A $ N $-Body Solver for Square Root Iteration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Metalloboranes from First-Principles Calculations: a Candidate for High-Density Hydrogen Storage
Metalloboranes from first-principles calculations: A candidate for high-density hydrogen storage A. R. Akbarzadeh, D. Vrinceanu, and C.J. Tymczak Department of Physics, Texas Southern University, Houston, Texas 77004, USA Abstract Using first principles calculations, we show the high hydrogen storage capacity of a new class of compounds, metalloboranes. Metalloboranes are transition metal (TM) and borane compounds that obey a novel-bonding scheme. We have found that the transition metal atoms can bind up to 10 H2-molecules with an average binding energy of 30 kJ/mole of H2, which lies favorably within the reversible adsorption range. Among the first row TM atoms, Sc and Ti are found to be the optimum in maximizing the H2 storage on the metalloborane cluster. Additionally, being ionically bonded to the borane molecule, the TMs do not suffer from the aggregation problem, which has been the biggest hurdle for the success of TM- decorated graphitic materials for hydrogen storage. Furthermore, since the borane 6-atom ring has identical bonding properties as carbon rings it is possible to link the metalloboranes into metal organic frameworks (MOF’s), which are thus able to adsorb hydrogen via Kubas interaction as well as the well-known van der Waals interaction. Finally, we construct a simple Monte-Catlo algorithm for Hydrogen uptake and show that Titanium metalloboranes in a MOF5 structure can absorb up to 11.5% hydrogen per weight at 100 bar of pressure. I. Introduction Due to the geographical distribution and supply limitation of fossil fuel resources and the increasing perceived negative impact of carbon dioxide emission in the environment, it is advantageous for the societies to take action in the search and implementation of alternative energy systems. -

Polynomial Transformations of Tschirnhaus, Bring and Jerrard
ACM SIGSAM Bulletin, Vol 37, No. 3, September 2003 Polynomial Transformations of Tschirnhaus, Bring and Jerrard Victor S. Adamchik Department of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA [email protected] David J. Jeffrey Department of Applied Mathematics, The University of Western Ontario, London, Ontario, Canada [email protected] Abstract Tschirnhaus gave transformations for the elimination of some of the intermediate terms in a polynomial. His transformations were developed further by Bring and Jerrard, and here we describe all these transformations in modern notation. We also discuss their possible utility for polynomial solving, particularly with respect to the Mathematica poster on the solution of the quintic. 1 Introduction A recent issue of the BULLETIN contained a translation of the 1683 paper by Tschirnhaus [10], in which he proposed a method for solving a polynomial equation Pn(x) of degree n by transforming it into a polynomial Qn(y) which has a simpler form (meaning that it has fewer terms). Specifically, he extended the idea (which he attributed to Decartes) in which a polynomial of degree n is reduced or depressed (lovely word!) by removing its term in degree n ¡ 1. Tschirnhaus’s transformation is a polynomial substitution y = Tk(x), in which the degree of the transformation k < n can be selected. Tschirnhaus demonstrated the utility of his transformation by apparently solving the cubic equation in a way different from Cardano. Although Tschirnhaus’s work is described in modern books [9], later works by Bring [2, 3] and Jerrard [7, 6] have been largely forgotten. Here, we present the transformations in modern notation and make some comments on their utility. -

