Eksploracja Zasobów Internetu Lab Ix - Apache Tika 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Unobtrusive, Scalable Approach to Large Scale Software License Analysis
DRAT: An Unobtrusive, Scalable Approach to Large Scale Software License Analysis Chris A. Mattmann1,2, Ji-Hyun Oh1,2, Tyler Palsulich1*, Lewis John McGibbney1, Yolanda Gil2,3, Varun Ratnakar3 1Jet Propulsion Laboratory 2Computer Science Department 3USC Information Sciences Institute California Institute of Technology University of Southern California University of Southern California Pasadena, CA 91109 USA Los Angeles, CA 90089 USA Marina Del Rey, CA [email protected] {mattmann,jihyuno}@usc.edu {gil,varunr}@ isi.edu Abstract— The Apache Release Audit Tool (RAT) performs (OSI) for complying with open source software open source license auditing and checking, however definition, however, there exist slight differences among these RAT fails to successfully audit today's large code bases. Being a licenses [2]. For instance, GPL is a “copyleft” license that natural language processing (NLP) tool and a crawler, RAT only allows derivative works under the original license, marches through a code base, but uses rudimentary black lists whereas MIT license is a “permissive” license that grants the and white lists to navigate source code repositories, and often does a poor job of identifying source code versus binary files. In right to sublicense the code under any kind of license [2]. This addition RAT produces no incremental output and thus on code difference could affect architectural design of the software. bases that themselves are "Big Data", RAT could run for e.g., a Furthermore, circumstances are more complicated when month and still not provide any status report. We introduce people publish software under the multiple licenses. Distributed "RAT" or the Distributed Release Audit Tool Therefore, an automated tool for verifying software licenses in (DRAT). -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Chris Mattmann
Chris Mattmann Associate Chief Technologist, NASA JPL Chris Mattmann is the Associate Chief Technologist and Innovation Officer in the Office of the Chief Technology and Innovation. Mattmann manages the IT Advanced Research and Open Source Projects Office and the NSF and Open Source Applications Office. Mattmann was formerly a member of the Engineering Administrative Office and formerly Chief Architect of the Instrument and Science Data Systems Section at NASA JPL with the responsibility for influencing science data system designs and facilitating the infusion of new technologies to meet our future challenges. Dr. Mattmann is also JPL's first Principal Scientist in the area of Data Science. He has over 18 years of experience at JPL and has conceived, realized and delivered the architecture for the next generation of reusable science data processing systems for NASA's Orbiting Carbon Observatory, NPP Sounder PEATE, and the Soil Moisture Active Passive (SMAP) Earth science missions. Mattmann's work has been funded by NASA, DARPA, DHS, NSF, NIH, NLM and by private industry. Mattmann was the first Vice President (VP) of Apache OODT (Object Oriented Data Technology), the first NASA project to enter the Apache Software Foundation (ASF) and he led the project's transition from JPL to the ASF. He contributes to open source as a Director at the Apache Software Foundation where he was one of the initial contributors to Apache Nutch as a member of its project management committee, the predecessor to the Apache Hadoop project. Mattmann is the progenitor of the Apache Tika framework, the digital "babel fish" and de-facto content analysis and detection framework that exists. -

Tika/Tika Overview.Htm Copyright © Tutorialspoint.Com
TTIIKKAA -- OOVVEERRVVIIEEWW http://www.tutorialspoint.com/tika/tika_overview.htm Copyright © tutorialspoint.com What is Apache Tika? Apache Tika is a library that is used for document type detection and content extraction from various file formats. Internally, Tika uses various existing document parsers and document type detection techniques to detect and extract data. Using Tika, one can develop a universal type detector and content extractor to extract both structured text as well as metadata from different types of documents such as spreadsheets, text documents, images, PDFs and even multimedia input formats to a certain extent. Tika provides a single generic API for parsing different file formats. It uses 83 existing specialized parser ibraries for each document type. All these parser libraries are encapsulated under a single interface called the Parser interface. Why Tika? According to filext.com, there are about 15k to 51k content types, and this number is growing day by day. Data is being stored in various formats such as text documents, excel spreadsheet, PDFs, images, and multimedia files, to name a few. Therefore, applications such as search engines and content management systems need additional support for easy extraction of data from these document types. Apache Tika serves this purpose by providing a generic API to detect and extract data from multiple file formats. Apache Tika Applications There are various applications that make use of Apache Tika. Here we will discuss a few prominent applications that depend heavily on Apache Tika. Search Engines Tika is widely used while developing search engines to index the text contents of digital documents. -

