Portal Search Custom Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
HCL Software's
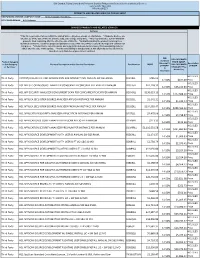
IBM Branded, Fujistu Branded and Panasonic Branded Products and Related Services and Cloud Services Contract DIR-TSO-3999 PRICING SHEET PRODUCTS AND RELATED SERVICES PRICING SHEET RESPONDING VENDOR COMPANY NAME:____Sirius Computer Solutions_______________ PROPOSED BRAND:__HCL Software__________________________ BRANDED PRODUCTS AND RELATED SERVICES Software * This file is generated for use within the United States. All prices shown are US Dollars. * Products & prices are effective as of the date of this file and are subject to change at any time. * HCL may announce new or withdraw products from marketing after the effective date of this file. * Nothwithstanding the product list and prices identified on this file, customer proposals/quotations issued will reflect HCL's current offerings and commercial list prices. * Product list is not all inclusive and may not include products removed from availability (sale) or added after the date of this update. * Product availability is not guaranteed. Not all products listed below are found on every State/Local government contract. DIR DIR CUSTOMER Customer Product Category PRICE (MSRP- Discount % Description or SubCategory Product Description and/or Service Description Part Number MSRP DIR CUSTOMER off MSRP* of MSRP or Services* DISCOUNT Plus (2 Admin Fee) Decimals) HCL SLED Third Party CNTENT/COLLAB ACC AND WEBSPH PRTL SVR INTRANET PVU ANNUAL SW S&S RNWL E045KLL $786.02 14.50% $677.09 Price HCL SLED Third Party HCL APP SEC OPEN SOURCE ANALYZER CONSCAN PER CONCURRENT EVENT PER ANNUM D20H6LL $41,118.32 -

IBM Websphere Portal for Multiplatforms V5.1 Handbook
Front cover IBM WebSpherehere Portal for Multiplatformsplatforms V5.11 Handbook New features and enhancements WebSphere Portal V5.1 implementation demonstrated on multiple platforms Clustering and migration demonstrations included Rufus Credle Faheem Atlaf James Barnes Javier Galvez Sunil Hiranniah Prinz Huang Fernanda Silveira ibm.com/redbooks International Technical Support Organization IBM WebSphere Portal for Multiplatforms V5.1 Handbook April 2005 SG24-6689-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (April 2005) This edition applies to IBM WebSphere Portal for Multiplatforms Version 5.1. © Copyright International Business Machines Corporation 2005. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . x Preface . xi The team that wrote this Redbook . .xi Become a published author . xiv Comments welcome. xiv Chapter 1. WebSphere Portal V5.1: New features and enhancements. 1 1.1 Introduction . 2 1.2 Installation and configuration enhancements . 2 1.3 Virtual portals . 4 1.4 Business process integration . 6 1.5 Search enhancements . 8 1.6 WebSphere Portal Document Manager . 13 1.7 Security enhancements. 16 1.8 Administration, operations, and deployment enhancements. 18 1.9 Personalization . 20 1.10 Web Content Management . 21 1.11 Programming model enhancements . 22 1.12 Summary . 24 Chapter 2. WebSphere Portal V5.1 planning and requirements . 25 2.1 Hardware requirements. 26 2.2 Software requirements . 26 Chapter 3. WebSphere Portal: Microsoft Windows Server 2003 install . 29 3.1 Using install logs . -
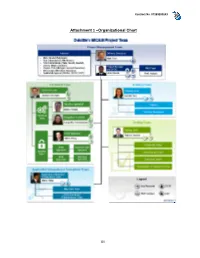
85 Attachment 1 –Organizational Chart
Contract No. 071B3200143 Attachment 1 –Organizational Chart 85 Contract No. 071B3200143 Appendix A - Breakdown of Hardware and Related Software Table 1: Hardware Cost ($): State Brand, Model # Item Specifications will provide from Comments and Description existing Contracts Total # of Virtual The hardware is Machines: 48 sized for Production, QA/Staging, Secure-24 VMware Total # of Virtual Development, and Cluster Access for CPUs: 96 Sandbox Server deploying ISIM, environments in the ISAM and ISFIM Total Virtual RAM: primary data center components 416 GB and for Production, and QA environments in the OS: RedHat Linux secondary data 6.x center The total storage is estimated for Total Storage: 35.7 Production, , TB QA/Staging, Development and Enterprise Class Sandbox Storage (3.8TB of Bronze SAN Storage Tier, 15.8TB of environments in the Silver Tier, 5.1TB of primary data center Logs Tier, 11TB of and for Production, Gold Tier) QA environments in the secondary data center CD/DVD Backup Device None None Rack w/ Power Supply Rack mountable Redundant Power Screen None None A total of 10 Web Gateway appliances are estimated for Production, QA/Staging, Web Gateway Development and Any other Hardware (list) v7.0 Hardware Appliance Sandbox environments in the primary data center and for Production, QA environments in the secondary data center. TOTAL $ 86 Contract No. 071B3200143 Table 2: Related Software Software Component Product Name Cost ($): State # of Licenses Comments License and Version will provide from existing Contracts Contractor user laptops already include this software. We will reuse the Report writers MS Office 2010 State owned software State of Michigan user licenses laptops will need this software for up to 4 users. -

