An Unobtrusive, Scalable Approach to Large Scale Software License Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

Mahasen: Distributed Storage Resource Broker K
Mahasen: Distributed Storage Resource Broker K. Perera, T. Kishanthan, H. Perera, D. Madola, Malaka Walpola, Srinath Perera To cite this version: K. Perera, T. Kishanthan, H. Perera, D. Madola, Malaka Walpola, et al.. Mahasen: Distributed Storage Resource Broker. 10th International Conference on Network and Parallel Computing (NPC), Sep 2013, Guiyang, China. pp.380-392, 10.1007/978-3-642-40820-5_32. hal-01513774 HAL Id: hal-01513774 https://hal.inria.fr/hal-01513774 Submitted on 25 Apr 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Mahasen: Distributed Storage Resource Broker K.D.A.K.S.Perera1, T Kishanthan1, H.A.S.Perera1, D.T.H.V.Madola1, Malaka Walpola1, Srinath Perera2 1 Computer Science and Engineering Department, University Of Moratuwa, Sri Lanka. {shelanrc, kshanth2101, ashansa.perera, hirunimadola, malaka.uom}@gmail.com 2 WSO2 Lanka, No 59, Flower Road, Colombo 07, Sri Lanka [email protected] Abstract. Modern day systems are facing an avalanche of data, and they are being forced to handle more and more data intensive use cases. These data comes in many forms and shapes: Sensors (RFID, Near Field Communication, Weather Sensors), transaction logs, Web, social networks etc. -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

LNCS 8147, Pp
Mahasen: Distributed Storage Resource Broker K.D.A.K.S. Perera1, T. Kishanthan1, H.A.S. Perera1, D.T.H.V. Madola1, Malaka Walpola1, and Srinath Perera2 1 Computer Science and Engineering Department, University Of Moratuwa, Sri Lanka {shelanrc,kshanth2101,ashansa.perera,hirunimadola, malaka.uom}@gmail.com 2 WSO2 Lanka, No. 59, Flower Road, Colombo 07, Sri Lanka [email protected] Abstract. Modern day systems are facing an avalanche of data, and they are be- ing forced to handle more and more data intensive use cases. These data comes in many forms and shapes: Sensors (RFID, Near Field Communication, Weath- er Sensors), transaction logs, Web, social networks etc. As an example, weather sensors across the world generate a large amount of data throughout the year. Handling these and similar data require scalable, efficient, reliable and very large storages with support for efficient metadata based searching. This paper present Mahasen, a highly scalable storage for high volume data intensive ap- plications built on top of a peer-to-peer layer. In addition to scalable storage, Mahasen also supports efficient searching, built on top of the Distributed Hash table (DHT) 1 Introduction Currently United States collects weather data from many sources like Doppler readers deployed across the country, aircrafts, mobile towers and Balloons etc. These sensors keep generating a sizable amount of data. Processing them efficiently as needed is pushing our understanding about large-scale data processing to its limits. Among many challenges data poses, a prominent one is storing the data and index- ing them so that scientist and researchers can come and ask for specific type of data collected at a given time and in a given region. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Chris Mattmann
Chris Mattmann Associate Chief Technologist, NASA JPL Chris Mattmann is the Associate Chief Technologist and Innovation Officer in the Office of the Chief Technology and Innovation. Mattmann manages the IT Advanced Research and Open Source Projects Office and the NSF and Open Source Applications Office. Mattmann was formerly a member of the Engineering Administrative Office and formerly Chief Architect of the Instrument and Science Data Systems Section at NASA JPL with the responsibility for influencing science data system designs and facilitating the infusion of new technologies to meet our future challenges. Dr. Mattmann is also JPL's first Principal Scientist in the area of Data Science. He has over 18 years of experience at JPL and has conceived, realized and delivered the architecture for the next generation of reusable science data processing systems for NASA's Orbiting Carbon Observatory, NPP Sounder PEATE, and the Soil Moisture Active Passive (SMAP) Earth science missions. Mattmann's work has been funded by NASA, DARPA, DHS, NSF, NIH, NLM and by private industry. Mattmann was the first Vice President (VP) of Apache OODT (Object Oriented Data Technology), the first NASA project to enter the Apache Software Foundation (ASF) and he led the project's transition from JPL to the ASF. He contributes to open source as a Director at the Apache Software Foundation where he was one of the initial contributors to Apache Nutch as a member of its project management committee, the predecessor to the Apache Hadoop project. Mattmann is the progenitor of the Apache Tika framework, the digital "babel fish" and de-facto content analysis and detection framework that exists. -

Tika/Tika Overview.Htm Copyright © Tutorialspoint.Com
TTIIKKAA -- OOVVEERRVVIIEEWW http://www.tutorialspoint.com/tika/tika_overview.htm Copyright © tutorialspoint.com What is Apache Tika? Apache Tika is a library that is used for document type detection and content extraction from various file formats. Internally, Tika uses various existing document parsers and document type detection techniques to detect and extract data. Using Tika, one can develop a universal type detector and content extractor to extract both structured text as well as metadata from different types of documents such as spreadsheets, text documents, images, PDFs and even multimedia input formats to a certain extent. Tika provides a single generic API for parsing different file formats. It uses 83 existing specialized parser ibraries for each document type. All these parser libraries are encapsulated under a single interface called the Parser interface. Why Tika? According to filext.com, there are about 15k to 51k content types, and this number is growing day by day. Data is being stored in various formats such as text documents, excel spreadsheet, PDFs, images, and multimedia files, to name a few. Therefore, applications such as search engines and content management systems need additional support for easy extraction of data from these document types. Apache Tika serves this purpose by providing a generic API to detect and extract data from multiple file formats. Apache Tika Applications There are various applications that make use of Apache Tika. Here we will discuss a few prominent applications that depend heavily on Apache Tika. Search Engines Tika is widely used while developing search engines to index the text contents of digital documents. -

