Industry Insights | HPC and the Future of Seismic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

Performance Analysis on Energy Efficient High
Performance Analysis on Energy Efficient High-Performance Architectures Roman Iakymchuk, François Trahay To cite this version: Roman Iakymchuk, François Trahay. Performance Analysis on Energy Efficient High-Performance Architectures. CC’13 : International Conference on Cluster Computing, Jun 2013, Lviv, Ukraine. hal-00865845 HAL Id: hal-00865845 https://hal.archives-ouvertes.fr/hal-00865845 Submitted on 25 Sep 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Performance Analysis on Energy Ecient High-Performance Architectures Roman Iakymchuk1 and François Trahay1 1Institut Mines-Télécom Télécom SudParis 9 Rue Charles Fourier 91000 Évry France {roman.iakymchuk, francois.trahay}@telecom-sudparis.eu Abstract. With the shift in high-performance computing (HPC) towards energy ecient hardware architectures such as accelerators (NVIDIA GPUs) and embedded systems (ARM processors), arose the need to adapt existing perfor- mance analysis tools to these new systems. We present EZTrace a performance analysis framework for parallel applications. EZTrace relies on several core components, in particular on a mechanism for instrumenting func- tions, a lightweight tool for recording events, and a generic interface for writing traces. To support EZTrace on energy ecient HPC systems, we developed a CUDA module and ported EZTrace to ARM processors. -

Science-Driven Development of Supercomputer Fugaku
Special Contribution Science-driven Development of Supercomputer Fugaku Hirofumi Tomita Flagship 2020 Project, Team Leader RIKEN Center for Computational Science In this article, I would like to take a historical look at activities on the application side during supercomputer Fugaku’s climb to the top of supercomputer rankings as seen from a vantage point in early July 2020. I would like to describe, in particular, the change in mindset that took place on the application side along the path toward Fugaku’s top ranking in four benchmarks in 2020 that all began with the Application Working Group and Computer Architecture/Compiler/ System Software Working Group in 2011. Somewhere along this path, the application side joined forces with the architecture/system side based on the keyword “co-design.” During this journey, there were times when our opinions clashed and when efforts to solve problems came to a halt, but there were also times when we took bold steps in a unified manner to surmount difficult obstacles. I will leave the description of specific technical debates to other articles, but here, I would like to describe the flow of Fugaku development from the application side based heavily on a “science-driven” approach along with some of my personal opinions. Actually, we are only halfway along this path. We look forward to the many scientific achievements and so- lutions to social problems that Fugaku is expected to bring about. 1. Introduction In this article, I would like to take a look back at On June 22, 2020, the supercomputer Fugaku the flow along the path toward Fugaku’s top ranking became the first supercomputer in history to simul- as seen from the application side from a vantage point taneously rank No. -

This Is Your Presentation Title
Introduction to GPU/Parallel Computing Ioannis E. Venetis University of Patras 1 Introduction to GPU/Parallel Computing www.prace-ri.eu Introduction to High Performance Systems 2 Introduction to GPU/Parallel Computing www.prace-ri.eu Wait, what? Aren’t we here to talk about GPUs? And how to program them with CUDA? Yes, but we need to understand their place and their purpose in modern High Performance Systems This will make it clear when it is beneficial to use them 3 Introduction to GPU/Parallel Computing www.prace-ri.eu Top 500 (June 2017) CPU Accel. Rmax Rpeak Power Rank Site System Cores Cores (TFlop/s) (TFlop/s) (kW) National Sunway TaihuLight - Sunway MPP, Supercomputing Center Sunway SW26010 260C 1.45GHz, 1 10.649.600 - 93.014,6 125.435,9 15.371 in Wuxi Sunway China NRCPC National Super Tianhe-2 (MilkyWay-2) - TH-IVB-FEP Computer Center in Cluster, Intel Xeon E5-2692 12C 2 Guangzhou 2.200GHz, TH Express-2, Intel Xeon 3.120.000 2.736.000 33.862,7 54.902,4 17.808 China Phi 31S1P NUDT Swiss National Piz Daint - Cray XC50, Xeon E5- Supercomputing Centre 2690v3 12C 2.6GHz, Aries interconnect 3 361.760 297.920 19.590,0 25.326,3 2.272 (CSCS) , NVIDIA Tesla P100 Cray Inc. DOE/SC/Oak Ridge Titan - Cray XK7 , Opteron 6274 16C National Laboratory 2.200GHz, Cray Gemini interconnect, 4 560.640 261.632 17.590,0 27.112,5 8.209 United States NVIDIA K20x Cray Inc. DOE/NNSA/LLNL Sequoia - BlueGene/Q, Power BQC 5 United States 16C 1.60 GHz, Custom 1.572.864 - 17.173,2 20.132,7 7.890 4 Introduction to GPU/ParallelIBM Computing www.prace-ri.eu How do -

