This Is Your Presentation Title
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

Petaflops for the People
PETAFLOPS SPOTLIGHT: NERSC housands of researchers have used facilities of the Advanced T Scientific Computing Research (ASCR) program and its EXTREME-WEATHER Department of Energy (DOE) computing predecessors over the past four decades. Their studies of hurricanes, earthquakes, NUMBER-CRUNCHING green-energy technologies and many other basic and applied Certain problems lend themselves to solution by science problems have, in turn, benefited millions of people. computers. Take hurricanes, for instance: They’re They owe it mainly to the capacity provided by the National too big, too dangerous and perhaps too expensive Energy Research Scientific Computing Center (NERSC), the Oak to understand fully without a supercomputer. Ridge Leadership Computing Facility (OLCF) and the Argonne Leadership Computing Facility (ALCF). Using decades of global climate data in a grid comprised of 25-kilometer squares, researchers in These ASCR installations have helped train the advanced Berkeley Lab’s Computational Research Division scientific workforce of the future. Postdoctoral scientists, captured the formation of hurricanes and typhoons graduate students and early-career researchers have worked and the extreme waves that they generate. Those there, learning to configure the world’s most sophisticated same models, when run at resolutions of about supercomputers for their own various and wide-ranging projects. 100 kilometers, missed the tropical cyclones and Cutting-edge supercomputing, once the purview of a small resulting waves, up to 30 meters high. group of experts, has trickled down to the benefit of thousands of investigators in the broader scientific community. Their findings, published inGeophysical Research Letters, demonstrated the importance of running Today, NERSC, at Lawrence Berkeley National Laboratory; climate models at higher resolution. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Towards Exascale Computing
TowardsTowards ExascaleExascale Computing:Computing: TheThe ECOSCALEECOSCALE ApproachApproach Dirk Koch, The University of Manchester, UK ([email protected]) 1 Motivation: let’s build a 1,000,000,000,000,000,000 FLOPS Computer (Exascale computing: 1018 FLOPS = one quintillion or a billion billion floating-point calculations per sec.) 2 1,000,000,000,000,000,000 FLOPS . 10,000,000,000,000,000,00 FLOPS 1975: MOS 6502 (Commodore 64, BBC Micro) 3 Sunway TaihuLight Supercomputer . 2016 (fully operational) . 12,543,6000,000,000,000,00 FLOPS (125.436 petaFLOPS) . Architecture Sunway SW26010 260C (Digital Alpha clone) 1.45GHz 10,649,600 cores . Power “The cooling system for TaihuLight uses a closed- coupled chilled water outfit suited for 28 MW with a custom liquid cooling unit”* *https://www.nextplatform.com/2016/06/20/look-inside-chinas-chart-topping-new-supercomputer/ . Cost US$ ~$270 million 4 TOP500 Performance Development We need more than all the performance of all TOP500 machines together! 5 TaihuLight for Exascale Computing? We need 8x the worlds fastest supercomputer: . Architecture Sunway SW26010 260C (Digital Alpha clone) @1.45GHz: > 85M cores . Power 224 MW (including cooling) costs ~ US$ 40K/hour, US$ 340M/year from coal: 2,302,195 tons of CO2 per year . Cost US$ 2.16 billion We have to get at least 10x better in energy efficiency 2-3x better in cost Also: scalable programming models 6 Alternative: Green500 Shoubu supercomputer (#1 Green500 in 2015): . Cores: 1,181,952 . Theoretical Peak: 1,535.83 TFLOPS/s . Memory: 82 TB . Processor: Xeon E5-2618Lv3 8C 2.3GHz . -

