From the Buzzing in Turing's Head to Machine Intelligence Contests
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Turing Test Round One Loebner Prize Competition: November 8
Summer 1 9 9 1 r Museum I VVS Turing Test Round One Loebner Prize Competition: November 8 The first round of the classic Turing Test of While the subject has been debated for machine intelligence will be held November 8, decades, artificial intelligence experts will get 1991 , at The Computer Museum. New York their first shot at a Turing Test real-time this philanthropist Dr. Hugh Loebner, President of fall at the Museum. Instead of being open Crown Industries, Inc., has offered a $100,000 ended- a challenge that no computer can prize for the first machine to pass the test. The approach at this time-each "conversation" historic contest is being will be limited to a particular subject to give ".. .ang computer that actuallg passes the unrestricted administered by the Cambridge the computer a better chance. Using a format (MA) Center for Behavioral akin to a public chess match, the judges will Turing Test will he. in euerg theoreticallg interesting Studies and the Museum. hold conversations on several computer In 1950, the brilliant British terminals in the Museum's auditorium. The sense. athinking thing. "[Daniel t Dennett] mathematician Alan Turing responses of each terminal will be controlled issued the ultimate challenge to either by "human confederates" or computers. computer science. He proposed an experiment The audience will be able to see the conversa to determine if a machine could think. His test tions on large screens near each terminal. requires a computer to emulate human behavior Afterwards, the tally of scores comparing (via a computer terminal) so well that it fools human and computer performances will be human judges into thinking its responses are announced. -

Can Machines Think?
Sandringham School Faculty of Computer Science Can Machines Think? This is a question posed by famous English Computer Scientist Alan Turing in Intelligent machines and programmes are judged. 1950. His ‘Turing Test’ has become the benchmark by which Artificially Recently, the Turing Test hit the news when a programme that simulated a 13 year old Ukrainian boy (called Eugene Goostman) managed to convince a third of testers that they were talking to a real human. http://www.bbc.co.uk/news/technology-27762088 http://www.reading.ac.uk/news-and-events/releases/PR583836.aspx http://www.alicebot.org/chatbots3/Eugene.pdf Your summer assignment is as follows: 1. 2. DesigningInvestigate a who fully Alan functional Turing Chatbot was and that explain can process in detail human what the language ‘Turing is oneTest’ of is the and most how difficult it is important tasks in in Computer the world Science. of Artificial Why Intelligence is this, what are the challenges? How did the Eugene Goostman bot overcome these? 3. Time to write your own Chatbot. In any language you choose (e.g. Python, Scratch, Java etc.), write a simple Chatbot. Clearly you will have to limit the questions that your bot can ask and the responses that it will Chatbot called Eliza at : https://groklearning.com/csedweek/hoc-eliza/ 4. What‘understand’! are the positiveIf you are implications totally stuck, for see the getting development started ofwith Artificial a simple Intelligence? What are the dangers to society of truly intelligent machines? Your assignment should be at least 4 pages of A4, excluding the programme listing. -

Language Technologies Past Present, and Future
Language technologies past present, and future Christopher Potts CSLI Summer Internship Program July 21, 2017 Many slides joint work with Bill MacCartney: http://web.stanford.edu/class/cs224u/ Hype and hand-wringing • Jürgen Schmidhuber: “We are on the verge not of another industrial revolution, but a new form of life, more like the big bang.” [link] • Elon Musk: “AI is a fundamental existential risk for human civilization, and I don't think people fully appreciate that.” [link] • October 2016: “Microsoft has made a major breakthrough in speech recognition, creating a technology that recognizes the words in a conversation as well as a person does.” [link] Two perspectives Overview • What is understanding? • A brief history of language technologies • Language technologies of the past • Language technologies of today • Current approaches and prospects • Predictions about the future! Readings and other background • Percy Liang: Talking to computers in natural language • Levesque: On our best behaviour • Mitchell: Reading the Web: A breakthrough goal for AI • Podcast: The challenge and promise of artificial intelligence • Podcast: Hal Daume on Talking Machines • Stanford CS224u, Natural language understanding What is understanding? To understand a statement is to: • determine its truth (with justification) • calculate its entailments • take appropriate action in light of it • translate it into another language • … The Turing Test (Turing 1950) Turing replaced “Can machines think?”, which he regarded as “too meaningless to deserve discussion” (p. 442), with the question whether an interrogator could be tricked into thinking that a machine was a human using only conversation (no visuals, no demands for physical performance, etc.). Some of the objections Turing anticipates • “Thinking is a function of man’s immortal soul. -