IBM Websphere Portal Here Portal
Front cover IBM WebSpherehere Portal for Multiplatforms V5 Handbook A better installation process and enhanced management capabilities Step-by-step installation instructions for multiplatforms Implementation of powerful clustering and collaboration capabilities Rufus Credle Faheem Altaf Serena Chan Fernanda Gomes Sunil Hiranniah Pralhad Khatri Shun Zhong Li Vikrant Mastoli ibm.com/redbooks International Technical Support Organization IBM WebSphere Portal for Multiplatforms V5 Handbook March 2004 SG24-6098-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xv. First Edition (March 2004) This edition applies to IBM WebSphere Application Server Enterprise V5.0, IBM HTTP Server 1.3.26.1, IBM DB2 Universal Database Enterprise Server Edition 8.1, IBM Directory Server V5.1, IBM Lotus Domino Enterprise Server 5.0.12, Lotus Sametime 3.0, Lotus QuickPlace for Windows 3.01and IBM WebSphere Portal for Multiplatforms, V5.0. © Copyright International Business Machines Corporation 2004. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . xv Trademarks . xvi Preface . xvii The team that wrote this redbook. xviii Become a published author . xx Comments welcome. xxi Chapter 1. Introduction: WebSphere Portal for Multiplatforms V5 . 1 1.1 IBM WebSphere Portal Enable for Multiplatforms. 2 1.2 IBM WebSphere Portal Extend for Multiplatforms. 4 1.3 Tools and components . 5 Chapter 2. Portal technology . 9 2.1 Portal evolution . 10 2.1.1 The generations of portal technology . 11 2.2 Overview . 12 2.2.1 WebSphere Portal architecture . -

Solicitation Number: Usc-R
AMENDMENT NO. 1 TO SOLICITATION TO: ALL VENDORS FROM: Charles Johnson, Procurement Manager SUBJECT: SOLICITATION NUMBER: USC-RFP-1810-CJ PROVIDE WEB CONTENT MANAGEMENT (CMS) AND RELATED SERVICES AND SUPPORT FOR THE EIGHT CAMPUSES WITH MULTIPLE LOCATIONS ACROSS THE STATE OF SOUTH CAROLINA THAT COMPRISE THE UNIVERSITY OF SOUTH CAROLINA SYSTEM DATE: September 27, 2010 This Amendment No.1 modifies the Best Value Bid only in the manner and to the extent as stated herein. BIDDER SHALL ACKNOWLEDGE RECEIPT OF AMENDMENT NO. 1 IN THE SPACE PROVIDED BELOW AND RETURN IT WITH THEIR BID RESPONSE. FAILURE TO DO SO MAY SUBJECT BID TO REJECTION. _____________________________ ________________________ Authorized Signature Name of Offeror _____________________________ Date SUBSECTION C. SCOPE Business Objectives OF SECTION III SCOPE OF WORK / SPECIFICATIONS HAS BEEN MODIFIED AND NOW READS AS FOLLOWS: C. SCOPE Business Objectives The University seeks to enter into a contract with a qualified offerer for a web content management system and related services and support. This system must be accessible from any USC campus and provide administrative access from any location using existing and future resources. CMS users may have PC’s, MAC’s or Linux computers. They may also access university resources with smartphones or other mobile devices. Any web browser could be installed on those devices. The contractor’s proposed Web CMS must support a mixed computing environment. USC technical support personnel requirements should be minimal. Therefore, the contractor will be responsible for updating, maintaining and supporting the application, providing 7X24 access to the application for all users, training USC technical support personnel, providing comprehensive documentation and “train the trainer” courses for CMS users. -

