Gov 1005: Data David Kane Fall 2018: M/W 1:30 – 2:45
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Advanced R Second Edition Chapman & Hall/CRC the R Series Series Editors John M
Advanced R Second Edition Chapman & Hall/CRC The R Series Series Editors John M. Chambers, Department of Statistics, Stanford University, California, USA Torsten Hothorn, Division of Biostatistics, University of Zurich, Switzerland Duncan Temple Lang, Department of Statistics, University of California, Davis, USA Hadley Wickham, RStudio, Boston, Massachusetts, USA Recently Published Titles Testing R Code Richard Cotton R Primer, Second Edition Claus Thorn Ekstrøm Flexible Regression and Smoothing: Using GAMLSS in R Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda De Bastiani The Essentials of Data Science: Knowledge Discovery Using R Graham J. Williams blogdown: Creating Websites with R Markdown Yihui Xie, Alison Presmanes Hill, Amber Thomas Handbook of Educational Measurement and Psychometrics Using R Christopher D. Desjardins, Okan Bulut Displaying Time Series, Spatial, and Space-Time Data with R, Second Edition Oscar Perpinan Lamigueiro Reproducible Finance with R Jonathan K. Regenstein, Jr. R Markdown The Definitive Guide Yihui Xie, J.J. Allaire, Garrett Grolemund Practical R for Mass Communication and Journalism Sharon Machlis Analyzing Baseball Data with R, Second Edition Max Marchi, Jim Albert, Benjamin S. Baumer Spatio-Temporal Statistics with R Christopher K. Wikle, Andrew Zammit-Mangion, and Noel Cressie Statistical Computing with R, Second Edition Maria L. Rizzo Geocomputation with R Robin Lovelace, Jakub Nowosad, Jannes Münchow Dose-Response Analysis with R Christian Ritz, Signe M. Jensen, Daniel Gerhard, Jens C. Streibig Advanced R, Second Edition Hadley Wickham For more information about this series, please visit: https://www.crcpress.com/go/ the-r-series Advanced R Second Edition Hadley Wickham CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 2019 by Taylor & Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. -

Navigating the R Package Universe by Julia Silge, John C
CONTRIBUTED RESEARCH ARTICLES 558 Navigating the R Package Universe by Julia Silge, John C. Nash, and Spencer Graves Abstract Today, the enormous number of contributed packages available to R users outstrips any given user’s ability to understand how these packages work, their relative merits, or how they are related to each other. We organized a plenary session at useR!2017 in Brussels for the R community to think through these issues and ways forward. This session considered three key points of discussion. Users can navigate the universe of R packages with (1) capabilities for directly searching for R packages, (2) guidance for which packages to use, e.g., from CRAN Task Views and other sources, and (3) access to common interfaces for alternative approaches to essentially the same problem. Introduction As of our writing, there are over 13,000 packages on CRAN. R users must approach this abundance of packages with effective strategies to find what they need and choose which packages to invest time in learning how to use. At useR!2017 in Brussels, we organized a plenary session on this issue, with three themes: search, guidance, and unification. Here, we summarize these important themes, the discussion in our community both at useR!2017 and in the intervening months, and where we can go from here. Users need options to search R packages, perhaps the content of DESCRIPTION files, documenta- tion files, or other components of R packages. One author (SG) has worked on the issue of searching for R functions from within R itself in the sos package (Graves et al., 2017). -

Downloaded from Ensembl V41 (6), All
IN SILICO APPROACHES TO INVESTIGATING MECHANISMS OF GENE REGULATION by SHANNAN JANELLE HO SUI B.Sc., The University of British Columbia, 2000 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY in THE FACULTY OF GRADUATE STUDIES (Genetics) THE UNIVERSITY OF BRITISH COLUMBIA (Vancouver) March 2008 © Shannan Janelle Ho Sui, 2008 Abstract Identification and characterization of regions influencing the precise spatial and temporal expression of genes is critical to our understanding of gene regulatory networks. Connecting transcription factors to the cis-regulatory elements that they bind and regulate remains a challenging problem in computational biology. The rapid accumulation of whole genome sequences and genome-wide expression data, and advances in alignment algorithms and motif-finding methods, provide opportunities to tackle the important task of dissecting how genes are regulated. Genes exhibiting similar expression profiles are often regulated by common transcription factors. We developed a method for identifying statistically over- represented regulatory motifs in the promoters of co-expressed genes using weight matrix models representing the specificity of known factors. Application of our methods to yeast fermenting in grape must revealed elements that play important roles in utilizing carbon sources. Extension of the method to metazoan genomes via incorporation of comparative sequence analysis facilitated identification of functionally relevant binding sites for sets of tissue-specific genes, and for genes showing similar expression in large-scale expression profiling studies. Further extensions address alternative promoters for human genes and coordinated binding of multiple transcription factors to cis-regulatory modules. Sequence conservation reveals segments of genes of potential interest, but the degree of sequence divergence among human genes and their orthologous sequences varies widely. -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

