving the Basics of GIS Students' Specialism by Means of Application
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Filariasis and Its Control in Fujian, China
REVIEW FILARIASIS AND ITS CONTROL IN FUJIAN, CHINA Liu ling-yuan, Liu Xin-ji, Chen Zi, Tu Zhao-ping, Zheng Guo-bin, Chen Vue-nan, Zhang Ying-zhen, Weng Shao-peng, Huang Xiao-hong and Yang Fa-zhu Fujian Provincial Institute of Parasitic Diseases, Fuzhou, Fujian, China. Abstract. Epidemiological survey of filariasis in Fujian Province, China showed that malayan filariasis, transmitted by Anopheles lesteri anthropophagus was mainly distributed in the northwest part and bancrof tian filariasis with Culex quinquefasciatus as vector, in middle and south coastal regions. Both species of filariae showed typical nocturnal periodicity. Involvement of the extremities was not uncommon in mala yan filariasis. In contrast, hydrocele was often present in bancroftian filariasis, in which limb impairment did not appear so frequently as in the former. Hetrazan treatment was administered to the microfilaremia cases identified during blood examination surveys, which were integrated with indoor residual spraying of insecticides in endemic areas of malayan filariasis when the vector mosquito was discovered and with mass treatment with hetrazan medicated salt in endemic areas of bancroft ian filariasis. At the same time the habitation condition was improved. These factors facilitated the decrease in incidence. As a result malayan and bancroftian filariasis were proclaimed to have reached the criterion of basic elimination in 1985 and 1987 respectively. Surveillance was pursued thereafter and no signs of resurgence appeared. DISCOVER Y OF FILARIASIS time: he found I male and 16 female adult filariae in retroperitoneallymphocysts and a lot of micro Fujian Province is situated between II S050' filariae in pulmonary capillaries and glomeruli at to 120°43' E and 23°33' to 28°19' N, on the south 8.30 am (Sasa, 1976). -

China's One Child Policy
Post Office Box 54401, San Jose, CA 95154, 310.592.5722 www.womensrightswithoutfrontiers.org China’s One Child Policy: New Evidence of Coercion Forced Abortion, Sterilization, Contraception And the Practice of “Implication” Reggie Littlejohn, President Women’s Rights Without Frontiers September 22, 2011 House Committee on Foreign Affairs, Subcommittee on Africa, Global Health, and Human Rights Women’s Rights Without Frontiers has obtained new documentation of coercive family planning in China. These thirteen cases were leaked out of China in an electronic document compiled by a source who has requested anonymity, for security reasons. This Chinese Author often pulled documentation off of the Internet. Predictably, some of the links on which these cases were posted have been removed. At other times the Chinese Author personally interviewed victims of coercion, at great risk to his personal safety. Biographical information about the Chinese Author can be found at the end of this report. What follows is a translation of these cases, set forth in reverse chronological order. We have presented these cases without commentary. They speak for themselves. For an analysis of the One-Child Policy, please see the testimony of Reggie Littlejohn, submitted simultaneously with this report. Ms. Littlejohn serves as China Aid Association’s expert on the One Child Policy. It is with great gratitude that Women’s Rights Without Frontiers acknowledges the substantial contributions China Aid made to this report. Case One: Family Planning Officials seize a woman for forced sterilization. When: September 12, 2009. Where: The west section of Beixin Street, Shangzhou District, Luoyang City, Henan Province Source: Eye-witness by the Chinese Author of this report As the witness described: Saturday, September 12, 2009 I saw a huge crowd of people moving forward in front of a cake shop when I walked in the west section of Beixin Street, Shangzhou District, Shangluo City, Henan Province. -

