Sound Synthesis and Sampling, Third Edition (Music Technology)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

USER MANUAL Table of Contents
USER MANUAL Table Of Contents Table Of Contents Foreword ........................................................................... 3 Parts and Multis ............................................................. 78 Control Features & Connections ..................................... 6 System Configuration .................................................... 85 Front Panel ............................................................................................... 6 Kyra Sound Programming ........................................... 95 Rear Panel Connections ...................................................................... 7 Troubleshooting ........................................................... 125 Specifications .................................................................... 8 Kyra USB Interface ...................................................... 130 Introduction ..................................................................... 10 Kyra Firmware Update ................................................ 130 Setup and Connections .................................................. 13 Technical Data .............................................................. 135 System Overview ............................................................ 18 Glossary ........................................................................ 136 Basic Controls ................................................................. 20 Product Support ........................................................... 154 The Control Panel Sections .......................................... -
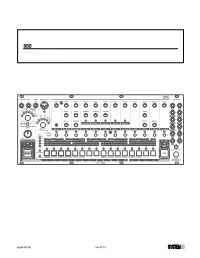
880 User Manual
880 Operation Manual START TAP STOP system80.net rev. 01/19 SYSTEM80 Introduction 1 The System80 880 is an analog drum machine for the The 880's sequencer features a familiar interface that Eurorack modular synthesizer format. Its drum voice allows for Rhythm Pattern creation using programmed circuits are based on the TR-808, the classic drum or real-time step entry. Manual Mode can be used for machine made by Roland Corporation between 1980 arrangement and improvisation during live and 1983. Wherever possible, the 880 uses the exact performance. There is also a Rhythm Compose mode same semiconductors specified in the original circuits. that allows patterns to be chained together into longer The sound very closely matches the sound and char- compositions. acter of the two vintage TR-808s that were used as references during the 880's design. Variation in The sequencer has been updated with 12 banks of 16 component tolerances as well as component aging Rhythm Patterns, shuffle, mutes, performance rolls, a may contribute to some perceptable differences in pair of fully assignable trigger outputs, and multiple sound between the 880 and a vintage TR-808. options for syncing to external devices. However, the same holds true for sound comparisons between original TR-808s and other 808 clones. The Eurorack modular synthesizer format invites experimentation and improvisation. The 880 features The 880 features all 16 of the original TR-808's analog 11 indivdual instrument outputs for separate mixing drum voices with one important difference: the five and processing of the sounds, either within a Eurorack switchable voices are controlled with electronic rather system or through other devices, such as filters, than mechanical switches. -

