Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Transcriptome Analysis of Laminar Tissue During the Early Stages of Experimentally Induced Equine Laminitis
GENOME-WIDE TRANSCRIPTOME ANALYSIS OF LAMINAR TISSUE DURING THE EARLY STAGES OF EXPERIMENTALLY INDUCED EQUINE LAMINITIS A Dissertation by JIXIN WANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY December 2010 Major Subject: Biomedical Sciences GENOME-WIDE TRANSCRIPTOME ANALYSIS OF LAMINAR TISSUE DURING THE EARLY STAGES OF EXPERIMENTALLY INDUCED EQUINE LAMINITIS A Dissertation by JIXIN WANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Approved by: Chair of Committee, Bhanu P. Chowdhary Committee Members, Terje Raudsepp Paul B. Samollow Loren C. Skow Penny K. Riggs Head of Department, Evelyn Tiffany-Castiglioni December 2010 Major Subject: Biomedical Sciences iii ABSTRACT Genome-wide Transcriptome Analysis of Laminar Tissue During the Early Stages of Experimentally Induced Equine Laminitis. (December 2010) Jixin Wang, B.S., Tarim University of Agricultural Reclamation; M.S., South China Agricultural University; M.S., Texas A&M University Chair of Advisory Committee: Dr. Bhanu P. Chowdhary Equine laminitis is a debilitating disease that causes extreme sufferring in afflicted horses and often results in a lifetime of chronic pain. The exact sequence of pathophysiological events culminating in laminitis has not yet been characterized, and this is reflected in the lack of any consistently effective therapeutic strategy. For these reasons, we used a newly developed 21,000 element equine-specific whole-genome oligoarray to perform transcriptomic analysis on laminar tissue from horses with experimentally induced models of laminitis: carbohydrate overload (CHO), hyperinsulinaemia (HI), and oligofructose (OF). -

WO 2019/068007 Al Figure 2
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2019/068007 Al 04 April 2019 (04.04.2019) W 1P O PCT (51) International Patent Classification: (72) Inventors; and C12N 15/10 (2006.01) C07K 16/28 (2006.01) (71) Applicants: GROSS, Gideon [EVIL]; IE-1-5 Address C12N 5/10 (2006.0 1) C12Q 1/6809 (20 18.0 1) M.P. Korazim, 1292200 Moshav Almagor (IL). GIBSON, C07K 14/705 (2006.01) A61P 35/00 (2006.01) Will [US/US]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., C07K 14/725 (2006.01) P.O. Box 4044, 7403635 Ness Ziona (TL). DAHARY, Dvir [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (21) International Application Number: Box 4044, 7403635 Ness Ziona (IL). BEIMAN, Merav PCT/US2018/053583 [EilL]; c/o ImmPACT-Bio Ltd., 2 Ilian Ramon St., P.O. (22) International Filing Date: Box 4044, 7403635 Ness Ziona (E.). 28 September 2018 (28.09.2018) (74) Agent: MACDOUGALL, Christina, A. et al; Morgan, (25) Filing Language: English Lewis & Bockius LLP, One Market, Spear Tower, SanFran- cisco, CA 94105 (US). (26) Publication Language: English (81) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of national protection available): AE, AG, AL, AM, 62/564,454 28 September 2017 (28.09.2017) US AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, 62/649,429 28 March 2018 (28.03.2018) US CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, (71) Applicant: IMMP ACT-BIO LTD. -

Evaluating Recovery Potential of the Northern White Rhinoceros from Cryopreserved Somatic Cells
