Novel Insights Into the Molecular Mechanisms Underlying Risk Of
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Pan-Cancer Analysis of Alternative Lengthening of Telomere Activity
cancers Article Pan-Cancer Analysis of Alternative Lengthening of Telomere Activity Ji-Yong Sung 1,2, Hee-Woong Lim 3, Je-Gun Joung 1,* and Woong-Yang Park 1,2,4,* 1 Samsung Genome Institute, Samsung Medical Center, Seoul 06351, Korea; [email protected] 2 Department of Health Science and Technology, Samsung Advanced Institute of Health Science and Technology, Sungkyunkwan University, Seoul 06351, Korea 3 Division of Biomedical Informatics, Cincinnati Children’s Hospital Medical Center, Cincinnati, OH 45229, USA; [email protected] 4 Department of Molecular Cell Biology, School of Medicine, Sungkyunkwan University, Seoul 06351, Korea * Correspondence: [email protected] (J.-G.J.); [email protected] (W.-Y.P.); Tel.: +82-2-3410-1706 (J.-G.J.); +82-2-3410-6128 (W.-Y.P.); Fax: +82-2-2148-9819 (W.-Y.P.) Received: 30 June 2020; Accepted: 5 August 2020; Published: 7 August 2020 Abstract: Alternative lengthening of telomeres (ALT) is a telomerase-independent mechanism that extends telomeres in cancer cells. It influences tumorigenesis and patient survival. Despite the clinical significance of ALT in tumors, the manner in which ALT is activated and influences prognostic outcomes in distinct cancer types is unclear. In this work, we profiled distinct telomere maintenance mechanisms (TMMs) using 8953 transcriptomes of 31 different cancer types from The Cancer Genome Atlas (TCGA). Our results demonstrated that approximately 29% of cancer types display high ALT activity with low telomerase activity in the telomere-lengthening group. Among the distinct ALT mechanisms, homologous recombination was frequently observed in sarcoma, adrenocortical carcinoma, and kidney chromophobe. Five cancer types showed a significant difference in survival in the presence of high ALT activity. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Cell Growth-Regulated Expression of Mammalian MCM5 and MCM6 Genes Mediated by the Transcription Factor E2F
Oncogene (1999) 18, 2299 ± 2309 ã 1999 Stockton Press All rights reserved 0950 ± 9232/99 $12.00 http://www.stockton-press.co.uk/onc Cell growth-regulated expression of mammalian MCM5 and MCM6 genes mediated by the transcription factor E2F Kiyoshi Ohtani1, Ritsuko Iwanaga1, Masataka Nakamura*,1, Masa-aki Ikeda2, Norikazu Yabuta3, Hiromichi Tsuruga3 and Hiroshi Nojima3 1Human Gene Sciences Center, Tokyo Medical and Dental University, Tokyo 113-8510, Japan 2Department of Developmental Biology, Graduate School of Dentistry, Tokyo Medical and Dental University, Tokyo 113-8549, Japan; 3Department of Molecular Genetics, Research Institute for Microbial Diseases, Osaka University, Suita 565-0871, Japan Initiation of DNA replication requires the function of family (MCM2-7) that have been identi®ed in yeast, MCM gene products, which participate in ensuring that Xenopus, and human. Mcm proteins seem to regulate DNA replication occurs only once in the cell cycle. the initiation at the replication origin where the loading Expression of all mammalian genes of the MCM family of the proteins onto the origin recognition complex is induced by growth stimulation, unlike yeast, and the (ORC) is regulated by Cdc6 and cyclin-dependent mRNA levels peak at G1/S boundary. In this study, we kinases (Donovan et al., 1997; Tanaka et al., 1997). examined the transcriptional activities of isolated human However, the mechanism(s) by which Mcm proteins MCM gene promoters. Human MCM5 and MCM6 control the initiation of DNA replication remains promoters with mutation in the E2F sites failed in unclear. promoter regulation following serum stimulation and Xenopus Mcm proteins seem to be able to access exogenous E2F expression. -
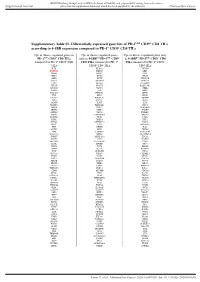
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Bioinformatics-Based Screening of Key Genes for Transformation of Liver
