Renderering Roblox
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

EEMBC and the Purposes of Embedded Processor Benchmarking Markus Levy, President
EEMBC and the Purposes of Embedded Processor Benchmarking Markus Levy, President ISPASS 2005 Certified Performance Analysis for Embedded Systems Designers EEMBC: A Historical Perspective • Began as an EDN Magazine project in April 1997 • Replace Dhrystone • Have meaningful measure for explaining processor behavior • Developed business model • Invited worldwide processor vendors • A consortium was born 1 EEMBC Membership • Board Member • Membership Dues: $30,000 (1st year); $16,000 (subsequent years) • Access and Participation on ALL Subcommittees • Full Voting Rights • Subcommittee Member • Membership Dues Are Subcommittee Specific • Access to Specific Benchmarks • Technical Involvement Within Subcommittee • Help Determine Next Generation Benchmarks • Special Academic Membership EEMBC Philosophy: Standardized Benchmarks and Certified Scores • Member derived benchmarks • Determine the standard, the process, and the benchmarks • Open to industry feedback • Ensures all processor/compiler vendors are running the same tests • Certification process ensures credibility • All benchmark scores officially validated before publication • The entire benchmark environment must be disclosed 2 Embedded Industry: Represented by Very Diverse Applications • Networking • Storage, low- and high-end routers, switches • Consumer • Games, set top boxes, car navigation, smartcards • Wireless • Cellular, routers • Office Automation • Printers, copiers, imaging • Automotive • Engine control, Telematics Traditional Division of Embedded Applications Low High Power -

Imagination Technologies Group Plc Annual Report 2006
Imagination Technologies Group plc Annual Report 2006 The data and projections shown on pages 1-24 are the product of consolidated partner data, analyst information and Imagination Technologies research. Imagination Technologies, the Imagination Technologies logo, PowerVR, the PowerVR logo, Metagence, the Metagence logo, Ensigma, the Ensigma logo, PURE Digital, IMGworks, CodeScape, META, MTX, MBX, MBX Lite, SGX, UCC, MiniEngine, PocketDAB, ReVu, the Bug, the Bug logo, Legato, EVOKE-1, TEMPUS, CHRONOS, OASIS, PURE ONE, SONUS-1XT and Élan are trademarks or registered trademarks of Imagination Technologies Limited. All other logos, products, trademarks and registered trademarks are the property of their respective owners. Copyright © 2006 Imagination Technologies Limited, an Imagination Technologies Group plc company. 4 colour print + matt lamination on 1 side, 215x280mm (h) trim size with 4mm spin, 300gsm board fold, gather and perfect bind 19/06/2006 Contact Oscar Tse / IMG Publications / 01923 260511 / [email protected] Introduction Improvements in technology mean that more and more functions can be integrated onto just one silicon chip. Whilst in the past, half a dozen companies might each have made a specialised chip to go into an advanced product like a TV or mobile phone, now it is more likely that one large semiconductor company will make a single chip that contains most, if not all, of that specialised knowledge. That’s where silicon IP, or ‘intellectual property’ comes in. Semiconductor companies can licence parts of a chip design from companies that specialise in those advanced technologies, instead of developing the technology themselves. They are especially likely to do this in new market areas. -
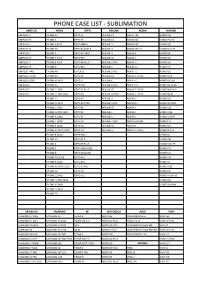
Qikink Product & Price List
PHONE CASE LIST - SUBLIMATION ONEPLUS APPLE OPPO REALME NOKIA HUAWEI ONEPLUS 3 IPHONE SE OPPO F3 REALME C1 NOKIA 730 HONOR 6X ONEPLUS 3T IPHONE 6 OPPO F5 REALME C2 NOKIA 640 HONOR 9 LITE ONEPLUS 5 IPHONE 6 PLUS OPPO FIND X REALME 3 NOKIA 540 HONOR Y9 ONEPLUS 5T IPHONE 6S OPPO REALME X REALME 3i NOKIA 7 PLUS HONOR 10 LITE ONEPLUS 6 IPHONE 7 OPPO F11 PRO REALME 5i NOKIA 8 HONOR 8C ONEPLUS 6T IPHONE 7 PLUS OPPO F15 REALME 5S NOKIA 6 HONOR 8X ONEPLUS 7 IPHONE 8 PLUS OPPO RENO 2F REALME 2 PRO NOKIA 3.1 HONOR 10 ONEPLUS 7T IPHONE X OPPO F11 REALME 3 NOKIA 2.1 HONOR 7C ONEPLUS 7PRO IPHONE XR OPPOF13 REALME 3 PRO NOKIA 7.1 HONOR 5C ONEPLUS 7T PRO IPHONE XS OPPO F1 REALME C3 NOKIA 3.1 PLUS HONOR P20 ONEPLUS NORD IPHONE XS MAX OPPO F7 REALME 6 NOKIA 5.1 HONOR 6PLUS ONEPLUS X IPHONE 11 OPPO A57 REALME 6 PRO NOKIA 7.2 HONOR PLAY 8A ONEPLUS 2 IPHONE 11 PRO OPPO F1 PLUS REALME X2 NOKIA 7.1 PLUS HONOR NOVA 3i ONEPLUS 1 IPHONE 11 PRO MAX OPPO F9 REALME X2 PRO NOKIA 6.1 PLUS HONOR PLAY IPHONE 12 OPPO A7 REALME 5 NOKIA 6.1 HONOR 8X IPHONE 12 MINI OPPO R17 PRO REALME 5 PRO NOKIA 8.1 HONOR 8X MAX IPHONE 12 PRO OPPO K1 REALME XT NOKIA 2 HONOR 20i IPHONE 12 PRO MAX OPPO F9 REALME 1 NOKIA 3 HONOR V20 IPHONE X LOGO OPPO F3 REALME X NOKIA 5 HONOR 6 PLAY IPHONE 7 LOGO OPPO A3 REALME 7 PRO NOKIA 6 (2018) HONOR 7X IPHONE 6 LOGO OPPO A5 REALME 5S NOKIA 8 HONOR 5X IPHONE XS MAX LOGO OPPO A9 REALME 5i NOKIA 2.1 PLUS HONOR 8 LITE IPHONE 8 LOGO OPPO R98 HONOR 8 IPHONE 5S OPPO F1 S HONOR 9N IPHONE 4 OPPO F3 PLUS HONOR 10 LITE IPHONE 5 OPPO A83 (2018) HONOR 7S IPHONE 8 -