Lessons from a Restricted Turing Test
Lessons from a Restricted Turing Test Stuart M. Shieber Aiken Computation Laboratory Division of Applied Sciences Harvard University March 28, 1994 (Revision 6) Abstract We report on the recent Loebner prize competition inspired by Turing’s test of intelligent behavior. The presentation covers the structure of the competition and the outcome of its first instantiation in an actual event, and an analysis of the purpose, design, and appropriateness of such a competition. We argue that the competition has no clear purpose, that its design prevents any useful outcome, and that such a competition is inappropriate given the current level of technology. We then speculate as to suitable alternatives to the Loebner prize. arXiv:cmp-lg/9404002v1 4 Apr 1994 This paper is to appear in Communications of the Association for Comput- ing Machinery, and is available from the Center for Research in Computing Technology, Harvard University, as Technical Report TR-19-92 and from the Computation and Language e-print server as cmp-lg/9404002. The Turing Test and the Loebner Prize The English logician and mathematician Alan Turing, in an attempt to develop a working definition of intelligence free of the difficulties and philosophical pitfalls of defining exactly what constitutes the mental process of intelligent reasoning, devised a test, instead, of intelligent behavior. The idea, codified in his cel- ebrated 1950 paper “Computing Machinery and Intelligence” (Turing, 1950), was specified as an “imitation game” in which a judge attempts to distinguish which of two agents is a human and which a computer imitating human re- sponses by engaging each in a wide-ranging conversation of any topic and tenor. -

I V Anthropomorphic Attachments in U.S. Literature, Robotics, And
Anthropomorphic Attachments in U.S. Literature, Robotics, and Artificial Intelligence by Jennifer S. Rhee Program in Literature Duke University Date:_______________________ Approved: ___________________________ Kenneth Surin, Supervisor ___________________________ Mark Hansen ___________________________ Michael Hardt ___________________________ Katherine Hayles ___________________________ Timothy Lenoir Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Literature in the Graduate School of Duke University 2010 i v ABSTRACT Anthropomorphic Attachments in U.S. Literature, Robotics, and Artificial Intelligence by Jennifer S. Rhee Program in Literature Duke University Date:_______________________ Approved: ___________________________ Kenneth Surin, Supervisor ___________________________ Mark Hansen ___________________________ Michael Hardt ___________________________ Katherine Hayles ___________________________ Timothy Lenoir An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Literature in the Graduate School of Duke University 2010 Copyright by Jennifer S. Rhee 2010 Abstract “Anthropomorphic Attachments” undertakes an examination of the human as a highly nebulous, fluid, multiple, and often contradictory concept, one that cannot be approached directly or in isolation, but only in its constitutive relationality with the world. Rather than trying to find a way outside of the dualism between human and not- human, -

Why Python for Chatbots
Schedule: 1. History of chatbots and Artificial Intelligence 2. The growing role of Chatbots in 2020 3. A hands on look at the A.I Chatbot learning sequence 4. Q & A Session Schedule: 1. History of chatbots and Artificial Intelligence 2. The growing role of Chatbots in 2020 3. A hands on look at the A.I Chatbot learning sequence 4. Q & A Session Image credit: Archivio GBB/Contrasto/Redux History •1940 – The Bombe •1948 – Turing Machine •1950 – Touring Test •1980 Zork •1990 – Loebner Prize Conversational Bots •Today – Siri, Alexa Google Assistant Image credit: Photo 172987631 © Pop Nukoonrat - Dreamstime.com 1940 Modern computer history begins with Language Analysis: “The Bombe” Breaking the code of the German Enigma Machine ENIGMA MACHINE THE BOMBE Enigma Machine image: Photographer: Timothy A. Clary/AFP The Bombe image: from movie set for The Imitation Game, The Weinstein Company 1948 – Alan Turing comes up with the concept of Turing Machine Image CC-BY-SA: Wikipedia, wvbailey 1948 – Alan Turing comes up with the concept of Turing Machine youtube.com/watch?v=dNRDvLACg5Q 1950 Imitation Game Image credit: Archivio GBB/Contrasto/Redux Zork 1980 Zork 1980 Text parsing Loebner Prize: Turing Test Competition bit.ly/loebnerP Conversational Chatbots you can try with your students bit.ly/MITsuku bit.ly/CLVbot What modern chatbots do •Convert speech to text •Categorise user input into categories they know •Analyse the emotion emotion in user input •Select from a range of available responses •Synthesize human language responses Image sources: Biglytics -

