Building a Self-Contained Search Engine in the Browser
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HTML5 Websocket Protocol and Its Application to Distributed Computing
CRANFIELD UNIVERSITY Gabriel L. Muller HTML5 WebSocket protocol and its application to distributed computing SCHOOL OF ENGINEERING Computational Software Techniques in Engineering MSc arXiv:1409.3367v1 [cs.DC] 11 Sep 2014 Academic Year: 2013 - 2014 Supervisor: Mark Stillwell September 2014 CRANFIELD UNIVERSITY SCHOOL OF ENGINEERING Computational Software Techniques in Engineering MSc Academic Year: 2013 - 2014 Gabriel L. Muller HTML5 WebSocket protocol and its application to distributed computing Supervisor: Mark Stillwell September 2014 This thesis is submitted in partial fulfilment of the requirements for the degree of Master of Science © Cranfield University, 2014. All rights reserved. No part of this publication may be reproduced without the written permission of the copyright owner. Declaration of Authorship I, Gabriel L. Muller, declare that this thesis titled, HTML5 WebSocket protocol and its application to distributed computing and the work presented in it are my own. I confirm that: This work was done wholly or mainly while in candidature for a research degree at this University. Where any part of this thesis has previously been submitted for a degree or any other qualification at this University or any other institution, this has been clearly stated. Where I have consulted the published work of others, this is always clearly attributed. Where I have quoted from the work of others, the source is always given. With the exception of such quotations, this thesis is entirely my own work. I have acknowledged all main sources of help. Where the thesis is based on work done by myself jointly with others, I have made clear exactly what was done by others and what I have contributed myself. -

Webgl™ Optimizations for Mobile
WebGL™ Optimizations for Mobile Lorenzo Dal Col Senior Software Engineer, ARM 1 Agenda 1. Introduction to WebGL™ on mobile . Rendering Pipeline . Locate the bottleneck 2. Performance analysis and debugging tools for WebGL . Generic optimization tips 3. PlayCanvas experience . WebGL Inspector 4. Use case: PlayCanvas Swooop . ARM® DS-5 Streamline . ARM Mali™ Graphics Debugger 5. Q & A 2 Bring the Power of OpenGL® ES to Mobile Browsers What is WebGL™? Why WebGL? . A cross-platform, royalty free web . It brings plug-in free 3D to the web, standard implemented right into the browser. Low-level 3D graphics API . Major browser vendors are members of . Based on OpenGL® ES 2.0 the WebGL Working Group: . A shader based API using GLSL . Apple (Safari® browser) . Mozilla (Firefox® browser) (OpenGL Shading Language) . Google (Chrome™ browser) . Opera (Opera™ browser) . Some concessions made to JavaScript™ (memory management) 3 Introduction to WebGL™ . How does it fit in a web browser? . You use JavaScript™ to control it. Your JavaScript is embedded in HTML5 and uses its Canvas element to draw on. What do you need to start creating graphics? . Obtain WebGLrenderingContext object for a given HTMLCanvasElement. It creates a drawing buffer into which the API calls are rendered. For example: var canvas = document.getElementById('canvas1'); var gl = canvas.getContext('webgl'); canvas.width = newWidth; canvas.height = newHeight; gl.viewport(0, 0, canvas.width, canvas.height); 4 WebGL™ Stack What is happening when a WebGL page is loaded . User enters URL . HTTP stack requests the HTML page Browser . Additional requests will be necessary to get Space User JavaScript™ code and other resources WebKit JavaScript Engine . -