Cennik Urządzeń Bez Umowy
Cennik urządzeń bez umowy Obowiązuje od dnia 01.04.2021 do wyczerpania stanów magazynowych objętych niniejszym Cennikiem lub jego odwołania. Model Cena bez umowy 2x Alcatel 3X 2019 999 2x Honor FlyPods Lite 399 2x Huawei P30 Lite 1999 2x Huawei Y6S 999 2x LG G8s ThinQ 3399 2x Meizu M6T 2+16 GB DS 499 2x Samsung A405F Galaxy A40 1599 2x TCL Słuchawki SOCL100BT 199 2x Xiaomi Redmi Note 8T 1499 Alcatel 1S 2020 399 Alcatel 1S 2020 UZZ 399 Alcatel 30.25 179 Alcatel 30.25 UZZ 179 Dual Screen do LGV60 899 FitGo FW10 Active 49 Folia Clearplex Ultra Film 89 Freestyle FH0915 69 Głośnik Bluetooth Spin-It Widget 49 Głośnik Maxton Masaya 69 Głośnik Maxton MX680 99 Hammer 5 Smart 299 Hammer Blade 3 1389 Hammer Energy 2 699 Hammer Energy 2 UZZ 599 Hammer Explorer 929 Hammer Explorer UZZ 899 Hover Ball 29,99 HP Pavilion 14 + Huawei E5573Cs 3249 HP Pavilion 14 + Huawei E5573Cs UZZ 2999 HTC Desire 20 Pro 1199 Huawei Band 4 Pro 199 Huawei BT SpeakerAM08 79 Huawei Color Band A2 99 Huawei FreeLace 299 P4 Sp. z o.o. ul. Wynalazek 1, 02-677 Warszawa, KRS 0000217207, REGON 015808609, NIP 951-21-20-077, Kapitał zakładowy 48.856.500,00 zł Strona 1 z 28 Model Cena bez umowy Huawei Mate 10 Lite DS + Mate 10 Lite DS 2199 Huawei Matebook D 14 + E5573C + HW CM51 2881 Huawei Matebook D 14+E5573C+HW AM61 2881 Huawei MediaPad T3 10 LTE 769 Huawei Mini Speaker CM510 79 Huawei NetBox B2368-66 cat.12 + Deco M5 1849 Huawei NetBox B2368-66 cat.12. -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Power Aware Tactical Computing
Power Aware Tactical Computing Song J Park1, Dale R Shires1, Brian J Henz1, James A Ross2, David A Richie3, and Jordan J Ruloff2 1U.S. Army Research Laboratory, APG, MD 2Dynamic Research Corp., Andover, MA 3Brown Deer Technology, Forest Hill, MD Abstract - Power consumption has become a chief supports and maintains high performance computing (HPC) impediment in the advancement of digital computing. To resources. The ARL DSRC provides state-of-the-art improve performance amid power limitations, accelerators computational solutions for the DoD research and are being applied to everyday systems. In particular, due to development community. Among the systems available at the mix of popularity and raw computational power, ARL is Harold system, which consists of 10,752 cores with graphics processing units (GPUs) have extended the the processing capability of 120 trillion floating-point applicability of digital computing in a multitude of sectors operations per second (TFLOPS). A predecessor, JVN from ubiquitous smartphones to environmentally responsible system, decommissioned in 2009, had 2048 cores with the supercomputing. Operating within the mobile power theoretical peak of 14.7 TFLOPS. Shifting the focus to constraint, the usefulness of a high performance graphics single-precision, the peak processing power for the Harold processor system in a tactical environment is explored in this system is 240 TFLOPS and 29.5 TFLOPS for the JVN study. A line-of-sight optimization algorithm serves as a system. Given that a single graphics card, Radeon HD 6990, compute-intensive application with characteristics relating is rated at 5.1 TFLOPS for peak single-precision arithmetic, to a tactical scenario. -