JD Edwards Enterpriseone Statement of Direction – Platforms
JD Edwards EnterpriseOne Statement of Direction – Platforms Last Updated: November 06, 2019 “PURPOSE STATEMENT: THIS DOCUMENT PROVIDES AN OVERVIEW OF CURRENT AND PLANNED PLATFORM SUPPORT INCLUDED IN ORACLE’S JD EDWARDS ENTERPRISEONE TOOLS RELEASES. IT IS INTENDED SOLELY TO HELP YOU ASSESS THE BUSINESS BENEFITS OF UPGRADING ENTERPRISEONE AND TO PLAN YOUR I.T. PROJECTS.” “DISCLAIMER: THIS DOCUMENT IN ANY FORM, SOFTWARE OR PRINTED MATTER, CONTAINS PROPRIETARY INFORMATION THAT IS THE EXCLUSIVE PROPERTY OF ORACLE. YOUR ACCESS TO AND USE OF THIS CONFIDENTIAL MATERIAL IS SUBJECT TO THE TERMS AND CONDITIONS OF YOUR ORACLE SOFTWARE LICENSE AND SERVICE AGREEMENT, WHICH HAS BEEN EXECUTED AND WITH WHICH YOU AGREE TO COMPLY. THIS DOCUMENT AND INFORMATION CONTAINED HEREIN MAY NOT BE DISCLOSED, COPIED, REPRODUCED OR DISTRIBUTED TO ANYONE OUTSIDE ORACLE WITHOUT PRIOR WRITTEN CONSENT OF ORACLE. THIS DOCUMENT IS NOT PART OF YOUR LICENSE AGREEMENT NOR CAN IT BE INCORPORATED INTO ANY CONTRACTUAL AGREEMENT WITH ORACLE OR ITS SUBSIDIARIES OR AFFILIATES. THIS DOCUMENT IS FOR INFORMATIONAL PURPOSES ONLY AND IS INTENDED SOLELY TO ASSIST YOU IN PLANNING FOR THE IMPLEMENTATION AND UPGRADE OF THE PRODUCT FEATURES DESCRIBED. IT IS NOT A COMMITMENT TO DELIVER ANY MATERIAL, CODE, OR FUNCTIONALITY, AND SHOULD NOT BE RELIED UPON IN MAKING PURCHASING DECISIONS. THE DEVELOPMENT, RELEASE, AND TIMING OF ANY FEATURES OR FUNCTIONALITY DESCRIBED IN THIS DOCUMENT REMAINS AT THE SOLE DISCRETION OF ORACLE. DUE TO THE NATURE OF THE PRODUCT ARCHITECTURE, IT MAY NOT BE POSSIBLE TO SAFELY INCLUDE ALL FEATURES DESCRIBED IN THIS DOCUMENT WITHOUT RISKING SIGNIFICANT DESTABILIZATION OF THE CODE.” This document is for informational purposes only and may not be incorporated into any contract. -

ERIC Pirardrue M
ERIC PIRARD [email protected] Rue Maurice Bawin 52 EA & Business Improvement Java Software Engineer PERSONNAL INFORMATION – http Date of Birth: 24 September 1971 – B Nationality: Belgian s ://itoffice.be - Civil Status: Married 4520 Antheit IT EXPERIENCES EA & Business Improvement – Senior Consultant at iMendos – Luxembourg - Since 01/06/2018 Belgium • Tasks: § ARIS (Software AG) tools installation, configuration and administration; § Installation and administration of internal and customer ARIS servers hosted BE: on AWS and Oracle Cloud; +32 497 443 540 § Analysis, specification and development of ARIS reports. • Customers projects § European Parliament – Luxembourg; § Administration du Personnel de l'État – Luxembourg; – LU: +352 6 § eProseed – Luxembourg. Software Engineer at OnePoint PSF – Luxembourg From 01/10/2015 until 31/05/2018 91 377 098 • Projects: § Java services center of OnePoint PSF – From 01/06/2017 Scoring project for Generali Luxembourg – Development of a web application for LCB/FT risks management imposed by the Commissariat Aux Assurances for the fight against money laundering and the terrorism financing. Assigned tasks : - Analysis and estimation of the developments based on the business requirements; - Functional analysis with the customer and estimations review based in the clarified requirements; - Define and realisation of the application and servers architecture; - Technical leader and development management with remote team; - Development of several required backend services. Eric Pirard CV – EA & Business -

