Evidence for Additive and Synergistic Action of Mammalian
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin
cells Review Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin Agnieszka Bochy ´nska,Juliane Lüscher-Firzlaff and Bernhard Lüscher * ID Institute of Biochemistry and Molecular Biology, Medical School, RWTH Aachen University, Pauwelsstrasse 30, 52057 Aachen, Germany; [email protected] (A.B.); jluescher-fi[email protected] (J.L.-F.) * Correspondence: [email protected]; Tel.: +49-241-8088850; Fax: +49-241-8082427 Received: 18 January 2018; Accepted: 27 February 2018; Published: 2 March 2018 Abstract: Regulation of gene expression is achieved by sequence-specific transcriptional regulators, which convey the information that is contained in the sequence of DNA into RNA polymerase activity. This is achieved by the recruitment of transcriptional co-factors. One of the consequences of co-factor recruitment is the control of specific properties of nucleosomes, the basic units of chromatin, and their protein components, the core histones. The main principles are to regulate the position and the characteristics of nucleosomes. The latter includes modulating the composition of core histones and their variants that are integrated into nucleosomes, and the post-translational modification of these histones referred to as histone marks. One of these marks is the methylation of lysine 4 of the core histone H3 (H3K4). While mono-methylation of H3K4 (H3K4me1) is located preferentially at active enhancers, tri-methylation (H3K4me3) is a mark found at open and potentially active promoters. Thus, H3K4 methylation is typically associated with gene transcription. The class 2 lysine methyltransferases (KMTs) are the main enzymes that methylate H3K4. KMT2 enzymes function in complexes that contain a necessary core complex composed of WDR5, RBBP5, ASH2L, and DPY30, the so-called WRAD complex. -

Utx Is Required for Proper Induction of Ectoderm and Mesoderm During Differentiation of Embryonic Stem Cells
Utx Is Required for Proper Induction of Ectoderm and Mesoderm during Differentiation of Embryonic Stem Cells Cristina Morales Torres1,2, Anne Laugesen1,2, Kristian Helin1,2,3* 1 Biotech Research and Innovation Centre (BRIC), University of Copenhagen, Copenhagen, Denmark, 2 Centre for Epigenetics, University of Copenhagen, Copenhagen, Denmark, 3 The Danish Stem Cell Center, University of Copenhagen, Copenhagen, Denmark Abstract Embryonic development requires chromatin remodeling for dynamic regulation of gene expression patterns to ensure silencing of pluripotent transcription factors and activation of developmental regulators. Demethylation of H3K27me3 by the histone demethylases Utx and Jmjd3 is important for the activation of lineage choice genes in response to developmental signals. To further understand the function of Utx in pluripotency and differentiation we generated Utx knockout embryonic stem cells (ESCs). Here we show that Utx is not required for the proliferation of ESCs, however, Utx contributes to the establishment of ectoderm and mesoderm in vitro. Interestingly, this contribution is independent of the catalytic activity of Utx. Furthermore, we provide data showing that the Utx homologue, Uty, which is devoid of detectable demethylase activity, and Jmjd3 partly compensate for the