The Molecular Basis of A-Thalassemia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In Silico Prediction of High-Resolution Hi-C Interaction Matrices
ARTICLE https://doi.org/10.1038/s41467-019-13423-8 OPEN In silico prediction of high-resolution Hi-C interaction matrices Shilu Zhang1, Deborah Chasman 1, Sara Knaack1 & Sushmita Roy1,2* The three-dimensional (3D) organization of the genome plays an important role in gene regulation bringing distal sequence elements in 3D proximity to genes hundreds of kilobases away. Hi-C is a powerful genome-wide technique to study 3D genome organization. Owing to 1234567890():,; experimental costs, high resolution Hi-C datasets are limited to a few cell lines. Computa- tional prediction of Hi-C counts can offer a scalable and inexpensive approach to examine 3D genome organization across multiple cellular contexts. Here we present HiC-Reg, an approach to predict contact counts from one-dimensional regulatory signals. HiC-Reg pre- dictions identify topologically associating domains and significant interactions that are enri- ched for CCCTC-binding factor (CTCF) bidirectional motifs and interactions identified from complementary sources. CTCF and chromatin marks, especially repressive and elongation marks, are most important for HiC-Reg’s predictive performance. Taken together, HiC-Reg provides a powerful framework to generate high-resolution profiles of contact counts that can be used to study individual locus level interactions and higher-order organizational units of the genome. 1 Wisconsin Institute for Discovery, 330 North Orchard Street, Madison, WI 53715, USA. 2 Department of Biostatistics and Medical Informatics, University of Wisconsin-Madison, Madison, WI 53715, USA. *email: [email protected] NATURE COMMUNICATIONS | (2019) 10:5449 | https://doi.org/10.1038/s41467-019-13423-8 | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | https://doi.org/10.1038/s41467-019-13423-8 he three-dimensional (3D) organization of the genome has Results Temerged as an important component of the gene regulation HiC-Reg for predicting contact count using Random Forests. -

NPRL3 Gene NPR3 Like, GATOR1 Complex Subunit
NPRL3 gene NPR3 like, GATOR1 complex subunit Normal Function The NPRL3 gene provides instructions for making a protein that is one piece of a group of proteins (complex) called GATOR1. This complex is found in cells throughout the body, where it regulates a signaling pathway called the mTOR pathway. The mTOR pathway is involved in cell growth and division (proliferation), the survival of cells, and the creation (synthesis) of new proteins. The role of the GATOR1 complex is to block this pathway by inhibiting (stopping) the activity of a complex called mTOR complex 1 ( mTORC1) that is integral to the mTOR pathway. In the brain, the mTOR pathway regulates many processes, including the growth and development of nerve cells and their ability to change and adapt over time (plasticity). Health Conditions Related to Genetic Changes Familial focal epilepsy with variable foci At least ten NPRL3 gene mutations have been found to cause familial focal epilepsy with variable foci (FFEVF), which is an uncommon form of recurrent seizures (epilepsy) that runs in families. Most of these mutations lead to the production of an abnormally short, nonfunctional protein. As a result, formation of normal GATOR1 complex is reduced, leading to overactivity of mTORC1 and excessive signaling of the mTOR pathway. It is not clear how an abnormally active mTOR pathway leads to the seizures of FFEVF. Research suggests that increased mTOR pathway signaling in the brain leads to changes in the connections between nerve cells (synapses) and increased activation (excitation) -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

Análise Integrativa De Perfis Transcricionais De Pacientes Com
UNIVERSIDADE DE SÃO PAULO FACULDADE DE MEDICINA DE RIBEIRÃO PRETO PROGRAMA DE PÓS-GRADUAÇÃO EM GENÉTICA ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Ribeirão Preto – 2012 ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas Tese apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo para obtenção do título de Doutor em Ciências. Área de Concentração: Genética Orientador: Prof. Dr. Eduardo Antonio Donadi Co-orientador: Prof. Dr. Geraldo A. S. Passos Ribeirão Preto – 2012 AUTORIZO A REPRODUÇÃO E DIVULGAÇÃO TOTAL OU PARCIAL DESTE TRABALHO, POR QUALQUER MEIO CONVENCIONAL OU ELETRÔNICO, PARA FINS DE ESTUDO E PESQUISA, DESDE QUE CITADA A FONTE. FICHA CATALOGRÁFICA Evangelista, Adriane Feijó Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. Ribeirão Preto, 2012 192p. Tese de Doutorado apresentada à Faculdade de Medicina de Ribeirão Preto da Universidade de São Paulo. Área de Concentração: Genética. Orientador: Donadi, Eduardo Antonio Co-orientador: Passos, Geraldo A. 1. Expressão gênica – microarrays 2. Análise bioinformática por module maps 3. Diabetes mellitus tipo 1 4. Diabetes mellitus tipo 2 5. Diabetes mellitus gestacional FOLHA DE APROVAÇÃO ADRIANE FEIJÓ EVANGELISTA Análise integrativa de perfis transcricionais de pacientes com diabetes mellitus tipo 1, tipo 2 e gestacional, comparando-os com manifestações demográficas, clínicas, laboratoriais, fisiopatológicas e terapêuticas. -