Germany's Top500 Businesses
GERMANY’S TOP500 DIGITAL BUSINESS MODELS IN SEARCH OF BUSINESS CONTENTS FOREWORD 3 INSIGHT 1 4 SLOW GROWTH RATES YET HIGH SALES INSIGHT 2 6 NOT ENOUGH REVENUE IS ATTRIBUTABLE TO DIGITIZATION INSIGHT 3 10 EU REGULATIONS ARE WEAKENING INNOVATION INSIGHT 4 12 THE GERMAN FEDERAL GOVERNMENT COULD TURN INTO AN INNOVATION DRIVER CONCLUSION 14 FOREWORD Large German companies are on the lookout. Their purpose: To find new growth prospects. While revenue increases of more than 5 percent on average have not been uncommon for Germany’s 500 largest companies in the past, that level of growth has not occurred for the last four years. The reasons are obvious. With their high export rates, This study is intended to examine critically the Germany’s industrial companies continue to be major opportunities arising at the beginning of a new era of players in the global market. Their exports have, in fact, technology. Accenture uses four insights to not only been so high in the past that it is now increasingly describe the progress that has been made in digital difficult to sustain their previous rates of growth. markets, but also suggests possible steps companies can take to overcome weak growth. Accenture regularly examines Germany’s largest companies on the basis of their ranking in “Germany’s Top500,” a list published every year in the German The four insights in detail: daily newspaper DIE WELT. These 500 most successful German companies generate revenue of more than INSIGHT 1 one billion Euros. In previous years, they were the Despite high levels of sales, growth among Germany’s engines of the German economy. -
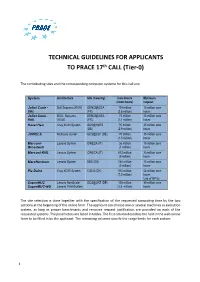
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

Supercomputer Fugaku
Supercomputer Fugaku Toshiyuki Shimizu Feb. 18th, 2020 FUJITSU LIMITED Copyright 2020 FUJITSU LIMITED Outline ◼ Fugaku project overview ◼ Co-design ◼ Approach ◼ Design results ◼ Performance & energy consumption evaluation ◼ Green500 ◼ OSS apps ◼ Fugaku priority issues ◼ Summary 1 Copyright 2020 FUJITSU LIMITED Supercomputer “Fugaku”, formerly known as Post-K Focus Approach Application performance Co-design w/ application developers and Fujitsu-designed CPU core w/ high memory bandwidth utilizing HBM2 Leading-edge Si-technology, Fujitsu's proven low power & high Power efficiency performance logic design, and power-controlling knobs Arm®v8-A ISA with Scalable Vector Extension (“SVE”), and Arm standard Usability Linux 2 Copyright 2020 FUJITSU LIMITED Fugaku project schedule 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 Fugaku development & delivery Manufacturing, Apps Basic Detailed design & General Feasibility study Installation review design Implementation operation and Tuning Select Architecture & Co-Design w/ apps groups apps sizing 3 Copyright 2020 FUJITSU LIMITED Fugaku co-design ◼ Co-design goals ◼ Obtain the best performance, 100x apps performance than K computer, within power budget, 30-40MW • Design applications, compilers, libraries, and hardware ◼ Approach ◼ Estimate perf & power using apps info, performance counts of Fujitsu FX100, and cycle base simulator • Computation time: brief & precise estimation • Communication time: bandwidth and latency for communication w/ some attributes for communication patterns • I/O time: ◼ Then, optimize apps/compilers etc. and resolve bottlenecks ◼ Estimation of performance and power ◼ Precise performance estimation for primary kernels • Make & run Fugaku objects on the Fugaku cycle base simulator ◼ Brief performance estimation for other sections • Replace performance counts of FX100 w/ Fugaku params: # of inst. commit/cycle, wait cycles of barrier, inst. -