Framework for Developing Offline HTML5 Applications
MASARYK UNIVERSITY FACULTY}w¡¢£¤¥¦§¨ OF I !"#$%&'()+,-./012345<yA|NFORMATICS Framework for Developing Offline HTML5 Applications DIPLOMA THESIS Petr Kunc Brno, 2013 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Advisor: doc. RNDr. Tomás Pitner, PhD. ii Acknowledgement Above all, I would like to thank my advisor doc. RNDr. Tomáš Pitner, PhD. for leading not only this diploma thesis but also for leading me during my studies. I would also like to thank my colleagues in Laboratory of Software Architectures and Information Systems, especially Mgr. Filip Nguyen and Mgr. Daniel Tovarˇnákfor priceless advice on implementation and for providing their knowledge. Nevertheless, I would like to thank my colleagues in Celebrio Software company. iii Abstract The aim of this thesis is to provide detailed information about developing offline web ap- plications. The thesis presents important technologies in the development and mostly deals with Application cache technology. It summarizes advantages and also disadvantages and problems of the technology. Then, it offers solutions to some of the problems and introduces framework for build- ing offline web applications more sophisticatedly. At last, demonstration application is pre- sented which shows the benefits of proposed technology. iv Keywords HTML5, offline, web applications, application -
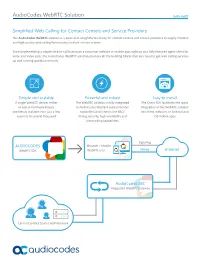
Audiocodes Webrtc Solution DATA SHEET
AudioCodes WebRTC Solution DATA SHEET Simplified Web Calling for Contact Centers and Service Providers The AudioCodes WebRTC solution is a quick and straightforward way for contact centers and service providers to supply intuitive and high-quality web calling functionality to their service centers. From implementing a simple click-to-call button on a consumer website or mobile app, right up to a fully featured agent client for voice and video calls, the AudioCodes WebRTC solution provides all the building blocks that you need to get web calling services up and running quickly and easily. Simple and scalable Powerful and robust Easy to install A single WebRTC device, either The WebRTC solution is fully integrated The Client SDK facilitates the quick virtual or hardware-based, in AudioCodes Mediant session border integration of the WebRTC solution seamlessly scalable from just a few controllers and inherits the SBCs’ into client websites or Android and sessions to several thousand strong security, high availability and iOS mobile apps transcoding capabilities Signaling AUDIOCODES Browser / Mobile WebRTC SDK WebRTC user Media Internet AudioCodes SBC Integrated WebRTC Gateway Carrier/Contact Center VoIP Network AudioCodes WebRTC Solution DATA SHEET Specifications WebRTC Gateway About AudioCodes AudioCodes Ltd. (NasdaqGS: AUDC) is a Deployment leading vendor of advanced voice networking VMWare KVM AWS Mediant 9000 Mediant 4000 method and media processing solutions for the digital workplace. With a commitment to the human 3,000 voice deeply embedded in its DNA, AudioCodes 5,000 WebRTC sessions 2,700 3,500 (20,000 on 1,000 enables enterprises and service providers (20K on roadmap) roadmap) to build and operate all-IP voice networks for unified communications, contact centers 3,000 1,050 integrated and hosted business services. -

A Websocket-Based Approach to Transporting Web Application Data
A WebSocket-based Approach to Transporting Web Application Data March 26, 2015 A thesis submitted to the Division of Graduate Studies and Research of the University of Cincinnati in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in the Department of Computer Science of the College of Engineering and Applied Science by Ross Andrew Hadden B.S., University of Cincinnati, Cincinnati, Ohio (2014) Thesis Adviser and Committee Chair: Dr. Paul Talaga Committee members: Dr. Fred Annexstein, Professor, and Dr. John Franco, Professor Abstract Most web applications serve dynamic data by either deferring an initial page response until the data has been retrieved, or by returning the initial response immediately and loading additional content through AJAX. We investigate another option, which is to return the initial response immediately and send additional content through a WebSocket connection as the data becomes available. We intend to illustrate the performance of this proposition, as compared to popular conventions of both a server- only and an AJAX approach for achieving the same outcome. This dissertation both explains and demonstrates the implementation of the proposed model, and discusses an analysis of the findings. We use a Node.js web application built with the Cornerstone web framework to serve both the content being tested and the endpoints used for data requests. An analysis of the results shows that in situations when minimal data is retrieved after a timeout, the WebSocket method is marginally faster than the server and AJAX methods, and when retrieving populated files or database records it is marginally slower. The WebSocket method considerably outperforms the AJAX method when making multiple requests in series, and when making requests in parallel the WebSocket and server approaches both outperform AJAX by a tremendous amount. -