loss of Utx. Taken together our results show that Utx is required for proper formation of ectoderm and mesoderm in vitro, and that Utx, similar to its C.elegans homologue, has demethylase dependent and independent functions. Citation: Morales Torres C, Laugesen A, Helin K (2013) Utx Is Required for Proper Induction of Ectoderm and Mesoderm during Differentiation of Embryonic Stem Cells. PLoS ONE 8(4): e60020. doi:10.1371/journal.pone.0060020 Editor: Qiang Wu, National University of Singapore, Singapore Received December 13, 2012; Accepted February 21, 2013; Published April 3, 2013 Copyright: ß 2013 Morales Torres et al. -

A Flexible Microfluidic System for Single-Cell Transcriptome Profiling
www.nature.com/scientificreports OPEN A fexible microfuidic system for single‑cell transcriptome profling elucidates phased transcriptional regulators of cell cycle Karen Davey1,7, Daniel Wong2,7, Filip Konopacki2, Eugene Kwa1, Tony Ly3, Heike Fiegler2 & Christopher R. Sibley 1,4,5,6* Single cell transcriptome profling has emerged as a breakthrough technology for the high‑resolution understanding of complex cellular systems. Here we report a fexible, cost‑efective and user‑ friendly droplet‑based microfuidics system, called the Nadia Instrument, that can allow 3′ mRNA capture of ~ 50,000 single cells or individual nuclei in a single run. The precise pressure‑based system demonstrates highly reproducible droplet size, low doublet rates and high mRNA capture efciencies that compare favorably in the feld. Moreover, when combined with the Nadia Innovate, the system can be transformed into an adaptable setup that enables use of diferent bufers and barcoded bead confgurations to facilitate diverse applications. Finally, by 3′ mRNA profling asynchronous human and mouse cells at diferent phases of the cell cycle, we demonstrate the system’s ability to readily distinguish distinct cell populations and infer underlying transcriptional regulatory networks. Notably this provided supportive evidence for multiple transcription factors that had little or no known link to the cell cycle (e.g. DRAP1, ZKSCAN1 and CEBPZ). In summary, the Nadia platform represents a promising and fexible technology for future transcriptomic studies, and other related applications, at cell resolution. Single cell transcriptome profling has recently emerged as a breakthrough technology for understanding how cellular heterogeneity contributes to complex biological systems. Indeed, cultured cells, microorganisms, biopsies, blood and other tissues can be rapidly profled for quantifcation of gene expression at cell resolution. -

Genome-Wide DNA Methylation Analysis of KRAS Mutant Cell Lines Ben Yi Tew1,5, Joel K
www.nature.com/scientificreports OPEN Genome-wide DNA methylation analysis of KRAS mutant cell lines Ben Yi Tew1,5, Joel K. Durand2,5, Kirsten L. Bryant2, Tikvah K. Hayes2, Sen Peng3, Nhan L. Tran4, Gerald C. Gooden1, David N. Buckley1, Channing J. Der2, Albert S. Baldwin2 ✉ & Bodour Salhia1 ✉ Oncogenic RAS mutations are associated with DNA methylation changes that alter gene expression to drive cancer. Recent studies suggest that DNA methylation changes may be stochastic in nature, while other groups propose distinct signaling pathways responsible for aberrant methylation. Better understanding of DNA methylation events associated