Repetitive Elements in Humans
International Journal of Molecular Sciences Review Repetitive Elements in Humans Thomas Liehr Institute of Human Genetics, Jena University Hospital, Friedrich Schiller University, Am Klinikum 1, D-07747 Jena, Germany; [email protected] Abstract: Repetitive DNA in humans is still widely considered to be meaningless, and variations within this part of the genome are generally considered to be harmless to the carrier. In contrast, for euchromatic variation, one becomes more careful in classifying inter-individual differences as meaningless and rather tends to see them as possible influencers of the so-called ‘genetic background’, being able to at least potentially influence disease susceptibilities. Here, the known ‘bad boys’ among repetitive DNAs are reviewed. Variable numbers of tandem repeats (VNTRs = micro- and minisatellites), small-scale repetitive elements (SSREs) and even chromosomal heteromorphisms (CHs) may therefore have direct or indirect influences on human diseases and susceptibilities. Summarizing this specific aspect here for the first time should contribute to stimulating more research on human repetitive DNA. It should also become clear that these kinds of studies must be done at all available levels of resolution, i.e., from the base pair to chromosomal level and, importantly, the epigenetic level, as well. Keywords: variable numbers of tandem repeats (VNTRs); microsatellites; minisatellites; small-scale repetitive elements (SSREs); chromosomal heteromorphisms (CHs); higher-order repeat (HOR); retroviral DNA 1. Introduction Citation: Liehr, T. Repetitive In humans, like in other higher species, the genome of one individual never looks 100% Elements in Humans. Int. J. Mol. Sci. alike to another one [1], even among those of the same gender or between monozygotic 2021, 22, 2072. -

Imputation of Exome Sequence Variants Into Population- Based Samples and Blood-Cell-Trait-Associated Loci in African Americans: NHLBI GO Exome Sequencing Project
ARTICLE Imputation of Exome Sequence Variants into Population- Based Samples and Blood-Cell-Trait-Associated Loci in African Americans: NHLBI GO Exome Sequencing Project Paul L. Auer,1,17 Jill M. Johnsen,2,3,17 Andrew D. Johnson,4,17 Benjamin A. Logsdon,1,17 Leslie A. Lange,5,17 Michael A. Nalls,6 Guosheng Zhang,5 Nora Franceschini,5 Keolu Fox,3 Ethan M. Lange,5 Stephen S. Rich,7 Christopher J. O’Donnell,4 Rebecca D. Jackson,8 Robert B. Wallace,9 Zhao Chen,10 Timothy A. Graubert,11 James G. Wilson,12 Hua Tang,13,17 Guillaume Lettre,14,17 Alex P. Reiner,1,6,17,* Santhi K. Ganesh,15,17 and Yun Li5,16,17,* Researchers have successfully applied exome sequencing to discover causal variants in selected individuals with familial, highly pene- trant disorders. We demonstrate the utility of exome sequencing followed by imputation for discovering low-frequency variants asso- ciated with complex quantitative traits. We performed exome sequencing in a reference panel of 761 African Americans and then imputed newly discovered variants into a larger sample of more than 13,000 African Americans for association testing with the blood cell traits hemoglobin, hematocrit, white blood count, and platelet count. First, we illustrate the feasibility of our approach by demon- strating genome-wide-significant associations for variants that are not covered by conventional genotyping arrays; for example, one such association is that between higher platelet count and an MPL c.117G>T (p.Lys39Asn) variant encoding a p.Lys39Asn amino À acid substitution of the thrombpoietin receptor gene (p ¼ 1.5 3 10 11). -