SIGLOG: Special Interest Group on Logic and Computation a Proposal
SIGLOG: Special Interest Group on Logic and Computation A Proposal Natarajan Shankar Computer Science Laboratory SRI International Menlo Park, CA Mar 21, 2014 SIGLOG: Executive Summary Logic is, and will continue to be, a central topic in computing. ACM has a core constituency with an interest in Logic and Computation (L&C), witnessed by 1 The many Turing Awards for work centrally in L&C 2 The ACM journal Transactions on Computational Logic 3 Several long-running conferences like LICS, CADE, CAV, ICLP, RTA, CSL, TACAS, and MFPS, and super-conferences like FLoC and ETAPS SIGLOG explores the connections between logic and computing covering theory, semantics, analysis, and synthesis. SIGLOG delivers value to its membership through the coordination of conferences, journals, newsletters, awards, and educational programs. SIGLOG enjoys significant synergies with several existing SIGs. Natarajan Shankar SIGLOG 2/9 Logic and Computation: Early Foundations Logicians like Alonzo Church, Kurt G¨odel, Alan Turing, John von Neumann, and Stephen Kleene have played a pioneering role in laying the foundation of computing. In the last 65 years, logic has become the calculus of computing underpinning the foundations of many diverse sub-fields. Natarajan Shankar SIGLOG 3/9 Logic and Computation: Turing Awardees Turing awardees for logic-related work include John McCarthy, Edsger Dijkstra, Dana Scott Michael Rabin, Tony Hoare Steve Cook, Robin Milner Amir Pnueli, Ed Clarke Allen Emerson Joseph Sifakis Leslie Lamport Natarajan Shankar SIGLOG 4/9 Interaction between SIGLOG and other SIGs Logic interacts in a significant way with AI (SIGAI), theory of computation (SIGACT), databases (SIGMOD) and knowledge bases (SIGKDD), programming languages (SIGPLAN), software engineering (SIGSOFT), computational biology (SIGBio), symbolic computing (SIGSAM), semantic web (SIGWEB), and hardware design (SIGDA and SIGARCH). -

Presidential Search Committee Meets, Reviews Upcoming Work
ETHEMedford, MA 02155 TUFTSTuesday, November 26,1991 DAILYJVol XXIII, Number 58 Faculty tables vote on Presidential search committee World Civ proposal meets, reviews upcoming work courses iUC to be intcrdiscipli by SCHAEF1cR nary. intcgr;ltblg disciplines fr()n by MAUREEN LENIHAN Senior Staff Writer Daily Editorial Board and PATRICK HEALY at leiist three of the five distribu The 19-member search com- Dally Edil(~r1alhtUd tion areas. mittee fonned to begin the pro- Although the proposed World Since 1986. threeteamsoffac cess of selecting anew university CivilizationsFoundation rcquire- ult y. including one professor frorr president met for the first time inent was briefly presented at the the School ofEngineering,devel yesterday, familiariz,ing them- Liberal Arts and Jackson facully oped three two-semester course: selves with their task and the meeting yesterday. the LAM fac- which were ultiinately opened tc committee‘s initial duties includ- ulty postponed further discussion students to take on a voluntce ing formali~inga Job description and voting on the prognun until basis. These courses, titled “P for the post. Dec. 11. Sense of Place.” “Time and Cal The committee. representing Dean of College of Liberal endars,“and “Memory and Iden trustees. administrators, faculty Arts and Jackson Mary Ella tity.“wereestablishedwith fincan members. staff members. stu- Fcinleibmoved tocrcate the Dec. cia1 support from ihe Davis Foun dents. and alumni, was fonncd in 1 I meeting since other meeting dation. the National Endowmen response toai miouiiccmcnt last topics preceding the World Civ for the Humimities, and the Uni May that University president presentation took up most of the versit y. -

© in This Web Service Cambridge University Press
Cambridge University Press 978-1-107-03903-2 - Modern Computer Algebra: Third Edition Joachim Von Zur Gathen and Jürgen Gerhard Index More information Index A page number is underlined (for example: 667) when it represents the definition or the main source of information about the index entry. For several key words that appear frequently only ranges of pages or the most important occurrences are indexed. AAECC ......................................... 21 analytic number theory . 508, 523, 532, 533, 652 Abbott,John .............................. 465, 734 AnalyticalEngine ............................... 312 Abel,NielsHenrik .............................. 373 Andrews, George Eyre . 644, 697, 729, 735 Abeliangroup ................................... 704 QueenAnne .................................... 219 Abramov, Serge˘ı Aleksandrovich (Abramov annihilating polynomial ......................... 341 SergeiAleksandroviq) 7, 641, 671, 675, annihilator, Ann( ) .............................. 343 734, 735 annusconfusionis· ................................ 83 Abramson, Michael . 738 Antoniou,Andreas ........................ 353, 735 Achilles ......................................... 162 Antoniszoon, Adrian (Metius) .................... 82 ACM . see Association for Computing Machinery Aoki,Kazumaro .......................... 542, 751 active attack . 580 Apéry, Roger . 671, 684, 697, 761 Adam,Charles .................................. 729 number ....................................... 684 Adams,DouglasNoël ..................... 729, 796 Apollonius of -