The Towers of Yue Olivia Rovsing Milburn Abstract This Paper
Acta Orientalia 2010: 71, 159–186. Copyright © 2010 Printed in Norway – all rights reserved ACTA ORIENTALIA ISSN 0001-6438 The Towers of Yue Olivia Rovsing Milburn Seoul National University Abstract This paper concerns the architectural history of eastern and southern China, in particular the towers constructed within the borders of the ancient non-Chinese Bai Yue kingdoms found in present-day southern Jiangsu, Zhejiang, Fujian and Guangdong provinces. The skills required to build such structures were first developed by Huaxia people, and hence the presence of these imposing buildings might be seen as a sign of assimilation. In fact however these towers seem to have acquired distinct meanings for the ancient Bai Yue peoples, particularly in marking a strong division between those groups whose ruling houses claimed descent from King Goujian of Yue and those that did not. These towers thus formed an important marker of identity in many ancient independent southern kingdoms. Keywords: Bai Yue, towers, architectural history, identity, King Goujian of Yue Introduction This paper concerns the architectural history of eastern and southern China, in particular the relics of the ancient non-Chinese kingdoms found in present-day southern Jiangsu, Zhejiang, Fujian and 160 OLIVIA ROVSING MILBURN Guangdong provinces. In the late Spring and Autumn period, Warring States era, and early Han dynasty these lands formed the kingdoms of Wu 吳, Yue 越, Minyue 閩越, Donghai 東海 and Nanyue 南越, in addition to the much less well recorded Ximin 西閩, Xiyue 西越 and Ouluo 甌駱.1 The peoples of these different kingdoms were all non- Chinese, though in the case of Nanyue (and possibly also Wu) the royal house was of Chinese origin.2 This paper focuses on one single aspect of the architecture of these kingdoms: the construction of towers. -

Xiamen International Bank Co., Ltd. 2018 Annual Report
Xiamen International Bank Co., Ltd. 2018 Annual Report 厦门国际银行股份有限公司 2018 年年度报告 Important Notice The Bank's Board of Directors, Board of Supervisors, directors, supervisors, and senior management hereby declare that this report does not contain any false records, misleading statements or material omissions, and they assume joint and individual responsibilities on the authenticity, accuracy and completeness of the information herein. The financial figures and indicators contained in this annual report compiled in accordance with China Accounting Standards, unless otherwise specified, are consolidated figures calculated based on domestic and overseas data in terms of RMB. Official auditor of the Bank, KPMG Hua Zhen LLP (special general partnership), conducted an audit on the 2018 Financial Statements of XIB compiled in accordance with China Accounting Standards, and issued a standard unqualified audit report. The Bank’s Chairman Mr. Weng Ruotong, Head of Accounting Affairs Ms. Tsoi Lai Ha, and Head of Accounting Department Mr. Zheng Bingzhang, hereby ensure the authenticity, accuracy and completeness of the financial report contained in this annual report. Notes on Major Risks: No major risks that can be predicted have been found by the Bank. During its operation, the key risks faced by the Bank include credit risks, market risks, operation risks, liquidity risks, compliance risks, country risks, information technology risks, and reputation risks, etc. The Bank has taken measures to effectively manage and control the various kinds of operational risks. For relevant information, please refer to Chapter 2, Discussion and Analysis of Business Conditions. Forward-looking Risk Statement: This Report involves several forward-looking statements about the financial position, operation performance and business development of the Bank, such as “will”, “may”, “strive”, “endeavor”, “plan to”, “goal” and other similar words used herein. -