BUSMGT 7331: Descriptive Analytics and Visualization
BUSMGT 7331: Descriptive Analytics and Visualization Spring 2019, Term 1 January 7, 2019 Instructor: Hyunwoo Park (https://fisher.osu.edu/people/park.2706) Office: Fisher Hall 632 Email: [email protected] Phone: 614-292-3166 Class Schedule: 8:30am-12:pm Saturday 1/19, 2/2, 2/16 Recitation/Office Hours: Thursdays 6:30pm-8pm at Gerlach 203 (also via WebEx) 1 Course Description Businesses and organizations today collect and store unprecedented quantities of data. In order to make informed decisions with such a massive amount of the accumulated data, organizations seek to adopt and utilize data mining and machine learning techniques. Applying advanced techniques must be preceded by a careful examination of the raw data. This step becomes increasingly important and also easily overlooked as the amount of data increases because human examination is prone to fail without adequate tools to describe a large dataset. Another growing challenge is to communicate a large dataset and complicated models with human decision makers. Descriptive analytics, and visualizations in particular, helps find patterns in the data and communicate the insights in an effective manner. This course aims to equip students with methods and techniques to summarize and communicate the underlying patterns of different types of data. This course serves as a stepping stone for further predictive and prescriptive analytics. 2 Course Learning Outcomes By the end of this course, students should successfully be able to: • Identify various distributions that frequently occur in observational data. • Compute key descriptive statistics from data. • Measure and interpret relationships among variables. • Transform unstructured data such as texts into structured format. -

Data Analysis in R
Data Analysis in R Course at a Glance This course will provide an introduction to reproducible data analysis with R (see Syllabus). Instructor Gabriel Baud-Bovy ([email protected] ) Credits: 5 Synopsis This course aims at giving to the student a methodology to analyze experimental results, from how to organize data to the writing of a report. It includes: an introduction to R an introduction to reproducible research with R examples of statistical analysis with R During this course, the student will have to analyze his own data and is expected to read before each course the material that will be made available on this page. The final grade will consist in the evaluation of a report demonstrating familiarity with the concepts and methods presented in the course. As an editor, the instructor will use Notepad++ (together with NppToR) on a Windows Machines but the student might use other ones (e.g., R studio, EMACS+ESS, Lyx, TexWork). The course will use Mardown as typesetting language. For those desirous to work with Latex and/or generate pdf, you will need to install also MikeTex. Syllabus Total of 15 hours Class 1: Case study, Reproducible research Class 2: R fundamental Class 3: Exploratory data analysis and graphical methods in R Class 4: Basic statistics Class 5: To be determined There will be a final examination decided by the instructor. Prerequisites The course assumes some familiarity with programming concepts and data structures (MATLAB, C/C++, Java or any other programming language). Contact the instructor if you have never programmed anything. -

Introduction to Data Science for Transportation Researchers, Planners, and Engineers
Portland State University PDXScholar Transportation Research and Education Center TREC Final Reports (TREC) 1-2017 Introduction to Data Science for Transportation Researchers, Planners, and Engineers Liming Wang Portland State University Follow this and additional works at: https://pdxscholar.library.pdx.edu/trec_reports Part of the Transportation Commons, Urban Studies Commons, and the Urban Studies and Planning Commons Let us know how access to this document benefits ou.y Recommended Citation Wang, Liming. Introduction to Data Science for Transportation Researchers, Planners, and Engineers. NITC-ED-854. Portland, OR: Transportation Research and Education Center (TREC), 2018. https://doi.org/ 10.15760/trec.192 This Report is brought to you for free and open access. It has been accepted for inclusion in TREC Final Reports by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. FINAL REPORT Introduction to Data Science for Transportation Researchers, Planners, and Engineers NITC-ED-854 January 2018 NITC is a U.S. Department of Transportation national university transportation center. INTRODUCTION TO DATA SCIENCE FOR TRANSPORTATION RESEARCHERS, PLANNERS, AND ENGINEERS Final Report NITC-ED-854 by Liming Wang Portland State University for National Institute for Transportation and Communities (NITC) P.O. Box 751 Portland, OR 97207 January 2017 Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient’s Catalog No. NITC-ED-854 4. Title and Subtitle 5. Report Date Introduction to Data Science for Transportation Researchers, Planners, and Engineers January 2017 6. Performing Organization Code 7. Author(s) 8. Performing Organization Report No. Liming Wang 9. -