IBM Websphere Portal for Multiplatforms V5.1 Handbook
Front cover IBM WebSpherehere Portal for Multiplatformsplatforms V5.11 Handbook New features and enhancements WebSphere Portal V5.1 implementation demonstrated on multiple platforms Clustering and migration demonstrations included Rufus Credle Faheem Atlaf James Barnes Javier Galvez Sunil Hiranniah Prinz Huang Fernanda Silveira ibm.com/redbooks International Technical Support Organization IBM WebSphere Portal for Multiplatforms V5.1 Handbook April 2005 SG24-6689-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (April 2005) This edition applies to IBM WebSphere Portal for Multiplatforms Version 5.1. © Copyright International Business Machines Corporation 2005. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . x Preface . xi The team that wrote this Redbook . .xi Become a published author . xiv Comments welcome. xiv Chapter 1. WebSphere Portal V5.1: New features and enhancements. 1 1.1 Introduction . 2 1.2 Installation and configuration enhancements . 2 1.3 Virtual portals . 4 1.4 Business process integration . 6 1.5 Search enhancements . 8 1.6 WebSphere Portal Document Manager . 13 1.7 Security enhancements. 16 1.8 Administration, operations, and deployment enhancements. 18 1.9 Personalization . 20 1.10 Web Content Management . 21 1.11 Programming model enhancements . 22 1.12 Summary . 24 Chapter 2. WebSphere Portal V5.1 planning and requirements . 25 2.1 Hardware requirements. 26 2.2 Software requirements . 26 Chapter 3. WebSphere Portal: Microsoft Windows Server 2003 install . 29 3.1 Using install logs . -

IBM Distributed Software Passport Advantage & Documentation & Media Date Last Updated: 09-Mar-10 Country/Currency: USA/USD
IBM Distributed Software Passport Advantage & Documentation & Media Date Last Updated: 09-Mar-10 Country/Currency: USA/USD Part Description SRP INFORMATION MANAGEMENT ACTIVE CONTENT EDITION FILENET ACTIVE CONTENT EDITION STANDARD PRODUCT BQ00KML IBM FILENET ACTIVE CONTENT EDITION 4.0 MULTILINGUAL MULTIPLATFORM MEDIA PACK 115.00 C8 BANKING RISK PERFORMANCE C8 BANKING RISK PERFORMANCE STANDARD PRODUCT B501MML IBM COGNOS 8 BANKING PERFORMANCE CREDIT-RISK VERSION 8.4.0 FOR MULTIPLATFORMS 115.00 MULTILINGUAL CD ROM 128 BIT ENCRYPTION MEDIA PACK C8 BI ANALYSIS C8 BI ANALYSIS STANDARD PRODUCT B500CML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS FOR MICROSOFT EXCEL VERSION 8.3 FOR 115.00 WINDOWS MULTILINGUAL CD ROM 128 BIT ENCRYPTION MEDIA PACK B500DML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS FOR MICROSOFT EXCEL VERSION 8.4 FOR 115.00 WINDOWS MULTILINGUAL CD ROM 128 BIT ENCRYPTION MEDIA PACK B5019ML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS VERSION 8.3 FOR MULTIPLATFORMS 115.00 MULTILINGUAL CD ROM 128 BIT ENCRYPTION MEDIA PACK B501BML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS VERSION 8.4 FOR MULTIPLATFORMS 115.00 MULTILINGUAL CD ROM 128 BIT ENCRYPTION MEDIA PACK B502IML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS VERSION 8.4.1 FOR MULTIPLATFORMS 115.00 MULTILINGUAL MEDIA PACK B502MML IBM COGNOS 8 BUSINESS INTELLIGENCE ANALYSIS FOR MICROSOFT EXCEL VERSION 8.4.1 FOR 115.00 WINDOWS MULTILINGUAL MEDIA PACK C8 BI FOR LINUX ON SYSTEM Z ADD ON C8 BI FOR LINUX ON SYSTEM Z ADD-ON STANDARD PRODUCT B5004ML IBM COGNOS 8 BUSINESS INTELLIGENCE FOR LINUX -