O (N) Methods in Electronic Structure Calculations
O(N) Methods in electronic structure calculations D R Bowler1;2;3 and T Miyazaki4 1London Centre for Nanotechnology, UCL, 17-19 Gordon St, London WC1H 0AH, UK 2Department of Physics & Astronomy, UCL, Gower St, London WC1E 6BT, UK 3Thomas Young Centre, UCL, Gower St, London WC1E 6BT, UK 4National Institute for Materials Science, 1-2-1 Sengen, Tsukuba, Ibaraki 305-0047, JAPAN E-mail: [email protected] E-mail: [email protected] Abstract. Linear scaling methods, or O(N) methods, have computational and memory requirements which scale linearly with the number of atoms in the system, N, in contrast to standard approaches which scale with the cube of the number of atoms. These methods, which rely on the short-ranged nature of electronic structure, will allow accurate, ab initio simulations of systems of unprecedented size. The theory behind the locality of electronic structure is described and related to physical properties of systems to be modelled, along with a survey of recent developments in real-space methods which are important for efficient use of high performance computers. The linear scaling methods proposed to date can be divided into seven different areas, and the applicability, efficiency and advantages of the methods proposed in these areas is then discussed. The applications of linear scaling methods, as well as the implementations available as computer programs, are considered. Finally, the prospects for and the challenges facing linear scaling methods are discussed. Submitted to: Rep. Prog. Phys. arXiv:1108.5976v5 [cond-mat.mtrl-sci] 3 Nov 2011 O(N) Methods 2 1. -

Curriculum Vitae
CURRICULUM VITAE Christopher J. Tymczak Tenured Associate Professor Director Department of Physics Texas Southern University High Texas Southern University Performance Computing Center Houston, Texas 77004 Texas Southern University Office: (713) 313-1849 Houston, Texas 77004 Email: [email protected] (http://hpcc.tsu.edu/) (http://physics.tsu.edu/) Co-Director Visiting Research Scientist NSF CREST Center for Research on Group T-1 Complex Networks Los Alamos National Laboratory Texas Southern University Los Alamos, New Mexico, 87507 Houston, Texas 77004 I specialize in the identification, development, and implementation of new scientific codes for exploiting advanced computing resources impacting large scale computation in diverse areas in Many-body physics, Quantum Chemistry and ab initio Molecular Dynamics. I am a tenured associate professor of physics at Texas Southern University, where I am spearheading the integration of supercomputing resources into various STEM programs. I am also the founder and director of the Texas Southern High Performance Computing Center (TSU-HPCC). At Los Alamos National Laboratory, I am a permanent scientific associate within the FreeON initiative, involving the development of massively parallel linear scaling quantum chemistry methods, currently under development in collaboration with Dr. Matt Challacombe (T-12) and Dr. Anders Niklasson (T-1). I was one of the first to exploit wavelet-based methods in large scale computing for understanding the electronic structure of materials. For the last six years, I have advanced the FreeON development through the exploitation of advanced data structures and advanced machine architectures. FreeON is now recognized as one of the first quantum chemical codes with demonstrable scalable parallelism within large- scale parallel clusters. -