Bid Invitation Announcement: Wind Turbine Foundation Construction
Bid Invitation Announcement Project Name: Wind Turbine Foundation Construction Project (section II) for Putian Pinghai Bay Offshore Wind Power Farm Phase II Project (hereinafter referred to as the “Project”). Tendering No.: PHWFD-II-ZB-025. 1. Bid invitation conditions Fujian Tendering Center Co., Ltd. (hereinafter referred to as "the Bidding Agency"), entrusted by Fujian Zhongmin Offshore Wind Power Co., Ltd. (hereinafter referred to as “the Tenderee”), now holds a public tendering for the Wind Turbine Foundation Construction Project (Section II) of the Putian Pinghai Bay Offshore Wind Power Farm Phase II Project for deciding contractors. The Project accepts the bids of eligible enterprises from the member contries of “BRICS”. 2. Project overview and tendering scope: 2.1 Project overview The Putian Pinghai Bay Offshore Wind Power Farm Phase II Project is situated in Pinghai Bay, Xiuyu District, Putian City. The project neighbors Daitou Peninsula on the west, Nanri Island on the north and Meizhou Island on the southwest. It is about 12km far from Pinghai Town and covers part areas of Zone B and Zone C of the Putian Pinghai Bay Offshore Wind Power Farm. A total of 41 sets of wind turbine generator units with an individual capacity of 6MW are proposed to be installed, including 20 sets in Zone B and 21 sets in Zone C. The total installed capacity will reach about 246MW. 2.2 Tendering scope: The tendering scope covers construction of foundation and ancillary facilities of 21 wind turbines in Area C. These include: Foundation construction and ancillary facilities installation for 21 wind turbines and engineering safety monitoring, special recording of vedios on all site construction processes of Phase II Projects (including Cormorant island Wharf, Booster Station, Phase II Marine Laying and Phase II Foundation Construction, etc.) , except the Basic construction and fan installation of I section and the installation of Phase II Wind Turbine . -

The Paradigm of Hakka Women in History
DOI: 10.4312/as.2021.9.1.31-64 31 The Paradigm of Hakka Women in History Sabrina ARDIZZONI* Abstract Hakka studies rely strongly on history and historiography. However, despite the fact that in rural Hakka communities women play a central role, in the main historical sources women are almost absent. They do not appear in genealogy books, if not for their being mothers or wives, although they do appear in some legends, as founders of villages or heroines who distinguished themselves in defending the villages in the absence of men. They appear in modern Hakka historiography—Hakka historiography is a very recent discipline, beginning at the end of the 19th century—for their moral value, not only for adhering to Confucian traditional values, but also for their endorsement of specifically Hakka cultural values. In this paper we will analyse the cultural paradigm that allows women to become part of Hakka history. We will show how ethical values are reflected in Hakka historiography through the reading of the earliest Hakka historians as they depict- ed Hakka women. Grounded on these sources, we will see how the narration of women in Hakka history has developed until the present day. In doing so, it is necessary to deal with some relevant historical features in the construc- tion of Hakka group awareness, namely migration, education, and women narratives, as a pivotal foundation of Hakka collective social and individual consciousness. Keywords: Hakka studies, Hakka woman, women practices, West Fujian Paradigma žensk Hakka v zgodovini Izvleček Študije skupnosti Hakka se močno opirajo na zgodovino in zgodovinopisje. -

High People's Court of Fujian Province Civil Judgement
High People's Court of Fujian Province Civil Judgement (2015) Min Min Zhong Zi No.2060 Appellant (defendant of the first instance): Xie Zhijin, Male, DOB: 10/27/1963, Han Chinese, Self-employed, residing in Cangshan District, Fuzhou, Fujian Appellant (defendant of the first instance): Ni Mingxiang, Male, DOB: 03/28/1965, Han Chinese, Farmer, residing in Fuqing, Fujian Appellant (defendant of the first instance): Zheng Shijiang, Male, DOB: 04/04/1966, Han Chinese, Farmer, residing in Fuqing, Fujian Attorney of the three appellants above: Xie Changling, Zhong Yin (Fuzhou) Law Firm. Appellee (plaintiff of the first instance): Friends of Nature Domicile: Room A201, Building 2, No. 12 Yumin Road, Chaoyang District, Beijing Legal Representative: Zhang Hehe, Deputy Director-General Entrusted Agent: Ge Feng, Female, Director of Legal and Policy Affairs, residing in Wuchang District, Wuhan Attorney: Liu Xiang, Golden Diamond Law Firm Appellee (plaintiff of the first instance): Fujian Green Home Environment-friendly Center Domicile: 3H, Buidling B, Hot Spring Park, Yingji Road No. 38, Gulou District, Fuzhou, Fujian Legal Representative: Lin Meiying, Director Attorney: Wu Anxin, Hubei Longzhong Law Firm Defendant of the First Instance: Li Mingshuo, Male, DOB: 12/16/1968, Han Chinese, Farmer, residing in Taishun County, Zhejiang Attorney: Qiu Shuhua, Fujian Quanxin Law Firm Third Party of the First Instance: Yanping District Land Resources Bureau of Nanping Municipal Land Resources Bureau Domicile: Shengli Street No. 182, Yanping District, Nanping, Fujian Legal Representative: Huang Ge, Director-General Attorney: He Jianhua, Fujian Shunning Law Firm Third Party of the First Instance: Yanping District Forestry Bureau of Nanping Municipal Forestry Bureau Domicile: Chaoyang Street No. -