Functional Analysis of Structural Variation in the 2D and 3D Human Genome
FUNCTIONAL ANALYSIS OF STRUCTURAL VARIATION IN THE 2D AND 3D HUMAN GENOME by Conor Mitchell Liam Nodzak A dissertation submitted to the faculty of The University of North Carolina at Charlotte in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Bioinformatics and Computational Biology Charlotte 2019 Approved by: Dr. Xinghua Mindy Shi Dr. Rebekah Rogers Dr. Jun-tao Guo Dr. Adam Reitzel ii c 2019 Conor Mitchell Liam Nodzak ALL RIGHTS RESERVED iii ABSTRACT CONOR MITCHELL LIAM NODZAK. Functional analysis of structural variation in the 2D and 3D human genome. (Under the direction of DR. XINGHUA MINDY SHI) The human genome consists of over 3 billion nucleotides that have an average distance of 3.4 Angstroms between each base, which equates to over two meters of DNA contained within the 125 µm3 volume diploid cell nuclei. The dense compaction of chromatin by the supercoiling of DNA forms distinct architectural modules called topologically associated domains (TADs), which keep protein-coding genes, noncoding RNAs and epigenetic regulatory elements in close nuclear space. It has recently been shown that these conserved chromatin structures may contribute to tissue-specific gene expression through the encapsulation of genes and cis-regulatory elements, and mutations that affect TADs can lead to developmental disorders and some forms of cancer. At the population-level, genomic structural variation contributes more to cumulative genetic difference than any other class of mutation, yet much remains to be studied as to how structural variation affects TADs. Here, we study the func- tional effects of structural variants (SVs) through the analysis of chromatin topology and gene activity for three trio families sampled from genetically diverse popula- tions from the Human Genome Structural Variation Consortium. -
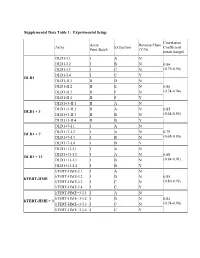
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

Genomic Diagnostics Within a Medically Underserved Population: Efficacy and Implications
© American College of Medical Genetics and Genomics ORIGINAL RESEARCH ARTICLE Genomic diagnostics within a medically underserved population: efficacy and implications Kevin A. Strauss, MD1, Claudia Gonzaga-Jauregui, PhD2, Karlla W. Brigatti, MS1, Katie B. Williams, MD, PhD1, Alejandra K. King, PhD2, Cristopher Van Hout, PhD2, Donna L. Robinson, CRNP1, Millie Young, RNC1, Kavita Praveen, PhD2, Adam D. Heaps, MS1, Mindy Kuebler, MS1, Aris Baras, MD2, Jeffrey G. Reid, PhD2, John D. Overton, PhD2, Frederick E. Dewey, MD2, Robert N. Jinks, PhD3, Ian Finnegan, BA3, Scott J. Mellis, MD, PhD2, Alan R. Shuldiner, MD2 and Erik G. Puffenberger, PhD1 Purpose: We integrated whole-exome sequencing (WES) and Compared to trio analysis, “family” WES (average seven exomes chromosomal microarray analysis (CMA) into a clinical workflow per proband) reduced filtered candidate variants from 22 ± 6to to serve an endogamous, uninsured, agrarian community. 5 ± 3 per proband. Nineteen (51%) alleles were de novo and 17 Methods: Seventy-nine probands (newborn to 49.8 years) who (46%) inherited; the latter added to a population-based diagnostic presented between 1998 and 2015 remained undiagnosed after panel. We found actionable secondary variants in 21 (4.2%) of 502 biochemical and molecular investigations. We generated WES data subjects, all of whom opted to be informed. for probands and family members and vetted variants through Conclusion: CMA and family-based WES streamline and rephenotyping, segregation analyses, and population studies. economize diagnosis of rare genetic disorders, accelerate novel Results: The most common presentation was neurological disease gene discovery, and create new opportunities for community-based (64%). Seven (9%) probands were diagnosed by CMA. -

