HTML5 Websocket Protocol and Its Application to Distributed Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AJAX Requests CPEN400A - Building Modern Web Applications - Winter 2018-1
What is AJAX XmlHttpRequest Callbacks and Error Handling JSON Lecture 6: AJAX Requests CPEN400A - Building Modern Web Applications - Winter 2018-1 Karthik Pattabiraman The Univerity of British Columbia Department of Electrical and Computer Engineering Vancouver, Canada Thursday, October 17, 2019 What is AJAX XmlHttpRequest Callbacks and Error Handling JSON What is AJAX ? 2 1 What is AJAX 2 XmlHttpRequest 3 Callbacks and Error Handling 4 JSON What is AJAX XmlHttpRequest Callbacks and Error Handling JSON What is AJAX ? 3 Mechanism for modern web applications to communicate with the server after page load Without refreshing the current page Request can be sent asynchronously without holding up the main JavaScript thread Stands for “Asynchronous JavaScript and XML”, but does not necessarily involve XML Complement of COMET (Server Push) What is AJAX XmlHttpRequest Callbacks and Error Handling JSON A Brief History of AJAX 4 Introduced by Microsoft as part of the Outlook Web Access (OWA) in 1998 Popularized by Google in Gmail, Maps in 2004-05 Term AJAX coined around 2005 in an article Made part of the W3C standard in 2006 Supported by all major browsers today What is AJAX XmlHttpRequest Callbacks and Error Handling JSON Uses of AJAX 5 Interactivity To enable content to be brought in from the server in response to user requests Performance Load the most critical portions of a webpage first, and then load the rest asynchronously Security (this is questionable) Bring in only the code/data that is needed on demand to reduce the attack surface of the -

USER GUIDE IE-SNC-P86xx-07
COMET SYSTEM www.cometsystem.com Web Sensor P8610 with PoE Web Sensor P8611 with PoE Web Sensor P8641 with PoE USER GUIDE IE-SNC-P86xx-07 © Copyright: COMET System, s.r.o. Is prohibited to copy and make any changes in this manual, without explicit agreement of company COMET System, s.r.o. All rights reserved. COMET System, s.r.o. makes constant development and improvement of their products. Manufacturer reserves the right to make technical changes to the device without previous notice. Misprints reserved. Manufacturer is not responsible for damages caused by using the device in conflict with this manual. To damages caused by using the device in conflict with this manual cannot be provide free repairs during the warranty period. Revision history This manual describes devices with latest firmware version according the table below. Older version of manual can be obtained from a technical support. This manual is also applicable to discontinued device P8631. Document version Date of issue Firmware version Note IE-SNC-P86xx-01 2011-06-13 4-5-1-22 Latest revision of manual for an old generation of firmware for P86xx devices. IE-SNC-P86xx-04 2014-02-20 4-5-5-x Initial revision of manual for new generation of 4-5-6-0 P86xx firmware. IE-SNC-P86xx-05 2015-03-13 4-5-7-0 IE-SNC-P86xx-06 2015-09-25 4-5-8-0 IE-SNC-P86xx-07 2017-10-26 4-5-8-1 2 IE-SNC-P86xx-07 Table of contents Introduction ........................................................................................................................................................ 4 General safety rules ..................................................................................................................................... 4 Device description and important notices .............................................................................................. -