Korg OASYS PСI. Описание Патчей И Эффектов
Korg OASYS PCI. Îïèñàíèå ïàò÷åé è ýôôåêòîâ Ñèñòåìà ñèíòåçà, îáðàáîòêè ýôôåêòàìè è ââîäà-âûâîäà àóäèîñèãíàëîâ Îôèöèàëüíûé è ýêñêëþçèâíûé äèñòðèáüþòîð êîìïàíèè Korg íà òåððèòîðèè Ðîññèè, ñòðàí Áàëòèè è ÑÍà êîìïàíèÿ A&T Trade. Äàííîå ðóêîâîäñòâî ïðåäîñòàâëÿåòñÿ áåñïëàòíî. Åñëè âû ïðèîáðåëè äàííûé ïðèáîð íå ó îôèöèàëüíîãî äèñòðèáüþòîðà ôèðìû Korg èëè àâòîðèçîâàííîãî äèëåðà êîìïàíèè A&T Trade, êîìïàíèÿ A&T Trade íå íåñ¸ò îòâåòñòâåííîñòè çà ïðåäîñòàâëåíèå áåñ- ïëàòíîãî ïåðåâîäà íà ðóññêèé ÿçûê ðóêîâîäñòâà ïîëüçîâàòåëÿ, à òàêæå çà îñóùåñòâëåíèå ãàðàíòèéíîãî è ñåðâèñíîãî îáñëóæèâà- íèÿ. Предупреждение Îáîðóäîâàíèå ïðîøëî òåñòîâûå èñïûòàíèÿ è ñîîòâåòñòâóåò òðåáîâàíèÿì, íàêëàäûâàåìûì íà öèôðîâûå ïðèáîðû êëàññà “B” ñî- ãëàñíî ÷àñòè 15 ïðàâèë FCC. Ýòè îãðàíè÷åíèÿ ðàçðàáîòàíû äëÿ îáåñïå÷åíèÿ íàäåæíîé çàùèòû îò èíòåðôåðåíöèè ïðè èíñòàëëÿ- öèè îáîðóäîâàíèÿ â æèëûõ ïîìåùåíèÿõ. Ïðèáîð ãåíåðèðóåò, èñïîëüçóåò è ñïîñîáåí èçëó÷àòü ýëåêòðîìàãíèòíûå âîëíû è, åñëè óñ- òàíîâëåí è ýêñïëóàòèðóåòñÿ áåç ñîáëþäåíèÿ ïðèâåäåííûõ ðåêîìåíäàöèé, ìîæåò âûçâàòü ïîìåõè â ðàáîòå ðàäèîñèñòåì. Òåì íå ìåíåå íåò ïîëíîé ãàðàíòèè, ÷òî ïðè îòäåëüíûõ èíñòàëëÿöèÿõ ïðèáîð íå áóäåò ãåíåðèðîâàòü ðàäèî÷àñòîòíûå ïîìåõè. Åñëè ïðèáîð âëèÿåò íà ðàáîòó ðàäèî- èëè òåëåâèçèîííûõ ñèñòåì (ýòî ïðîâåðÿåòñÿ âêëþ÷åíèåì è îòêëþ÷åíèåì ïðèáîðà), òî ðåêîìåíäóåòñÿ ïðåäïðèíÿòü ñëåäóþùèå ìåðû: • Ïåðåîðèåíòèðóéòå èëè ðàñïîëîæèòå â äðóãîì ìåñòå ïðèíèìàþùóþ àíòåííó. • Ðàçíåñèòå íà âîçìîæíî áîëüøåå ðàññòîÿíèå ïðèáîð è ïðèåìíèê. • Âêëþ÷èòå ïðèáîð â ðîçåòêó, êîòîðàÿ íàõîäèòñÿ â öåïè, îòëè÷íîé îò öåïè ðîçåòêè ïðèåìíèêà. • Ïðîêîíñóëüòèðóéòåñü ñ äèëåðîì èëè êâàëèôèöèðîâàííûì òåëåâèçèîííûì ìàñòåðîì. Íåñàíêöèîíèðîâàííàÿ ìîäèôèêàöèÿ îáîðóäîâàíèÿ ïîëüçîâàòåëåì ìîæåò ïðèâåñòè ê ëèøåíèþ ïðàâà íà ãàðàíòèéíîå îáñëóæèâà- íèå äàííîãî îáîðóäîâàíèÿ. Гарантийное обслуживание Ïî âñåì âîïðîñàì, ñâÿçàííûì ñ ðåìîíòîì èëè ñåðâèñíûì îáñëóæèâàíèåì ñèñòåìû OASYS PCI, îáðàùàéòåñü ê ïðåäñòàâèòåëÿì ôèðìû Korg — êîìïàíèè A&T Trade. -

Organ1st: Issue Fourteen May to July 2002 1 Welcome to Issue Fourteen Containing in Colour
The Magazine for Organists This Issue: “At Home with Penny Weedon” by Tony Kerr Profile of Nicholas Martin Profile of Ryan Edwards Glyn Madden interviewed by Robert Mottram Carol Williams “Behind the Scenes at Blenheim Palace” “The Lady Is A Tramp” Organ Arrangement by Glyn Madden “The B3 March” Topline Music Alan Ashton’s “Organised Keyboards” PDF “Time Was” by Ivor Manual (Part Six) ORGAN1st: Issue Fourteen May to July 2002 1 Welcome to issue fourteen containing in colour. We have thought about some letters! If you have any questions profiles of Nicholas Martin, Penny changing the printed magazine to colour, or comments about organists, organs, our Weedon, Ryan Edwards, plus much more. but the web versions are the best option magazine, concerts or recordings etc., for us at the moment. please send them to us. You can post, We have a great arrangement of “The fax (or preferably email) them. We will Lady Is A Tramp” by Glyn Madden. Our New issues are available to subscribers send a £5.00 credit note for any we print thanks go to him for a super arrangement only for the first few months. As we do and £10.00 for the best one. which is exclusive to us. We also have an not have to wait for the web version to be interviewFourteen with him by Robert Mottram. printed, they are available on our website Organ Festivals by Tim Flint: in early January, April, July and October I have also included a topline version of Tim Flint has started his own Organ (a month before the printed ones are sent one of my own compositions called “The Festivals called “Superior Hotel Breaks out). -