Programming Hive
www.it-ebooks.info www.it-ebooks.info Programming Hive Edward Capriolo, Dean Wampler, and Jason Rutherglen Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo www.it-ebooks.info Programming Hive by Edward Capriolo, Dean Wampler, and Jason Rutherglen Copyright © 2012 Edward Capriolo, Aspect Research Associates, and Jason Rutherglen. All rights re- served. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or [email protected]. Editors: Mike Loukides and Courtney Nash Indexer: Bob Pfahler Production Editors: Iris Febres and Rachel Steely Cover Designer: Karen Montgomery Proofreaders: Stacie Arellano and Kiel Van Horn Interior Designer: David Futato Illustrator: Rebecca Demarest October 2012: First Edition. Revision History for the First Edition: 2012-09-17 First release See http://oreilly.com/catalog/errata.csp?isbn=9781449319335 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. Programming Hive, the image of a hornet’s hive, and related trade dress are trade- marks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. -

Big Data Processing on Arbitrarily Distributed Dataset
Big Data Processing on Arbitrarily Distributed Dataset by Dongyao Wu A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY SCHOOL OF COMPUTER SCIENCE AND ENGINEERING FACULTY OF ENGINEERING Thursday, 1st June, 2017 All rights reserved. This work may not be reproduced in whole or in part, by photocopy or other means, without the permission of the author. c 2017 by Dongyao Wu PLEASE TYPE THE UNIVERSITY OF NEW SOUTH WALES Thesis/Dissertation Sheet Surname or Family name: Wu First name: Dongyao Other name/s: Abbreviation for degree as given in the University calendar: PhD School: School of Computer Science and Engineering Faculty: Faculty of Engineering Title: Big Data Processing on Arbitrarily Distributed Dataset Abstract 350 words maximum: (PLEASE TYPE) Over the past years, frameworks such as MapReduce and Spark have been Introduced to ease the task of developing big data programs and applications. These frameworks significantly reduce the complexity of developing big data programs and applications. However, in reality, many real-world scenarios require pipelining and Integration of multiple big data jobs. As the big data pipelines and applications become more and more complicated, It Is almost Impossible to manually optimize the performance for each component not to mention the whole pipeline/application. At the same time, there are also increasing requirements to facilitate interaction, composition and Integration for big data analytics applications In continuously evolving, Integrating and delivering scenarios. In addition, with the emergence and development of cloud computing, mobile computing and the Internet of Things, data are Increasingly collected and stored In highly distributed infrastructures (e.g. -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/ -
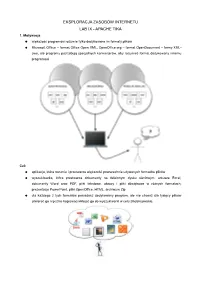
Eksploracja Zasobów Internetu Lab Ix - Apache Tika 1
EKSPLORACJA ZASOBÓW INTERNETU LAB IX - APACHE TIKA 1. Motywacja większość programów rozumie tylko dedykowane im formaty plików Microsoft Offiice – format Office Open XML, OpenOffice.org – format OpenDocument – formy XML- owe, ale programy potrzebują specjalnych konwerterów, aby rozumieć format dedykowany innemu programowi Cel: aplikacja, która rozumie i przetwarza większość powszechnie używanych formatów plików wyszukiwarka, która przetwarza dokumenty na dzielonym dysku sieciowym: arkusze Excel, dokumenty Word oraz PDF, pliki tekstowe, obrazy i pliki dźwiękowe w różnych formatach, prezentacje PowerPoint, pliki OpenOffice, HTML, archiwum Zip dla każdego z tych formatów posiadasz dedykowany program, ale nie chcesz dla tysięcy plików otwierać go i ręcznie kopiować/wklejać go do wyszukiwarki w celu zindeksowania 2. Typy plików: w sieci istnieje ok. 51 tysięcy różnych typów plików. Zawartość różni się pod względem rozmiaru, formatu i kodowania metoda przechowywania tekstu i informacji “spreadsheet”, “web page” - nie wystarczająco dokładne; “.xls”, “.html” - bardzo często zależy od systemu operacyjnego oraz zainstalowanych programów; MIME - Multipurpose Internet Mail Extensions – aby ułatwić programom “deal with the data in an appropriate manner” identyfikator: type/subtype oraz opcjonalne parametry attribute=value ponad 1000 typów oficjalnych: text/plain; charset=us-ascii, text/html, image/jpeg, application/msword, kilka tysięcy typów nieoficjalnych: image/x-icon and application/vnd.amazon.ebook ze strony programistów: konieczność uwzględnienia wiedzy nt. formatu w aplikacji Tika udostępnia metody automatycznego wykrywania typu pliku 3. Biblioteki do parsowania Microsoft Office – czytanie i pisanie dokumentów Word, Adobe Acrobat oraz Acrobat Reader – to samo dla dokumentów PDF interakcja z użytkownikiem, brak dostępu do zawartości dla innych programów alternatywa: biblioteka parsująca – format dokumentu mapowany na API, którego łatwiej używać i zrozumieć niż surowe wzorce bajtów np.