with oncogenic KRAS expression could enhance therapeutic approaches. Here we analyzed the basal CpG methylation of 11 KRAS-mutant and dependent pancreatic cancer cell lines and observed strikingly similar methylation patterns. KRAS knockdown resulted in unique methylation changes with limited overlap between each cell line. In KRAS-mutant Pa16C pancreatic cancer cells, while KRAS knockdown resulted in over 8,000 diferentially methylated (DM) CpGs, treatment with the ERK1/2-selective inhibitor SCH772984 showed less than 40 DM CpGs, suggesting that ERK is not a broadly active driver of KRAS-associated DNA methylation. KRAS G12V overexpression in an isogenic lung model reveals >50,600 DM CpGs compared to non-transformed controls. In lung and pancreatic cells, gene ontology analyses of DM promoters show an enrichment for genes involved in diferentiation and development. Taken all together, KRAS-mediated DNA methylation are stochastic and independent of canonical downstream efector signaling. These epigenetically altered genes associated with KRAS expression could represent potential therapeutic targets in KRAS-driven cancer. Activating KRAS mutations can be found in nearly 25 percent of all cancers1. -

1714 Gene Comprehensive Cancer Panel Enriched for Clinically Actionable Genes with Additional Biologically Relevant Genes 400-500X Average Coverage on Tumor
xO GENE PANEL 1714 gene comprehensive cancer panel enriched for clinically actionable genes with additional biologically relevant genes 400-500x average coverage on tumor Genes A-C Genes D-F Genes G-I Genes J-L AATK ATAD2B BTG1 CDH7 CREM DACH1 EPHA1 FES G6PC3 HGF IL18RAP JADE1 LMO1 ABCA1 ATF1 BTG2 CDK1 CRHR1 DACH2 EPHA2 FEV G6PD HIF1A IL1R1 JAK1 LMO2 ABCB1 ATM BTG3 CDK10 CRK DAXX EPHA3 FGF1 GAB1 HIF1AN IL1R2 JAK2 LMO7 ABCB11 ATR BTK CDK11A CRKL DBH EPHA4 FGF10 GAB2 HIST1H1E IL1RAP JAK3 LMTK2 ABCB4 ATRX BTRC CDK11B CRLF2 DCC EPHA5 FGF11 GABPA HIST1H3B IL20RA JARID2 LMTK3 ABCC1 AURKA BUB1 CDK12 CRTC1 DCUN1D1 EPHA6 FGF12 GALNT12 HIST1H4E IL20RB JAZF1 LPHN2 ABCC2 AURKB BUB1B CDK13 CRTC2 DCUN1D2 EPHA7 FGF13 GATA1 HLA-A IL21R JMJD1C LPHN3 ABCG1 AURKC BUB3 CDK14 CRTC3 DDB2 EPHA8 FGF14 GATA2 HLA-B IL22RA1 JMJD4 LPP ABCG2 AXIN1 C11orf30 CDK15 CSF1 DDIT3 EPHB1 FGF16 GATA3 HLF IL22RA2 JMJD6 LRP1B ABI1 AXIN2 CACNA1C CDK16 CSF1R DDR1 EPHB2 FGF17 GATA5 HLTF IL23R JMJD7 LRP5 ABL1 AXL CACNA1S CDK17 CSF2RA DDR2 EPHB3 FGF18 GATA6 HMGA1 IL2RA JMJD8 LRP6 ABL2 B2M CACNB2 CDK18 CSF2RB DDX3X EPHB4 FGF19 GDNF HMGA2 IL2RB JUN LRRK2 ACE BABAM1 CADM2 CDK19 CSF3R DDX5 EPHB6 FGF2 GFI1 HMGCR IL2RG JUNB LSM1 ACSL6 BACH1 CALR CDK2 CSK DDX6 EPOR FGF20 GFI1B HNF1A IL3 JUND LTK ACTA2 BACH2 CAMTA1 CDK20 CSNK1D DEK ERBB2 FGF21 GFRA4 HNF1B IL3RA JUP LYL1 ACTC1 BAG4 CAPRIN2 CDK3 CSNK1E DHFR ERBB3 FGF22 GGCX HNRNPA3 IL4R KAT2A LYN ACVR1 BAI3 CARD10 CDK4 CTCF DHH ERBB4 FGF23 GHR HOXA10 IL5RA KAT2B LZTR1 ACVR1B BAP1 CARD11 CDK5 CTCFL DIAPH1 ERCC1 FGF3 GID4 HOXA11 IL6R KAT5 ACVR2A -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Potential Genotoxicity from Integration Sites in CLAD Dogs Treated Successfully with Gammaretroviral Vector-Mediated Gene Therapy