IMG PPT Template
Imagination Technologies Group Overview May 2010 Company Overview . Leading Semiconductor IP Supplier . POWERVR™ graphics, video, display processing . ENSIGMA™ receivers and communications processors . META™ processors – SoC centric real-time, DSP, Linux . Licensees: Leading Semis and OEMs . #3 Silicon Design IP provider * . Innovative Consumer Product Manufacturer . PURE digital radio, internet connected audio . Established technology powerhouse . Founded:1985 . Listed:1994-London Stock Exchange:IMG . Employees: more than 650 worldwide * Source: Gartner IP Suppliers Report, March 2010 UK Headquarters R&D Sales 2.2 © Imagination Technologies Ltd. Group Revenues £m 65 60 PURE 55 Technology 50 45 40 35 30 25 20 15 10 5 0 04/05 05/06 06/07 07/08** 08/09 * 13 months to April ‘08 3 © Imagination Technologies Ltd. Everything, Everywhere The connected “four screens”: TV, PC, Mobile & In-Car The Cloud Mobile devices have to deliver the internet, PC capabilities, TV, music, navigation and more… 4 © Imagination Technologies Ltd. Our Technology Business SoC Technologies & Solutions Markets Mobile IMGworks Phone Customer’s 3rd Party IP Internal IP Customised IP Multimedia ENSIGMA META POWERVR Communications Hand-held Processor/DSP Graphics Multimedia POWERVR Display META POWERVR Audio Video SoC Home Consumer & Entertainment Display Audio Mobile Computing OpenGL MeOS Radio OpenGL-ES De-interlace Nucleus TV OpenVG Linux Frame rate In-Car Mobile TV DirectX conversion Android Electronics WiFi etc Audio Bluetooth Noise SW Stacks reduction etc MPEG1/2/4 etc H264 etc Emerging VC1 Markets etc 5 © Imagination Technologies Ltd. The Virtuous Technology Cycle… Semiconductor Partners Creates SoCs & Sells Chips SUNPLUS Makes products Creates & & sells them to Licenses IP consumers… OEMs Emerging trend with OEM partners Consumers demand more, better, cheaper…everywhere Consumers …which drives demand for more advanced & efficient IP … 6 © Imagination Technologies Ltd. -