Webgl: the Standard, the Practice and the Opportunity Web3d Conference August 2012
WebGL: The Standard, the Practice and the Opportunity Web3D Conference August 2012 © Copyright Khronos Group 2012 | Page 1 Agenda and Speakers • 3D on the Web and the Khronos Ecosystem - Neil Trevett, NVIDIA and Khronos Group President • Hands On With WebGL - Ken Russell, Google and WebGL Working Group Chair © Copyright Khronos Group 2012 | Page 2 Khronos Connects Software to Silicon • Khronos APIs define processor acceleration capabilities - Graphics, video, audio, compute, vision and sensor processing APIs developed today define the functionality of platforms and devices tomorrow © Copyright Khronos Group 2012 | Page 3 APIs BY the Industry FOR the Industry • Khronos standards have strong industry momentum - 100s of man years invested by industry leading experts - Shipping on billions of devices and multiple operating systems • Khronos is OPEN for any company to join and participate - Standards are truly open – one company, one vote - Solid legal and Intellectual Property framework for industry cooperation - Khronos membership fees to cover expenses • Khronos APIs define core device acceleration functionality - Low-level “Foundation” functionality needed on every platform - Rigorous conformance tests for cross-vendor consistency • They are FREE - Members agree to not request royalties Silicon Software © Copyright Khronos Group 2012 | Page 4 Apple Over 100 members – any company worldwide is welcome to join Board of Promoters © Copyright Khronos Group 2012 | Page 5 API Standards Evolution WEB INTEROP, VISION MOBILE AND SENSORS DESKTOP OpenVL New API technology first evolves on high- Mobile is the new platform for Apps embrace mobility’s end platforms apps innovation. Mobile unique strengths and need Diverse platforms – mobile, TV, APIs unlock hardware and complex, interoperating APIs embedded – mean HTML5 will conserve battery life with rich sensory inputs become increasingly important e.g. -

Web Technologies VU (706.704)
Web Technologies VU (706.704) Vedran Sabol ISDS, TU Graz Nov 09, 2020 Vedran Sabol (ISDS, TU Graz) Web Technologies Nov 09, 2020 1 / 68 Outline 1 Introduction 2 Drawing in the Browser (SVG, 3D) 3 Audio and Video 4 Javascript APIs 5 JavaScript Changes Vedran Sabol (ISDS, TU Graz) Web Technologies Nov 09, 2020 2 / 68 HTML5 - Part II Web Technologies (706.704) Vedran Sabol ISDS, TU Graz Nov 09, 2020 Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 3 / 68 Drawing in the Browser (SVG, 3D) SVG Scalable Vector Graphics (SVG) Web standard for vector graphics (as opposed to canvas - raster-based) Declarative style (as opposed to canvas rendering - procedural) Developed by W3C (http://www.w3.org/Graphics/SVG/) XML application (SVG DTD) http://www.w3.org/TR/SVG11/svgdtd.html SVG is supported by all current browsers Editors Inkscape and svg-edit (Web App) Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 4 / 68 Drawing in the Browser (SVG, 3D) SVG Features Basic shapes: rectangles, circles, ellipses, path, etc. Painting: filling, stroking, etc. Text Example - simple shapes Grouping of basic shapes Transformation: translation, rotation, scale, skew Example - grouping and transforms Vedran Sabol (ISDS, TU Graz) HTML5 - Part II Nov 09, 2020 5 / 68 Drawing in the Browser (SVG, 3D) SVG Features Colors: true color, transparency, gradients, etc. Clipping, masking Filter effects Interactivity: user events Scripting, i.e. JavaScript, supports DOM Animation: attributes, transforms, colors, motion (along paths) Raster images may be embedded (JPEG, -