Downloaded from genome.cshlp.org on September 26, 2021 - Published by Cold Spring Harbor Laboratory Press Research Evaluating recovery potential of the northern white rhinoceros from cryopreserved somatic cells Tate Tunstall,1 Richard Kock,2 Jiri Vahala,3 Mark Diekhans,4 Ian Fiddes,4 Joel Armstrong,4 Benedict Paten,4 Oliver A. Ryder,1,5 and Cynthia C. Steiner1,5 1San Diego Zoo Institute for Conservation Research, Escondido, California 92027, USA; 2Royal Veterinary College, University of London, London NW1 0TU, United Kingdom; 3Dvur Krlov Zoo, Dvr Krlov nad Labem 544 01, Czech Republic; 4Jack Baskin School of Engineering, University California Santa Cruz, Santa Cruz, California 95064, USA The critically endangered northern white rhinoceros is believed to be extinct in the wild, with the recent death of the last male leaving only two remaining individuals in captivity. Its extinction would appear inevitable, but the development of advanced cell and reproductive technologies such as cloning by nuclear transfer and the artificial production of gametes via stem cells differentiation offer a second chance for its survival. In this work, we analyzed genome-wide levels of genetic diversity, inbreeding, population history, and demography of the white rhinoceros sequenced from cryopreserved somatic cells, with the goal of informing how genetically valuable individuals could be used in future efforts toward the genetic res- cue of the northern white rhinoceros. We present the first sequenced genomes of the northern white rhinoceros, which show relatively high levels of heterozygosity and an average genetic divergence of 0.1% compared with the southern sub- species. The two white rhinoceros subspecies appear to be closely related, with low genetic admixture and a divergent time <80,000 yr ago. -

Contents 1 Northern White Rhinoceros Pedigree
Contents 1 Northern white rhinoceros pedigree 1 2 Genetic Divergence 2 3 Shared SNP Polymorphism 2 4 Admixture and PCA 4 5 Mitochondrial Tree 5 6 Demographic Inference Using @a@i 7 7 Inbreeding 8 8 Selection 9 9 Identification of the X chromosome 14 1 Northern white rhinoceros pedigree Figure 1: NWR pedigree highlighting individuals sequenced in this study (in blue box) presumably unrelated, with name, studbook number, ID number, and ploidy number 1 Dinka Lucy Angalifu Nola Nadi SB #74 SB #28 SB #348 SB #374 SB #376 KB6571- KB3731- KB9947- KB 8175 KB 5764 1845 618 3803 FZ 2859 FZ 1329 2n = 82 2n = 82 2n = 82 2n = 82 2n = 82 Nasima Saut SB #351 SB #373 KB8174- KB9939- 2872 3799 2n = 82 2n = 82 Nabire Suni SB #789 SB #630 KB8172- KB5765- 2864 2863 2n = 81 2n = 82 2 Genetic Divergence Pair-wise genetic divergence was estimated between all pairs of individuals using sites callable among all individuals, and defined as (2*homs+hets)/(2*callable fraction of genome), as defined in (Prado-Martinez et al., 2013). Divergence values for all individuals are shown in Supplementary Material Table 1. Calcu- lations were performed on the full set of 9.4 million SNPs. 3 Shared SNP Polymorphism In order to calculate shared polymorphism between the NWR and SWR, we took the average polymorphism of all possible combinations of the nine NWR 2 Table 1: Pair-wise genetic divergence for all rhinoceroses included in this study SB 28 SB 377 SB 376 SB 372 SB 156 SB 74 SB 24 SB 147 SB 351 SB 374 SB 373 SB 348 SB 34 SB 28 0 0 0 0 0 0 0 0 0 0 0 0 0 SB 377 0.0020231648 -