Prices Subject to Change Without Notice. Call Today Or Visit Us Online! Keyboard Workstations & Synthesizers 299
298 KEYBOARD WORKSTATIONS & SYNTHESIZERS NEW! ROLAND JUPITER-50 SYNTHESIZER A 76-key, 128-voice synth for both studio and stage performances. Combines the expression of the JUPITER-80 with the travel friendliness of the JUNO series, bringing SuperNATURAL® sound and pro performance to every stage and studio. Features weighted keyboard, friendly user interface with intui- tive color-coded buttons/sliders, registration function for saving and selecting sounds instantly, pro-quality multi-effects and reverb, and USB audio/MIDI functionality. • Expressive performance controllers (D BEAM, pitch/mod lever, & control in jacks) • Bundled with SONAR LE and JUPITER-50 Control Surface plug-in for SONAR. • Over 1,500 SuperNATURAL® synthesizer tones ITEM DESCRIPTION PRICE JP-50......................... JUPITER-50 synthesizer ...................................................................1999.00 ROLAND JUNO-GI MOBILE SYNTHESIZER Roland’s JUNO-GI has over 1,300 ROLAND JUPITER 80 The latest incarnation of one of the most legendary sounds, an onboard eight-track digital recorder, and professional effects cre- names in synthesis. The Jupiter 80 is a live performance powerhouse with 256 ated by BOSS. Over 1,300 factory selections cover a wide array of instrument polyphonic voices. There is a full color touch screen and plenty of assignable types and musical styles, and Tone Category buttons help you scan the vast buttons, knobs, pitch and mod wheels, and a D-Beam controller. library with ease. • Fat, multi-layered SuperNATURAL sound set • AC Adapter or -

Instructions for Midi Interface Roland Tr-808 Drum Machine
INSTRUCTIONS FOR MIDI INTERFACE ROLAND TR-808 DRUM MACHINE USING THE MIDI INTERFACE Your TR808 drum is now equipped to send and receive MIDI information. When turned on the machine will function normally, sending out and receiving MIDI note & velocity information on the channels set in memory. The factory channel settings are: receive chan 10 omni off transmit chan 10 and Stop/start TX/RX enabled Clock information is always sent and Start/stop information is sent and received if enabled. (Not channel sensitive) YOU CAN RETURN TO THE FACTORY MIDI SETTINGS BY SWITCHING THE MACHINE ON WHILST HOLDING THE RED BUTTON PRESSED (hold for a couple of seconds) With the rear panel switch set to normal (up) the TR808 drum will run from its own internal clock and will send out MIDI timing information at a rate determined by the tempo control. With the rear panel switch in the down position however, it will run from MIDI sync at the rate set by the MIDI device connected. If no MIDI timing information ispresent then the TR808 drum will not run. Some drum machines/sequencers may not send start/stop codes, in this case pressing the start switch on the TR808, will make it wait until MIDI clock/sync is present. You can make the TR808 ignore start/stop codes by selecting it from the programming mode described in the next paragraph, when set to disable the TR808 will neither respond to, nor send start/stop codes - when enabled (the default condition) start/stop codes will be both sent and received. -