Computational PHYSICS Shuai Dong
Computational physiCs Shuai Dong Evolution: Is this our final end-result? Outline • Brief history of computers • Supercomputers • Brief introduction of computational science • Some basic concepts, tools, examples Birth of Computational Science (Physics) The first electronic general-purpose computer: Constructed in Moore School of Electrical Engineering, University of Pennsylvania, 1946 ENIAC: Electronic Numerical Integrator And Computer ENIAC Electronic Numerical Integrator And Computer • Design and construction was financed by the United States Army. • Designed to calculate artillery firing tables for the United States Army's Ballistic Research Laboratory. • It was heralded in the press as a "Giant Brain". • It had a speed of one thousand times that of electro- mechanical machines. • ENIAC was named an IEEE Milestone in 1987. Gaint Brain • ENIAC contained 17,468 vacuum tubes, 7,200 crystal diodes, 1,500 relays, 70,000 resistors, 10,000 capacitors and around 5 million hand-soldered joints. It weighed more than 27 tons, took up 167 m2, and consumed 150 kW of power. • This led to the rumor that whenever the computer was switched on, lights in Philadelphia dimmed. • Input was from an IBM card reader, and an IBM card punch was used for output. Development of micro-computers modern PC 1981 IBM PC 5150 CPU: Intel i3,i5,i7, CPU: 8088, 5 MHz 3 GHz Floppy disk or cassette Solid state disk 1984 Macintosh Steve Jobs modern iMac Supercomputers The CDC (Control Data Corporation) 6600, released in 1964, is generally considered the first supercomputer. Seymour Roger Cray (1925-1996) The father of supercomputing, Cray-1 who created the supercomputer industry. Cray Inc. -

Unlocking the Full Potential of the Cray XK7 Accelerator
Unlocking the Full Potential of the Cray XK7 Accelerator ∗ † Mark D. Klein , and, John E. Stone ∗National Center for Supercomputing Application, University of Illinois at Urbana-Champaign, Urbana, IL, 61801, USA †Beckman Institute, University of Illinois at Urbana-Champaign, Urbana, IL, 61801, USA Abstract—The Cray XK7 includes NVIDIA GPUs for ac- [2], [3], [4], and for high fidelity movie renderings with the celeration of computing workloads, but the standard XK7 HVR volume rendering software.2 In one example, the total system software inhibits the GPUs from accelerating OpenGL turnaround time for an HVR movie rendering of a trillion- and related graphics-specific functions. We have changed the operating mode of the XK7 GPU firmware, developed a custom cell inertial confinement fusion simulation [5] was reduced X11 stack, and worked with Cray to acquire an alternate driver from an estimate of over a month for data transfer to and package from NVIDIA in order to allow users to render and rendering on a conventional visualization cluster down to post-process their data directly on Blue Waters. Users are able just one day when rendered locally using 128 XK7 nodes to use NVIDIA’s hardware OpenGL implementation which has on Blue Waters. The fully-graphics-enabled GPU state is many features not available in software rasterizers. By elim- inating the transfer of data to external visualization clusters, currently considered an unsupported mode of operation by time-to-solution for users has been improved tremendously. In Cray, and to our knowledge Blue Waters is presently the one case, XK7 OpenGL rendering has cut turnaround time only Cray system currently running in this mode. -

FCMSSR Meeting 2018-01 All Slides
Federal Committee for Meteorological Services and Supporting Research (FCMSSR) Dr. Neil Jacobs Assistant Secretary for Environmental Observation and Prediction and FCMSSR Chair April 30, 2018 Office of the Federal Coordinator for Meteorology Services and Supporting Research 1 Agenda 2:30 – Opening Remarks (Dr. Neil Jacobs, NOAA) 2:40 – Action Item Review (Dr. Bill Schulz, OFCM) 2:45 – Federal Coordinator's Update (OFCM) 3:00 – Implementing Section 402 of the Weather Research And Forecasting Innovation Act Of 2017 (OFCM) 3:20 – Federal Meteorological Services And Supporting Research Strategic Plan and Annual Report. (OFCM) 3:30 – Qualification Standards For Civilian Meteorologists. (Mr. Ralph Stoffler, USAF A3-W) 3:50 – National Earth System Predication Capability (ESPC) High Performance Computing Summary. (ESPC Staff) 4:10 – Open Discussion (All) 4:20 – Wrap-Up (Dr. Neil Jacobs, NOAA) Office of the Federal Coordinator for Meteorology Services and Supporting Research 2 FCMSSR Action Items AI # Text Office Comment Status Due Date Responsible 2017-2.1 Reconvene JAG/ICAWS to OFCM, • JAG/ICAWS convened. Working 04/30/18 develop options to broaden FCMSSR • Options presented to FCMSSR Chairmanship beyond Agencies ICMSSR the Undersecretary of Commerce • then FCMSSR with a for Oceans and Atmosphere. revised Charter Draft a modified FCMSSR • Draft Charter reviewed charter to include ICAWS duties by ICMSSR. as outlined in Section 402 of the • Pending FCMSSR and Weather Research and Forecasting OSTP approval to Innovation Act of 2017 and secure finalize Charter for ICMSSR concurrence. signature. Recommend new due date: 30 June 2018. 2017-2.2 Publish the Strategic Plan for OFCM 1/12/18: Plan published on Closed 11/03/17 Federal Weather Coordination as OFCM website presented during the 24 October 2017 FCMMSR Meeting. -
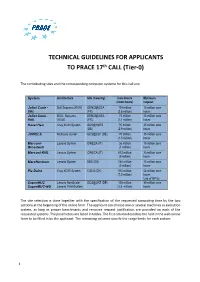
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