An Overview December 2012
An Overview December 2012 PUSH TECHNOLOGY LIMITED Telephone: +44 (0)20 3588 0900 3RD FLOOR HOLLAND HOUSE Email: [email protected] 1-4 BURY STREET LONDON EC3A 5AW www.pushtechnology.com ©Copyright Push Technology Ltd December 2012 Contents Introduction 3 Diff usionTM Technology 3 Development experience 4 Publishers 4 Scalability Message queues 4 Distribution 5 Performance 5 Management 5 Support and Training 6 Diff erentiators 6 Data quality of service Benefi ts 7 Inteligent data management 2 ©Copyright Push Technology Ltd December 2012 Introduction Push’s fl agship product, Diff usionTM, provides a Diff usionTM Technology one stop, end-to-end solution for delivering real- At the heart of Diff usionTM is the Diff usionTM server - a time data services to “edge” facing Internet and 100% Java, high performance message broker and data mobile clients. distribution engine with support for multiple protocols Diff usionTM provides all of the components required to including Push Technology’s own high-speed, protocol deliver a scalable, high performance solution across DPT as well as standards Comet and WebSockets. Native a broad range of client technologies; including a high client connectivity is supported on a wide-range of throughput, low latency message broker; scalable, cross- platforms, from JavaScript to Java, Flash/ActionScript to platform connection infrastructure and intelligent traffi c Android and .NET to iOS/Objective-C – the Diff usionTM management and shaping. client SDKs cover all of the popular mobile and browser- based client technology choices in use today. Diff usionTM provides signifi cant benefi ts to customers: • Stream real-time, dynamic content over the Transports Internet to any device. -
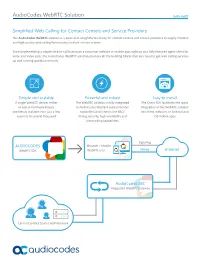
Audiocodes Webrtc Solution DATA SHEET
AudioCodes WebRTC Solution DATA SHEET Simplified Web Calling for Contact Centers and Service Providers The AudioCodes WebRTC solution is a quick and straightforward way for contact centers and service providers to supply intuitive and high-quality web calling functionality to their service centers. From implementing a simple click-to-call button on a consumer website or mobile app, right up to a fully featured agent client for voice and video calls, the AudioCodes WebRTC solution provides all the building blocks that you need to get web calling services up and running quickly and easily. Simple and scalable Powerful and robust Easy to install A single WebRTC device, either The WebRTC solution is fully integrated The Client SDK facilitates the quick virtual or hardware-based, in AudioCodes Mediant session border integration of the WebRTC solution seamlessly scalable from just a few controllers and inherits the SBCs’ into client websites or Android and sessions to several thousand strong security, high availability and iOS mobile apps transcoding capabilities Signaling AUDIOCODES Browser / Mobile WebRTC SDK WebRTC user Media Internet AudioCodes SBC Integrated WebRTC Gateway Carrier/Contact Center VoIP Network AudioCodes WebRTC Solution DATA SHEET Specifications WebRTC Gateway About AudioCodes AudioCodes Ltd. (NasdaqGS: AUDC) is a Deployment leading vendor of advanced voice networking VMWare KVM AWS Mediant 9000 Mediant 4000 method and media processing solutions for the digital workplace. With a commitment to the human 3,000 voice deeply embedded in its DNA, AudioCodes 5,000 WebRTC sessions 2,700 3,500 (20,000 on 1,000 enables enterprises and service providers (20K on roadmap) roadmap) to build and operate all-IP voice networks for unified communications, contact centers 3,000 1,050 integrated and hosted business services. -

A Websocket-Based Approach to Transporting Web Application Data
A WebSocket-based Approach to Transporting Web Application Data March 26, 2015 A thesis submitted to the Division of Graduate Studies and Research of the University of Cincinnati in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in the Department of Computer Science of the College of Engineering and Applied Science by Ross Andrew Hadden B.S., University of Cincinnati, Cincinnati, Ohio (2014) Thesis Adviser and Committee Chair: Dr. Paul Talaga Committee members: Dr. Fred Annexstein, Professor, and Dr. John Franco, Professor Abstract Most web applications serve dynamic data by either deferring an initial page response until the data has been retrieved, or by returning the initial response immediately and loading additional content through AJAX. We investigate another option, which is to return the initial response immediately and send additional content through a WebSocket connection as the data becomes available. We intend to illustrate the performance of this proposition, as compared to popular conventions of both a server- only and an AJAX approach for achieving the same outcome. This dissertation both explains and demonstrates the implementation of the proposed model, and discusses an analysis of the findings. We use a Node.js web application built with the Cornerstone web framework to serve both the content being tested and the endpoints used for data requests. An analysis of the results shows that in situations when minimal data is retrieved after a timeout, the WebSocket method is marginally faster than the server and AJAX methods, and when retrieving populated files or database records it is marginally slower. The WebSocket method considerably outperforms the AJAX method when making multiple requests in series, and when making requests in parallel the WebSocket and server approaches both outperform AJAX by a tremendous amount. -