The Hypothalamus As a Hub for SARS-Cov-2 Brain Infection and Pathogenesis
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The hypothalamus as a hub for SARS-CoV-2 brain infection and pathogenesis Sreekala Nampoothiri1,2#, Florent Sauve1,2#, Gaëtan Ternier1,2ƒ, Daniela Fernandois1,2 ƒ, Caio Coelho1,2, Monica ImBernon1,2, Eleonora Deligia1,2, Romain PerBet1, Vincent Florent1,2,3, Marc Baroncini1,2, Florence Pasquier1,4, François Trottein5, Claude-Alain Maurage1,2, Virginie Mattot1,2‡, Paolo GiacoBini1,2‡, S. Rasika1,2‡*, Vincent Prevot1,2‡* 1 Univ. Lille, Inserm, CHU Lille, Lille Neuroscience & Cognition, DistAlz, UMR-S 1172, Lille, France 2 LaBoratorY of Development and PlasticitY of the Neuroendocrine Brain, FHU 1000 daYs for health, EGID, School of Medicine, Lille, France 3 Nutrition, Arras General Hospital, Arras, France 4 Centre mémoire ressources et recherche, CHU Lille, LiCEND, Lille, France 5 Univ. Lille, CNRS, INSERM, CHU Lille, Institut Pasteur de Lille, U1019 - UMR 8204 - CIIL - Center for Infection and ImmunitY of Lille (CIIL), Lille, France. # and ƒ These authors contriButed equallY to this work. ‡ These authors directed this work *Correspondence to: [email protected] and [email protected] Short title: Covid-19: the hypothalamic hypothesis 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Gnomad Lof Supplement
1 gnomAD supplement gnomAD supplement 1 Data processing 4 Alignment and read processing 4 Variant Calling 4 Coverage information 5 Data processing 5 Sample QC 7 Hard filters 7 Supplementary Table 1 | Sample counts before and after hard and release filters 8 Supplementary Table 2 | Counts by data type and hard filter 9 Platform imputation for exomes 9 Supplementary Table 3 | Exome platform assignments 10 Supplementary Table 4 | Confusion matrix for exome samples with Known platform labels 11 Relatedness filters 11 Supplementary Table 5 | Pair counts by degree of relatedness 12 Supplementary Table 6 | Sample counts by relatedness status 13 Population and subpopulation inference 13 Supplementary Figure 1 | Continental ancestry principal components. 14 Supplementary Table 7 | Population and subpopulation counts 16 Population- and platform-specific filters 16 Supplementary Table 8 | Summary of outliers per population and platform grouping 17 Finalizing samples in the gnomAD v2.1 release 18 Supplementary Table 9 | Sample counts by filtering stage 18 Supplementary Table 10 | Sample counts for genomes and exomes in gnomAD subsets 19 Variant QC 20 Hard filters 20 Random Forest model 20 Features 21 Supplementary Table 11 | Features used in final random forest model 21 Training 22 Supplementary Table 12 | Random forest training examples 22 Evaluation and threshold selection 22 Final variant counts 24 Supplementary Table 13 | Variant counts by filtering status 25 Comparison of whole-exome and whole-genome coverage in coding regions 25 Variant annotation 30 Frequency and context annotation 30 2 Functional annotation 31 Supplementary Table 14 | Variants observed by category in 125,748 exomes 32 Supplementary Figure 5 | Percent observed by methylation. -
Get High-Res Image