MIDI に関する技術系統化調査 1 Systematized Survey of MIDI and Related Technologies
MIDI に関する技術系統化調査 1 Systematized Survey of MIDI and Related Technologies 井土 秀樹 Hideki Izuchi ■ 要旨 MIDI(Musical Instrument Digital Interface)は、日本の MIDI 規格協議会(現 AMEI:一般社団法人 音楽電子事業協会)と国際団体の MMA(MIDI Manufacturers Association)により制定された電子楽器の 演奏データを機器間でデジタル転送するための共通規格である。 1981 年 6 月シカゴで開催された NAMM ショーで、共通インターフェースの可能性に関して、最初の呼 びかけを行ったのがローランド創業者の梯郁太郎である。この呼びかけに応じ、最初の規格案を提案したのが Dave Smith(Sequential Circuits Inc. 社長)であった。両者は MIDI の制定に尽力し、MIDI 規格がその後 の音楽産業の発展に貢献したことが評価され、MIDI 制定から 30 周年を迎える 2013 年第 55 回グラミー賞 にて、連名でテクニカル・グラミー・アワードを受賞している。 MIDI を使って、異なる電子楽器同士がメーカーの枠を超えて同時に鳴らせるようになった。またコンピュー ターと電子楽器をつなぐことが可能となり、コンピューター上で演奏データを作成し、MIDI を通じて電子楽 器を自動演奏させることが可能となった。机の上で音楽の最終形まで制作可能になったことから「Desk Top Music」と呼ばれ、音楽制作の現場を大きく変えることになった。 また 1990 年代大手パソコン通信ホストによりアマチュア・ミュージシャンによる MIDI データの流通が隆 盛を極めた。このような MIDI データの流通には GS 音源、XG 音源と呼ばれたデファクトスタンダードな音色 配置と、SMF(Standard MIDI File)と呼ばれた MIDI データを記憶する共通ファイル・フォーマットの存在 が貢献した。 1992 年通信カラオケの誕生によって MIDI は楽器業界以外にも活躍の場を得ることになる。MIDI データを 使った通信カラオケシステムは、従来のディスクメディアによるカラオケシステムより、新曲の制作・配信が圧 倒的に速く、内蔵曲数の制限も少なく、ランニングコストも安価になったことから、カラオケの低価格・大衆化 を大きく前進させた。また 1999 年 2 月の i モード・サービス開始などにより、コンテンツ・プロバイダのメ ニューサイトで着信メロディーの演奏データを課金のうえダウンロードするのが一般的となり、携帯電話向けコ ンテンツビジネスが急速に拡大した。着信メロディーの演奏データの実体は Standard MIDI File(SMF)で あり、MIDI データが携帯端末の世界でも活用された。 MIDI は演奏データ情報に留まらず、クロック情報、タイムコード情報なども扱えるためレコーディング・ス タジオの制作プロセスを大きく変革した。さらに MIDI の RP(推奨実施例)として MIDI Machine Control、 MIDI Show Control、MIDI Visual Control 等も制定され、マルチトラックレコーダーの機器制御、照明機 器の制御、映像機器の制御にも MIDI が使われるようになった。 1999 年には MIDI を USB ケーブルの中に通すことが可能となり、また 2015 年には Bluetooth Low Energy(BLE)が規格化され、 2016 -

Early Reception Histories of the Telharmonium, the Theremin, And
Electronic Musical Sounds and Material Culture: Early Reception Histories of the Telharmonium, the Theremin, and the Hammond Organ By Kelly Hiser A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Music) at the UNIVERSITY OF WISCONSIN-MADISON 2015 Date of final oral examination: 4/21/2015 The dissertation is approved by the following members of the Final Oral Committee ` Susan C. Cook, Professor, Professor, Musicology Pamela M. Potter, Professor, Professor, Musicology David Crook, Professor, Professor, Musicology Charles Dill, Professor, Professor, Musicology Ann Smart Martin, Professor, Professor, Art History i Table of Contents Acknowledgements ii List of Figures iv Chapter 1 1 Introduction, Context, and Methods Chapter 2 29 29 The Telharmonium: Sonic Purity and Social Control Chapter 3 118 Early Theremin Practices: Performance, Marketing, and Reception History from the 1920s to the 1940s Chapter 4 198 “Real Organ Music”: The Federal Trade Commission and the Hammond Organ Chapter 5 275 Conclusion Bibliography 291 ii Acknowledgements My experience at the University of Wisconsin-Madison has been a rich and rewarding one, and I’m grateful for the institutional and personal support I received there. I was able to pursue and complete a PhD thanks to the financial support of numerous teaching and research assistant positions and a Mellon-Wisconsin Summer Fellowship. A Public Humanities Fellowship through the Center for the Humanities allowed me to actively participate in the Wisconsin Idea, bringing skills nurtured within the university walls to new and challenging work beyond them. As a result, I leave the university eager to explore how I might share this dissertation with both academic and public audiences. -