JD Edwards Enterpriseone Tools System Overview Guide, Release 9.1.X E50711-04 Copyright © 2013, 2015, Oracle And/Or Its Affiliates
1[JD] Edwards EnterpriseOne Tools System Overview Guide Release 9.1.x E50711-04 April 2015 JD Edwards EnterpriseOne Tools System Overview Guide, Release 9.1.x E50711-04 Copyright © 2013, 2015, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Integrated Identity Managementment Using IBM Tivoli Security Solutions
Front cover Integrated Identity Managementment using IBM Tivoli Security Solutions Latest technology in access control and identity management solutions Holistically covers security in e-business projects Best practices and experiences Axel Bücker Jaime Cordoba Palacios Michael Grimwade Loïc Guézo Mari Heiser Samantha Letts Sridhar Muppidi ibm.com/redbooks International Technical Support Organization Integrated Identity Management using IBM Tivoli Security Solutions May 2004 SG24-6054-00 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. First Edition (May 2004) This edition applies to Tivoli Access Manager for e-business 5.1, Tivoli Identity Manager 4.5, Tivoli Privacy Manager 1.2, Tivoli Risk Manager 4.2, Tivoli Directory Server 5.2, and Tivoli Directory Integrator 5.2. © Copyright International Business Machines Corporation 2004. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix The team that wrote this redbook. ix Become a published author . xii Comments welcome. xii Part 1. Why Integrated Identity Management . 1 Chapter 1. An introduction to a new reference architecture . 3 1.1 Everything is on demand today . 4 1.2 Security management methods and practices . 5 1.2.1 Confidentiality . 6 1.2.2 Integrity . 6 1.2.3 Availability . 6 1.2.4 Areas of security implied in the CIA Triad . 7 1.3 Business drivers . 8 1.4 Issues affecting identity integration solutions . 9 1.5 Integrated identity in the enterprise . 11 1.5.1 Access control management. -

Radislav Golubtsov
Radislav Golubtsov OBJECTIVE To obtain the position of a Software Developer / Senior Software Developer An IT multilinguist SUMMARY Total IT experience – 20 years Hardware ● Intel x86 (i686 / x86-64) ● HP PA-RISC ● IBM PowerPC ● Sun SPARCstation Operating Unices and derivatives (OpenBSD, FreeBSD, Arch Linux, Debian GNU/Linux, Systems Ubuntu, Fedora, CentOS, Red Hat Enterprise Linux, Mac OS X, HP-UX, IBM AIX, Sun Solaris). Microsoft Windows Programming C, Go, Java, Perl 5, Python 2/3, Bash Shell Script, JavaScript (ES5-6/Node.js), Languages GNOME Vala/Genie, Lua, C++, Objective-C 2.0, Fortran 95, Erlang, Elixir, LFE (Lisp Flavoured Erlang), Clojure Technologies ● Python and related modules, libraries, and frameworks (Python Standard Library, Twisted Web, Klein, Falcon, Flask, Celery, Django REST framework, ReportLab PDF Toolkit, etc.) ● Linux kernel API, Linux kernel modules (block device driver) ● Perl and related modules, libraries, and frameworks (DBI, CGI, LWP, Mojolicious, Text::Xslate, Asterisk::AGI, Net::DNS::Native, IO::Select, etc.) ● IVR (Interactive Voice Response) using Asterisk VoIP PBX ● GNU libmicrohttpd (C library to make a lightweight multi-threaded HTTP server), GNU C Library (glibc), GNU C++ Library (libstdc++), GNOME libsoup ● GTFS Realtime (General Transit Feed Specification), Google Text-To-Speech API ● Java SE / EE, Java Servlet, JavaServer Pages (JSP), JSP Standard Tag Library (JSTL), Java Portlet, Spring Boot, Spring Web MVC, Spring Security, Play! Framework, Vaadin Framework, Apache Struts / Struts 2, JavaServer Faces (JSF), Java Database Connectivity (JDBC), JavaMail, Java Abstract Window Toolkit (AWT), Java Swing, iText (Java-PDF Library), jQuery (JavaScript Library), Node.js / Luvit, Harpjs.com, HTML, CSS, XML, YAML, JSON, SQL, GNUstep / Cocoa API, Eclipse Standard Widget Toolkit (SWT), HTTP(S), (S)FTP, SSH, SCP, RESTful microservices, etc.