Central Library: IIT GUWAHATI
Central Library, IIT GUWAHATI BACK VOLUME LIST DEPARTMENTWISE (as on 20/04/2012) COMPUTER SCIENCE & ENGINEERING S.N. Jl. Title Vol.(Year) 1. ACM Jl.: Computer Documentation 20(1996)-26(2002) 2. ACM Jl.: Computing Surveys 30(1998)-35(2003) 3. ACM Jl.: Jl. of ACM 8(1961)-34(1987); 43(1996);45(1998)-50 (2003) 4. ACM Magazine: Communications of 39(1996)-46#3-12(2003) ACM 5. ACM Magazine: Intelligence 10(1999)-11(2000) 6. ACM Magazine: netWorker 2(1998)-6(2002) 7. ACM Magazine: Standard View 6(1998) 8. ACM Newsletters: SIGACT News 27(1996);29(1998)-31(2000) 9. ACM Newsletters: SIGAda Ada 16(1996);18(1998)-21(2001) Letters 10. ACM Newsletters: SIGAPL APL 28(1998)-31(2000) Quote Quad 11. ACM Newsletters: SIGAPP Applied 4(1996);6(1998)-8(2000) Computing Review 12. ACM Newsletters: SIGARCH 24(1996);26(1998)-28(2000) Computer Architecture News 13. ACM Newsletters: SIGART Bulletin 7(1996);9(1998) 14. ACM Newsletters: SIGBIO 18(1998)-20(2000) Newsletters 15. ACM Newsletters: SIGCAS 26(1996);28(1998)-30(2000) Computers & Society 16. ACM Newsletters: SIGCHI Bulletin 28(1996);30(1998)-32(2000) 17. ACM Newsletters: SIGCOMM 26(1996);28(1998)-30(2000) Computer Communication Review 1 Central Library, IIT GUWAHATI BACK VOLUME LIST DEPARTMENTWISE (as on 20/04/2012) COMPUTER SCIENCE & ENGINEERING S.N. Jl. Title Vol.(Year) 18. ACM Newsletters: SIGCPR 17(1996);19(1998)-20(1999) Computer Personnel 19. ACM Newsletters: SIGCSE Bulletin 28(1996);30(1998)-32(2000) 20. ACM Newsletters: SIGCUE Outlook 26(1998)-27(2001) 21. -

Lawrence Berkeley National Laboratory Recent Work
Lawrence Berkeley National Laboratory Recent Work Title From NWChem to NWChemEx: Evolving with the Computational Chemistry Landscape. Permalink https://escholarship.org/uc/item/4sm897jh Journal Chemical reviews, 121(8) ISSN 0009-2665 Authors Kowalski, Karol Bair, Raymond Bauman, Nicholas P et al. Publication Date 2021-04-01 DOI 10.1021/acs.chemrev.0c00998 Peer reviewed eScholarship.org Powered by the California Digital Library University of California From NWChem to NWChemEx: Evolving with the computational chemistry landscape Karol Kowalski,y Raymond Bair,z Nicholas P. Bauman,y Jeffery S. Boschen,{ Eric J. Bylaska,y Jeff Daily,y Wibe A. de Jong,x Thom Dunning, Jr,y Niranjan Govind,y Robert J. Harrison,k Murat Keçeli,z Kristopher Keipert,? Sriram Krishnamoorthy,y Suraj Kumar,y Erdal Mutlu,y Bruce Palmer,y Ajay Panyala,y Bo Peng,y Ryan M. Richard,{ T. P. Straatsma,# Peter Sushko,y Edward F. Valeev,@ Marat Valiev,y Hubertus J. J. van Dam,4 Jonathan M. Waldrop,{ David B. Williams-Young,x Chao Yang,x Marcin Zalewski,y and Theresa L. Windus*,r yPacific Northwest National Laboratory, Richland, WA 99352 zArgonne National Laboratory, Lemont, IL 60439 {Ames Laboratory, Ames, IA 50011 xLawrence Berkeley National Laboratory, Berkeley, 94720 kInstitute for Advanced Computational Science, Stony Brook University, Stony Brook, NY 11794 ?NVIDIA Inc, previously Argonne National Laboratory, Lemont, IL 60439 #National Center for Computational Sciences, Oak Ridge National Laboratory, Oak Ridge, TN 37831-6373 @Department of Chemistry, Virginia Tech, Blacksburg, VA 24061 4Brookhaven National Laboratory, Upton, NY 11973 rDepartment of Chemistry, Iowa State University and Ames Laboratory, Ames, IA 50011 E-mail: [email protected] 1 Abstract Since the advent of the first computers, chemists have been at the forefront of using computers to understand and solve complex chemical problems. -
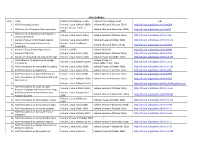
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Robert Grossman Curriculum Vita
Robert Grossman Curriculum Vita Summary Robert Grossman is a faculty member at the University of Chicago, where he is the Director of Informatics at the Institute for Genomics and Systems Biology, a Senior Fellow at the Computation Institute, and a Professor of Medicine in the Section of Genetic Medicine. His research group focuses on bioinformatics, data mining, cloud computing, data intensive computing, and related areas. He is also the Chief Research Informatics Officer of the Biological Sciences Division. From 1998 to 2010, he was the Director of the National Center for Data Mining at the University of Illinois at Chicago (UIC). From 1984 to 1988 he was a faculty member at the University of California at Berkeley. He received a Ph.D. from Princeton in 1985 and a B.A. from Harvard in 1980. He is also the Founder and a Partner of Open Data Group. Open Data provides management consulting and outsourced analytic services for businesses and organizations. At Open Data, he has led the development of analytic systems that are used by millions of people daily all over the world. He has published over 150 papers in refereed journals and proceedings and edited seven books on data intensive computing, bioinformatics, cloud computing, data mining, high performance computing and networking, and Internet technologies. Prior to founding the Open Data Group, he founded Magnify, Inc. in 1996. Magnify provides data mining solutions to the insurance industry. Grossman was Magnify’s CEO until 2001 and its Chairman until it was sold to ChoicePoint in 2005. ChoicePoint was acquired by LexisNexis in 2008. -