Jiang et al. J Transl Med (2020) 18:40 https://doi.org/10.1186/s12967-020-02229-8 Journal of Translational Medicine RESEARCH Open Access Bioinformatics-based screening of key genes for transformation of liver cirrhosis to hepatocellular carcinoma Chen Hao Jiang1,2, Xin Yuan1,2, Jiang Fen Li1,2, Yu Fang Xie1,2, An Zhi Zhang1,2, Xue Li Wang1,2, Lan Yang1,2, Chun Xia Liu1,2, Wei Hua Liang1,2, Li Juan Pang1,2, Hong Zou1,2, Xiao Bin Cui1,2, Xi Hua Shen1,2, Yan Qi1,2, Jin Fang Jiang1,2, Wen Yi Gu4, Feng Li1,2,3 and Jian Ming Hu1,2* Abstract Background: Hepatocellular carcinoma (HCC) is the most common type of liver tumour, and is closely related to liver cirrhosis. Previous studies have focussed on the pathogenesis of liver cirrhosis developing into HCC, but the molecular mechanism remains unclear. The aims of the present study were to identify key genes related to the transformation of cirrhosis into HCC, and explore the associated molecular mechanisms. Methods: GSE89377, GSE17548, GSE63898 and GSE54236 mRNA microarray datasets from Gene Expression Omni- bus (GEO) were analysed to obtain diferentially expressed genes (DEGs) between HCC and liver cirrhosis tissues, and network analysis of protein–protein interactions (PPIs) was carried out. String and Cytoscape were used to analyse modules and identify hub genes, Kaplan–Meier Plotter and Oncomine databases were used to explore relationships between hub genes and disease occurrence, development and prognosis of HCC, and the molecular mechanism of the main hub gene was probed using Kyoto Encyclopedia of Genes and Genomes(KEGG) pathway analysis. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Aneuploidy: Using Genetic Instability to Preserve a Haploid Genome?
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Science (Cancer Biology) Aneuploidy: Using genetic instability to preserve a haploid genome? Submitted by: Ramona Ramdath In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Science Examination Committee Signature/Date Major Advisor: David Allison, M.D., Ph.D. Academic James Trempe, Ph.D. Advisory Committee: David Giovanucci, Ph.D. Randall Ruch, Ph.D. Ronald Mellgren, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: April 10, 2009 Aneuploidy: Using genetic instability to preserve a haploid genome? Ramona Ramdath University of Toledo, Health Science Campus 2009 Dedication I dedicate this dissertation to my grandfather who died of lung cancer two years ago, but who always instilled in us the value and importance of education. And to my mom and sister, both of whom have been pillars of support and stimulating conversations. To my sister, Rehanna, especially- I hope this inspires you to achieve all that you want to in life, academically and otherwise. ii Acknowledgements As we go through these academic journeys, there are so many along the way that make an impact not only on our work, but on our lives as well, and I would like to say a heartfelt thank you to all of those people: My Committee members- Dr. James Trempe, Dr. David Giovanucchi, Dr. Ronald Mellgren and Dr. Randall Ruch for their guidance, suggestions, support and confidence in me. My major advisor- Dr. David Allison, for his constructive criticism and positive reinforcement. -

Chromosome Integrity in Saccharomyces Cerevisiae: the Interplay of DNA Replication Initiation Factors, Elongation Factors, and Origins
Downloaded from genesdev.cshlp.org on October 1, 2021 - Published by Cold Spring Harbor Laboratory Press Chromosome integrity in Saccharomyces cerevisiae: the interplay of DNA replication initiation factors, elongation factors, and origins Dongli Huang1,2 and Douglas Koshland1,3 1Howard Hughes Medical Institute, Carnegie Institution of Washington, Department of Embryology, Baltimore, Maryland 21210, USA; 2Johns Hopkins University, Department of Biology, Baltimore, Maryland 21218, USA The integrity of chromosomes during cell division is ensured by both trans-acting factors and cis-acting chromosomal sites. Failure of either these chromosome integrity determinants (CIDs) can cause chromosomes to be broken and subsequently misrepaired to form gross chromosomal rearrangements (GCRs). We developed a simple and rapid assay for GCRs, exploiting yeast artificial chromosomes (YACs) in Saccharomyces cerevisiae. We used this assay to screen a genome-wide pool of mutants for elevated rates of GCR. The analyses of these mutants define new CIDs (Orc3p, Orc5p, and Ycs4p) and new pathways required for chromosome integrity in DNA replication elongation (Dpb11p), DNA replication initiation (Orc3p and Orc5p), and mitotic condensation (Ycs4p). We show that the chromosome integrity function of Orc5p is associated with its ATP-binding motif and is distinct from its function in controlling the efficiency of initiation of DNA replication. Finally, we used our YAC assay to assess the interplay of trans and cis factors in chromosome integrity. Increasing the number of origins on a YAC suppresses GCR formation in our dpb11 mutant but enhances it in our orc mutants. This result provides potential insights into the counterbalancing selective pressures necessary for the evolution of origin density on chromosomes. -

