A Websocket-Based Approach to Transporting Web Application Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differential Fuzzing the Webassembly
Master’s Programme in Security and Cloud Computing Differential Fuzzing the WebAssembly Master’s Thesis Gilang Mentari Hamidy MASTER’S THESIS Aalto University - EURECOM MASTER’STHESIS 2020 Differential Fuzzing the WebAssembly Fuzzing Différentiel le WebAssembly Gilang Mentari Hamidy This thesis is a public document and does not contain any confidential information. Cette thèse est un document public et ne contient aucun information confidentielle. Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Antibes, 27 July 2020 Supervisor: Prof. Davide Balzarotti, EURECOM Co-Supervisor: Prof. Jan-Erik Ekberg, Aalto University Copyright © 2020 Gilang Mentari Hamidy Aalto University - School of Science EURECOM Master’s Programme in Security and Cloud Computing Abstract Author Gilang Mentari Hamidy Title Differential Fuzzing the WebAssembly School School of Science Degree programme Master of Science Major Security and Cloud Computing (SECCLO) Code SCI3084 Supervisor Prof. Davide Balzarotti, EURECOM Prof. Jan-Erik Ekberg, Aalto University Level Master’s thesis Date 27 July 2020 Pages 133 Language English Abstract WebAssembly, colloquially known as Wasm, is a specification for an intermediate representation that is suitable for the web environment, particularly in the client-side. It provides a machine abstraction and hardware-agnostic instruction sets, where a high-level programming language can target the compilation to the Wasm instead of specific hardware architecture. The JavaScript engine implements the Wasm specification and recompiles the Wasm instruction to the target machine instruction where the program is executed. Technically, Wasm is similar to a popular virtual machine bytecode, such as Java Virtual Machine (JVM) or Microsoft Intermediate Language (MSIL). -

Dynamic Web Pages with the Embedded Web Server
Dynamic Web Pages With The Embedded Web Server The Digi-Geek’s AJAX Workbook (NET+OS, XML, & JavaScript) Version 1.0 5/4/2011 Page 1 Copyright Digi International, 2011 Table of Contents Chapter 1 - How to Use this Guide ............................................................................................................... 5 Prerequisites – If You Can Ping, You Can Use This Thing! ..................................................................... 5 Getting Help with TCP/IP and Wi-Fi Setup ............................................................................................ 5 The Study Guide or the Short Cut? ....................................................................................................... 5 C Code ................................................................................................................................................... 6 HTML Code ............................................................................................................................................ 6 XML File ................................................................................................................................................. 6 Provide us with Your Feedback ............................................................................................................. 6 Chapter 2 - The Server-Client Relationship ................................................................................................... 7 Example – An Analogy for a Normal HTML page ................................................................................. -

Attacking AJAX Web Applications Vulns 2.0 for Web 2.0
Attacking AJAX Web Applications Vulns 2.0 for Web 2.0 Alex Stamos Zane Lackey [email protected] [email protected] Blackhat Japan October 5, 2006 Information Security Partners, LLC iSECPartners.com Information Security Partners, LLC www.isecpartners.com Agenda • Introduction – Who are we? – Why care about AJAX? • How does AJAX change Web Attacks? • AJAX Background and Technologies • Attacks Against AJAX – Discovery and Method Manipulation – XSS – Cross-Site Request Forgery • Security of Popular Frameworks – Microsoft ATLAS – Google GWT –Java DWR • Q&A 2 Information Security Partners, LLC www.isecpartners.com Introduction • Who are we? – Consultants for iSEC Partners – Application security consultants and researchers – Based in San Francisco • Why listen to this talk? – New technologies are making web app security much more complicated • This is obvious to anybody who reads the paper – MySpace – Yahoo – Worming of XSS – Our Goals for what you should walk away with: • Basic understanding of AJAX and different AJAX technologies • Knowledge of how AJAX changes web attacks • In-depth knowledge on XSS and XSRF in AJAX • An opinion on whether you can trust your AJAX framework to “take care of security” 3 Information Security Partners, LLC www.isecpartners.com Shameless Plug Slide • Special Thanks to: – Scott Stender, Jesse Burns, and Brad Hill of iSEC Partners – Amit Klein and Jeremiah Grossman for doing great work in this area – Rich Cannings at Google • Books by iSECer Himanshu Dwivedi – Securing Storage – Hackers’ Challenge 3 • We are -