Research of Web Real-Time Communication Based on Web Socket
Int. J. Communications, Network and System Sciences, 2012, 5, 797-801 http://dx.doi.org/10.4236/ijcns.2012.512083 Published Online December 2012 (http://www.SciRP.org/journal/ijcns) Research of Web Real-Time Communication Based on Web Socket Qigang Liu, Xiangyang Sun Sydney Institute of Language & Commerce, Shanghai University, Shanghai, China Email: [email protected] Received September 4, 2012; revised October 15, 2012; accepted October 26, 2012 ABSTRACT Regarding the limitations of traditional web real-time communication solutions such as polling, long-polling, flash plug-in, propose that using new coming Web Socket technology in the web real-time communication field, introduce the features of Web Socket technology, analysis the difference between Web Socket protocol and HTTP protocol, offer an approach to implement the Web Socket both in client and server side, prove Web Socket can decrease network traf- fic and latency greatly by an experiment, made the prospect of future application of Web Socket in web real-time com- munication. Keywords: Web Socket; Full-Duplex; HTTP Streaming; Long-Polling; Latency 1. Introduction mary solutions used by Web developers to accomplish the real-time communication between browser and server The Internet has been an indispensable part of people’s in the past. life in the fast growing information age. People’s re- Polling an approach manually refreshing page is re- quirements for the Internet have changed from informa- placed by auto running program is the earliest solution tion accessibility in the Web 1.0 era to information in- for real-time communication applied in browser. Easy teraction in the Web 2.0 era, and to current instant inter- implementation and no additional requirement for client action observed in an increasing number of pricing sys- and server are the big advantage of this solution. -

The Websockets Package
The websockets Package Bryan W. Lewis [email protected] December 18, 2012 1 Introduction HTML 5 websockets define an efficient socket-like communication protocol for the web. The websockets package is a native websocket implementation for R that supports most of the draft IETF protocols in use today by web browsers. The websockets package is especially well-suited to interaction between R and web scripting languages like Javascript. Multiple simultaneous web- socket server and client connections are supported. The package has few dependencies and is written mostly in R. Packages are available for all major R platforms including GNU/Linux, OS X, and Windows. Websockets are a particularly simple way to expose R to the Web as a service–they let Javascript and other scripts embedded in web pages directly interact with R, bypassing traditional middleware layers like .NET, Java, and web servers normally used for such interaction. In some cases, websockets can be much more efficient than traditional Ajax schemes for interacting with clients over web protocols. Websockets also simplify service scalability in many cases. The websockets package provides three main capabilities: 1. An websocket service. 2. An websocket client. 3. A basic HTTP service. This guide illustrates each capability with simple examples. The websockets Package 2 Running an R websockets server, step by step The websockets package includes a server function that can initiate and respond to websocket and HTTP events over a network connection (websockets are an extension of standard HTTP). All R/Websocket server applications share the following basic recipe: 1. Load the library. 2. Initialize a websocket server with create_server. -