Crystal Structure of a Variant PAM2 Motif of LARP4B Bound to the MLLE Domain of PABPC1
biomolecules Article Crystal Structure of a Variant PAM2 Motif of LARP4B Bound to the MLLE Domain of PABPC1 Clemens Grimm *, Jann-Patrick Pelz, Cornelius Schneider, Katrin Schäffler and Utz Fischer Department of Biochemistry, Theodor Boveri Institute, Biocenter of the University of Würzburg, 97070 Würzburg, Germany; [email protected] (J.-P.P.); [email protected] (C.S.); katrin.schaeffl[email protected] (K.S.); utz.fi[email protected] (U.F.) * Correspondence: [email protected] Received: 3 April 2020; Accepted: 4 June 2020; Published: 6 June 2020 Abstract: Eukaryotic cells determine the protein output of their genetic program by regulating mRNA transcription, localization, translation and turnover rates. This regulation is accomplished by an ensemble of RNA-binding proteins (RBPs) that bind to any given mRNA, thus forming mRNPs. Poly(A) binding proteins (PABPs) are prominent members of virtually all mRNPs that possess poly(A) tails. They serve as multifunctional scaffolds, allowing the recruitment of diverse factors containing a poly(A)-interacting motif (PAM) into mRNPs. We present the crystal structure of the variant PAM motif (termed PAM2w) in the N-terminal part of the positive translation factor LARP4B, which binds to the MLLE domain of the poly(A) binding protein C1 cytoplasmic 1 (PABPC1). The structural analysis, along with mutational studies in vitro and in vivo, uncovered a new mode of interaction between PAM2 motifs and MLLE domains. Keywords: PAM2w; PAM2; PABC1; MLLE domain; PABP; Poly(A) binding protein 1. Introduction In higher eukaryotes, posttranscriptional mechanisms contribute significantly to gene expression. The mRNA, which is translated into proteins by the ribosomes, has first to undergo several maturation steps, from the primary pre-mRNA transcript to the mature mRNA. -

Open Data for Differential Network Analysis in Glioma
International Journal of Molecular Sciences Article Open Data for Differential Network Analysis in Glioma , Claire Jean-Quartier * y , Fleur Jeanquartier y and Andreas Holzinger Holzinger Group HCI-KDD, Institute for Medical Informatics, Statistics and Documentation, Medical University Graz, Auenbruggerplatz 2/V, 8036 Graz, Austria; [email protected] (F.J.); [email protected] (A.H.) * Correspondence: [email protected] These authors contributed equally to this work. y Received: 27 October 2019; Accepted: 3 January 2020; Published: 15 January 2020 Abstract: The complexity of cancer diseases demands bioinformatic techniques and translational research based on big data and personalized medicine. Open data enables researchers to accelerate cancer studies, save resources and foster collaboration. Several tools and programming approaches are available for analyzing data, including annotation, clustering, comparison and extrapolation, merging, enrichment, functional association and statistics. We exploit openly available data via cancer gene expression analysis, we apply refinement as well as enrichment analysis via gene ontology and conclude with graph-based visualization of involved protein interaction networks as a basis for signaling. The different databases allowed for the construction of huge networks or specified ones consisting of high-confidence interactions only. Several genes associated to glioma were isolated via a network analysis from top hub nodes as well as from an outlier analysis. The latter approach highlights a mitogen-activated protein kinase next to a member of histondeacetylases and a protein phosphatase as genes uncommonly associated with glioma. Cluster analysis from top hub nodes lists several identified glioma-associated gene products to function within protein complexes, including epidermal growth factors as well as cell cycle proteins or RAS proto-oncogenes.