Qualcomm® Quick Charge™ Technology Device List
One charging solution is all you need. Waiting for your phone to charge is a thing of the past. Quick Charge technology is ® designed to deliver lightning-fast charging Qualcomm in phones and smart devices featuring Qualcomm® Snapdragon™ mobile platforms ™ and processors, giving you the power—and Quick Charge the time—to do more. Technology TABLE OF CONTENTS Quick Charge 5 Device List Quick Charge 4/4+ Quick Charge 3.0/3+ Updated 09/2021 Quick Charge 2.0 Other Quick Charge Devices Qualcomm Quick Charge and Qualcomm Snapdragon are products of Qualcomm Technologies, Inc. and/or its subsidiaries. Devices • RedMagic 6 • RedMagic 6Pro Chargers • Baseus wall charger (CCGAN100) Controllers* Cypress • CCG3PA-NFET Injoinic-Technology Co Ltd • IP2726S Ismartware • SW2303 Leadtrend • LD6612 Sonix Technology • SNPD1683FJG To learn more visit www.qualcomm.com/quickcharge *Manufacturers may configure power controllers to support Quick Charge 5 with backwards compatibility. Power controllers have been certified by UL and/or Granite River Labs (GRL) to meet compatibility and interoperability requirements. These devices contain the hardware necessary to achieve Quick Charge 5. It is at the device manufacturer’s discretion to fully enable this feature. A Quick Charge 5 certified power adapter is required. Different Quick Charge 5 implementations may result in different charging times. Devices • AGM X3 • Redmi K20 Pro • ASUS ZenFone 6* • Redmi Note 7* • Black Shark 2 • Redmi Note 7 Pro* • BQ Aquaris X2 • Redmi Note 9 Pro • BQ Aquaris X2 Pro • Samsung Galaxy -

Renesas Technology to Release SH7776 (SH-Navi3), Industry’S First Dual-Core Soc with Built-In Image Recognition Processing Function for Car Information Terminals
Renesas Technology to Release SH7776 (SH-Navi3), Industry’s First Dual-Core SoC with Built-in Image Recognition Processing Function for Car Information Terminals ⎯ Achieves excellent performance of 1,920 MIPS and a single-chip solution for next- generation car information systems ⎯ Tokyo, January 19, 2009 — Renesas Technology Corp. today announced the SH7776 (SH-Navi3), a dual-core system-on-chip (SoC) device with on-chip enhanced graphics functions and a high- performance image recognition processing function for the next generation high-performance car information terminals that evolved from car navigation systems. The SH7776 (SH-Navi3) integrates two CPU cores on a single chip and achieves superior processing performance of 1,920 million instructions per second (MIPS), twice that of comparable earlier single-chip SoC products from Renesas Technology. Sample shipments will begin in April 2009 in Japan. Renesas Technology has the top share*1 in the worldwide market for microprocessors for car navigation systems, and the SH-Navi Series,*2 a single-chip SoC device implementing functions essential for high-performance car navigation systems such as 3-D graphics, is already used in many high-end products. Car navigation systems will be evolving into “next-generation car information centers,” which play the central role in car information control to assure convenience, safety, and environmental considerations while driving. The new SH7776 dual-core SoC device delivers on a single chip the performance and functions essential to such a “next-generation car information center.” It enables display of colorful and realistic 3-D graphics use of a multimedia and information communication as well as navigations, display of 2-D/3-D graphics use of a graphical user interface (GUI)*3 for enhanced user-friendliness, and image recognition for functions such as lane detection and preceding vehicle tracking. -