Chinese Immigrant Transnational Organizations in the United States1
Draft, 05-10-2012 Traversing Ancestral and New Homelands: Chinese Immigrant Transnational Organizations in the United States1 Min Zhou and Rennie Lee University of California, Los Angeles [To be presented at the Transnational Network Meeting, Center for Migration and Development, Princeton University, May 11-12, 2012; to be included in Portes, Alejandro (ed.), Development at a Distance: The Role of Immigrant Organizations in the Development of Sending Nations. New York: Russell Sage Foundation.] Over the past three decades, immigrant transnational organizations in the United States have proliferated with accelerated international migration and the rise of new transportation and communication technologies that facilitate long-distance and cross-border ties. Their impact and influence have grown in tandem with immigrants’ drive to make it in America—their new homeland—as well as with the need for remittances and investments in sending countries—their ancestral homelands. Numerous studies of immigrant groups found that remittances and migrant investments represented one of the major sources of foreign exchange of sending countries and were used as “collateral” for loans from international financial institutions (Basch et al. 1994; Glick-Schiller et al. 1992; Portes et al. 1999). Past studies also found that transnational flows were not merely driven by individual behavior but by collective forces via organizations as well (Goldring 2002; Landolt 2000; Moya 2005; Piper 2009; Popkin 1999; Portes et al. 2007; Portes and Zhou 2012; Schrover and Vermeulen 2005; Waldinger et al. 2008). But the density and strength of the economic, sociocultural, and political ties of immigrant groups across borders vary, and the effects of immigrant transnational organizations on homeland development vary (Portes et al. -

China – Fujian – Family Planning – “Hidden” Children
Refugee Review Tribunal AUSTRALIA RRT RESEARCH RESPONSE Research Response Number: CHN31026 Country: China Date: 15 December 2006 Keywords: China – Fujian – Family Planning – Hidden children This response was prepared by the Country Research Section of the Refugee Review Tribunal (RRT) after researching publicly accessible information currently available to the RRT within time constraints. This response is not, and does not purport to be, conclusive as to the merit of any particular claim to refugee status or asylum. Questions 1. How many excess children are there in a family of two girls and then a son? 2. What would be the “social compensation fees” in a case like this? 3. Does a child born out of wedlock and/or outside a hospital receive a birth certificate and household registration? 4. Would the second daughter be entitled to a birth certificate? 5. Is there any evidence of hidden births or children? 6. What evidence is there that tubal ligations are required in Fujian? 7. How liberally or strictly is the One Child Policy applied in rural Fujian? RSPONSE 1. How many excess children are there in a family of two girls and then a son? Definitive information on this question was not found in the sources consulted. Under family planning regulations permission for the birth of additional children may vary according to the parents’ circumstances and their location. Sources indicate that in many provinces rural couples are allowed to have a second child if the first is a girl. In respect of Fujian, the current family planning regulations were adopted in 2002. Other family regulations were in place during the 1990s. -