Nprl3 Gene Intron That Enhances Its Transcription in Peripheral Blood
Scuola Internazionale Superiore di Studi Avanzati PhD Course in Functional and Structural Genomics Discovery of a human VNTR allelic variant in Nprl3 gene intron that enhances its transcription in peripheral blood Thesis submitted for the degree of “Philosophiæ Doctor” Candidate Supervisor Maria Bertuzzi Prof. Stefano Gustincich Academic Year 2014-2015 Table of contents Table of contents Abstract ....................................................................................................................................1 Introduction ..............................................................................................................................3 Gene expression regulation ..................................................................................................3 Gene expression profiling ................................................................................................5 NanoCAGE ......................................................................................................................6 TSS complexity ................................................................................................................7 Expression Quantitative Trait Loci (eQTL) .....................................................................8 Repetitive elements in the mammalian genome.................................................................10 Minisatellites and human diseases .................................................................................11 Parkinson’s disease.............................................................................................................14 -

A Catalogue of Stress Granules' Components
Catarina Rodrigues Nunes A Catalogue of Stress Granules’ Components: Implications for Neurodegeneration UNIVERSIDADE DO ALGARVE Departamento de Ciências Biomédicas e Medicina 2019 Catarina Rodrigues Nunes A Catalogue of Stress Granules’ Components: Implications for Neurodegeneration Master in Oncobiology – Molecular Mechanisms of Cancer This work was done under the supervision of: Clévio Nóbrega, Ph.D UNIVERSIDADE DO ALGARVE Departamento de Ciências Biomédicas e Medicina 2019 i ii A catalogue of Stress Granules’ Components: Implications for neurodegeneration Declaração de autoria de trabalho Declaro ser a autora deste trabalho, que é original e inédito. Autores e trabalhos consultados estão devidamente citados no texto e constam na listagem de referências incluída. I declare that I am the author of this work, that is original and unpublished. Authors and works consulted are properly cited in the text and included in the list of references. _______________________________ (Catarina Nunes) iii Copyright © 2019 Catarina Nunes A Universidade do Algarve reserva para si o direito, em conformidade com o disposto no Código do Direito de Autor e dos Direitos Conexos, de arquivar, reproduzir e publicar a obra, independentemente do meio utilizado, bem como de a divulgar através de repositórios científicos e de admitir a sua cópia e distribuição para fins meramente educacionais ou de investigação e não comerciais, conquanto seja dado o devido crédito ao autor e editor respetivos. iv Part of the results of this thesis were published in Nunes,C.; Mestre,I.; Marcelo,A. et al. MSGP: the first database of the protein components of the mammalian stress granules. Database (2019) Vol. 2019. (In annex A). v vi ACKNOWLEDGEMENTS A realização desta tese marca o final de uma etapa académica muito especial e que jamais irei esquecer. -

Databases Featuring Genomic Sequence Alignment
D466–D470 Nucleic Acids Research, 2005, Vol. 33, Database issue doi:10.1093/nar/gki045 Improvements to GALA and dbERGE II: databases featuring genomic sequence alignment, annotation and experimental results Laura Elnitski1,2,*, Belinda Giardine1, Prachi Shah1, Yi Zhang1, Cathy Riemer1, Matthew Weirauch4, Richard Burhans1, Webb Miller1,3 and Ross C. Hardison2 1Department of Computer Science and Engineering, 2Department of Biochemistry and Molecular Biology and 3Department of Biology, The Pennsylvania State University, University Park, PA 16802, USA and 4Department of Computer Science, University of California, Santa Cruz, CA 95064, USA Received August 14, 2004; Revised and Accepted September 28, 2004 ABSTRACT gene expression patterns, requires bioinformatic tools for organization and interpretation. Genome browsers, such as We describe improvements to two databases that give the UCSC Genome Browser (1,2), Ensembl (3) and Map access to information on genomic sequence similar- Viewer at NCBI (4), provide views of genes and genomic ities, functional elements in DNA and experimental regions with user-selected annotations. results that demonstrate those functions. GALA, the To provide querying capacity across data types, we devel- database of Genome ALignments and Annotations, is oped GALA, a Genome Alignment and Annotation database. now a set of interlinked relational databases for five The first release recorded whole-genome human–mouse align- vertebrate species, human, chimpanzee, mouse, rat ments along with extensive annotation of the human genome and chicken. For each species, GALA records pair- in a relational database (5). An example of the use of GALA is wise and multiple sequence alignments, scores to find highly conserved regions that do not code for proteins; derived from those alignments that reflect the likeli- some of these could have novel functions.