Language-Agnostic Data Analysis Workflows and Reproducible Research
Language-agnostic data analysis workflows and reproducible research Andrew John Lowe 28 April 2017 Abstract This is the abstract for a document that briefly describes methods for interacting with different programming languages within the same data analysis workflow. 0.1 Overview • This talk: language-agnostic (or polyglot) analysis workflows • I’ll show how it is possible to work in multiple languages and switch between them without leaving the workflow you started • Additionally, I’ll demonstrate how an entire workflow can be encapsulated in a markdown file that is rendered to a publishable paper with cross-references and a bibliography (and with raw a LATEX file produced as a by-product) in a simple process, making the whole analysis workflow reproducible 0.2 Which tool/language is best? • TMVA, scikit-learn, h2o, caret, mlr, WEKA, Shogun, . • C++, Python, R, Java, MATLAB/Octave, Julia, . • Many languages, environments and tools • People may have strong opinions • A false polychotomy? • Be a polyglot! 0.3 Approaches • Save-and-load • Language-specific bindings • Notebook • knitr 1 Save-and-load approach 1.1 Flat files • Language agnostic • Formats like text, CSV, and JSON are well-supported • Breaks workflow • Data types may not be preserved (e.g., datetime, NULL) • New binary format Feather solves this 1 1.2 Feather Feather: A fast on-disk format for data frames for R and Python, powered by Apache Arrow, developed by Wes McKinney and Hadley Wickham # In R: library(feather) path <- "my_data.feather" write_feather(df, path) # In Python: import feather -
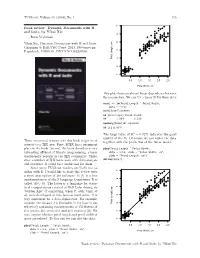
Dynamic Documents with R and Knitr, by Yihui Xie 116 Tugboat, Volume 35 (2014), No
TUGboat, Volume 35 (2014), No. 1 115 ● ● ● Book review: Dynamic Documents with R ● ● ● and knitr, by Yihui Xie ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Boris Veytsman ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Yihui Xie, Dynamic Documents with R and knitr. ● ● ● ● ● ● ● ● ● ● ● ● ● ● Chapman & Hall/CRC Press, 2013, 190+xxvi pp. ● ● ● ● ● ● ● ● ● US$ ISBN ● Paperback, 59.95. 978-1482203530. ● ● ● ● Petal Length, cm Petal ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 6 7 0.5 1.0 1.5 2.0 2.5 Petal Width, cm This plot shows an almost linear dependence between the parameters. We can try a linear fit for these data: model <- lm(Petal.Length ˜ Petal.Width, data = iris) model$coefficients ## (Intercept) Petal.Width ## 1.084 2.230 summary(model)$r.squared ## [1] 0.9271 The large value of R2 = 0.9271 indicates the good quality of the fit. Of course we can replot the data There are several reasons why this book might be of together with the prediction of the linear model: interest to a TEX user. First, LATEX has a prominent place in the book. Second, the book describes a very plot(Petal.Length ˜ Petal.Width, interesting offshoot of literate programming, a topic data = iris, xlab = "Petal Width, cm", traditionally popular in the TEX community. Third, ylab = "Petal Length, cm") abline(model) since a number of TEX users work with data analysis and statistics, R could be a useful tool for them. Since some TUGboat readers are likely not fa- ● ● ● miliar with R, I would like to start this review with ● ● a short description of the software. R [1] is a free ● ● ● ● ● ● ● ● ● ● ● implementation of the S language (sometimes R is ● ● ● ● ● ● ● ● ● ● ● ● ● ● called GNU S). -