Web-Enabled DDS Version 1.0
Date: July 2016 Web-Enabled DDS Version 1.0 __________________________________________________ OMG Document Number: formal/2016-03-01 Standard document URL: http://www.omg.org/spec/DDS-WEB Machine Consumable File(s): Normative: http://www.omg.org/spec/DDS-WEB/20150901/webdds_rest1.xsd http://www.omg.org/spec/DDS-WEB/20150901/webdds_websockets1.xsd http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1_types.xsd http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1.wsdl http://www.omg.org/spec/DDS-WEB/20131122/webdds_soap1_notify.wsdl Non-normative: http://www.omg.org/spec/DDS-WEB/20150901/webdds_rest1_example.xml http://www.omg.org/spec/DDS-WEB/20150901/webdds_pim_model_v1.eap _______________________________________________ Copyright © 2013, eProsima Copyright © 2016, Object Management Group, Inc. (OMG) Copyright © 2013, Real-Time Innovations, Inc. (RTI) Copyright © 2013, THALES USE OF SPECIFICATION - TERMS, CONDITIONS & NOTICES The material in this document details an Object Management Group specification in accordance with the terms, condi- tions and notices set forth below. This document does not represent a commitment to implement any portion of this speci- fication in any company's products. The information contained in this document is subject to change without notice. LICENSES The companies listed above have granted to the Object Management Group, Inc. (OMG) a nonexclusive, royalty-free, paid up, worldwide license to copy and distribute this document and to modify this document and distribute copies of the modified version. Each of the copyright holders listed above has agreed that no person shall be deemed to have infringed the copyright in the included material of any such copyright holder by reason of having used the specification set forth herein or having conformed any computer software to the specification. -

HTML5 Websockets
HHTTMMLL55 -- WWEEBBSSOOCCKKEETTSS http://www.tutorialspoint.com/html5/html5_websocket.htm Copyright © tutorialspoint.com Web Sockets is a next-generation bidirectional communication technology for web applications which operates over a single socket and is exposed via a JavaScript interface in HTML 5 compliant browsers. Once you get a Web Socket connection with the web server, you can send data from browser to server by calling a send method, and receive data from server to browser by an onmessage event handler. Following is the API which creates a new WebSocket object. var Socket = new WebSocket(url, [protocal] ); Here first argument, url, specifies the URL to which to connect. The second attribute, protocol is optional, and if present, specifies a sub-protocol that the server must support for the connection to be successful. WebSocket Attributes Following are the attribute of WebSocket object. Assuming we created Socket object as mentioned above − Attribute Description Socket.readyState The readonly attribute readyState represents the state of the connection. It can have the following values − A value of 0 indicates that the connection has not yet been established. A value of 1 indicates that the connection is established and communication is possible. A value of 2 indicates that the connection is going through the closing handshake. A value of 3 indicates that the connection has been closed or could not be opened. Socket.bufferedAmount The readonly attribute bufferedAmount represents the number of bytes of UTF-8 text that have been queued using send method. WebSocket Events Following are the events associated with WebSocket object. Assuming we created Socket object as mentioned above − Event Event Handler Description open Socket.onopen This event occurs when socket connection is established. -

HTML5 and Java Technologies
HTML5 and Java Technologies Peter Doschkinow Senior Java Architect The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. Agenda . Motivation . HTML5 Overview – Related Java Technologies . Thin Server Architecture . Demo Motivation . Need for clarification Gartner’s 2012 Emerging Technologies Hype Cycle – What is behind the hype . Architectural consequences of new trends . What does the Java platform offer to meet the new challenges . Building of common understanding Web Technology History . 1991 HTML . 1995 JavaScript @ Netscape . 1994 HTML2 . 1996 ECMAScript 1.0, 1.1 . 1996 CSS1 . 1997 ECMAScript 1.2 . 1997 HTML4 . 1998 ECMAScript 1.3 . 1998 CSS2 . 2000 ECMAScript 3 . 2000 XHTML1 . 2010 ECMAScript 5 . 2002 Tableless Web Design . Next: ECMAScript 6 Harmony . 2005 AJAX . 2009 HTML5: as of Dec 2012 W3C CR HTML5 Features W3C / Web Hypertext Application Technology Working Group(WHATWG) . Markup – Semantic markup replacing common usages of generic <span>, <div> . <nav>, <footer>,<audio>, <video>, ... API – Canvas 2D (for immidate mode 2D drawing),Timed media playback – Offline Web Applications, Local Srorage and Filesystem, Web Storage – Geolocation, Web Storage, IndexedDB – File API, Drag-and-Drop, Browser History – ... HTML5 Features Offloaded to other specs, originally part of HTML5 . WebSocket API, Server-Sent Events(SSE), Web Messaging, Web Workers, Web Storage (Web Apps WG ) . -