30 20 10 5 52 37 32 69 69 78 # mutations Non syn. Syn. A->T C->(A/T) A->(C/G) C->G indel+null double_null # mutations/Mb 0 1% 2% 1% 2% 1% 1% 1% 4% 1% 2% 1% 1% 2% 2% 1% 1% 1% 2% 1% 1% 1% 2% 2% 1% 2% 1% 3% 1% 1% 2% 2% 1% 2% 2% 2% 1% 1% 2% 1% 2% 1% 1% 2% 4% 2% 2% 1% 1% 2% 2% 1% 1% 2% 2% 1% 2% 2% 2% 2% 2% 1% 3% 2% 6% 3% 2% 1% 2% 2% 3% 3% 2% 2% 3% 2% 2% 2% 2% 2% 2% 2% 2% 2% 6% 2% 2% 2% 12% 2% 2% 3% 2% 3% 2% 3% 2% 7% 2% 2% 3% 5% 8% 3% 4% 3% 8% 3% 9% 9% 5% 9% 7% 11% 23% 20% 21% 0 1 2 3 4 GBM-06-0743-TP GBM-02-0003-TP GBM-32-1970-TP GBM-19-2625-TP GBM-06-2563-TP GBM-06-2567-TP GBM-06-0876-TP GBM-14-0813-TP GBM-28-5207-TP GBM-32-1991-TP GBM-76-4927-TP GBM-06-0157-TP GBM-06-0155-TP GBM-06-0649-TP GBM-06-0749-TP GBM-14-1395-TP GBM-76-6191-TP GBM-28-5209-TP GBM-06-2561-TP GBM-06-1804-TP GBM-06-0881-TP GBM-76-6661-TP GBM-14-1456-TP GBM-14-0790-TP GBM-06-6695-TP GBM-76-6656-TP GBM-26-5139-TP GBM-06-0750-TP GBM-81-5911-TP GBM-14-1034-TP GBM-27-2528-TP GBM-06-5413-TP GBM-06-0879-TP GBM-15-0742-TP GBM-19-1790-TP GBM-06-0154-TP GBM-06-0158-TP GBM-06-0211-TP GBM-06-0650-TP GBM-06-0142-TP GBM-28-1747-TP GBM-06-0137-TP GBM-14-1829-TP GBM-06-2557-TP GBM-14-1823-TP GBM-12-3652-TP GBM-14-0786-TP GBM-06-5856-TP GBM-06-0174-TP GBM-76-4926-TP GBM-27-1831-TP GBM-81-5910-TP GBM-12-3650-TP GBM-14-0789-TP GBM-06-0747-TP GBM-06-6700-TP GBM-19-2624-TP GBM-06-0878-TP GBM-16-1045-TP GBM-06-2565-TP GBM-76-6662-TP GBM-32-2634-TP GBM-06-0184-TP GBM-76-6286-TP GBM-06-5858-TP GBM-76-6283-TP GBM-27-1838-TP GBM-06-0875-TP GBM-06-0195-TP GBM-27-2519-TP GBM-76-4925-TP GBM-16-0846-TP -

Us 2018 / 0305689 A1
US 20180305689A1 ( 19 ) United States (12 ) Patent Application Publication ( 10) Pub . No. : US 2018 /0305689 A1 Sætrom et al. ( 43 ) Pub . Date: Oct. 25 , 2018 ( 54 ) SARNA COMPOSITIONS AND METHODS OF plication No . 62 /150 , 895 , filed on Apr. 22 , 2015 , USE provisional application No . 62/ 150 ,904 , filed on Apr. 22 , 2015 , provisional application No. 62 / 150 , 908 , (71 ) Applicant: MINA THERAPEUTICS LIMITED , filed on Apr. 22 , 2015 , provisional application No. LONDON (GB ) 62 / 150 , 900 , filed on Apr. 22 , 2015 . (72 ) Inventors : Pål Sætrom , Trondheim (NO ) ; Endre Publication Classification Bakken Stovner , Trondheim (NO ) (51 ) Int . CI. C12N 15 / 113 (2006 .01 ) (21 ) Appl. No. : 15 /568 , 046 (52 ) U . S . CI. (22 ) PCT Filed : Apr. 21 , 2016 CPC .. .. .. C12N 15 / 113 ( 2013 .01 ) ; C12N 2310 / 34 ( 2013. 01 ) ; C12N 2310 /14 (2013 . 01 ) ; C12N ( 86 ) PCT No .: PCT/ GB2016 /051116 2310 / 11 (2013 .01 ) $ 371 ( c ) ( 1 ) , ( 2 ) Date : Oct . 20 , 2017 (57 ) ABSTRACT The invention relates to oligonucleotides , e . g . , saRNAS Related U . S . Application Data useful in upregulating the expression of a target gene and (60 ) Provisional application No . 62 / 150 ,892 , filed on Apr. therapeutic compositions comprising such oligonucleotides . 22 , 2015 , provisional application No . 62 / 150 ,893 , Methods of using the oligonucleotides and the therapeutic filed on Apr. 22 , 2015 , provisional application No . compositions are also provided . 62 / 150 ,897 , filed on Apr. 22 , 2015 , provisional ap Specification includes a Sequence Listing . SARNA sense strand (Fessenger 3 ' SARNA antisense strand (Guide ) Mathew, Si Target antisense RNA transcript, e . g . NAT Target Coding strand Gene Transcription start site ( T55 ) TY{ { ? ? Targeted Target transcript , e . -

Expression Pattern of Olfactory Receptor Genes in Human Cumulus Cells As an Indicator for Competent Oocyte Selection