Lumada Data Catalog Product Manager Lumada Data Catalog V 6
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Lumada Data Catalog Product Manager Lumada Data Catalog v 6 . 0 . 0 ( D r a f t ) Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations BSD 3-clause "New" or "Revised" abego TreeLayout Core 1.0.1 License ActiveMQ Artemis JMS Client All 2.9.0 Apache License 2.0 Aliyun Message and Notification 1.1.8.8 Apache License 2.0 Service SDK for Java An open source Java toolkit for 0.9.0 Apache License 2.0 Amazon S3 Annotations for Metrics 3.1.0 Apache License 2.0 ANTLR 2.7.2 ANTLR Software Rights Notice ANTLR 2.7.7 ANTLR Software Rights Notice BSD 3-clause "New" or "Revised" ANTLR 4.5.3 License BSD 3-clause "New" or "Revised" ANTLR 4.7.1 License ANTLR 4.7.1 MIT License BSD 3-clause "New" or "Revised" ANTLR 4 Tool 4.5.3 License AOP Alliance (Java/J2EE AOP 1 Public Domain standard) Aopalliance Version 1.0 Repackaged 2.5.0 Eclipse Public License 2.0 As A Module Aopalliance Version 1.0 Repackaged Common Development and 2.5.0-b05 As A Module Distribution License 1.1 Aopalliance Version 1.0 Repackaged 2.6.0 Eclipse Public License 2.0 As A Module Apache Atlas Common 1.1.0 Apache License 2.0 Apache Atlas Integration 1.1.0 Apache License 2.0 Apache Atlas Typesystem 0.8.4 Apache License 2.0 Apache Avro 1.7.4 Apache License 2.0 Apache Avro 1.7.6 Apache License 2.0 Apache Avro 1.7.6-cdh5.3.3 Apache License 2.0 Apache Avro 1.7.7 Apache License -

Fast Indexing and Searching of Forensic Disk Images
High Performance Indexing of Large Heterogeneous Data Sets using GPU Massimo Bernaschi IAC – National Research Council of Italy funded by the ISEC programme under GA n° 4000003856 Why a new indexer? • Law Enforcement Agencies need an easy and fast tool to index and search seized disk images GTC 2015 2 How it works • Extract raw files and metadata from (seized) disk images • Distribute them over multiple systems • Extract plain text and metadata from every file – including deleted files • Create distributed indexes • Provide a friendly user interface to query results • Organize query results in an intuitive visual representation GTC 2015 3 Architecture Overview CONNECTIONS’ LEGEND Web GUI DB input/ouput DATABASE HPC cluster Admin Search SEARCHER MEDIATOR DBMS COORDINATOR Job Status Scheduler Manager WORKER AGENT INDEX Worker Nodes REPO HPC Cluster GTC 2015 4 Architecture Overview (cont.) • Coordinator – Manage, coordinate and monitor the whole system • DBMS – Provides the interface to the Database • Mediator – Mediates among all components to ease message communication • Admin – Web UI – Used to manage the infrastruture, create investigation cases and add disk images for indexing • Worker Agent – Runs all worker nodes and provides services for monitoring, starting, stopping, configuring local components • Index Repository – Repository used to store results of all indexing jobs GTC 2015 5 Architecture Overview (cont.) • Each worker node can run one or more – Image-Extractor • to extract files from seized disk images – Docu-Parser • to trasform -