Towards Web-Based Delta Synchronization for Cloud Storage Services
Towards Web-based Delta Synchronization for Cloud Storage Services He Xiao and Zhenhua Li, Tsinghua University; Ennan Zhai, Yale University; Tianyin Xu, UIUC; Yang Li and Yunhao Liu, Tsinghua University; Quanlu Zhang, Microsoft Research; Yao Liu, SUNY Binghamton https://www.usenix.org/conference/fast18/presentation/xiao This paper is included in the Proceedings of the 16th USENIX Conference on File and Storage Technologies. February 12–15, 2018 • Oakland, CA, USA ISBN 978-1-931971-42-3 Open access to the Proceedings of the 16th USENIX Conference on File and Storage Technologies is sponsored by USENIX. Towards Web-based Delta Synchronization for Cloud Storage Services He Xiao Zhenhua Li ∗ Ennan Zhai Tianyin Xu Tsinghua University Tsinghua University Yale University UIUC Yang Li Yunhao Liu Quanlu Zhang Yao Liu Tsinghua University Tsinghua University Microsoft Research SUNY Binghamton Abstract savings in the presence of users’ file edits [29, 39, 40]. Delta synchronization (sync) is crucial for network-level Unfortunately, today delta sync is only available for efficiency of cloud storage services. Practical delta sync PC clients and mobile apps, but not for the web—the most pervasive and OS-independent access method [37]. techniques are, however, only available for PC clients 0 and mobile apps, but not web browsers—the most per- After a file f is edited into a new version f by users, vasive and OS-independent access method. To under- Dropbox’s PC client will apply delta sync to automati- stand the obstacles of web-based delta sync, we imple- cally upload only the altered bits to the cloud; in contrast, Dropbox’s web interface requires users to manually up- ment a delta sync solution, WebRsync, using state-of- 0 1 the-art web techniques based on rsync, the de facto delta load the entire content of f to the cloud. -

USER GUIDE IE-SNC-Tx6xx-06
COMET SYSTEM www.cometsystem.com Web Sensor T0610 with PoE Web Sensor T4611 with PoE Web Sensor T3610 with PoE Web Sensor T3611 with PoE Web Sensor T7610 with PoE Web Sensor T7611 with PoE Web Sensor T7613D with PoE Web Sensor T6640 with PoE Web Sensor T6641 with PoE Web Sensor T5640 with PoE Web Sensor T5641 with PoE USER GUIDE IE-SNC-Tx6xx-06 © Copyright: COMET System, s.r.o. Is prohibited to copy and make any changes in this manual, without explicit agreement of company COMET System, s.r.o. All rights reserved. COMET System, s.r.o. makes constant development and improvement of all its products. Manufacturer reserves the right to make technical changes without previous notice. Misprints reserved. Manufacturer is not responsible for damages caused by using the device in conflict with this manual. To damages caused by using the device in conflict with this manual cannot be provided free repairs during the warranty period. Revision history This manual describes devices with latest firmware version according the table below. Older version of manual can be obtained from a technical support. Document version Date of issue Firmware version Note IE-SNC-Tx6xx-01 2013-04-29 1-5-5-x Initial revision of manual 1-5-6-0 IE-SNC-Tx6xx-02 2013-12-03 1-5-7-0 1-5-7-1 IE-SNC-Tx6xx-04 2017-02-20 1-5-7-2 1-5-7-3 IE-SNC-Tx6xx-05 2017-09-29 1-5-7-4 IE-SNC-Tx6xx-06 2017-12-18 1-5-7-5 New devices T6640, T6641, T5640, T5641 2 IE-SNC-Tx6xx-06 Table of contents Introduction .......................................................................................................................................................