Gene Therapy (2008) 15, 1067–1071 & 2008 Nature Publishing Group All rights reserved 0969-7128/08 $30.00 www.nature.com/gt SHORT COMMUNICATION Potential genotoxicity from integration sites in CLAD dogs treated successfully with gammaretroviral vector-mediated gene therapy M Hai1,3, RL Adler1,3, TR Bauer Jr1,3, LM Tuschong1, Y-C Gu1,XWu2 and DD Hickstein1 1Experimental Transplantation and Immunology Branch, Center for Cancer Research, National Cancer Institute, National Institutes of Health, Bethesda, Maryland, USA and 2Laboratory of Molecular Technology, Scientific Applications International Corporation-Frederick, National Cancer Institute-Frederick, Frederick, Maryland, USA Integration site analysis was performed on six dogs with in hematopoietic stem cells. Integrations clustered around canine leukocyte adhesion deficiency (CLAD) that survived common insertion sites more frequently than random. greater than 1 year after infusion of autologous CD34+ bone Despite potential genotoxicity from RIS, to date there has marrow cells transduced with a gammaretroviral vector been no progression to oligoclonal hematopoiesis and no expressing canine CD18. A total of 387 retroviral insertion evidence that vector integration sites influenced cell survival sites (RIS) were identified in the peripheral blood leukocytes or proliferation. Continued follow-up in disease-specific from the six dogs at 1 year postinfusion. A total of 129 RIS animal models such as CLAD will be required to provide an were identified in CD3+ T-lymphocytes and 102 RIS in accurate estimate -

MLL3/MLL4 Methyltransferase Activities Regulate Embryonic Stem Cell
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.14.296558; this version posted September 14, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 MLL3/MLL4 methyltransferase activities regulate embryonic stem cell 2 differentiation independent of enhancer H3K4me1 3 4 Guojia Xie1, Ji-Eun Lee1, Kaitlin McKernan1, Young-Kwon Park1, Younghoon Jang1, Chengyu Liu2, Weiqun 5 Peng3 and Kai Ge1* 6 7 1Laboratory of Endocrinology and Receptor Biology, National Institute of Diabetes and Digestive and Kidney 8 Diseases, National Institutes of Health, Bethesda, MD 20892, USA 9 2Transgenic Core, National Heart, Lung, and Blood Institute, National Institutes of Health, Bethesda, MD 10 20892, USA 11 3Departments of Physics and Anatomy and Cell Biology, The George Washington University, Washington, 12 DC 20052, USA 13 14 *To whom correspondence should be addressed. (Email: [email protected]) 15 16 17 18 19 Highlights 20 ● Simultaneous elimination of MLL3 and MLL4 enzymatic activities leads to early embryonic lethality in 21 mice 22 ● MLL3/4 enzymatic activities are dispensable for ESC differentiation towards the three germ layers 23 ● ESCs lacking MLL3/4 enzymatic activities show cavitation defects during EB differentiation, likely due 24 to impaired VE induction 25 ● MLL3/4-catalyzed H3K4me1 is dispensable for enhancer activation in ESC differentiation 26 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.09.14.296558; this version posted September 14, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. -
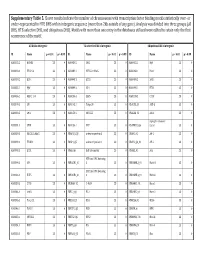
Supplementary Table 5. Clover Results Indicate the Number Of