HTML5 Websocket Protocol and Its Application to Distributed Computing
CRANFIELD UNIVERSITY Gabriel L. Muller HTML5 WebSocket protocol and its application to distributed computing SCHOOL OF ENGINEERING Computational Software Techniques in Engineering MSc arXiv:1409.3367v1 [cs.DC] 11 Sep 2014 Academic Year: 2013 - 2014 Supervisor: Mark Stillwell September 2014 CRANFIELD UNIVERSITY SCHOOL OF ENGINEERING Computational Software Techniques in Engineering MSc Academic Year: 2013 - 2014 Gabriel L. Muller HTML5 WebSocket protocol and its application to distributed computing Supervisor: Mark Stillwell September 2014 This thesis is submitted in partial fulfilment of the requirements for the degree of Master of Science © Cranfield University, 2014. All rights reserved. No part of this publication may be reproduced without the written permission of the copyright owner. Declaration of Authorship I, Gabriel L. Muller, declare that this thesis titled, HTML5 WebSocket protocol and its application to distributed computing and the work presented in it are my own. I confirm that: This work was done wholly or mainly while in candidature for a research degree at this University. Where any part of this thesis has previously been submitted for a degree or any other qualification at this University or any other institution, this has been clearly stated. Where I have consulted the published work of others, this is always clearly attributed. Where I have quoted from the work of others, the source is always given. With the exception of such quotations, this thesis is entirely my own work. I have acknowledged all main sources of help. Where the thesis is based on work done by myself jointly with others, I have made clear exactly what was done by others and what I have contributed myself. -

Mastering Ajax, Part 4: Exploiting DOM for Web Response Convert HTML Into an Object Model to Make Web Pages Responsive and Interactive
Mastering Ajax, Part 4: Exploiting DOM for Web response Convert HTML into an object model to make Web pages responsive and interactive Skill Level: Introductory Brett McLaughlin Author and Editor O'Reilly Media Inc. 14 Mar 2006 The great divide between programmers (who work with back-end applications) and Web programmers (who spend their time writing HTML, CSS, and JavaScript) is long standing. However, the Document Object Model (DOM) bridges the chasm and makes working with both XML on the back end and HTML on the front end possible and an effective tool. In this article, Brett McLaughlin introduces the Document Object Model, explains its use in Web pages, and starts to explore its usage from JavaScript. Like many Web programmers, you have probably worked with HTML. HTML is how programmers start to work on a Web page; HTML is often the last thing they do as they finish up an application or site, and tweak that last bit of placement, color, or style. And, just as common as using HTML is the misconception about what exactly happens to that HTML once it goes to a browser to render to the screen. Before I dive into what you might think happens -- and why it is probably wrong -- I want you need to be clear on the process involved in designing and serving Web pages: 1. Someone (usually you!) creates HTML in a text editor or IDE. 2. You then upload the HTML to a Web server, like Apache HTTPD, and make it public on the Internet or an intranet. Exploiting DOM for Web response Trademarks © Copyright IBM Corporation 2006 Page 1 of 19 developerWorks® ibm.com/developerWorks 3. -

The Implementation of Large Video File Upload System Based on the HTML5 API and Ajax Yungeng Xu , Sanxing
Joint International Mechanical, Electronic and Information Technology Conference (JIMET 2015) The Implementation of Large Video File Upload System Based on the HTML5 API and Ajax Yungeng Xu1, a, Sanxing Cao2, b 1 Department of Science and Engineering, Communication University of China, Beijing 2 New Media Institute, Communication University of China, Beijing a b [email protected], [email protected] Keywords: HTML5; File upload; Shell; XMLHttpRequest Abstract. The function of upload file is an important web page designs. Traditional file upload function for file upload function by HTML form and $_FILES system function, has the advantages of convenience, can cope with a relatively small file upload. The traditional HTML way has been difficult to meet the upload of the oversized file. Service not only to open a link waiting for this file is uploaded, but also to allocate the same size of memory to save this file. In the case of large concurrency may cause a great pressure on the server. This article is the use of HTML5 File API to upload video files in the original form on the basis of form, use the function of slice inside the HTML5 file API for the split file upload, to achieve the result of no refresh upload files. Have a valid practical significance. Introduction With the development of web technology, watch videos on the website has become an important forms of entertainment in the people's daily life. Internet video give people a great deal of freedom to choose the way of entertainment, not limited to the live TV mode. People can watch the video on the webpage. -