LYX and Knitr
knitr.1 LYX and knitr The knitr package allows one to embed R code within LYX and LATEX documents. When a document is compiled into a PDF, LYX/LATEX connects to R to run the R code and the code/output is automatically put into the PDF. In addition to this being a convenient way to use both LYX/LATEX with R, it also provides an important component to the reproducibility of research (RR). For example, one can include the code for a data analysis de- scribed in a paper. This ensures that there would be no “copying and pasting errors” and also provide readers of the paper an im- mediate way to reproduce the research. RR continues to become more important and fortunately more tools are being developed to make it possible. Below are some discussions on the topic: • AMSTAT News column on RR at http://magazine. amstat.org/blog/2011/01/01/scipolicyjan11. • CRAN task view for RR and R at http://cran.r-project. org/web/views/ReproducibleResearch.html. • Yihui Xie: Author of knitr – First and second editions of his Dynamic Documents with R and knitr book. Note that this book was typed in LYX. – Website for knitr at http://yihui.name/knitr The Sweave environment is another way to include R code inside of LYX/LATEX. This was developed prior to knitr, but it is more difficult to use. The purpose of this section is to examine the main compo- nents of knitr so that you will be able to complete the rest of the semester using LYX and knitr together for all assign- ments in our course! Also, a very important purpose is to give you the tools needed to complete all assignments in other R- based courses by using knitr and LYX together! The files used knitr.2 here are intro_example_cereal.lyx, intro_example_cereal.pdf, cereal.csv, ExternalCode.R, FirstBeamer-knitr.zip, JSM2015.zip, and RMarkdown.zip. -

The R Journal, June 2012
The Journal Volume 2/1, June 2010 A peer-reviewed, open-access publication of the R Foundation for Statistical Computing Contents Editorial..................................................3 Contributed Research Articles IsoGene: An R Package for Analyzing Dose-response Studies in Microarray Experiments..5 MCMC for Generalized Linear Mixed Models with glmmBUGS ................. 13 Mapping and Measuring Country Shapes............................... 18 tmvtnorm: A Package for the Truncated Multivariate Normal Distribution........... 25 neuralnet: Training of Neural Networks............................... 30 glmperm: A Permutation of Regressor Residuals Test for Inference in Generalized Linear Models.................................................. 39 Online Reproducible Research: An Application to Multivariate Analysis of Bacterial DNA Fingerprint Data............................................ 44 Two-sided Exact Tests and Matching Confidence Intervals for Discrete Data.......... 53 Book Reviews A Beginner’s Guide to R......................................... 59 News and Notes Conference Review: The 2nd Chinese R Conference........................ 60 Introducing NppToR: R Interaction for Notepad++......................... 62 Changes in R 2.10.1–2.11.1........................................ 64 Changes on CRAN............................................ 72 News from the Bioconductor Project.................................. 85 R Foundation News........................................... 86 2 The Journal is a peer-reviewed publication of -

6:30 PM Grand Ballroom Foyer
Printable Program Printed on: 09/23/2021 Wednesday, May 29 Registration SDSS Hours Wed, May 29, 7:00 AM - 6:30 PM Grand Ballroom Foyer SC1 - Welcome to the Tidyverse: An Introduction to R for Data Science Short Course Wed, May 29, 8:00 AM - 5:30 PM Grand Ballroom E Instructor(s): Garrett Grolemund, RStudio Looking for an effective way to learn R? This one day course will teach you a workflow for doing data science with the R language. It focuses on using R's Tidyverse, which is a core set of R packages that are known for their impressive performance and ease of use. We will focus on doing data science, not programming. You'll learn to: * Visualize data with R's ggplot2 package * Wrangle data with R's dplyr package * Fit models with base R, and * Document your work reproducibly with R Markdown Along the way, you will practice using R's syntax, gaining comfort with R through many exercises and examples. Bring your laptop! The workshop will be taught by Garrett Grolemund, an award winning instructor and the co-author of _R for Data Science_. SC2 - Modeling in the Tidyverse Short Course Wed, May 29, 8:00 AM - 5:30 PM Grand Ballroom F Instructor(s): Max Kuhn, RStudio The tidyverse is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. In the last two years, a suite of tidyverse packages have been created that focus on modeling. This course walks through the process of modeling data using these tools.