GPU Developments 2017T
GPU Developments 2017 2018 GPU Developments 2017t © Copyright Jon Peddie Research 2018. All rights reserved. Reproduction in whole or in part is prohibited without written permission from Jon Peddie Research. This report is the property of Jon Peddie Research (JPR) and made available to a restricted number of clients only upon these terms and conditions. Agreement not to copy or disclose. This report and all future reports or other materials provided by JPR pursuant to this subscription (collectively, “Reports”) are protected by: (i) federal copyright, pursuant to the Copyright Act of 1976; and (ii) the nondisclosure provisions set forth immediately following. License, exclusive use, and agreement not to disclose. Reports are the trade secret property exclusively of JPR and are made available to a restricted number of clients, for their exclusive use and only upon the following terms and conditions. JPR grants site-wide license to read and utilize the information in the Reports, exclusively to the initial subscriber to the Reports, its subsidiaries, divisions, and employees (collectively, “Subscriber”). The Reports shall, at all times, be treated by Subscriber as proprietary and confidential documents, for internal use only. Subscriber agrees that it will not reproduce for or share any of the material in the Reports (“Material”) with any entity or individual other than Subscriber (“Shared Third Party”) (collectively, “Share” or “Sharing”), without the advance written permission of JPR. Subscriber shall be liable for any breach of this agreement and shall be subject to cancellation of its subscription to Reports. Without limiting this liability, Subscriber shall be liable for any damages suffered by JPR as a result of any Sharing of any Material, without advance written permission of JPR. -

Get Additional ₹ 3000 on Exchange. Kind Offer
Offer Title: Get Additional ₹3000 on Exchange Kind Offer: Exchange price is subject to physical check. Offer Description: Upgrade to the latest Galaxy A72 and get additional ₹3000 on exchange of your old Samsung smartphone device. Offer available on select Samsung devices only and availability of the Offer is subject to area pin codes of customers. Exchange for devices purchased via Samsung.com - Important Information: 1. You can exchange your old select Samsung smartphone device with Galaxy A72. 2. The Exchange Offer is provided to you by Samsung in collaboration with “Manak Waste Management Pvt Ltd., (“Cashify”)” and the evaluation and exchange of your old Samsung smartphone device shall be subject to the terms and conditions of Cashify, for details refer https://www.cashify.in/terms-of-use & https://www.cashify.in/terms-conditions. 3. Exchange can be done on "Samsung Shop". Galaxy A72 Galaxy A72 (8/128 GB) (8/256 GB) ₹ 3000 ₹ 3000 4. Please give correct inputs, with regards to screen condition & availability of accessories, at the time of evaluating your old Smartphone. Any incorrect information provided by you shall result in cancellation/rejection of the Exchange Offer. In such scenario, you shall not be eligible to receive the exchange value and/or any benefit/Offer from Samsung or the exchange partner in lieu of the Exchange Offer or exchange value and no claims shall be entertained in this regard. 5. Exchange Price shown is the Maximum Price subject to physical check at the time of exchange. 6. The screen condition and accessories declared by you will be verified at the time of exchange. -

The Supercomputer in Your Pocket
14 The supercomputer in your pocket Over the past decade, the computing landscape has shifted from beige boxes under desks to a mix of laptops, smartphones, tablets, and hybrid devices. This explosion of mobile CPUs is a profound shift for the semiconductor industry and will have a dramatic impact on its competitive intensity and structure. Harald Bauer, The shift toward mobile computing, at the expense Two major contests will play out for semi- Yetloong Goh, of tethered CPUs, is a major change that has conductor vendors competing in the mobile Joseph Park, raised the competitive metabolism of the semi- arena: the clash between vertical-integration Sebastian Schink, and conductor sector. Mobile, now the central and horizontal-specialization business models, Christopher Thomas battleground of the technology industry, is having and the clash between the two dominant an intense impact on the larger semiconductor architectures and ecosystems, ARM and x86. landscape. Mobile-computing processor require- Each of these battles will be explored in ments now drive the industry, setting design detail below. requirements for transistor structures, process generations, and CPU architecture. It’s the More and more smartphones are as capable as must-win arena for all the semiconductor sector’s the computers of yesteryear. Laptops have top companies. Over the next half decade, leading displaced desktops as the most popular form players will spend hundreds of billions of dollars factor for PCs, and, thanks to the success on R&D. of Apple’s iPad, tablets have stormed into the 15 marketplace. PC original equipment manu- assumes a doubling of processing power every facturers (OEMs) aren’t waiting to lose consumer 18 months, holds the same path for the next few share of wallet to tablets.