Passing the Turing Test Does Not Mean the End of Humanity
Cogn Comput (2016) 8:409–419 DOI 10.1007/s12559-015-9372-6 Passing the Turing Test Does Not Mean the End of Humanity 1 1 Kevin Warwick • Huma Shah Received: 18 September 2015 / Accepted: 20 November 2015 / Published online: 28 December 2015 Ó The Author(s) 2015. This article is published with open access at Springerlink.com Abstract In this paper we look at the phenomenon that is we do wish to dispel, however, is the assumption which the Turing test. We consider how Turing originally intro- links passing the Turing test with the achievement for duced his imitation game and discuss what this means in a machines of human-like or human-level intelligence. practical scenario. Due to its popular appeal we also look Unfortunately the assumed chain of events which means into different representations of the test as indicated by that passing the Turing test sounds the death knell for numerous reviewers. The main emphasis here, however, is humanity appears to have become engrained in the thinking to consider what it actually means for a machine to pass the in certain quarters. One interesting corollary of this is that Turing test and what importance this has, if any. In par- when it was announced in 2014 that the Turing test had ticular does it mean that, as Turing put it, a machine can been finally passed [39] there was an understandable ‘‘think’’. Specifically we consider claims that passing the response from those same quarters that it was not possible Turing test means that machines will have achieved for such an event to have occurred, presumably because we human-like intelligence and as a consequence the singu- were still here in sterling health to both make and debate larity will be upon us in the blink of an eye. -

'Realness' in Chatbots: Establishing Quantifiable Criteria
'Realness' in Chatbots: Establishing Quantifiable Criteria Kellie Morrissey and Jurek Kirakowski School of Applied Psychology, University College Cork, Ireland {k.morrissey,jzk}@ucc.ie Abstract. The aim of this research is to generate measurable evaluation criteria acceptable to chatbot users. Results of two studies are summarised. In the first, fourteen participants were asked to do a critical incident analysis of their tran- scriptions with an ELIZA-type chatbot. Results were content analysed, and yielded seven overall themes. In the second, these themes were made into statements of an attitude-like nature, and 20 participants chatted with five win- ning entrants in the 2011 Chatterbox Challenge and five which failed to place. Latent variable analysis reduced the themes to four, resulting in four subscales with strong reliability which discriminated well between the two categories of chatbots. Content analysis of freeform comments led to a proposal of four dimensions along which people judge the naturalness of a conversation with chatbots. Keywords: Chatbot, user-agent, intelligent assistant, naturalness, convincing, usability, evaluation, quantitative, questionnaire, Turing, Chatterbox. 1 Evaluating for Naturalness Conversational agents, or chatbots, are systems that are capable of performing actions on behalf of computer users; in essence, reducing the cognitive workload on users engaging with computer systems. There are two key strategies used. The first is the use of a set of well-learnt communicative conventions: natural language -

Presentación De Powerpoint
ARTIFICIAL INTELLIGENCE www.aceleralia.com | 2020 Aceleralia es una marca registrada de 2 Digits Growth® Todos los derechos reservados ARTIFICIAL INTELLIGENCE Problem solving Reasoning Problem solving, particularly in artificial intelligence, may be characterized as a systematic search through a To reason is to draw inferences appropriate to the range of possible actions in order to reach some situation. Inferences are classified as either deductive predefined goal or solution. Problem-solving methods or inductive. An example of the former is, “Fred must divide into special purpose and general purpose. A be in either the museum or the café. He is not in the special-purpose method is tailor-made for a particular café; therefore he is in the museum,” and of the latter, problem and often exploits very specific features of the “Previous accidents of this sort were caused by situation in which the problem is embedded. In instrument failure; therefore this accident was caused contrast, a general-purpose method is applicable to a by instrument failure.” wide variety of problems. The most significant difference between these forms One general-purpose technique used in AI is means- of reasoning is that in the deductive case the truth of end analysis—a step-by-step, or incremental, reduction the premises guarantees the truth of the conclusion, of the difference between the current state and the whereas in the inductive case the truth of the premise final goal. lends support to the conclusion without giving absolute assurance. Inductive reasoning is common in science, The program selects actions from a list of means—in where data are collected and tentative models are the case of a simple robot this might consist of PICKUP, developed to describe and predict future behavior— PUTDOWN, MOVEFORWARD, MOVEBACK, until the appearance of anomalous data forces the MOVELEFT, and MOVERIGHT—until the goal is model to be revised. -
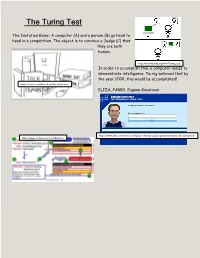
The Turing Test
The Turing Test The Imitation Game: A computer (A) and a person (B) go head to head in a competition. The object is to convince a Judge (C) that they are both human. https://en.wikipedia.org/wiki/Turing_test In order to accomplish this, a computer needs to demonstrate intelligence. Turing believed that by the year 2000, this would be accomplished! https://classic.csunplugged.org/the-turing-test/ ELIZA, PARRY, Eugene Goostman https://www.zdnet.com/article/computer-chatbot-eugene-goostman-passes-the-turing-test/ https://www.codeproject.com/Articles/ 12454/Developing-AI-chatbots But what about Deep Blue & Watson…? Both programs were created by IBM. Deep Blue was able to defeat an international chess champion, while Watson defeated two Jeopardy champions at the same time. https://en.wikipedia.org/wiki/Watson_(computer) Bibliography Artificial Intelligence: The Turing Test. Accessed March 17, 2018. http://www.psych.utoronto.ca/users/reingold/courses/ai/turing.html. Bansa, Shubhan, “Turing Test in Artificial Intelligence." GeeksforGeeks. February 07, 2018. Accessed March 14, 2018. https://www.geeksforgeeks.org/turing-test-artificial- intelligence/. Bell, Steven. "Promise and Peril of AI for Academic Librarians | From the Bell Tower." Library Journal. April 14, 2016. Accessed March 15, 2018. https://lj.libraryjournal.com/2016/04/opinion/steven-bell/promise-and-peril-of-ai-for- academic-librarians-from-the-bell-tower/#_. "Computer AI Passes Turing Test in 'world First'." BBC News. June 09, 2014. Accessed March 17, 2018. http://www.bbc.com/news/technology-27762088. "Eliza, the Computer Therapist." Eliza, Computer Therapist. Accessed March 17, 2018. https://www.cyberpsych.org/eliza/. -