Measuring Power Consumption on IBM Blue Gene/P
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Springer - Publisher Connector Comput Sci Res Dev DOI 10.1007/s00450-011-0192-y SPECIAL ISSUE PAPER Measuring power consumption on IBM Blue Gene/P Michael Hennecke · Wolfgang Frings · Willi Homberg · Anke Zitz · Michael Knobloch · Hans Böttiger © The Author(s) 2011. This article is published with open access at Springerlink.com Abstract Energy efficiency is a key design principle of the Top10 supercomputers on the November 2010 Top500 list IBM Blue Gene series of supercomputers, and Blue Gene [1] alone (which coincidentally are also the 10 systems with systems have consistently gained top GFlops/Watt rankings an Rpeak of at least one PFlops) are consuming a total power on the Green500 list. The Blue Gene hardware and man- of 33.4 MW [2]. These levels of power consumption are al- agement software provide built-in features to monitor power ready a concern for today’s Petascale supercomputers (with consumption at all levels of the machine’s power distribu- operational expenses becoming comparable to the capital tion network. This paper presents the Blue Gene/P power expenses for procuring the machine), and addressing the measurement infrastructure and discusses the operational energy challenge clearly is one of the key issues when ap- aspects of using this infrastructure on Petascale machines. proaching Exascale. We also describe the integration of Blue Gene power moni- While the Flops/Watt metric is useful, its emphasis on toring capabilities into system-level tools like LLview, and LINPACK performance and thus computational load ne- highlight some results of analyzing the production workload glects the fact that the energy costs of memory references at Research Center Jülich (FZJ). -

Providing a Robust Tools Landscape for CORAL Machines
Providing a Robust Tools Landscape for CORAL Machines 4th Workshop on Extreme Scale Programming Tools @ SC15 in AusGn, Texas November 16, 2015 Dong H. Ahn Lawrence Livermore Naonal Lab Michael Brim Oak Ridge Naonal Lab Sco4 Parker Argonne Naonal Lab Gregory Watson IBM Wesley Bland Intel CORAL: Collaboration of ORNL, ANL, LLNL Current DOE Leadership Computers Objective - Procure 3 leadership computers to be Titan (ORNL) Sequoia (LLNL) Mira (ANL) 2012 - 2017 sited at Argonne, Oak Ridge and Lawrence Livermore 2012 - 2017 2012 - 2017 in 2017. Leadership Computers - RFP requests >100 PF, 2 GiB/core main memory, local NVRAM, and science performance 4x-8x Titan or Sequoia Approach • Competitive process - one RFP (issued by LLNL) leading to 2 R&D contracts and 3 computer procurement contracts • For risk reduction and to meet a broad set of requirements, 2 architectural paths will be selected and Oak Ridge and Argonne must choose different architectures • Once Selected, Multi-year Lab-Awardee relationship to co-design computers • Both R&D contracts jointly managed by the 3 Labs • Each lab manages and negotiates its own computer procurement contract, and may exercise options to meet their specific needs CORAL Innova,ons and Value IBM, Mellanox, and NVIDIA Awarded $325M U.S. Department of Energy’s CORAL Contracts • Scalable system solu.on – scale up, scale down – to address a wide range of applicaon domains • Modular, flexible, cost-effec.ve, • Directly leverages OpenPOWER partnerships and IBM’s Power system roadmap • Air and water cooling • Heterogeneous -

Summit Supercomputer
Cooling System Overview: Summit Supercomputer David Grant, PE, CEM, DCEP HPC Mechanical Engineer Oak Ridge National Laboratory Corresponding Member of ASHRAE TC 9.9 Infrastructure Co-Lead - EEHPCWG ORNL is managed by UT-Battelle, LLC for the US Department of Energy Today’s Presentation #1 ON THE TOP 500 LIST • System Description • Cooling System Components • Cooling System Performance NOVEMBER 2018 #1 JUNE 2018 #1 2 Feature Titan Summit Summit Node Overview Application Baseline 5-10x Titan Performance Number of 18,688 4,608 Nodes Node 1.4 TF 42 TF performance Memory per 32 GB DDR3 + 6 GB 512 GB DDR4 + 96 GB Node GDDR5 HBM2 NV memory per 0 1600 GB Node Total System >10 PB DDR4 + HBM2 + 710 TB Memory Non-volatile System Gemini (6.4 GB/s) Dual Rail EDR-IB (25 GB/s) Interconnect Interconnect 3D Torus Non-blocking Fat Tree Topology Bi-Section 15.6 TB/s 115.2 TB/s Bandwidth 1 AMD Opteron™ 2 IBM POWER9™ Processors 1 NVIDIA Kepler™ 6 NVIDIA Volta™ 32 PB, 1 TB/s, File System 250 PB, 2.5 TB/s, GPFS™ Lustre® Peak Power 9 MW 13 MW Consumption 3 System Description – How do we cool it? • >100,000 liquid connections 4 System Description – What’s in the data center? • Passive RDHXs- 215,150ft2 (19,988m2) of total heat exchange surface (>20X the area of the data center) – With a 70°F (21.1 °C) entering water temperature, the room averages ~73°F (22.8°C) with ~3.5MW load and ~75.5°F (23.9°C) with ~10MW load. -