Fscrawler Documentation Release 2.6 David Pilato
FSCrawler Documentation Release 2.6 David Pilato Jan 11, 2019 Installation Guide 1 Download FSCrawler 3 2 Running as a Service on Windows5 3 Upgrade FSCrawler 7 3.1 Upgrade to 2.2..............................................7 3.2 Upgrade to 2.3..............................................7 3.3 Upgrade to 2.4..............................................9 3.4 Upgrade to 2.5..............................................9 3.5 Upgrade to 2.6.............................................. 10 4 Getting Started 11 4.1 Start FSCrawler............................................. 11 4.2 Searching for docs............................................ 12 4.3 Ignoring folders............................................. 12 5 Crawler options 13 6 Starting with a REST gateway 15 7 Supported formats 17 8 Tips and tricks 19 8.1 Moving files to a “watched” directory.................................. 19 8.2 Indexing from HDFS drive........................................ 19 8.3 OCR integration............................................. 19 8.4 Using docker............................................... 22 9 Status files 23 10 CLI options 25 10.1 Upgrade................................................. 25 10.2 Loop................................................... 25 10.3 Restart.................................................. 26 10.4 Rest.................................................... 26 11 JVM Settings 27 i 12 Configuring an external logger configuration file 29 13 Job file specification 31 14 The most simple crawler 33 15 Local FS settings 35 15.1 Root -

Processing Data Sources with Big Data Frameworks Behandla Datakällor
DEGREE PROJECT IN COMPUTER ENGINEERING, FIRST CYCLE, 15 CREDITS STOCKHOLM, SWEDEN 2016 Processing data sources with big data frameworks Behandla datakällor med big data-ramverk JOAKIM LÖNNEGREN SIMON NYSTRÖM KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF TECHNOLOGY AND HEALTH Processing data sources with big data frameworks Behandla datakällor med big data-ramverk Joakim Lönnegren Simon Nyström Degree project in Computer Science First level, 15 hp Supervisor from KTH: Reine Bergström Examiner: Ibrahim Orhan TRITA-STH 2016:55 KTH The School of Technology and Health 136 40 Handen, Sweden Abstract Big data is a concept that is expanding rapidly. As more and more data is generated and garnered, there is an increasing need for efficient solutions that can be utilized to process all this data in attempts to gain value from it. The purpose of this thesis is to find an efficient way to quickly process a large num- ber of relatively small files. More specifically, the purpose is to test two frameworks that can be used for processing big data. The frameworks that are tested against each other are Apache NiFi and Apache Storm. A method is devised in order to, firstly, construct a data flow and secondly, con- struct a method for testing the performance and scalability of the frameworks run- ning this data flow. The results reveal that Apache Storm is faster than Apache NiFi, at the sort of task that was tested. As the number of nodes included in the tests went up, the performance did not al- ways do the same. This indicates that adding more nodes to a big data processing pipeline, does not always result in a better performing setup and that, sometimes, other measures must be made to heighten the performance. -

Imvision OSS Open Source Software
imVision® Open Source Software 860641279 Revision C June 2019 commscope.com NOTE: This document revision applies to imVision® System Manager version 8.2. To obtain open source software license information for subsequent versions of imVision® System Manager, refer to the “Legal Notices” section of imVision® System Manager’s help system. imVision® System Manager Open Source Software (OSS) Catalog Table of Contents Purpose and Scope ....................................................................................................................................... 2 Open Source Software Catalog Table ........................................................................................................... 2 Licenses ........................................................................................................................................................ 6 Apache License Version 2.0 ...................................................................................................................... 6 BSD ............................................................................................................................................................ 8 COMMON DEVELOPMENT AND DISTRIBUTION LICENSE (CDDL v1.0) ............................................. 9 Eclipse Public License - v1.0 ................................................................................................................... 15 GNU Lesser General Public License v2.1 .............................................................................................. -
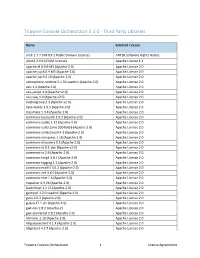
Tripwire Console Orchestrator 5.1.0 - Third Party Libraries
Tripwire Console Orchestrator 5.1.0 - Third Party Libraries Name Selected License antlr 2.7.7 (ANTLR 2 Public Domain License) ANTLR Software Rights Notice jdom2 2.0.6 (JDOM License) Apache License 1.1 apache-el 8.0.9.M3 (Apache-2.0) Apache License 2.0 apache-jsp 8.0.9.M3 (Apache-2.0) Apache License 2.0 apache-jsp 9.2.14 (Apache-2.0) Apache License 2.0 atmosphere-runtime 2.4.30.vaadin1 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache 2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache v2.0) Apache License 2.0 buttongroup 2.3 (Apache v2.0) Apache License 2.0 byte-buddy 1.9.5 (Apache-2.0) Apache License 2.0 classmate 1.3.4 (Apache-2.0) Apache License 2.0 commons-beanutils 1.9.3 (Apache-2.0) Apache License 2.0 commons-codec 1.12 (Apache-2.0) Apache License 2.0 commons-collections 20040616 (Apache-2.0) Apache License 2.0 commons-collections4 4.3 (Apache-2.0) Apache License 2.0 commons-compress 1.18 (Apache-2.0) Apache License 2.0 commons-discovery 0.5 (Apache 2.0) Apache License 2.0 commons-id 0.1-dev (Apache v2.0) Apache License 2.0 commons-io 2.6 (Apache-2.0) Apache License 2.0 commons-lang3 3.8.1 (Apache-2.0) Apache License 2.0 commons-logging 1.2 (Apache-2.0) Apache License 2.0 commons-math3 3.6.1 (Apache-2.0) Apache License 2.0 commons-net 3.6.0 (Apache-2.0) Apache License 2.0 commons-text 1.4 (Apache-2.0) Apache License 2.0 cssparser 0.9.24 (Apache-2.0) Apache License 2.0 fastinfoset 1.2.15 (Apache-2.0) Apache License 2.0 gentyref 1.2.0.vaadin1 (Apache 2.0) Apache License 2.0 gson 2.6.2 (Apache-2.0) -