Download Article
Advances in Social Science, Education and Humanities Research, volume 171 International Conference on Art Studies: Science, Experience, Education (ICASSEE 2017) Research on the Artistic Characteristics and Cultural Connotation of Women's Headgear and Hairdo of She Nationality in Fujian Province Xu Chen Clothing and Design Faculty Minjiang University Fashion Design Center of Fujian Province Fuzhou, China Jiangang Wang* Yonggui Li Clothing and Design Faculty Clothing and Design Faculty Minjiang University Minjiang University Fashion Design Center of Fujian Province Fashion Design Center of Fujian Province Fuzhou, China Fuzhou, China *Corresponding Author Abstract—In this paper, the author takes women's of She nationality includes the phoenix coronet and the headgear and hairdo of She nationality in modern times as the hairdo worn by women. According to the scholar Pan objects of study. With the historical materials and the Hongli's views, the hairdo of She nationality of Fujian literature, this paper investigates the characteristics of province can be divided into Luoyuan style, Fuan style women's headgear and hairdo of She nationality in Fujian (including Ningde), Xiapu style, Fuding style (including province, and analyzes the distribution and historical origin of Zhejiang and Anhui), Shunchang style, Guangze style and women's headgear and hairdo of She nationality in Fujian Zhangping style [1]. The author believes that the current province. Based on the theoretical foundation of semiotics and women hairdo of She nationality of Fujian province only folklore, this paper analyzes the symbolic language and the retain the four forms of Luoyuan, Fuan (the same with implication of the symbols of women's headgear and hairdo of Ningde), the eastern Xiapu, the western Xiapu (the same She nationality, and reveals the connotation of the ancestor worship, reproductive worship, migratory memory, love and with Fuding). -

Chinese Producers 1. Anhui Fushitong Industrial Co., Ltd No
Barcode:3695509-02 A-570-084 INV - Investigation - Chinese Producers 1. Anhui Fushitong Industrial Co., Ltd No. 158 Hezhong Rd. Qingpu, Shanghai People's Republic of China Website: yanyangstone.com Phone: 021-39800305 Fax: 021-39800390 2. Anhui Macrolink Advanced Materials Co., Ltd. Yongqing Road, Fengyang Industrial Park, Fengyang Chuzhou, Anhui 233121 People's Republic of China Website: http://www.stonecontact.com/suppliers-72256/anhui-macrolink-advanced- materials-co-ltd Phone: 86-550-2213218 3. Anhui Ruxiang Quartz Stone Co., Ltd. No. 1 Industrial Park, Shucheng Luan, Anhui 231300 People's Republic of China Website: https://rxquartzstone.en.ec21.com/ Phone: 86-564-8041216; 86-15395030376 Fax: 86-564-8041216 4. BECK quartz stone No. 6 Jinsha Rd., Yuantan Zhen,Qingcheng Qingyuan, Guangdong People's Republic of China Website: http://www.stonecontact.com/suppliers-135418/beck-quartz-stone Phone: 86-13450825204 5. Best Cheer Stone, Inc. (BCS) No. 2 Land, Bin Hai Industry Zone, Shui Tou Town Nan An, Fu Jian People's Republic of China Website: http://www.bestcheerusa.com/; http://www.bestcheer.com/index_en.aspx Phone: (86)0595-86007000 Fax: (86)0595-86007001; (818) 765 - 7406 Filed By: [email protected], Filed Date: 4/16/18 8:04 PM, Submission Status: Approved Barcode:3695509-02 A-570-084 INV - Investigation - 6. Bestone High Tech Materials Co., Ltd. (BSU Bestone (AKA BEST Quartz Stone)) Rm 48, 2/F, Hall D Chawan Road, Meijia Decorative Materials City, Chancheng Foshan, Guangdong, China 528000 People's Republic of China Website: http://www.bstquartz.com/ Phone: (86 757) 82584141; Fax: (86 757) 82584242 7. -
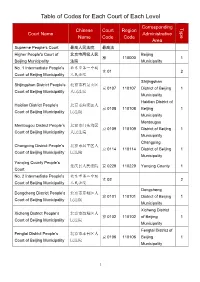
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115