NCRC Award Brian Docs
NCRC 2012 Radio Awards Application, Documentary Bio and Program Note Producer: Brian Meagher Bio: It all began when I was six years old and I heard `Popcorn` for the first time. I remember being at the A&W Drive-In, the waitresses arriving at our car on roller skates, and this incredible song providing the soundtrack. Electronic music has provided my soundtrack ever since. Program: Synthumentary (episodes 1-3) Description: Synthumentary is a five-part look at the evolution of the electronic instruments and their place in popular culture, from the earliest electromechanical musical devices to the Moog explosion of the late 60`s and early 70`s. Synthumentary presents a survey of the landmark inventors, instruments, artists and recordings of each era. In each episode, we look at a different scene, discuss the era`s principle actors and play some of their music to illustrate the style of music made at the time. The evolution of electronic music technology is explained to frame each episode. Our aim is to provide the casual listener of electronic music with an appreciation of its possibilities and the more knowledgeable fan with at least a few nuggets of novel information. Among the subjects covered are: The Telharmonium, Theremin, The ”Forbidden Planet” Soundtrack, Raymond Scott, The Ondioline, Jean-Jacques Perrey and Gershon Kingsley, Bob Moog and the Moog music phenomena, Silver Apples, and the Canadian scene: Hugh LeCaine to Bruce Haack to Jean Sauvageau. The intro and outro theme is an original composition written and performed by members of The Unireverse for Synthumentary. The audio submitted contains excerpts from all three episodes. -

The Science Sound
The Science of Sound Education Guide Introduction: Music is Science Education Guide Acknowledgements Written and developed by Kim Leavitt, Director of Education and Community Engagement, The Phoenix Symphony and Jordan Drum, Education Assistant, The Phoenix Symphony Based on The Science of Sound Classroom Concert created and developed by Mark Dix, Violist, The Phoenix Symphony Lesson Plans created by April Pettit, General Music/Band/Orchestra/Choir, Dunbar Elementary School Funding for The Science of Sound Education Guide was provided by the Craig & Barbara Barrett Foundation 12 LearningThe Science Objectives: of Sound: AcademicTable of Connections Contents Acknowledgements 2 Table of Contents 3 Introduction: Music is Science 4 Learning Objectives : Academic Connections 5 Arizona Academic Content Standards 5 The Science Behind Sound 6 Science of Sound Lesson Plans 9 Science Lesson: Exploring Vibration and Sound Grades: 2-8 10 Music and Technology: Comparing and Contrasting Music Instruments Grades: 3-8 11 Music Lesson: Engineering Musical Instruments Grades: 2-8 12 Music and Science: Experimenting with Sound Waves Grades: 5-12 13 Music, Math & Engineering Lesson: Creating Straw Panpipes Grades: 4-8 15 Assessment Tools 16 Longitudinal Waves in Music 17 Quiz: How is Sound Produced? 18 Science of Sound Writing Prompts 19 Interactive Quiz: Name That Instrument! 20 Interactive Game: Making Music with Science 21 Venn Diagram: Instrument Families 22 Instrument Family Word Search 23 music engineering science 31 3 Introduction: Music is Science Making music is a scientific process. Scientists and historians have tried to explain the complex phenomena of music for thousands of years. Many questions exist: How is sound produced? What causes music notes to be loud or soft? Why are some notes high and others low? What is the difference between “noise” and music? The science behind how a musical instrument functions is fascinating. -