Supplementary Table 5. Clover results indicate the number of chromosomes with transcription factor binding motifs statistically over‐ or under‐represented in HTE DHS within intergenic sequence (more than 2kb outside of any gene). Analysis was divided into three groups (all DHS, HTE‐selective DHS, and ubiquitous DHS). Motifs with more than one entry in the databases utilized were edited to retain only the first occurrence of the motif. All DHS x Intergenic TEselective DHS x Intergenic Ubiquitous DHS x Intergenic ID Name p < 0.01 p > 0.99 ID Name p < 0.01 p > 0.99 ID Name p < 0.01 p > 0.99 MA0002.2 RUNX1 23 0 MA0080.2 SPI1 23 0 MA0055.1 Myf 23 0 MA0003.1 TFAP2A 23 0 MA0089.1 NFE2L1::MafG 23 0 MA0068.1 Pax4 23 0 MA0039.2 Klf4 23 0 MA0098.1 ETS1 23 0 MA0080.2 SPI1 23 0 MA0055.1 Myf 23 0 MA0099.2 AP1 23 0 MA0098.1 ETS1 23 0 MA0056.1 MZF1_1‐4 23 0 MA0136.1 ELF5 23 0 MA0139.1 CTCF 23 0 MA0079.2 SP1 23 0 MA0145.1 Tcfcp2l1 23 0 V$ALX3_01 ALX‐3 23 0 MA0080.2 SPI1 23 0 MA0150.1 NFE2L2 23 0 V$ALX4_02 Alx‐4 23 0 myocyte enhancer MA0081.1 SPIB 23 0 MA0156.1 FEV 23 0 V$AMEF2_Q6 factor 23 0 MA0089.1 NFE2L1::MafG 23 0 V$AP1FJ_Q2 activator protein 1 23 0 V$AP1_01 AP‐1 23 0 MA0090.1 TEAD1 23 0 V$AP4_Q5 activator protein 4 23 0 V$AP2_Q6_01 AP‐2 23 0 MA0098.1 ETS1 23 0 V$AR_Q6 half‐site matrix 23 0 V$ARX_01 Arx 23 0 BTB and CNC homolog MA0099.2 AP1 23 0 V$BACH1_01 1 23 0 V$BARHL1_01 Barhl‐1 23 0 BTB and CNC homolog MA0136.1 ELF5 23 0 V$BACH2_01 2 23 0 V$BARHL2_01 Barhl2 23 0 MA0139.1 CTCF 23 0 V$CMAF_02 C‐MAF 23 0 V$BARX1_01 Barx1 23 0 MA0144.1 Stat3 23 0 -

Functional Annotation of Human Long Noncoding Rnas Using Chromatin
bioRxiv preprint doi: https://doi.org/10.1101/2021.01.13.426305; this version posted January 14, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Funconal annotaon of human long noncoding RNAs using chroman conformaon data Saumya Agrawal1, Tanvir Alam2, Masaru Koido1,3, Ivan V. Kulakovskiy4,5, Jessica Severin1, Imad ABugessaisa1, Andrey Buyan5,6, Josee Dos&e7, Masayoshi Itoh1,8, Naoto Kondo9, Yunjing Li10, Mickaël Mendez11, Jordan A. Ramilowski1,12, Ken Yagi1, Kayoko Yasuzawa1, CHi Wai Yip1, Yasushi Okazaki1, MicHael M. Ho9man11,13,14,15, Lisa Strug10, CHung CHau Hon1, CHikashi Terao1, Takeya Kasukawa1, Vsevolod J. Makeev4,16, Jay W. SHin1, Piero Carninci1, MicHiel JL de Hoon1 1RIKEN Center for Integra&ve Medical Sciences, YokoHama, Japan. 2College of Science and Engineering, Hamad Bin KHalifa University, DoHa, Qatar. 3Ins&tute of Medical Science, THe University of Tokyo, Tokyo, Japan. 4Vavilov Ins&tute of General Gene&cs, Russian Academy of Sciences, Moscow, Russia. 5Ins&tute of Protein ResearcH, Russian Academy of Sciences, PusHcHino, Russia. 6Faculty of Bioengineering and Bioinforma&cs, Lomonosov Moscow State University, Moscow, Russia. 7Department of BiocHemistry, Rosalind and Morris Goodman Cancer ResearcH Center, McGill University, Montréal, QuéBec, Canada. 8RIKEN Preven&ve Medicine and Diagnosis Innova&on Program, Wako, Japan. 9RIKEN Center for Life Science TecHnologies, YokoHama, Japan. 10Division of Biosta&s&cs, Dalla Lana ScHool of PuBlic HealtH, University of Toronto, Toronto, Ontario, Canada. 11Department of Computer Science, University of Toronto, Toronto, Ontario, Canada. 12Advanced Medical ResearcH Center, YokoHama City University, YokoHama, Japan. -

Alterations of NFIA in Chronic Malignant Myeloid Diseases