Turkish Journal of Biology Turk J Biol (2020) 44: 371-380 http://journals.tubitak.gov.tr/biology/ © TÜBİTAK Research Article doi:10.3906/biy-2003-79 Expression pattern of olfactory receptor genes in human cumulus cells as an indicator for competent oocyte selection 1 2 1,3 4 5 Neda DAEI-FARSHBAF , Reza AFLATOONIAN , Fatemeh-Sadat AMJADI , Sara TALEAHMAD , Mahnaz ASHRAFI , 3,1, Mehrdad BAKHTIYARI * 1 Department of Anatomy, Faculty of Medicine, Iran University of Medical Sciences, Tehran, Iran 2 Department of Endocrinology and Female Infertility, Reproductive Biomedicine Research Center, Royan Institute for Reproductive Biomedicine, Academic Center for Education, Culture and Research, Tehran, Iran 3 Cellular and Molecular Research Center, Faculty of Medicine, Iran University of Medical Sciences, Tehran, Iran 4 Department of Molecular Systems Biology, Cell Science Research Center, Royan Institute for Stem Cell Biology and Technology (RI-SCBT), Academic Center for Education, Culture and Research, Tehran, Iran 5 Department of Obstetrics and Gynecology, Faculty of Medicine, Iran University of Medical Sciences, Tehran, Iran Received: 26.03.2020 Accepted/Published Online: 09.09.2020 Final Version: 14.12.2020 Abstract: Odorant or olfactory receptors are mainly localized in the olfactory epithelium for the perception of different odors. Interestingly, many ectopic olfactory receptors with low expression levels have recently been found in nonolfactory tissues to involve in local functions. Therefore, we investigated the probable role of the olfactory signaling pathway in the surrounding microenvironment of oocyte. This study included 22 women in intracytoplasmic sperm injection cycle. The expression of olfactory target molecules in cumulus cells surrounding the growing and mature oocytes was evaluated by Western blotting and real-time polymerase chain reaction. -

Comprehensive Genomic Analysis of Dietary Habits in UK Biobank Identifies Hundreds of Genetic Associations
ARTICLE https://doi.org/10.1038/s41467-020-15193-0 OPEN Comprehensive genomic analysis of dietary habits in UK Biobank identifies hundreds of genetic associations ✉ Joanne B. Cole 1,2,3, Jose C. Florez1,2,4 & Joel N. Hirschhorn1,3,5 Unhealthful dietary habits are leading risk factors for life-altering diseases and mortality. Large-scale biobanks now enable genetic analysis of traits with modest heritability, such as 1234567890():,; diet. We perform a genomewide association on 85 single food intake and 85 principal component-derived dietary patterns from food frequency questionnaires in UK Biobank. We identify 814 associated loci, including olfactory receptor associations with fruit and tea intake; 136 associations are only identified using dietary patterns. Mendelian randomization suggests our top healthful dietary pattern driven by wholemeal vs. white bread consumption is causally influenced by factors correlated with education but is not strongly causal for coronary artery disease or type 2 diabetes. Overall, we demonstrate the value in complementary phenotyping approaches to complex dietary datasets, and the utility of genomic analysis to understand the relationships between diet and human health. 1 Programs in Metabolism and Medical and Population Genetics, The Broad Institute of MIT and Harvard, Cambridge, MA, USA. 2 Diabetes Unit and Center for Genomic Medicine, Massachusetts General Hospital, Boston, MA, USA. 3 Division of Endocrinology and Center for Basic and Translational Obesity Research, Boston Children’s Hospital, Boston, MA, -