INSTRUMENTS for NEW MUSIC Luminos Is the Open Access Monograph Publishing Program from UC Press
SOUND, TECHNOLOGY, AND MODERNISM TECHNOLOGY, SOUND, THOMAS PATTESON THOMAS FOR NEW MUSIC NEW FOR INSTRUMENTS INSTRUMENTS PATTESON | INSTRUMENTS FOR NEW MUSIC Luminos is the open access monograph publishing program from UC Press. Luminos provides a framework for preserv- ing and reinvigorating monograph publishing for the future and increases the reach and visibility of important scholarly work. Titles published in the UC Press Luminos model are published with the same high standards for selection, peer review, production, and marketing as those in our traditional program. www.luminosoa.org The publisher gratefully acknowledges the generous contribu- tion to this book provided by the AMS 75 PAYS Endowment of the American Musicological Society, funded in part by the National Endowment for the Humanities and the Andrew W. Mellon Foundation. The publisher also gratefully acknowledges the generous contribution to this book provided by the Curtis Institute of Music, which is committed to supporting its faculty in pursuit of scholarship. Instruments for New Music Instruments for New Music Sound, Technology, and Modernism Thomas Patteson UNIVERSITY OF CALIFORNIA PRESS University of California Press, one of the most distin- guished university presses in the United States, enriches lives around the world by advancing scholarship in the humanities, social sciences, and natural sciences. Its activi- ties are supported by the UC Press Foundation and by philanthropic contributions from individuals and institu- tions. For more information, visit www.ucpress.edu. University of California Press Oakland, California © 2016 by Thomas Patteson This work is licensed under a Creative Commons CC BY- NC-SA license. To view a copy of the license, visit http:// creativecommons.org/licenses. -

Lagersalg 2019.Xlsx
SOUNDFORCE LAGERSALG 2019 Lagersalget foregår fredag d. 1. november 2019 på Birkegårdsvej 11, 8361 Hasselager. Alt Udstyr på listen bliver solgt fra kl. 15:00 - 18:00. Det er IKKE mUligt at reservere - først til mølle. Der kan betales med MobilePay eller kontant. Vi tager IKKE imod Dankort. Alle priser er inkl. moms. TROMMER / PERCUSSION # ITEM PRIS NOTE S1 Gretsch 1958 vintage Round Badge - 12x8", 14x5", 14x14", 20x14" 18.500,00 kr. Light Blue Pearl - Vintage S2 Hayman Steel Tambourine 50,00 kr. S3 Mapex Pro M sæt - 22x18", 10x8", 12x9", 14x14", 16x16", 14x5" 5.000,00 kr. Black S4 Roland TM6-Pro - Trigger Module 2.775,00 kr. Ny S5 Roland-HPD15 - Handsonic Drum Pad 900,00 kr. S6 Roland-TM2 - Trigger Module 800,00 kr. S7 Sonor Shaker 50,00 kr. S8 Yamaha Absolute Maple Hybrid - 10x8", 12x9", 16x15", 22x18" 12.000,00 kr. Piano Black S9 Yamaha Recording Custom - 10x7", 12x8", 16x15", 18x16", 22x16" 21.500,00 kr. Real Wood - Nyt demo BÆKKENER # ITEM PRIS NOTE S1 Paiste 15" Traditional Medium Light Hi-Hat 1.950,00 kr. S2 Paiste 6" Cup Chime 250,00 kr. S3 Paiste 9" Traditional Thin Splash 550,00 kr. S4 Zildjian 13" K/Z Hi-Hat 900,00 kr. S5 Zildjian 20" A Ping Ride 800,00 kr. S6 Zildjian 9" K Custom Hybrid Splash 650,00 kr. HARDWARE # ITEM PRIS NOTE S1 Diverse Boom Arm 30,00 kr. 8 stk S2 Diverse Clamp 30,00 kr. S3 DW 5000TD Hi-Hat Stand 2-legs 900,00 kr. S4 DW 6000 BD Pedal 800,00 kr.