It's a Multi-Core World
It’s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group Moore’s Law is not to blame. Intel process technology capabilities High Volume Manufacturing 2004 2006 2008 2010 2012 2014 2016 2018 Feature Size 90nm 65nm 45nm 32nm 22nm 16nm 11nm 8nm Integration Capacity (Billions of 2 4 8 16 32 64 128 256 Transistors) Transistor for Influenza Virus 90nm Process Source: CDC 50nm Source: Intel At end of day, we keep using all those new transistors. That Power and Clock Inflection Point in 2004… didn’t get better. Fun fact: At 100+ Watts and <1V, currents are beginning to exceed 100A at the point of load! Source: Kogge and Shalf, IEEE CISE Courtesy Horst Simon, LBNL Not a new problem, just a new scale… CPU Power W) Cray-2 with cooling tower in foreground, circa 1985 And how to get more performance from more transistors with the same power. RULE OF THUMB A 15% Frequency Power Performance Reduction Reduction Reduction Reduction In Voltage 15% 45% 10% Yields SINGLE CORE DUAL CORE Area = 1 Area = 2 Voltage = 1 Voltage = 0.85 Freq = 1 Freq = 0.85 Power = 1 Power = 1 Perf = 1 Perf = ~1.8 Single Socket Parallelism Processor Year Vector Bits SP FLOPs / core / Cores FLOPs/cycle cycle Pentium III 1999 SSE 128 3 1 3 Pentium IV 2001 SSE2 128 4 1 4 Core 2006 SSE3 128 8 2 16 Nehalem 2008 SSE4 128 8 10 80 Sandybridge 2011 AVX 256 16 12 192 Haswell 2013 AVX2 256 32 18 576 KNC 2012 AVX512 512 32 64 2048 KNL 2016 AVX512 512 64 72 4608 Skylake 2017 AVX512 512 96 28 2688 Putting It All Together Prototypical Application: Serial Weather Model CPU MEMORY First Parallel Weather Modeling Algorithm: Richardson in 1917 Courtesy John Burkhardt, Virginia Tech Weather Model: Shared Memory (OpenMP) Core Fortran: !$omp parallel do Core do i = 1, n Core a(i) = b(i) + c(i) enddoCore C/C++: MEMORY #pragma omp parallel for Four meteorologists in the samefor(i=1; room sharingi<=n; i++) the map. -

Hardware Complexity and Software Challenges
Trends in HPC: hardware complexity and software challenges Mike Giles Oxford University Mathematical Institute Oxford e-Research Centre ACCU talk, Oxford June 30, 2015 Mike Giles (Oxford) HPC Trends June 30, 2015 1 / 29 1 { 10? 10 { 100? 100 { 1000? Answer: 4 cores in Intel Core i7 CPU + 384 cores in NVIDIA K1100M GPU! Peak power consumption: 45W for CPU + 45W for GPU Question ?! How many cores in my Dell M3800 laptop? Mike Giles (Oxford) HPC Trends June 30, 2015 2 / 29 Answer: 4 cores in Intel Core i7 CPU + 384 cores in NVIDIA K1100M GPU! Peak power consumption: 45W for CPU + 45W for GPU Question ?! How many cores in my Dell M3800 laptop? 1 { 10? 10 { 100? 100 { 1000? Mike Giles (Oxford) HPC Trends June 30, 2015 2 / 29 Question ?! How many cores in my Dell M3800 laptop? 1 { 10? 10 { 100? 100 { 1000? Answer: 4 cores in Intel Core i7 CPU + 384 cores in NVIDIA K1100M GPU! Peak power consumption: 45W for CPU + 45W for GPU Mike Giles (Oxford) HPC Trends June 30, 2015 2 / 29 Top500 supercomputers Really impressive { 300× more capability in 10 years! Mike Giles (Oxford) HPC Trends June 30, 2015 3 / 29 My personal experience 1982: CDC Cyber 205 (NASA Langley) 1985{89: Alliant FX/8 (MIT) 1989{92: Stellar (MIT) 1990: Thinking Machines CM5 (UTRC) 1987{92: Cray X-MP/Y-MP (NASA Ames, Rolls-Royce) 1993{97: IBM SP2 (Oxford) 1998{2002: SGI Origin (Oxford) 2002 { today: various x86 clusters (Oxford) 2007 { today: various GPU systems/clusters (Oxford) 2011{15: GPU cluster (Emerald @ RAL) 2008 { today: Cray XE6/XC30 (HECToR/ARCHER @ EPCC) 2013 { today: Cray XK7 with GPUs (Titan @ ORNL) Mike Giles (Oxford) HPC Trends June 30, 2015 4 / 29 Top500 supercomputers Power requirements are raising the question of whether this rate of improvement is sustainable. -