Passing the Turing Test Does Not Mean the End of Humanity
Passing the Turing Test Does Not Mean the End of Humanity Warwick, K & Shah, H Author post-print (accepted) deposited by Coventry University’s Repository Original citation & hyperlink: Warwick, K & Shah, H 2016, 'Passing the Turing Test Does Not Mean the End of Humanity' Cognitive Computation, vol 8, no. 3. DOI: 10.1007/s12559-015-9372-6 https://dx.doi.org/10.1007/s12559-015-9372-6 DOI 10.1007/s12559-015-9372-6 ISSN 1866-9956 ESSN 1866-9964 Publisher: Springer The final publication is available at Springer via http://dx.doi.org/10.1007/s12559- 015-9372-6 Copyright © and Moral Rights are retained by the author(s) and/ or other copyright owners. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This item cannot be reproduced or quoted extensively from without first obtaining permission in writing from the copyright holder(s). The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the copyright holders. This document is the author’s post-print version, incorporating any revisions agreed during the peer-review process. Some differences between the published version and this version may remain and you are advised to consult the published version if you wish to cite from it. Passing the Turing Test Does Not Mean the End of Humanity Kevin Warwick and Huma Shah Coventry University, Priory Street, Coventry, CV1 5FB, UK Email: [email protected] , [email protected] Corresponding author: Kevin Warwick, tele: 44-247765-9893 Abstract: In this paper we look at the phenomenon that is the Turing test. -

AISB Quarterly an Anarchy of Methods: Current Trends in How Intelligence Is Abstracted in AI by John Lehman (U
AISB QUARTERLY the newsletter of the society for the study of artificial intelligence and simulation of behaviour No. 141 July, 2015 Do you feel artistic? Exhibit your artwork on our front covers! Email us at [email protected]! Artwork by Alwyn Husselmann, PhD (Massey Univ., New Zealand) Visualisation is an important tool for gaining insight into how algorithms behave. There have been many techniques developed, including some to visualise 3D voxel sets [1], program space in genetic programming [2] and vector fields [3], amongst a large number of methods in other domains. A qualitative understanding of an algorithm is useful not only in diagnosing implementations, but also in improving performance. In parametric optimisation, algorithms such as the Firefly Algorithm [4] are quite sim- ple to visualise provided they are being used on a problem with less than four dimensions. Search algorithms in this class are known as metaheuristics, as they have an ability to optimise unknown functions of an arbitrary number of variables without gradient infor- mation. Observations of particle movement are particularly useful for calibrating the internal parameters of the algorithm. Pictured on the cover is a visualisation of a Firefly Algorithm optimising the three- dimensional Rosenbrock Function [5]. Each coloured sphere represents a potential min- imum candidate. The optimum is near the centre of the cube, at coordinate (1, 1, 1). Colour is used here to indicate the output of the Rosenbrock function, whereas the 3D coordinate of each particle is representative of the actual values used as input to the function. The clustering seen amongst the particles in the image is due to the local neighbourhood searches occurring.