Tracking Down the Bad Guys Tom Barber - NASA JPL Big Data Conference - Vilnius Nov 2017 Who Am I?
Tracking Down The Bad Guys Tom Barber - NASA JPL Big Data Conference - Vilnius Nov 2017 Who am I? Tom Barber Data Nerd Open Source Business Intelligence Developer Director of Meteorite BI and Spicule LTD Software Developer at NASA JPL in the Computer Science for Data Intensive Applications Group Some stuff I’ve worked on Saiku Analytics - OLAP Browser Apache OODT - Data Processing Toolkit originally by NASA Pentaho Business Intelligence Suite - Business Intelligence Suite Apache Tika - Metadata Extraction Apache DRAT - Release Auditing Sparkler - Spark Crawler How I ended up working at NASA It’s an easy 6 step process!! 1. Want to be an astronaut 2. Learn about data 3. Volunteer some time on open source code and meet new people 4. Decide to change job direction 5. Ask random people for new job 6. Get offered a job at NASA See…. easy! Work we do at NASA JPL We build applications for high volume data processing and visualisation. ● Genomics Search and data extraction ● Polar data discovery ● Data processing for a number of satellite programs ● Storage and archive of planetary data ● Track down criminals!!! What is DARPA? Defense Advanced Research Projects Agency Founded in response to Sputnik Invests in technology for (US) National Security Work with external partners to bring knowledge to programs The Challenge Memex seeks to develop software that advances online search capabilities far beyond the current state of the art. The goal is to invent better methods for interacting with and sharing information, so users can quickly and thoroughly organize and search subsets of information relevant to their individual interests. -

Content Extraction and Search Using Apache Tika
Content extraction and search using Apache Tika Objective In April 2011, the U.S. Federal Bureau of Investigation launched its Vault site (http://vault.fbi.gov). The site contains over 3000 declassified documents that have been scanned from paper and made available via a digital content management system. One of the many documents on the FBI web site having to do with the subject of UFOs (Unidentified Flying Objects) We went to the search portion of the site and did a query for UFO: 269 hits come back from the search. Of the 3000 or more documents, 269 is not an insignificant number by any means (it amounts to about 9% of the total corpus), however, it seems like there would be a larger number of documents in the FBI’s vault concerning the subject of UFOs. In this assignment, you are going to use Apache Tika to help us test our theory. Task Description The entire corpus of PDF files (13 GB) from the FBI’s vault web site has already been collected and packaged into a tar file. With the corpus of PDF files in hand, a Java program to be written as Hw3.java will: Accept an input file containing any number of search keyword(s) and/or phrase(s) Iterate through the corpus of data on your local computer. Call Apache Tika to extract all of the text from each PDF file Scan the extracted text to search for the given search keyword(s) Count and output statistics about o the number of documents that contain the keywords o the total number occurrences of the keywords o list of files containing the keywords The program analyze the results to help us decide whether or not the FBI’s search is telling us the truth when it says only 9% of its vault corpus has to do with UFOs, or whether or not something more is hiding in that rich treasure trove of information.