Joaovicentesouto-Tcc.Pdf
UNIVERSIDADE FEDERAL DE SANTA CATARINA CENTRO TECNOLÓGICO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA CIÊNCIAS DA COMPUTAÇÃO João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Florianópolis 6 de dezembro de 2019 João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Trabalho de Conclusão do Curso do Curso de Graduação em Ciências da Computação do Centro Tecnológico da Universidade Federal de Santa Catarina como requisito para ob- tenção do título de Bacharel em Ciências da Computação. Orientador: Prof. Márcio Bastos Castro, Dr. Coorientador: Pedro Henrique Penna, Me. Florianópolis 6 de dezembro de 2019 Ficha de identificação da obra elaborada pelo autor, através do Programa de Geração Automática da Biblioteca Universitária da UFSC. Souto, João Vicente An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS / João Vicente Souto ; orientador, Márcio Bastos Castro , coorientador, Pedro Henrique Penna , 2019. 92 p. Trabalho de Conclusão de Curso (graduação) - Universidade Federal de Santa Catarina, Centro Tecnológico, Graduação em Ciências da Computação, Florianópolis, 2019. Inclui referências. 1. Ciências da Computação. 2. Sistema Operacional Distribuído. 3. Camada de Abstração de Hardware. 4. Processador Lightweight Manycore. 5. Kalray MPPA-256. I. , Márcio Bastos Castro. II. , Pedro Henrique Penna. III. Universidade Federal de Santa Catarina. Graduação em Ciências da Computação. IV. Título. João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Este Trabalho de Conclusão do Curso foi julgado adequado para obtenção do Título de Bacharel em Ciências da Computação e aprovado em sua forma final pelo curso de Graduação em Ciências da Computação. -

A Performance Analysis of the First Generation of HPC-Optimized Arm Processors
McIntosh-Smith, S., Price, J., Deakin, T., & Poenaru, A. (2019). A performance analysis of the first generation of HPC-optimized Arm processors. Concurrency and Computation: Practice and Experience, 31(16), [e5110]. https://doi.org/10.1002/cpe.5110 Publisher's PDF, also known as Version of record License (if available): CC BY Link to published version (if available): 10.1002/cpe.5110 Link to publication record in Explore Bristol Research PDF-document This is the final published version of the article (version of record). It first appeared online via Wiley at https://doi.org/10.1002/cpe.5110 . Please refer to any applicable terms of use of the publisher. University of Bristol - Explore Bristol Research General rights This document is made available in accordance with publisher policies. Please cite only the published version using the reference above. Full terms of use are available: http://www.bristol.ac.uk/red/research-policy/pure/user-guides/ebr-terms/ Received: 18 June 2018 Revised: 27 November 2018 Accepted: 27 November 2018 DOI: 10.1002/cpe.5110 SPECIAL ISSUE PAPER A performance analysis of the first generation of HPC-optimized Arm processors Simon McIntosh-Smith James Price Tom Deakin Andrei Poenaru High Performance Computing Research Group, Department of Computer Science, Summary University of Bristol, Bristol, UK In this paper, we present performance results from Isambard, the first production supercomputer Correspondence to be based on Arm CPUs that have been optimized specifically for HPC. Isambard is the first Simon McIntosh-Smith, High Performance Cray XC50 ‘‘Scout’’ system, combining Cavium ThunderX2 Arm-based CPUs with Cray's Aries Computing Research Group, Department of interconnect.