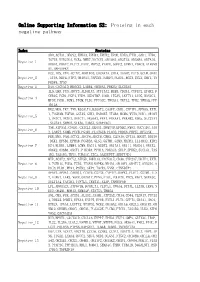
Online Supporting Information S2: Proteins in Each Negative Pathway
Online Supporting Information S2: Proteins in each negative pathway Index Proteins ADO,ACTA1,DEGS2,EPHA3,EPHB4,EPHX2,EPOR,EREG,FTH1,GAD1,HTR6, IGF1R,KIR2DL4,NCR3,NME7,NOTCH1,OR10S1,OR2T33,OR56B4,OR7A10, Negative_1 OR8G1,PDGFC,PLCZ1,PROC,PRPS2,PTAFR,SGPP2,STMN1,VDAC3,ATP6V0 A1,MAPKAPK2 DCC,IDS,VTN,ACTN2,AKR1B10,CACNA1A,CHIA,DAAM2,FUT5,GCLM,GNAZ Negative_2 ,ITPA,NEU4,NTF3,OR10A3,PAPSS1,PARD3,PLOD1,RGS3,SCLY,SHC1,TN FRSF4,TP53 Negative_3 DAO,CACNA1D,HMGCS2,LAMB4,OR56A3,PRKCQ,SLC25A5 IL5,LHB,PGD,ADCY3,ALDH1A3,ATP13A2,BUB3,CD244,CYFIP2,EPHX2,F CER1G,FGD1,FGF4,FZD9,HSD17B7,IL6R,ITGAV,LEFTY1,LIPG,MAN1C1, Negative_4 MPDZ,PGM1,PGM3,PIGM,PLD1,PPP3CC,TBXAS1,TKTL2,TPH2,YWHAQ,PPP 1R12A HK2,MOS,TKT,TNN,B3GALT4,B3GAT3,CASP7,CDH1,CYFIP1,EFNA5,EXTL 1,FCGR3B,FGF20,GSTA5,GUK1,HSD3B7,ITGB4,MCM6,MYH3,NOD1,OR10H Negative_5 1,OR1C1,OR1E1,OR4C11,OR56A3,PPA1,PRKAA1,PRKAB2,RDH5,SLC27A1 ,SLC2A4,SMPD2,STK36,THBS1,SERPINC1 TNR,ATP5A1,CNGB1,CX3CL1,DEGS1,DNMT3B,EFNB2,FMO2,GUCY1B3,JAG Negative_6 2,LARS2,NUMB,PCCB,PGAM1,PLA2G1B,PLOD2,PRDX6,PRPS1,RFXANK FER,MVD,PAH,ACTC1,ADCY4,ADCY8,CBR3,CLDN16,CPT1A,DDOST,DDX56 ,DKK1,EFNB1,EPHA8,FCGR3A,GLS2,GSTM1,GZMB,HADHA,IL13RA2,KIR2 Negative_7 DS4,KLRK1,LAMB4,LGMN,MAGI1,NUDT2,OR13A1,OR1I1,OR4D11,OR4X2, OR6K2,OR8B4,OXCT1,PIK3R4,PPM1A,PRKAG3,SELP,SPHK2,SUCLG1,TAS 1R2,TAS1R3,THY1,TUBA1C,ZIC2,AASDHPPT,SERPIND1 MTR,ACAT2,ADCY2,ATP5D,BMPR1A,CACNA1E,CD38,CYP2A7,DDIT4,EXTL Negative_8 1,FCER1G,FGD3,FZD5,ITGAM,MAPK8,NR4A1,OR10V1,OR4F17,OR52D1,O R8J3,PLD1,PPA1,PSEN2,SKP1,TACR3,VNN1,CTNNBIP1 APAF1,APOA1,CARD11,CCDC6,CSF3R,CYP4F2,DAPK1,FLOT1,GSTM1,IL2 -
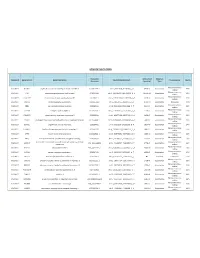
Somatic Mutations
SOMATIC MUTATIONS Transcript Amino Acid Mutation Sample ID Gene Symbol Gene Description Nucleotide (genomic) Consequence Mut % Accession (protein) Type Nonsynonymous PGDX11T ACSBG2 acyl-CoA synthetase bubblegum family member 2 CCDS12159.1 chr19_6141628_6141628_C_A 654A>D Substitution 46% coding Nonsynonymous PGDX11T ATR ataxia telangiectasia and Rad3 related CCDS3124.1 chr3_143721232_143721232_G_A 1451R>W Substitution 32% coding Nonsynonymous PGDX11T C1orf183 chromosome 1 open reading frame 183 CCDS841.1 chr1_112071336_112071336_C_T 224R>Q Substitution 22% coding PGDX11T CMYA5 cardiomyopathy associated 5 NM_153610 chr5_79063455_79063455_C_A 1037C>X Substitution Nonsense 34% Nonsynonymous PGDX11T CNR1 cannabinoid receptor 1 (brain) CCDS5015.1 chr6_88911646_88911646_C_T 23V>M Substitution 35% coding Nonsynonymous PGDX11T COL4A4 collagen; type IV; alpha 4 CCDS42828.1 chr2_227681807_227681807_G_A 227R>C Substitution 20% coding Nonsynonymous PGDX11T CYBASC3 cytochrome b; ascorbate dependent 3 CCDS8004.1 chr11_60877136_60877136_G_A 149R>C Substitution 34% coding Nonsynonymous PGDX11T DYRK3 dual-specificity tyrosine-(Y)-phosphorylation regulated kinase 3 CCDS30999.1 chr1_204888091_204888091_G_A 309V>I Substitution 44% coding Nonsynonymous PGDX11T ELMO1 engulfment and cell motility 1 CCDS5449.1 chr7_37239295_37239295_G_A 160T>M Substitution 24% coding Nonsynonymous PGDX11T FAM83H family with sequence similarity 83; member H CCDS6410.2 chr8_144884473_144884473_C_A 90G>C Substitution 53% coding Nonsynonymous PGDX11T KPTN kaptin (actin binding protein)