Navigation and Interaction in Urban Environments Using Webgl
NAVIGATION AND INTERACTION IN URBAN ENVIRONMENTS USING WEBGL Mar´ıa Dolores Robles-Ortega, Lidia Ortega, Francisco R. Feito and Manuel J. Gonz´alez Department of Computer Science, University of Ja´en, Paraje Las Lagunillas, s/n 23071 Ja´en, Spain Keywords: WebGL, X3DOM, 3D Urban Scenes, X3D, Web System. Abstract: The process of rendering and interacting with large scenes in web systems is still an open problem in 3D urban environments. In this paper we propose a prototype to visualize a city model in a client-server architecture using open-source technologies like WebGL and X3DOM. Moreover, free navigation around the scene is allowed and users are able to obtain additional information when interacting with buildings and street furniture. To achieve this objective, a MySQL geodatabase has been designed to store both geometric and non-geometric urban information. Therefore, the extra data about the urban elements is obtained through queries in the database. The communication process between MySQL and the X3D model is performed by Ajax. 1 INTRODUCTION model. Evidently, the language used to implement the 3D City Modeling (3DCM) is a research area of great system should fulfill all the requirements described interest with a wide range of applications such as ur- above. Nowadays there are some approaches, like the ban planning, architecture, emergency management, ISO standard language X3D (W3C, 2004) for render- or engineering and construction. The accessibility ing 3D scenes in the Web, but they need the installa- of these tools through the Internet would be a desir- tion of specific plugins. To avoid this drawback, some able option. -

AJAX Xmlhttprequest
AAJJAAXX -- XXMMLLHHTTTTPPRREEQQUUEESSTT http://www.tutorialspoint.com/ajax/what_is_xmlhttprequest.htm Copyright © tutorialspoint.com The XMLHttpRequest object is the key to AJAX. It has been available ever since Internet Explorer 5.5 was released in July 2000, but was not fully discovered until AJAX and Web 2.0 in 2005 became popular. XMLHttpRequest XHR is an API that can be used by JavaScript, JScript, VBScript, and other web browser scripting languages to transfer and manipulate XML data to and from a webserver using HTTP, establishing an independent connection channel between a webpage's Client-Side and Server-Side. The data returned from XMLHttpRequest calls will often be provided by back-end databases. Besides XML, XMLHttpRequest can be used to fetch data in other formats, e.g. JSON or even plain text. You already have seen a couple of examples on how to create an XMLHttpRequest object. Listed below is listed are some of the methods and properties that you have to get familiar with. XMLHttpRequest Methods abort Cancels the current request. getAllResponseHeaders Returns the complete set of HTTP headers as a string. getResponseHeaderheaderName Returns the value of the specified HTTP header. openmethod, URL openmethod, URL, async openmethod, URL, async, userName openmethod, URL, async, userName, password Specifies the method, URL, and other optional attributes of a request. The method parameter can have a value of "GET", "POST", or "HEAD". Other HTTP methods, such as "PUT" and "DELETE" primarilyusedinRESTapplications may be possible. The "async" parameter specifies whether the request should be handled asynchronously or not. "true" means that the script processing carries on after the send method without waiting for a response, and "false" means that the script waits for a response before continuing script processing. -
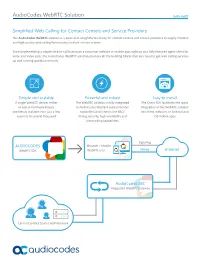
Audiocodes Webrtc Solution DATA SHEET
AudioCodes WebRTC Solution DATA SHEET Simplified Web Calling for Contact Centers and Service Providers The AudioCodes WebRTC solution is a quick and straightforward way for contact centers and service providers to supply intuitive and high-quality web calling functionality to their service centers. From implementing a simple click-to-call button on a consumer website or mobile app, right up to a fully featured agent client for voice and video calls, the AudioCodes WebRTC solution provides all the building blocks that you need to get web calling services up and running quickly and easily. Simple and scalable Powerful and robust Easy to install A single WebRTC device, either The WebRTC solution is fully integrated The Client SDK facilitates the quick virtual or hardware-based, in AudioCodes Mediant session border integration of the WebRTC solution seamlessly scalable from just a few controllers and inherits the SBCs’ into client websites or Android and sessions to several thousand strong security, high availability and iOS mobile apps transcoding capabilities Signaling AUDIOCODES Browser / Mobile WebRTC SDK WebRTC user Media Internet AudioCodes SBC Integrated WebRTC Gateway Carrier/Contact Center VoIP Network AudioCodes WebRTC Solution DATA SHEET Specifications WebRTC Gateway About AudioCodes AudioCodes Ltd. (NasdaqGS: AUDC) is a Deployment leading vendor of advanced voice networking VMWare KVM AWS Mediant 9000 Mediant 4000 method and media processing solutions for the digital workplace. With a commitment to the human 3,000 voice deeply embedded in its DNA, AudioCodes 5,000 WebRTC sessions 2,700 3,500 (20,000 on 1,000 enables enterprises and service providers (20K on roadmap) roadmap) to build and operate all-IP voice networks for unified communications, contact centers 3,000 1,050 integrated and hosted business services. -