Compute System Metrics (Bof)
Setting Trends for Energy-Efficient Supercomputing Natalie Bates, EE HPC Working Group Tahir Cader, HP & The Green Grid Wu Feng, Virginia Tech & Green500 John Shalf, Berkeley Lab & NERSC Horst Simon, Berkeley Lab & TOP500 Erich Strohmaier, Berkeley Lab & TOP500 ISC BoF; May 31, 2010; Hamburg, Germany Why We Are Here • “Can only improve what you can measure” • Context – Power consumption of HPC and facilities cost are increasing • What is needed? – Converge on a common basis between different research and industry groups for: •metrics • methodologies • workloads for energy-efficient supercomputing, so we can make progress towards solutions. Current Technology Roadmaps will Depart from Historical Gains Power is the Leading Design Constraint From Peter Kogge, DARPA Exascale Study … and the power costs will still be staggering From Peter Kogge, DARPA Exascale Study $1M per megawatt per year! (with CHEAP power) Absolute Power Levels Power Consumption Power Efficiency What We Have Done • Stages of Green Supercomputing – Denial – Awareness – Hype – Substance The Denial Phase (2001 – 2004) • Green Destiny – A 240-Node Supercomputer in 5 Sq. Ft. – LINPACK Performance: 101 Gflops – Power Consumption: 3.2 kW • Prevailing Views embedded processor – “Green Destiny is so low power that it runs just as fast when it is unplugged.” – “In HPC, no one cares about power & cooling, and no one ever will …” – “Moore’s Law for Power will stimulate the economy by creating a new market in cooling technologies.” The Awareness Phase (2004 – 2008) • Green Movements & Studies – IEEE Int’l Parallel & Distributed Processing Symp. (2005) • Workshop on High-Performance, Power-Aware Computing (HPPAC) Green500 • Metrics: Energy-Delay Product and FLOPS/Watt FLOPS/watt – Green Grid (2007) • Industry-driven consortium of all the top system vendors • Metric: Power Usage Efficiency (PUE) – Kogge et al., “ExaScale Computing Study: Technology Challenges in Achieving Exascale Systems, DARPA ITO, AFRL, 2008. -

Presentación De Powerpoint
Towards Exaflop Supercomputers Prof. Mateo Valero Director of BSC, Barcelona National U. of Defense Technology (NUDT) Tianhe-1A • Hybrid architecture: • Main node: • Two Intel Xeon X5670 2.93 GHz 6-core Westmere, 12 MB cache • One Nvidia Tesla M2050 448-ALU (16 SIMD units) 1150 MHz Fermi GPU: • 32 GB memory per node • 2048 Galaxy "FT-1000" 1 GHz 8-core processors • Number of nodes and cores: • 7168 main nodes * (2 sockets * 6 CPU cores + 14 SIMD units) = 186368 cores (not including 16384 Galaxy cores) • Peak performance (DP): • 7168 nodes * (11.72 GFLOPS per core * 6 CPU cores * 2 sockets + 36.8 GFLOPS per SIMD unit * 14 SIMD units per GPU) = 4701.61 TFLOPS • Linpack performance: 2.507 PF 53% efficiency • Power consumption 4.04 MWatt Source http://blog.zorinaq.com/?e=36 Cartagena, Colombia, May 18-20 Top10 Rank Site Computer Procs Rmax Rpeak 1 Tianjin, China XeonX5670+NVIDIA 186368 2566000 4701000 2 Oak Ridge Nat. Lab. Cray XT5,6 cores 224162 1759000 2331000 3 Shenzhen, China XeonX5670+NVIDIA 120640 1271000 2984300 4 GSIC Center, Tokyo XeonX5670+NVIDIA 73278 1192000 2287630 5 DOE/SC/LBNL/NERSC Cray XE6 12 cores 153408 1054000 1288630 Commissariat a l'Energie Bull bullx super-node 6 138368 1050000 1254550 Atomique (CEA) S6010/S6030 QS22/LS21 Cluster, 7 DOE/NNSA/LANL PowerXCell 8i / Opteron 122400 1042000 1375780 Infiniband National Institute for 8 Computational Cray XT5-HE 6 cores 98928 831700 1028850 Sciences/University of Tennessee 9 Forschungszentrum Juelich (FZJ) Blue Gene/P Solution 294912 825500 825500 10 DOE/NNSA/LANL/SNL Cray XE6 8-core 107152 816600 1028660 Cartagena, Colombia, May 18-20 Looking at the Gordon Bell Prize • 1 GFlop/s; 1988; Cray Y-MP; 8 Processors • Static finite element analysis • 1 TFlop/s; 1998; Cray T3E; 1024 Processors • Modeling of metallic magnet atoms, using a variation of the locally self-consistent multiple scattering method.