The Websockets Package
The websockets Package Bryan W. Lewis [email protected] December 18, 2012 1 Introduction HTML 5 websockets define an efficient socket-like communication protocol for the web. The websockets package is a native websocket implementation for R that supports most of the draft IETF protocols in use today by web browsers. The websockets package is especially well-suited to interaction between R and web scripting languages like Javascript. Multiple simultaneous web- socket server and client connections are supported. The package has few dependencies and is written mostly in R. Packages are available for all major R platforms including GNU/Linux, OS X, and Windows. Websockets are a particularly simple way to expose R to the Web as a service–they let Javascript and other scripts embedded in web pages directly interact with R, bypassing traditional middleware layers like .NET, Java, and web servers normally used for such interaction. In some cases, websockets can be much more efficient than traditional Ajax schemes for interacting with clients over web protocols. Websockets also simplify service scalability in many cases. The websockets package provides three main capabilities: 1. An websocket service. 2. An websocket client. 3. A basic HTTP service. This guide illustrates each capability with simple examples. The websockets Package 2 Running an R websockets server, step by step The websockets package includes a server function that can initiate and respond to websocket and HTTP events over a network connection (websockets are an extension of standard HTTP). All R/Websocket server applications share the following basic recipe: 1. Load the library. 2. Initialize a websocket server with create_server. -

A 3D Collaborative Editor Using Webgl and Webrtc
A 3D collaborative editor using WebGL and WebRTC Caroline Desprat Jean-Pierre Jessel Hervé Luga [email protected] [email protected] [email protected] VORTEX team, IRIT UMR5505, University of Toulouse, France Online collaborative 3D design Objectives Collaborative design environments share 3D scenes • pluginless visualization of 3D scenes on the web, across the network. 3D scenes or models are very • exclusive use of client resources for likely to be constructed and reviewed by more than communication, one person, particularly in the context of 3D sci- • message broadcasting: asynchronous and entific visualization [1], CAD (Computer Aided De- granular, sign) [2] or BIM (Building Information Modeling) • real-time collaboration across the network with [3] solutions with various architectures [4] [5]. shared access to 3D models. Question What architecture is the best suited in online 3D collaborative design environments for small teams using exclusively browser’s ressources? Our hybrid architecture for 3D web-based collaboration Web-based editor P2P communication Client visualization, interaction and edition. WebRTC and DataChannels The 3D interface integrates a viewport and pro- vides: WebRTC (Web Real-Time Protocol) allows Da- P2P connections be- • the list of contributors, taChannel protocol for tween web brow-sers to exchange any raw • basic transformations tools (CRUD), data in real-time[6]. • and viewport informations. WebRTC uses signaling mechanism (via WebSocket server) to manage peers, the network configuration and the media capabilities. Server: RESTful architecture Auto-management of the P2P full mesh network of REST architecture (client/server/NoSQL DB users (designed for small teams). queries) benefits distributed hypermedia systems. PeerJS library bootstraps WebRTC API for compat- ibility reasons. -

3D Graphics Technologies for Web Applications an Evaluation from the Perspective of a Real World Application
Institutionen för systemteknik Department of Electrical Engineering Examensarbete 3D Graphics Technologies for Web Applications An Evaluation from the Perspective of a Real World Application Master thesis performed in information coding by Klara Waern´er LiTH-ISY-EX--12/4562--SE Link¨oping 2012-06-19 Department of Electrical Engineering Linköpings tekniska högskola Linköpings universitet Linköpings universitet SE-581 83 Linköping, Sweden 581 83 Linköping 3D Graphics Technologies for Web Applications An Evaluation from the Perspective of a Real World Application Master thesis in information coding at Link¨oping Institute of Technology by Klara Waern´er LiTH-ISY-EX--12/4562--SE Supervisors: Fredrik Bennet SICK IVP AB Jens Ogniewski ISY, Link¨opingUniversity Examiner: Ingemar Ragnemalm ISY, Link¨opingUniversity Link¨oping2012-06-19 Presentation Date Department and Division 2012-05-31 Department of Electrical Engineering Publishing Date (Electronic version) 2012-06-19 Language Type of Publication ISBN (Licentiate thesis) X English Licentiate thesis ISRN: LiTH-ISY-EX--12/4562--SE Other (specify below) X Degree thesis Thesis C-level Title of series (Licentiate thesis) Thesis D-level Report Number of Pages Other (specify below) Series number/ISSN (Licentiate thesis) 90 URL, Electronic Version http://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-78726 Publication Title 3D Graphics Technologies for Web Applications: An Evaluation from the Perspective of a Real World Application Publication Title (Swedish) Tekniker för 3D-grafik i webbapplikationer: En utvärdering sedd utifrån en riktig applikations perspektiv Author(s) Klara Waernér Abstract Web applications are becoming increasingly sophisticated and functionality that was once exclusive to regular desktop applications can now be found in web applications as well. -