The Use of Scalable Vector Graphics in Flexible, Thin-Client Architectures for Tv Navigation
THE USE OF SCALABLE VECTOR GRAPHICS IN FLEXIBLE, THIN-CLIENT ARCHITECTURES FOR TV NAVIGATION Michael Adams Solution Area TV, Ericsson Abstract Support rapid development of new applications without the need for new Today’s subscribers are demanding more software download to the set-top and more from their service providers: Enable personalization of a service to each subscriber’s preferences Personalization: New behaviors from a Allow full customization of the user- new generation of “digital natives”, (who interface, including branding expect the service to adapt to them!), Allow the use of third-party developers, powerful search capabilities, and using Web 2.0 service creation methods recommendations engines. Provide set-top independence and Communication: Multitasking, social multiplatform portability networking, and sharing the viewing Decouple CA/DRM certification from new experience through chat and instant features and applications development messaging Interactivity: Polls, games, and enhanced INTRODUCTION programming Today’s subscribers are demanding more And subscribers want all the above and more from their service providers. What services and features to be delivered as a they want can be grouped into three main single, integrated service experience across categories: any device, anywhere, and at anytime! Personalization The Internet has shown how to deliver all Communication kinds of services by means of thin-client Interactivity approaches using the Representational State Transfer (REST) model. Meanwhile, most Personalization deployed cable architectures still rely on a “state-full”, thick-client approach. I want my service to adapt to my needs. I need recommendations to sort my Can thin-client architectures really “wheat” from the “chaff”. satisfy large cable system requirements for I want to watch anything, on any device, performance, scalability, high-availability, at any time, anywhere. -

Making Phone Calls from Blazor Webassembly with Twilio Voice
© Niels Swimberghe https://swimburger.net - @RealSwimburger 1 About me • Niels Swimberghe aka Swimburger • Grew up in Belgium, working in USA • .NET Developer / Tech Content Creator • Blog at swimbuger.net • Twitter: @RealSwimburger • Company: 2 Programmatic communication using HTTP Webhooks Example TwiML Sample: https://demo.twilio.com/welcome/voice/ Based on in-depth guide on Twilio Blog Check out guide at Twilio Blog Application • Out of the box Blazor WebAssembly application • Phone dialer • Initiate phone calls from browser • Receive phone calls in browser Recommended architecture Demo architecture Demo architecture Auth flow 1. Ajax HTTP Request JWT token 2. Server generates JWT token and sends token in HTTP response 3. Twilio JavaScript SDK establishes bidirectional connection with Twilio over WebSocket Incoming call flow 1. Phone calls Twilio Phone Number 2. Twilio sends HTTP request to your webhook asking for instructions 3. Webhook responds with TwiML instructions Incoming call flow Webhook responds with TwiML instructions Incoming call flow 4. Twilio dials client 5. Client accepts incoming connection => VoIP established Outgoing call flow 1. Client connects to Twilio with To parameter 2. Twilio sends HTTP request to your webhook asking for instructions 3. Webhook responds with TwiML instructions Outgoing call flow Webhook responds with TwiML instructions Outgoing call flow 4. Twilio dials phone number 5. Phone accepts incoming connection => VoIP established Let’s see how its built Step 1: Create Twilio resources • You need to -

The Websockets Package
The websockets Package Bryan W. Lewis [email protected] December 18, 2012 1 Introduction HTML 5 websockets define an efficient socket-like communication protocol for the web. The websockets package is a native websocket implementation for R that supports most of the draft IETF protocols in use today by web browsers. The websockets package is especially well-suited to interaction between R and web scripting languages like Javascript. Multiple simultaneous web- socket server and client connections are supported. The package has few dependencies and is written mostly in R. Packages are available for all major R platforms including GNU/Linux, OS X, and Windows. Websockets are a particularly simple way to expose R to the Web as a service–they let Javascript and other scripts embedded in web pages directly interact with R, bypassing traditional middleware layers like .NET, Java, and web servers normally used for such interaction. In some cases, websockets can be much more efficient than traditional Ajax schemes for interacting with clients over web protocols. Websockets also simplify service scalability in many cases. The websockets package provides three main capabilities: 1. An websocket service. 2. An websocket client. 3. A basic HTTP service. This guide illustrates each capability with simple examples. The websockets Package 2 Running an R websockets server, step by step The websockets package includes a server function that can initiate and respond to websocket and HTTP events over a network connection (websockets are an extension of standard HTTP). All R/Websocket server applications share the following basic recipe: 1. Load the library. 2. Initialize a websocket server with create_server.