FCRC 2011 June 4 - 11, San Jose, CA TIMELINE SCHEDULE
FCRC 2011 June 4 - 11, San Jose, CA TIMELINE SCHEDULE Sponsored by Corporate Support Provided by Gold Silver CONFERENCE/WORKSHOP/EVENT ACRONYMS & DATES Dates Full Name Dates Full Name 3DAPAS 8 A Workshop on Dynamic Distrib. Data-Intensive Applications, Programming Abstractions, & Systs (HPDC) IWQoS 6--7 Int. Workshop on Quality of Service (ACM SIGMETRICS and IEEE Communications Society) A4MMC 4 Applications fo Multi and Many Core Processors: Analysis, Implementation, and Performance (ISCA) LSAP 8 P Workshop on Large-Scale System and Application Performance (HPDC) AdAuct 5 Ad Auction Workshop (EC) MAMA 8 Workshop on Mathematical Performance Modeling and Analysis (METRICS) AMAS-BT 4 P Workship on Architectural and Microarchitectural Support for Binary Translation (ISCA) METRICS 7--11 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems BMD 5 Workshop on Bayesian Mechanism Design (EC) MoBS 5 A Workshop on Modeling, Benchmarking, and Simulation (ISCA) CARD 5 P Workshop on Computer Architecture Research Directions (ISCA) MRA 8 Int. Workshop on MapReduce and its Applications (HPDC) CBP 4 P JILP Workshop on Computer Architecture Competitions: Championship Branch Prediction (ISCA) MSPC 5 Memory Systems Performance and Correctness (PLDI) Complex 8--10 IEEE Conference on Computational Complexity (IEEE TCMFC) NDCA 5 A New Directions in Computer Architecture (ISCA) CRA-W 4--5 CRA-W Career Mentoring Workshop NetEcon 6 Workshop on the Economics of Networks, Systems, and Computation (EC) DIDC 8 P Int. Workshop on Data-Intensive Distributed Computing (HPDC) PLAS 5 Programming Languages and Analysis for Security Workshop (PLDI) EAMA 4 Workshop on Emerging Applications and Manycore Architectures (ISCA) PLDI 4--8 ACM SIGPLAN Conference on Programming Language Design and Implementation EC 5--9 ACM Conference on Electronic Commerce (ACM SIGECOM) PODC 6--8 ACM SIGACT-SIGOPT Symp.