Web-Enabled DDS Version 1.0
Date: July 2016 Web-Enabled DDS Version 1.0 __________________________________________________ OMG Document Number: formal/2016-03-01 Standard document URL: http://www.omg.org/spec/DDS-WEB Machine Consumable File(s): Normative: http://www.omg.org/spec/DDS-WEB/20150901/webdds_rest1.xsd http://www.omg.org/spec/DDS-WEB/20150901/webdds_websockets1.xsd http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1_types.xsd http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1.wsdl http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1_notify.wsdl Non-normative: http://www.omg.org/spec/DDS-WEB/20150901/webdds_rest1_example.xml http://www.omg.org/spec/DDS-WEB/20150901/webdds_pim_model_v1.eap _______________________________________________ Copyright © 2013, eProsima Copyright © 2016, Object Management Group, Inc. (OMG) Copyright © 2013, Real-Time Innovations, Inc. (RTI) Copyright © 2013, THALES USE OF SPECIFICATION - TERMS, CONDITIONS & NOTICES The material in this document details an Object Management Group specification in accordance with the terms, condi- tions and notices set forth below. This document does not represent a commitment to implement any portion of this speci- fication in any company's products. The information contained in this document is subject to change without notice. LICENSES The companies listed above have granted to the Object Management Group, Inc. (OMG) a nonexclusive, royalty-free, paid up, worldwide license to copy and distribute this document and to modify this document and distribute copies of the modified version. Each of the copyright holders listed above has agreed that no person shall be deemed to have infringed the copyright in the included material of any such copyright holder by reason of having used the specification set forth herein or having conformed any computer software to the specification. -

HTML5 Websockets
HHTTMMLL55 -- WWEEBBSSOOCCKKEETTSS http://www.tutorialspoint.com/html5/html5_websocket.htm Copyright © tutorialspoint.com Web Sockets is a next-generation bidirectional communication technology for web applications which operates over a single socket and is exposed via a JavaScript interface in HTML 5 compliant browsers. Once you get a Web Socket connection with the web server, you can send data from browser to server by calling a send method, and receive data from server to browser by an onmessage event handler. Following is the API which creates a new WebSocket object. var Socket = new WebSocket(url, [protocal] ); Here first argument, url, specifies the URL to which to connect. The second attribute, protocol is optional, and if present, specifies a sub-protocol that the server must support for the connection to be successful. WebSocket Attributes Following are the attribute of WebSocket object. Assuming we created Socket object as mentioned above − Attribute Description Socket.readyState The readonly attribute readyState represents the state of the connection. It can have the following values − A value of 0 indicates that the connection has not yet been established. A value of 1 indicates that the connection is established and communication is possible. A value of 2 indicates that the connection is going through the closing handshake. A value of 3 indicates that the connection has been closed or could not be opened. Socket.bufferedAmount The readonly attribute bufferedAmount represents the number of bytes of UTF-8 text that have been queued using send method. WebSocket Events Following are the events associated with WebSocket object. Assuming we created Socket object as mentioned above − Event Event Handler Description open Socket.onopen This event occurs when socket connection is established.