Letters to the Editor 583 BACH2 is a B-cell specific transcription factor that induces 2Laboratoire d0He´matologie, CHU de Caen, Caen, France; 3 apoptosis in lymphoma cells and reduced expression has been De´parement de Genetique, Laboratoire Pasteur, Cerba, France and associated with poor prognostic outcome in diffuse large B-cell 4 lymphoma.7 Department of Haematology, John Radcliffe Hospital, Oxford, UK Our data also suggested that many components of the E-mail: [email protected] transforming growth factor-b (TGFb) signalling pathway are downregulated in PPBL (Supplementary Figure S3), including the tumour-suppressor molecule SMAD4 (Figure 1i; P ¼ 0.007). The TGFb pathway negatively regulates cell growth, and References inactivation of SMAD4 is present in over half of pancreatic 8 cancers and up to 35% of colorectal cancers. This is as far as 1 Mossafa H, Malaure H, Maynadie M, Valensi F, Schillinger F, we know the first description of the downregulation of SMAD4 Garand R et al. Persistent polyclonal B lymphocytosis with in a B-cell disorder. binucleated lymphocytes: a study of 25 cases. Groupe Francais PPBL represents a useful model for B-cell dysfunction as it d’Hematologie Cellulaire. Br J Haematol 1999; 104: 486–493. displays characteristics associated with benign (polyclonality, 2 Ozanne BW, Spence HJ, McGarry LC, Hennigan RF. Transcription factors control invasion: AP-1 the first among equals. Oncogene benign clinical course) and malignant disease (frequent chromo- 2007; 26: 1–10. somal abnormalities and aberrant B-cell morphology). Nearly all 3 Watanabe M, Sasaki M, Itoh K, Higashihara M, Umezawa K, Kadin studies to date have sought to characterize the morphological or ME et al. -

A Small UTX Stabilization Domain of Trr Is Conserved Within Mammalian MLL3-4/COMPASS and Is Sufficient to Rescue Loss of Viability in Null Animals
Downloaded from genesdev.cshlp.org on October 4, 2021 - Published by Cold Spring Harbor Laboratory Press A small UTX stabilization domain of Trr is conserved within mammalian MLL3-4/ COMPASS and is sufficient to rescue loss of viability in null animals Ryan Rickels,1 Lu Wang,1 Marta Iwanaszko,1 Patrick A. Ozark,1 Marc A. Morgan,1 Andrea Piunti,1 Natalia Khalatyan,2 Shimaa H.A. Soliman,1 Emily J. Rendleman,1 Jeffrey N. Savas,2 Edwin R. Smith,1 and Ali Shilatifard1 1Simpson Querrey Institute for Epigenetics, Department of Biochemistry and Molecular Genetics, 2Department of Neurology, Northwestern University Feinberg School of Medicine, Chicago, Illinois 60611, USA Catalytic-inactivating mutations within the Drosophila enhancer H3K4 mono-methyltransferase Trr and its mammalian homologs, MLL3/4, cause only minor changes in gene expression compared with whole-gene deletions for these COMPASS members. To identify essential histone methyltransferase-independent functions of Trr, we screened to identify a minimal Trr domain sufficient to rescue Trr-null lethality and demonstrate that this domain binds and stabilizes Utx in vivo. Using the homologous MLL3/MLL4 human sequences, we mapped a short ∼80- amino-acid UTX stabilization domain (USD) that promotes UTX stability in the absence of the rest of MLL3/4. Nuclear UTX stability is enhanced when the USD is fused with the MLL4 HMG-box. Thus, COMPASS-dependent UTX stabilization is an essential noncatalytic function of Trr/MLL3/MLL4, suggesting that stabilizing UTX could be a therapeutic strategy for cancers with MLL3/4 loss-of-function mutations. [Keywords: COMPASS; chromatin; epigenetics; transcription] Supplemental material is available for this article.